
ホームページ >テクノロジー周辺機器 >AI >CLRNet: 自動運転車線検出のための階層的に洗練されたネットワーク アルゴリズム
CLRNet: 自動運転車線検出のための階層的に洗練されたネットワーク アルゴリズム

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-08 12:00:05752ブラウズ
ビジュアル ナビゲーション システムでは、車線検出は重要な機能です。これは、自動運転や先進運転支援システム (ADAS) などのアプリケーションに大きな影響を与えるだけでなく、スマート車両の自己位置決めや安全運転においても重要な役割を果たします。したがって、車線検出技術の開発は、交通システムのインテリジェンスと安全性を向上させる上で非常に重要です。
ただし、車線検出には独自のローカル パターンがあり、ネットワーク画像内の車線情報を正確に予測する必要があり、正確な位置特定を実現するには詳細な低レベルの特徴に依存します。したがって、車線検出は、コンピューター ビジョンにおける重要かつ困難なタスクであると考えられます。
車線を正確に検出するには、さまざまな特徴レベルを使用することが非常に重要ですが、割引作業はまだ探索段階にあります。このペーパーでは、車線検出における高レベルおよび低レベルの機能を完全に活用することを目的としたクロスレイヤー リファインメント ネットワーク (CLRNet) を紹介します。まず、高レベルのセマンティック特徴を持つレーンを検出し、次に低レベルの特徴に基づいて調整します。このアプローチでは、より多くのコンテキスト情報を利用して車線を検出すると同時に、ローカルの詳細な車線特徴を利用して測位精度を向上させることができます。さらに、ROIGather を通じてグローバル コンテキストを収集することで、レーンのフィーチャ表現をさらに強化できます。まったく新しいネットワークの設計に加えて、ライン IoU 損失も導入され、車線ラインをユニット全体として回帰させて測位精度を向上させます。
前述したように、Lane には高レベルのセマンティクスがありますが、特定のローカル パターンがあるため、正確に位置を特定するには詳細な低レベルの機能が必要です。 CNN のさまざまな機能レベルを効果的に利用する方法が依然として問題です。以下の図 1(a) に示すように、ランドマークと車線の意味は異なりますが、類似した特性 (長い白線など) を共有しています。高レベルのセマンティクスとグローバル コンテキストがなければ、それらを区別することは困難です。一方で、地域性も重要で、路地は細く長く、土地柄は単純です。
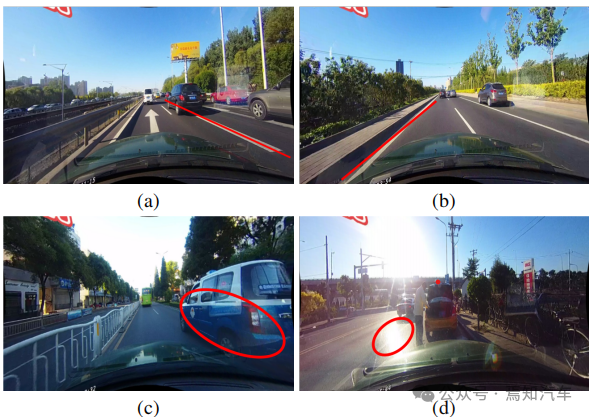
#高度な機能の検出結果は図 1(b) に示されており、車線は正常に検出されていますが、精度を向上させる必要があります。したがって、低レベルの情報と高レベルの情報を組み合わせることで相互に補完し、より正確な車線検出が可能になります。
車線検出におけるもう 1 つの一般的な問題は、車線の存在に関する視覚情報が欠如していることです。場合によっては、車線が他の車両によって占有され、車線の検出が困難になる場合があります。さらに、極端な照明条件下では車線の認識が困難になる可能性があります。
関連作業
以前の作業では、車線のローカル ジオメトリをモデル化してグローバル結果に統合するか、完全接続レイヤーを構築しました。車線を予測するためのグローバルな特徴。これらの検出器は、車線検出におけるローカルまたはグローバルの特徴の重要性を実証していますが、両方の特徴を同時に活用していないため、検出パフォーマンスが不正確になる可能性があります。たとえば、SCNN と RESA は、グローバル コンテキストを収集するためのメッセージ パッシング メカニズムを提案していますが、これらの方法はピクセル レベルの予測を実行し、レーンを全体の単位として扱いません。その結果、そのパフォーマンスは多くの最先端の検出器に比べて遅れをとっています。
