
ホームページ >テクノロジー周辺機器 >AI >「コンセプチュアルエレガンス」の問題と戦え! Google、新しい時間認識フレームワークをリリース:画像認識精度が15%向上
「コンセプチュアルエレガンス」の問題と戦え! Google、新しい時間認識フレームワークをリリース:画像認識精度が15%向上

- 王林転載
- 2024-03-02 12:04:02728ブラウズ
概念ドリフトは、機械学習研究において常に厄介な問題です。これは、時間の経過とともにデータ分布が変化し、モデルの有効性に影響を与えることを指します。この状況により、研究者は新しいデータ分布に適応するためにモデルを常に調整する必要があります。コンセプトドリフトの問題を解決する鍵は、データの変化をタイムリーに検出して適応できるアルゴリズムを開発することです。 - 過去 10 年間を明らかにする定常状態学習ベンチマーク 1 年間にわたるオブジェクトの視覚的特性の大きな変化。
この現象は「スローコンセプトドリフト」と呼ばれ、オブジェクト分類モデルに深刻な課題をもたらします。オブジェクトの外観や属性は時間の経過とともに変化するため、モデルがこの変化に適応し、引き続き正確に分類できるようにする方法が研究の焦点になります。
最近、この課題に直面して、Google AI の研究チームは MUSCATEL (Multi-Scale Temporal Learning) Driving Methods と呼ばれる最適化を提案し、モデルのパフォーマンスを向上させることに成功しました。大規模で常に変化するデータセットに対応します。この研究成果はAAAI2024で発表されました。 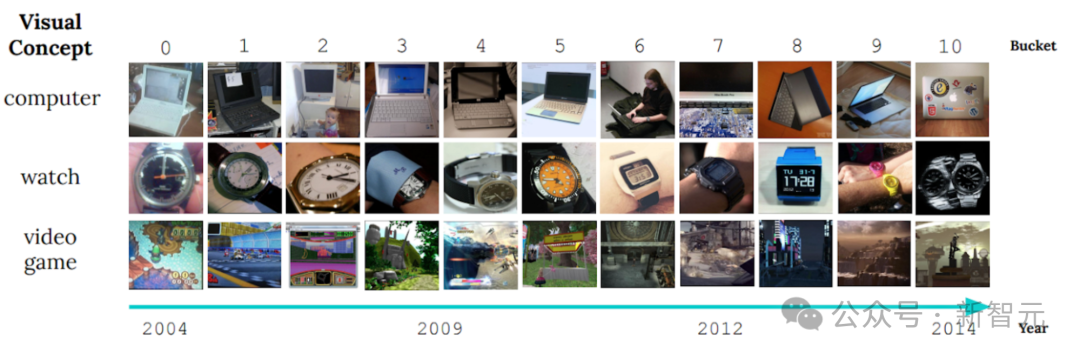
論文アドレス: https://arxiv.org/abs/2212.05908
現在、確率ドリフトの主流の手法は、オンライン学習と継続学習(オンラインで継続学習)です。
これらの方法の主なコンセプトは、モデルを継続的に更新して最新のデータに適応させ、モデルの有効性を確保することです。ただし、このアプローチには 2 つの大きな課題があります。
これらの手法では、多くの場合、最新のデータのみに焦点が当てられ、過去のデータに含まれる貴重な情報が無視されます。さらに、すべてのデータ インスタンスの寄与は時間の経過とともに均一に減衰すると仮定していますが、これは実際の状況と一致しません。
