
ホームページ >テクノロジー周辺機器 >AI >1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い
1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違い

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-03-02 11:19:301436ブラウズ
今日の急速な技術変化の波の中で、人工知能 (AI)、機械学習 (ML)、ディープラーニング (DL) は輝かしい星のような存在であり、情報テクノロジーの新たな波をリードしています。これら 3 つの単語は、さまざまな最先端の議論や実践で頻繁に登場しますが、この分野に慣れていない多くの探検家にとって、その具体的な意味や内部のつながりはまだ謎に包まれているかもしれません。
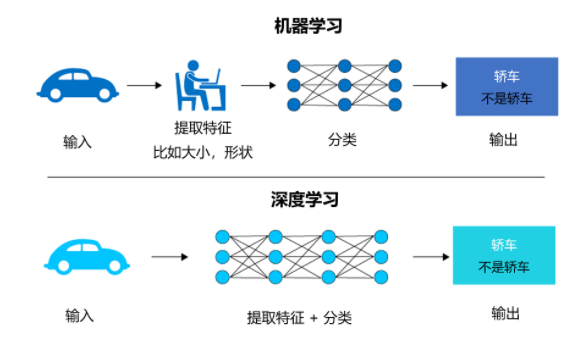
まずこの写真を見てみましょう。

ディープラーニング、機械学習、人工知能の間には密接な相関関係があり、進歩的な関係があることがわかります。ディープラーニングは、人工知能の重要なコンポーネントである機械学習の特定の分野です。これらの分野間のつながりと相互促進により、人工知能技術の継続的な開発と改善が可能になります。
人工知能とは何ですか?
人工知能 (AI) は広範な概念であり、その主な目標は、人間の知能をシミュレート、拡張、さらにはそれを超えることができるコンピューティング システムを開発することです。
- 画像認識 (画像認識) は AI の重要な分野であり、コンピューターが視覚センサーを通じてデータを取得し、実行できるようにする方法の研究に特化しています。人間の目や脳による視覚信号の認識・理解プロセスをシミュレートし、画像内の物体、シーン、動作などの情報を識別するための分析。
- 自然言語処理 (NLP) は、人間の自然言語を理解して生成するコンピューターの能力です。テキスト分類、意味分析、機械翻訳などのさまざまなタスクをカバーし、人間の自然言語をシミュレートすることを目指しています。読み書きにおける知的な行動について話します。
- Computer Vision (CV) は、広義の画像認識を含み、画像解析、ビデオ解析、三次元再構成なども含み、コンピュータが二次元または三次元から情報を抽出できるようにすることを目的としています。世界を「見て」理解することは、人間の視覚システムを深く模倣したものです。
- ナレッジ グラフ (KG) は、エンティティとそれらの相互の複雑な関係を保存および表現するために使用される構造化データ モデルであり、認知プロセスにおける人間の知識の蓄積と発展をシミュレートします。事前知識に基づいて推論し学習するプロセス。
これらのハイエンドテクノロジーは、「人間の知能をシミュレートする」という中心概念を中心に研究され、応用されています。彼らは、さまざまな知覚次元(視覚、聴覚、思考ロジックなど)の開発に焦点を当てており、人工知能技術の継続的な開発と進歩を共同で推進しています。
機械学習とは何ですか?