車線検出では、低レベルの機能と高レベルの機能が補完的であることに基づいて、本稿では、低レベルの機能と高レベルの機能を最大限に活用する新しいネットワーク アーキテクチャ (CLRNet) を提案します。車線検出のための高レベルの機能。まず、ROIGather を通じてグローバル コンテキストが収集され、車線フィーチャの表現がさらに強化され、他のネットワークに挿入することもできます。次に、レーン検出用に調整された Line over Union (LIoU) 損失が提案され、レーンをユニット全体として回帰させ、パフォーマンスを大幅に向上させます。さまざまな検出器の位置決め精度をより適切に比較するために、新しい mF1 インジケーターも使用されます。
CNN に基づく車線検出は現在、主にセグメンテーションベースの方法、アンカーベースの方法、パラメータベースの方法の 3 つの方法に分けられ、車線の表現に基づいて識別されます。 。
1. セグメンテーションベースの方法
このタイプのアルゴリズムは通常、ピクセルごとの予測式を採用します。つまり、車線検出はセマンティック セグメンテーション タスクと見なされます。 SCNN は、視覚的に検出できないオブジェクトの問題を解決するためのメッセージ パッシング メカニズムを提案しています。これは、車線内に存在する強い空間関係を捉えます。 SCNN は車線検出パフォーマンスを大幅に向上させますが、この方法はリアルタイム アプリケーションには時間がかかります。 RESA は、ネットワークがグローバルな機能を収集してパフォーマンスを向上できるようにするリアルタイム機能集約モジュールを提案しています。 CurveLane-NAS では、Neural Architecture Search (NAS) を使用して、正確な情報を取得してカーブレーンの検出を容易にする、より優れたネットワークを見つけます。ただし、NAS は計算コストが非常に高く、多くの GPU 時間を必要とします。これらのセグメンテーションベースの方法は、画像全体に対してピクセルレベルの予測を実行し、車線を全体の単位として考慮しないため、非効率的で時間がかかります。
2. アンカーベースの方法
車線検出におけるアンカーベースの方法は、2 つのカテゴリに分類できます。たとえば、行アンカーベースの方法と行アンカーベースの方法です。ライン アンカー ベースの方法では、正確な車線を回帰するための参照として事前定義されたライン アンカーが使用されます。 Line-CNN は、車線検出にラインとコードを使用する先駆的な作品です。 LaneATT は、グローバル情報を集約できる新しいアンカーベースのアテンション メカニズムを提案しています。最先端の結果を達成し、高い有効性と効率性を示します。 SGNet は、新しい消失点ガイド付きアンカー ジェネレーターを導入し、パフォーマンスを向上させるために複数の構造ガイドを追加します。行アンカーベースの方法の場合、画像上の事前定義された各行の可能性のあるセルを予測します。 UFLD は、レーンアンカーベースの車線検出方法を最初に提案し、軽量のバックボーン ネットワークを採用して高い推論速度を実現しました。シンプルで高速ですが、全体的なパフォーマンスは良くありません。 CondLaneNet は、条件付き畳み込みと行アンカー ベースの式に基づいた条件付き車線検出戦略を導入しています。つまり、最初に車線境界線の開始点を特定し、次に行アンカー ベースの車線検出を実行します。ただし、一部の複雑なシナリオでは、開始点を特定することが難しく、パフォーマンスが比較的低下します。
3. パラメータベースの手法
点回帰とは異なり、パラメータベースの手法ではパラメータを使用して予測します。車線曲線モデリングが実行され、これらのパラメータが車線を検出するために回帰分析されます。 PolyLaneNet は多項式回帰問題を採用し、高い効率を実現します。 LSTR は、道路構造とカメラの姿勢を考慮して車線の形状をモデル化し、車線検出タスクに Transformer を導入してグローバルな特徴を取得します。