MUSCATEL メソッドは、トレーニング インスタンスに重要度スコアを割り当て、将来のインスタンスでのモデルのパフォーマンスを最適化することで、これらの問題を効果的に解決できます。
この目的を達成するために、研究者らは実体とその年齢を組み合わせてスコアを生成する補助モデルを導入しました。補助モデルとメイン モデルは、2 つの中心的な問題を解決するために協力して学習します。
このメソッドは、実際のアプリケーションで優れたパフォーマンスを発揮します。3,900 万枚の写真をカバーし、9 年間継続した大規模な実世界のデータセット実験では、他の定常状態の学習ベースラインを上回るパフォーマンスを示しました。精度が 15% 向上しました。
同時に、2 つの非定常学習データセットと継続学習環境において、SOTA 手法よりも優れた結果も示しています。
教師あり学習への概念ドリフトの課題
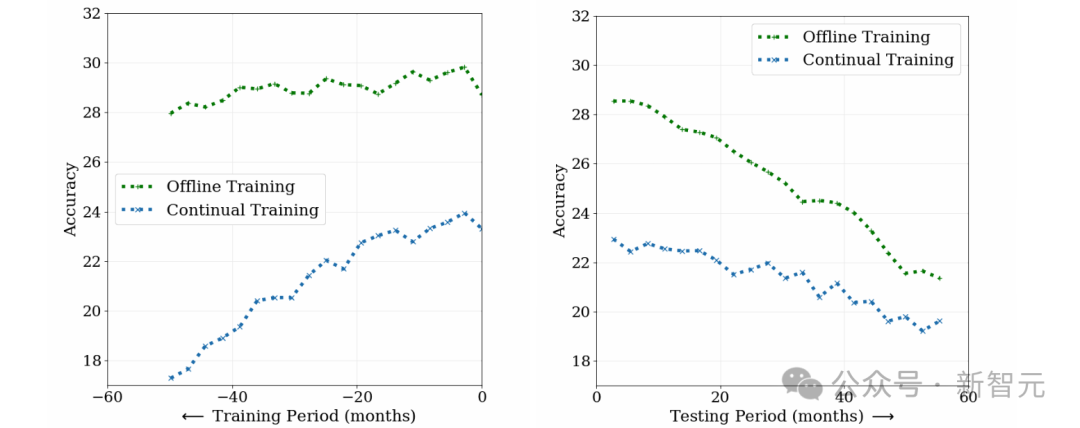
教師あり学習への概念ドリフトの課題を研究するために、研究者は写真分類タスクを実施しました 2 つの方法、オフライン トレーニングと継続トレーニングを、10 年間の約 3,900 万枚のソーシャル メディア写真を使用して比較しました。
以下の図に示すように、オフライン トレーニング モデルの初期パフォーマンスは高いものの、時間の経過とともに精度が低下し、壊滅的な忘却により初期データの理解が低下します。
逆に、継続的トレーニング モデルの初期パフォーマンスは低くなりますが、古いデータへの依存度が低く、テスト中の劣化が速くなります。
これは、時間の経過とともにデータが進化し、2 つのモデルの適用可能性が低下することを示しています。概念ドリフトは教師あり学習に課題をもたらし、データの変化に適応するためにモデルを継続的に更新する必要があります。
#MUSCATEL
##MUSCATEL は、遅さの概念、ドリフトの問題に対する革新的なアプローチです。 。オフライン学習と継続学習の利点をうまく組み合わせることで、将来のモデルのパフォーマンス低下を軽減することを目指しています。
膨大な学習データを前に、MUSCATEL は独特の魅力を発揮します。従来のオフライン学習に依存するだけでなく、これに基づいて過去のデータの影響を慎重に調整および最適化し、モデルの将来のパフォーマンスのための強固な基盤を築きます。