機械学習 (ML) は、人工知能 (AI) の分野における重要な分野です。さまざまなアルゴリズムを使用して、コンピューター システムがデータからルールとパターンを自動的に学習して予測と決定を行えるようにし、それによって人間の知能の能力を強化および拡張します。
たとえば、猫認識モデルをトレーニングする場合、機械学習プロセスは次のとおりです。
- データの前処理: まず、収集した大量の猫と猫以外の写真を前処理します。スケーリング、グレースケール、正規化、その他の操作を含む処理、および画像の特徴ベクトル表現への変換。これらの特徴は、Haar 様特徴、ローカル バイナリ パターン (LBP)、または特徴記述子など、手動で設計された特徴抽出技術から取得される場合があります。他のコンピュータビジョン分野で一般的に使用されます。
- 特徴の選択と次元削減: 問題の特性に従って主要な特徴を選択し、冗長で無関係な情報を削除し、場合によっては PCA、LDA、およびその他の次元削減手法を使用して、特徴の次元をさらに削減し、アルゴリズムの効率を向上させます。
- モデル トレーニング: 次に、前処理されたラベル付きデータ セットを使用して選択した機械学習モデルをトレーニングし、モデルが特定の特徴を区別できるようにモデル パラメーターを調整してモデルのパフォーマンスを最適化します。 。
- モデルの評価と検証: トレーニングが完了した後、独立したテスト セットを使用してモデルが評価され、モデルが良好な汎化能力を備えており、新しい未確認のサンプルに正確に適用できることが確認されます。
一般的に使用される機械学習アルゴリズムのトップ 10 は次のとおりです: デシジョン ツリー、ランダム フォレスト、ロジスティック回帰、SVM、単純ベイズ、K 最近傍アルゴリズム、K 平均法アルゴリズム、Adaboost アルゴリズム、ニューラル ネットワーク、Marrコフら。
ディープラーニングとは何ですか?
ディープ ラーニング (DL) は機械学習の特殊な形式で、人間の脳がディープ ニューラル ネットワーク構造を通じて情報を処理する方法をシミュレートし、データから複雑な特徴表現を自動的に抽出します。
たとえば、猫認識モデルをトレーニングする場合、深層学習プロセスは次のとおりです。
(1) データの前処理と準備:
- 大量のデータを収集します。猫と猫以外の画像を含むデータセット。各画像に対応するラベル (「猫」または「猫以外」など) が付けられるようにクリーニングおよび注釈が付けられます。
- 画像前処理: すべての画像を均一なサイズに調整し、正規化処理、データ補正などの操作を実行します。
(2) モデルの設計と構築:
- ディープ ラーニング アーキテクチャを選択する: 画像認識タスクには、通常、畳み込みニューラル ネットワーク (CNN) が使用されます。 CNN は、画像の局所的な特徴を効果的に抽出し、多層構造を通じてそれらを抽象化できます。
- 畳み込み層 (特徴抽出用)、プーリング層 (計算量を削減し、過学習を防止するため)、全結合層 (特徴を統合および分類するため)、および可能なバッチ削減を含むモデル階層を構築する層、活性化関数 (ReLU、シグモイドなど)。
(3) 初期化パラメータとハイパーパラメータの設定:
- モデル内の各層の重みとバイアスを初期化するには、ランダム初期化または特定の初期化戦略を使用できます。 。
- 学習率、オプティマイザー (SGD、Adam など)、バッチ サイズ、トレーニング期間 (エポック) などのハイパーパラメーターを設定します。
(4) 順伝播:
- 前処理した画像をモデルに入力し、各層で畳み込み、プーリング、線形変換などの演算を行い、最後に出力層の予測確率分布、つまりモデルが入力画像が猫であると判断する確率を取得します。
(5) 損失関数と逆伝播:
- クロスエントロピー損失関数またはその他の適切な損失関数を使用して、モデルの予測結果と実際の予測結果との差を測定します。ラベルの違い。
- 損失を計算した後、バックプロパゲーションアルゴリズムを実行してモデルパラメータに対する損失の勾配を計算し、パラメータを更新します。
(6) 最適化とパラメーターの更新:
- 損失関数を最小限に抑える目的で、勾配降下法またはその他の最適化アルゴリズムを使用して、勾配情報に基づいてモデル パラメーターを調整します。 。
- 各トレーニング反復中、モデルはパラメータの学習と調整を継続し、猫の画像を認識する能力を徐々に向上させます。
(7) 検証と評価:
- 検証セット上のモデルのパフォーマンスを定期的に評価し、精度、精度、再現率、およびその他の指標の変化を監視します。このガイドのハイパーパラメータはモデルのトレーニング中の調整と早期停止戦略。
(8) トレーニングの完了とテスト:
- 検証セット上のモデルのパフォーマンスが安定するか、事前に設定された停止条件に達したら、トレーニングを停止します。
- 最後に、独立したテスト セットでモデルの汎化能力を評価し、モデルが新しい未確認のサンプルで猫を効果的に識別できることを確認します。
以上が1 つの記事で理解: AI、機械学習、ディープラーニングのつながりと違いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。