パラメータベースの手法では、回帰に必要なパラメータは少なくなりますが、予測パラメータの影響を受けやすくなります。たとえば、高次の係数の予測が正しくないと、レーンの形状が変化する可能性があります。パラメーターベースの方法は推論速度が速いものの、より高いパフォーマンスを達成するのに依然として苦労しています。
クロスレイヤー洗練ネットワーク (CLRNet) の方法論的概要
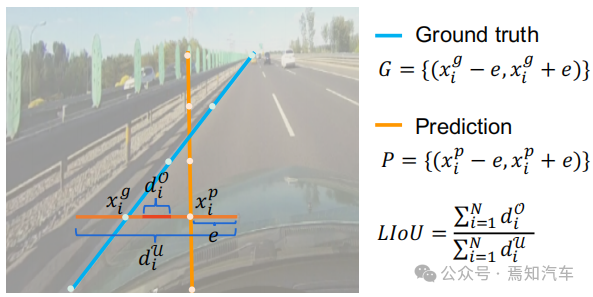
この記事では、新しいフレームワーククロスレイヤー洗練ネットワークについて紹介します。 (CLRNet)、車線検出に低レベル機能と高レベル機能を完全に活用します。具体的には、車線を大まかに特定するために、高度な意味論的特徴が最初に検出されます。その後、詳細な特徴に基づいて車線の位置と特徴抽出を段階的に調整して、高精度の検出結果 (つまり、より正確な位置) を取得します。視覚的に検出できない車線内の死角領域の問題を解決するために、ROI コレクターが導入され、ROI レーンの特徴と特徴マップ全体の間の関係を確立することで、よりグローバルなコンテキスト情報を取得します。さらに、車線の交差対結合比 IoU も定義され、車線 IoU (LIoU) 損失が車線を全体の単位として回帰するために提案され、標準損失と比較してパフォーマンスが大幅に向上します(つまり、滑らか) -l1 損失)。
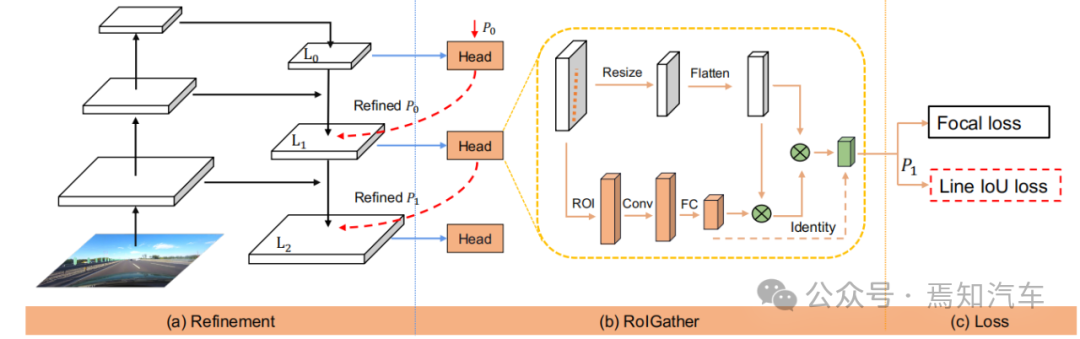
#図 2. CLRNet の概要
上の図は、この記事で紹介する CLRNet アルゴリズムを示しています。レーンマーキング用 IoU によって処理されるフロントエンドネットワーク全体。このうち、図(a)のネットワークはFPN構造から特徴マップを生成します。その後、各レーンの事前の高レベルの特徴から低レベルの特徴まで洗練されます。図 (b) は、各ヘッドがより多くのコンテキスト情報を利用してレーンの事前の特徴を取得することを示しています。図 (c) は、レーンの事前分類と回帰を示しています。この記事で提案されている回線 IoU 損失は、回帰パフォーマンスをさらに向上させるのに役立ちます。
次に、この記事で紹介したアルゴリズムの動作プロセスを詳しく説明します。
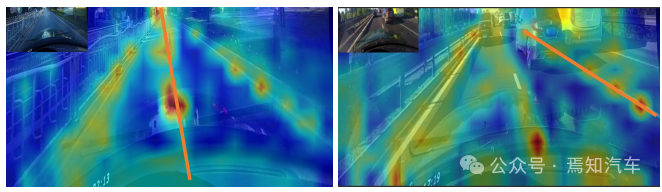
#1. 車線ネットワークの表現 ご存知のとおり、実際の道路の車線は細くて長いです。このフィーチャ表現には強力な形状事前情報があるため、事前定義された車線事前情報は、ネットワークが車線をより適切に特定するのに役立ちます。従来の物体検出では、物体は長方形のボックスで表されます。ただし、どのような種類の長方形のボックスも長い線を表すのには適していません。ここでは、等距離の 2D 点が車線表現として使用されます。具体的には、車線は一連の点、つまり P = {(x1, y1), · · ·,(xN , yN )} として表されます。点の y 座標は、画像の垂直方向、つまり (1) 前景と背景の確率。 (2) 車線の長さが優先されます。 (3) 車線の開始点と前の車線の x 軸の間の角度 (x、y、θ と呼ばれます)。 (4) N オフセット、つまり予測とその真の値の間の水平距離。 2. クロスレイヤーの改良動機 ニューラル ネットワークでは、深い高レベルの特徴ペアにより多くのロードが与えられます。セマンティックな特徴を持つオブジェクトはより強力なフィードバックを示しますが、浅い低レベルの特徴はより多くのローカル コンテキスト情報を持ちます。車線オブジェクトが高レベルのフィーチャにアクセスできるようにするアルゴリズムは、車線の境界線やランドマークの区別など、より有用なコンテキスト情報を活用するのに役立ちます。同時に、詳細な機能により、高い位置精度で車線を検出できます。オブジェクト検出では、ConvNet 特徴階層のピラミッド形状を利用する特徴ピラミッドを構築し、異なるスケールのオブジェクトを異なるピラミッド レベルに割り当てます。ただし、高レベル機能と低レベル機能の両方がレーンにとって重要であるため、レーンを 1 つのレベルだけに直接割り当てることは困難です。 