新しいデータに対するメイン モデルのパフォーマンスをさらに向上させるために、MUSCATEL は補助モデルを導入します。
以下の図の最適化目標に基づいて、トレーニング補助モデルは、その内容と経過時間に基づいて各データ ポイントに重みを割り当てます。この設計により、モデルが将来のデータの変化に適応し、継続的な学習機能を維持できるようになります。
補助モデルとメインモデルを共進化させるために、MUSCATEL はメタ学習戦略も採用しています。
この戦略の鍵は、以下の図に示すように、サンプル インスタンスと年齢の寄与を効果的に分離し、複数の固定減衰時間スケールを組み合わせて重みを設定することです。
さらに、MUSCATEL は、より正確な学習を実現するために、各インスタンスを最適な時間スケールで「分散」することも学習します。 。
インスタンスの重みスコア
下の図に示すように、CLEAR オブジェクト認識チャレンジでは、学習された補助モデルがオブジェクトの重みを正常に調整しました。オブジェクト: 新しい外観を持つオブジェクトの重量は増加し、古い外観を持つオブジェクトの重量は減少します。
勾配ベースの特徴重要度評価を通じて、補助モデルが背景や背景ではなく、画像内の被写体に焦点を当てていることがわかります。インスタンスの年齢に依存しない特性により、その有効性が証明されています。
大規模な写真分類タスクにおける大きな進歩
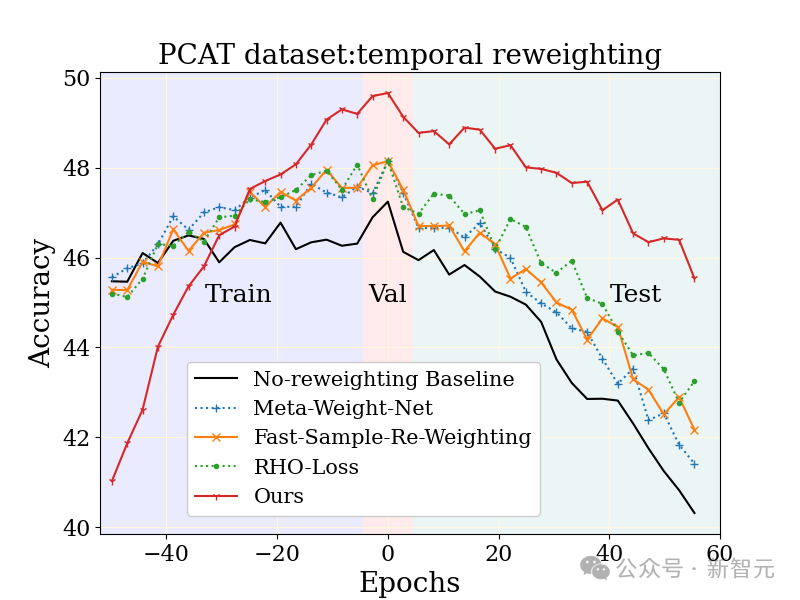
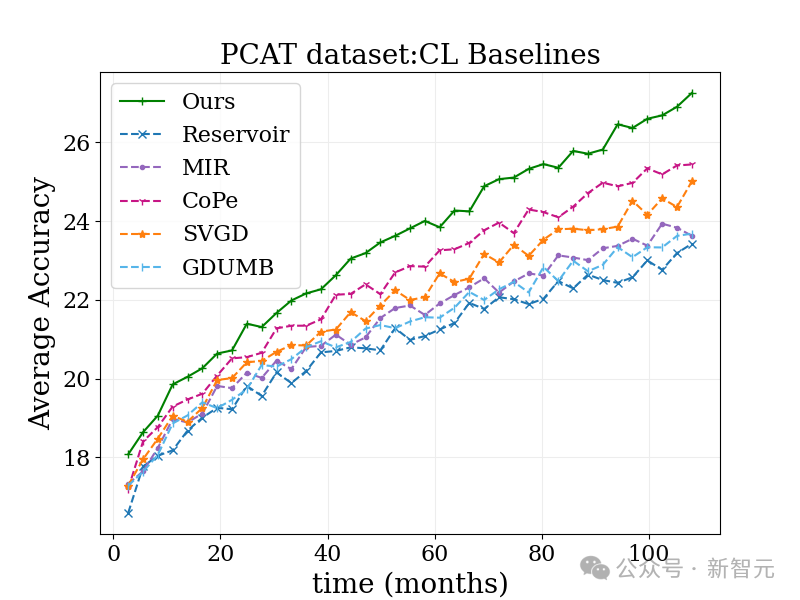
大規模な写真分類タスク写真分類タスク (PCAT) は、最初の 5 年間のデータをトレーニング セットとして使用し、最後の 5 年間のデータをテスト セットとして使用します。
重み付けされていないベースラインや他の堅牢な学習手法と比較して、MUSCATEL メソッドには明らかな利点があります。
#MUSCATEL メソッドでは、テスト中のパフォーマンスの大幅な向上と引き換えに、遠い過去のデータの精度を意識的に調整していることは注目に値します。 。この戦略は、モデルが将来のデータに適応する能力を最適化するだけでなく、テスト中の劣化が少ないことも示します。
データセット全体での広範なユーザビリティの検証