Cascade RCNN からインスピレーションを得た、レーン オブジェクトをすべてのレベルに割り当て、個々のレーンを順番に検出できます。 特に、高度な機能を備えた車線を検出して、車線の位置を大まかに特定できます。検出された既知のレーンに基づいて、より詳細な特徴を使用してレーンを絞り込むことができます。 3. 洗練された構造 #アルゴリズム全体の目標は、ConvNet のピラミッド機能階層を利用することです。 (低レベルのセマンティクスから高レベルのセマンティクスまでの機能を使用して)、常に高レベルのセマンティクスを持つ機能ピラミッドを構築します。残差ネットワーク ResNet がバックボーンとして使用され、{L0、L1、L2} は FPN によって生成された特徴レベルを表すために使用されます。 #図 2 に示すように、クロスレイヤーリファインメントは最高レベル L0 から始まり、徐々に L2 に近づきます。対応する絞り込みは、{R0,R1,R2} を使用して表されます。次に、一連の改良構造の構築に進むことができます。 ここで、 t = 1, · · · , T, T は、改良点。 メソッド全体は、高度なセマンティクスで最上位層から検出を実行します。Pt は、レーン事前のパラメーター (開始点の座標 x、y および角度 θ) であり、インスピレーションと自己-の学び。最初のレイヤー L0 では、P0 は画像平面上に均一に分布し、リファインメント Rt は Pt を入力として受け取り、ROI レーンの特徴を取得し、次に 2 つの FC レイヤーを実行してリファインメント パラメーター Pt を取得します。レーン事前情報と特徴情報の抽出を段階的に改良することは、クロスレイヤーの改良において非常に重要です。なお、この方法はFPN構造に限定されるものではなく、ResNetのみを使用したり、PAFPNを採用したりすることも適している。 4. ROI コレクション レーン事前情報を各特徴マップに割り当てた後、ROI を使用できます。モジュールはレーン事前特徴を取得します。ただし、これらの機能のコンテキスト情報はまだ不十分です。場合によっては、極端な照明条件下では、レーン インスタンスが占有されたり、隠れたりすることがあります。この場合、車線の存在を示すローカル視覚リアルタイム追跡データが存在しない可能性があります。ピクセルが車線に属しているかどうかを判断するには、近くの特徴を調べる必要があります。最近の調査では、リモートの依存関係を完全に活用すればパフォーマンスが向上する可能性があることも示されています。したがって、車線の特徴をよりよく学習するために、より有用なコンテキスト情報を収集できます。 これを行うには、まずレーンに沿って畳み込み計算が実行され、レーン前の各ピクセルが近くのピクセルから情報を収集し、この情報に基づいて占有部分を強調できるようになります。さらに、レーン事前特徴と特徴マップ全体の間の関係が確立されます。したがって、より多くのコンテキスト情報を利用して、より適切な特徴表現を学習できます。 ROI 収集モジュールの構造全体は軽量で、実装が簡単です。特徴マップとレーン事前分布を入力として受け取るため、各レーン事前分布には N 個のポイントがあります。バウンディングボックスの ROI Align とは異なり、各レーン事前情報収集では、まず ROI Align に従ってレーン事前 ROI 特徴 (Xp ∈ RC × Np) を取得する必要があります。前のレーンから Np ポイントを均一にサンプリングし、共一次内挿を使用してこれらの位置での入力フィーチャの正確な値を計算します。 L1 および L2 の ROI フィーチャの場合、前のレイヤーの ROI フィーチャを接続することによってフィーチャ表現を強化できます。各レーンピクセルの近くの特徴は、抽出された ROI 特徴を畳み込むことによって収集できます。メモリを節約するために、ここでは完全接続を使用してレーン事前特徴 (Xp ∈ RC×1) をさらに抽出します。特徴マップのサイズは Xf ∈ R に調整されます。 C ×H×W は、引き続き Xf ∈RC×HW に平坦化できます。 事前特徴を持つレーンのグローバル コンテキスト情報を収集するには、まず ROI レーン事前特徴 (Xp) とグローバル特徴の間の注意行列 W を計算する必要があります。 map (Xf) は次のように記述されます: ここで、 f は正規化関数のソフト マックスです。集約された特徴は次のように記述できます。 出力 G は、 Xf のすべての位置から選択された Xp 上の Xf の重ね合わせ値を反映します。最後に、出力は元の入力 Xp に追加されます。 ROIGather がネットワーク内でどのように機能するかをさらに示すために、アテンション マップの ROIGather 分析を図 3 に視覚化します。これは、レーン事前の ROI 特徴と特徴マップ全体の間の注意を示しています。オレンジ色の線は以前の対応レーン、赤色の領域は注目重みの高いスコアに対応します。 図 3. ROIGather のアテンション ウェイトの図解 上の図は、最初にレーンを示しています。テストの ROI 特徴 (オレンジ色の線) と特徴マップ全体の間の注意の重み。色が明るいほど、重みの値は大きくなります。特に、提案された ROIGather は、豊富なセマンティック情報を含むグローバル コンテキストを効果的に収集し、オクルージョン下でも前景レーンの特徴をキャプチャできます。 #5. 車線の交差と結合率 IoU 損失 前述したように、レーン 事前分布は、グラウンド トゥルースに回帰する必要がある離散点で構成されます。スムーズ l1 などの一般的な距離損失を使用して、これらのポイントを回帰できます。ただし、この損失はポイントを別個の変数として扱います。これは過度に単純化された仮定であり、回帰の精度が低くなります。 距離損失とは対照的に、Intersection over Union (IoU) は、車線事前分布をユニット全体として回帰でき、評価指標に合わせて調整されます。ここでは、Line over Union (LIoU) 損失を計算するための、シンプルで効率的なアルゴリズムが導出されます。 下図に示すように、サンプリングされた xi 位置に応じて拡張セグメントの IoU を積分することで、ライン交差と和集合率 IoU を計算できます。 #図 4. ライン IoU ダイアグラム #上図の式に示すように、線分の交差と結合比率 IoU の定義から、2 つの線分の相互作用と結合の比率である線 IoU 損失が導入され始めます。図 4 に示すように、予測された車線内の各点について、まずその点 (xpi) を半径 e の線分に延長します。次に、延長した線分とそのグラウンドトゥルースの間の IoU を次のように計算できます。 ここで、xpi - e、xpi e は xp i, xgi -e, xgi e の展開ポイントは、対応するグラウンドトゥルース ポイントです。 d0i は負の値になる可能性があることに注意してください。これにより、重複しない線分の場合に効率的な情報の最適化が可能になります。 すると、LIoU は無限の直線点の組み合わせと考えることができます。式を簡素化し、計算を容易にするために、それを離散形式に変換します。 その後、LIoU 損失は次のように定義されます。 ここで、−1 ≤ LIoU ≤1、2 つのラインが完全に重なる場合、LIoU = 1、2 つのラインが遠く離れている場合、LIoU は -1 に収束します。 。 回線 IoU 損失による車線相関の計算には 2 つの利点があります: (1) シンプルで微分可能であり、並列コンピューティングの実装が簡単です。 (2) レーン全体を予測するため、全体的なパフォーマンスの向上に役立ちます。 #6. トレーニングと推論の詳細 最初に、前方サンプル選択が実行されます。 トレーニング プロセス中、各グラウンド トゥルース レーンには、ポジティブ サンプルとして 1 つ以上の予測レーンが動的に割り当てられます。特に、予測されたレーンは、次のように定義される割り当てコストに従って順序付けされます。 ここで、Ccls は、予測とラベルの間の焦点コストです。 。 