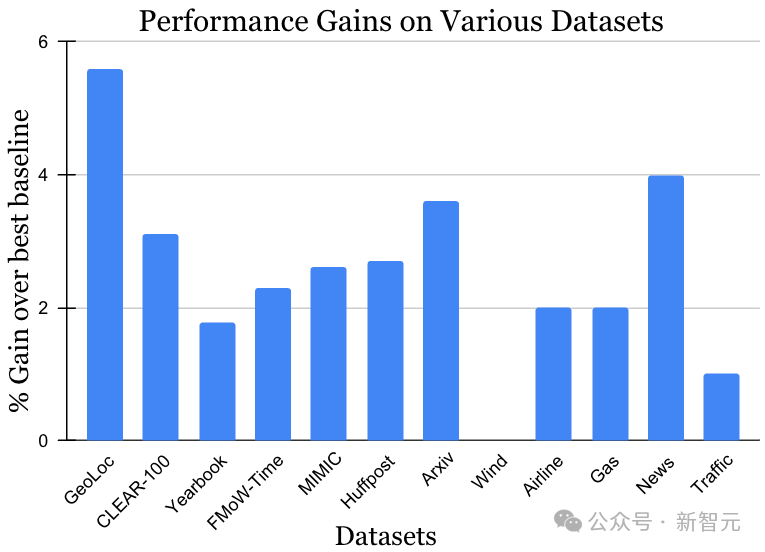
非定常学習課題のデータセットは、写真、衛星画像、ソーシャル メディアのテキスト、医療記録、センサーの読み取り値、表形式のデータなど、データ サイズも 10,000 インスタンスから 3,900 万インスタンスの範囲に及びます。以前の最良の方法はデータセットごとに異なる可能性があることに注意してください。ただし、以下の図に示すように、データと手法の両方における多様性という観点から、MUSCATEL 手法は顕著なゲイン効果を示しています。この結果は、MUSCATEL の幅広い適用可能性を十分に示しています。
#大規模なデータ処理の課題に対処するために継続学習アルゴリズムを拡張する
山に直面したとき大規模なデータを扱う場合、従来のオフライン学習方法では不十分だと感じるかもしれません。
この問題を念頭に置いて、研究チームは、大規模なデータの処理に簡単に適応できるように、継続学習にヒントを得た方法を巧みに採用しました。
この方法は非常に簡単で、データの各バッチに時間重みを追加し、モデルを順番に更新します。
モデルの更新は最新のデータにのみ基づいて行うことができるなど、これを行うにはまだいくつかの小さな制限がありますが、その効果は驚くほど良好です。
以下の写真分類ベンチマーク テストでは、この方法は従来の連続学習アルゴリズムやその他のさまざまなアルゴリズムよりも優れたパフォーマンスを示しました。
また、その考え方は既存の多くの手法とよくマッチするため、他の手法と組み合わせることでさらに驚くべき効果が期待できます。
# 全体として、研究チームはオフライン学習と継続学習をうまく組み合わせて、業界を長年悩ませてきたデータドリフト問題を解決しました。
この革新的な戦略は、モデルの「災害の忘却」現象を大幅に軽減するだけでなく、大規模データの継続学習の将来の開発に新しい道を切り開き、機械学習の分野全体に新たな方向性をもたらし、新たな活力を注入しました。

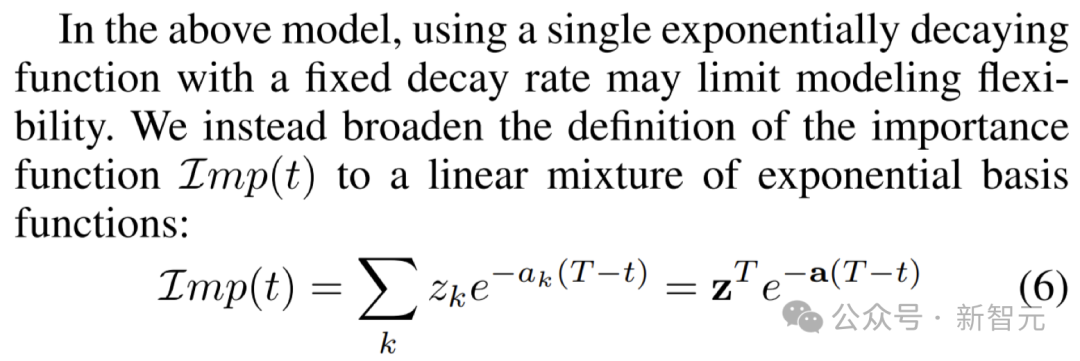


以上が「コンセプチュアルエレガンス」の問題と戦え! Google、新しい時間認識フレームワークをリリース:画像認識精度が15%向上の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。