Csim は、予測されたレーンと実際のレーンの間の類似性コストです。これは 3 つの部分で構成され、Cdis は有効なすべてのレーン ポイントの平均ピクセル距離を表し、Cxy は開始点座標の距離を表し、Ctheta はシータ角度の差を表し、すべて [0, 1] に正規化されます。 wcls と wsim は、定義された各コンポーネントの重み係数です。各グラウンド トゥルース レーンには、Cassign に従って予測レーンの動的番号 (top-k) が割り当てられます。 第二に、トレーニングの損失があります。 トレーニング損失には分類損失と回帰損失が含まれます。回帰損失は指定されたサンプルについてのみ計算されます。全体的な損失関数は次のように定義されます: Lcls は予測とラベルの間の焦点損失、Lxytl は開始点の座標、シータ角度の回帰です。レーン長のスムーズ l1 損失、LLIoU は、予測されたレーンとグランド トゥルースの間の回線 IoU 損失です。補助的なセグメンテーション損失を追加すると、トレーニング中にのみ使用され、推論コストがかかりません。 最後に、効果的な推論があります。分類スコアでしきい値を設定してバックグラウンド レーン (事前の低スコア レーン) をフィルターし、後で nms を使用して重複の高いレーンを削除します。 1 対 1 の割り当てを使用する場合、つまり、top-k = 1 を設定する場合、これは nms フリーにすることもできます。 この論文では、車線検出のためのクロスレイヤーリファインメントネットワーク (CLRNet) を提案します。 CLRNet は、高レベルの機能を利用して車線を予測すると同時に、ローカルの詳細な機能を活用して位置特定の精度を向上させることができます。車線の存在の視覚的証拠が不十分であるという問題を解決するために、ROIGather を通じてすべてのピクセルとの関係を確立することで車線の特徴表現を強化することが提案されています。レーン全体を回帰するために、レーン検出用に調整された Line IoU 損失が提案され、標準損失 (つまり、smooth-l1 損失) と比較してパフォーマンスが大幅に向上します。この方法は、3 つのレーン検出ベンチマーク データセット、つまり CULane、LLamas、および Tusimple で評価されます。提案された方法は、3 レーン検出ベンチマークにおいて他の最先端の方法 (CULane、Tusimple、LLAMAS) よりも大幅に優れています。 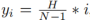 に均一にサンプリングされます。ここで、H は画像の高さです。したがって、x 座標は対応する
に均一にサンプリングされます。ここで、H は画像の高さです。したがって、x 座標は対応する 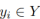 に関連付けられ、この表現をここではレーンファーストと呼びます。各レーンの事前予測はネットワークによって予測され、次の 4 つの部分で構成されます:
に関連付けられ、この表現をここではレーンファーストと呼びます。各レーンの事前予測はネットワークによって予測され、次の 4 つの部分で構成されます: 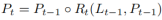
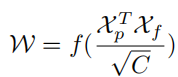
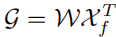
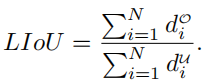
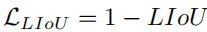
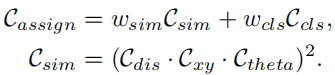
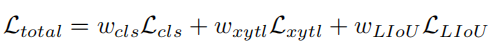
概要
以上がCLRNet: 自動運転車線検出のための階層的に洗練されたネットワーク アルゴリズムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。