


大規模言語モデル (LLM) は、複数の連鎖された生成呼び出し、高度なヒント技術、制御フロー、および外部環境との対話を必要とする複雑なタスクで広く使用されています。それにもかかわらず、これらのアプリケーションをプログラミングして実行するための現在の効率的なシステムには、重大な欠点があります。
研究者らは最近、LLM との対話性を向上させることを目的とした、SGLang と呼ばれる新しい構造化生成言語 (構造化生成言語) を提案しました。 SGLang は、バックエンド ランタイム システムの設計とフロントエンド言語を統合することにより、LLM のパフォーマンスを向上させ、制御を容易にします。この研究は、機械学習の分野で著名な学者であり、CMU 助教授である Chen Tianqi 氏によっても進められました。
一般に、SGLang の貢献には主に次のものが含まれます。
バックエンドでは、研究チームは、KV である RadixAttend を提案しました。キャッシュ (KV キャッシュ) テクノロジーは、複数の LLM 生成呼び出しにわたって自動かつ効率的に再利用されます。
フロントエンド開発では、チームは Python に埋め込んで生成プロセスを制御できる柔軟なドメイン固有言語を開発しました。この言語はインタプリタモードまたはコンパイラモードで実行できます。
バックエンド コンポーネントとフロントエンド コンポーネントは連携して、複雑な LLM プログラムの実行とプログラミングの効率を向上させます。
この調査では、SGLang を使用して、エージェント、推論、抽出、対話、少数ショット学習タスクなどの一般的な LLM ワークロードを実装し、NVIDIA A10G GPU で Llama-7B および Mixtral-8x7B モデルを採用しています。以下の図 1 と図 2 に示すように、SGLang のスループットは、既存のシステム (ガイダンスや vLLM) と比較して 5 倍増加しています。
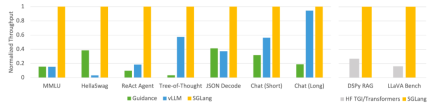
#図 1: LLM タスクにおけるさまざまなシステムのスループット (A10G、FP16 上の Llama-7B、テンソル並列処理 = 1)
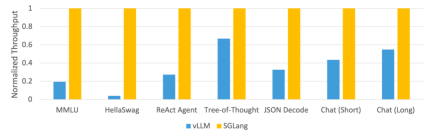
図 2: LLM タスクにおけるさまざまなシステムのスループット (A10G、FP16、Zhang の Mixtral-8x7B 並列処理量 = 8)
バックエンド: KV キャッシュの自動再利用に RadixAttendance を使用する
SGLang ランタイムの開発プロセス中に、調査では、複雑な LLM を最適化するための鍵となることが判明しました。プログラムは KV キャッシュの再利用ですが、現在のシステムではうまく処理できません。 KV キャッシュの再利用とは、同じプレフィックスを持つ異なるプロンプトが中間 KV キャッシュを共有できることを意味し、冗長なメモリと計算を回避します。複数の LLM 呼び出しを伴う複雑なプログラムでは、KV キャッシュのさまざまな再利用モードが存在する場合があります。以下の図 3 は、LLM ワークロードで一般的に見られる 4 つのパターンを示しています。一部のシステムは特定のシナリオで KV キャッシュの再利用を処理できますが、多くの場合、手動の構成とアドホックな調整が必要になります。さらに、考えられる再利用パターンは多様であるため、既存のシステムは手動構成であってもすべてのシナリオに自動的に適応することはできません。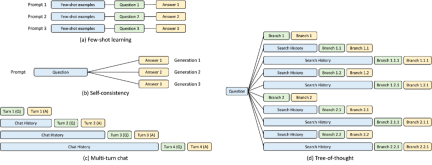
#図 3: KV キャッシュ共有の例。青いボックスは共有可能なプロンプト部分、緑のボックスは共有不可能な部分、黄色のボックスは共有不可能なモデル出力です。共有可能な部分には、小規模な学習例、自己一貫性に関する質問、複数回の対話にわたる会話履歴、および思考ツリーでの検索履歴が含まれます。
これらの再利用の機会を体系的に活用するために、この研究では、実行時に KV キャッシュを自動的に再利用する新しい方法である RadixAttendance を提案します。このメソッドは、ビルド リクエストの完了後に KV キャッシュを破棄するのではなく、プロンプトとビルド結果の KV キャッシュを基数ツリーに保持します。このデータ構造により、効率的なプレフィックス検索、挿入、削除が可能になります。この調査では、最も長く使用されていない (LRU) エビクション ポリシーを実装し、キャッシュ ヒット率を向上させるためにキャッシュを意識したスケジューリング ポリシーを追加しています。 基数ツリーは、トライ (接頭辞ツリー) の省スペースな代替手段として使用できます。一般的なツリーとは異なり、基数ツリーのエッジは単一の要素だけでなく、異なる長さの要素のシーケンスでもマークできるため、基数ツリーの効率が向上します。 この研究では、基数ツリーを利用して、キーとして機能するトークン シーケンスと、値として機能する対応する KV キャッシュ テンソル間のマッピングを管理します。これらの KV キャッシュ テンソルは、ページ レイアウトで GPU に保存されます。各ページはトークンのサイズです。 GPU メモリ容量が限られており、無制限の KV キャッシュ テンソルを再トレーニングできないことを考慮すると、エビクション戦略が必要です。この研究では、LRU エビクション戦略を採用して、リーフ ノードを再帰的にエビクトします。さらに、RadixAttention は、連続バッチ処理やページ単位のアテンションなどの既存のテクノロジーと互換性があります。マルチモーダル モデルの場合、RADIXATTENTION を簡単に拡張してイメージ トークンを処理できます。下の図は、複数の受信リクエストを処理するときに基数ツリーがどのように維持されるかを示しています。フロントエンドは常に完全なプロンプトをランタイムに送信し、ランタイムはプレフィックスの一致、再利用、およびキャッシュを自動的に実行します。ツリー構造は CPU に保存されるため、メンテナンスのオーバーヘッドが低くなります。
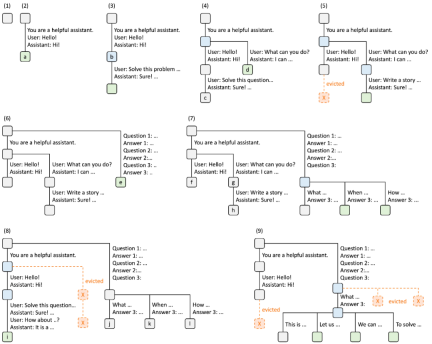
図 4. LRU エビクション ポリシーを使用した RadixAttendant 操作の例 (9 つのステップで示されています)。
図 4 は、さまざまなリクエストに応じて基数ツリーが動的に進化する様子を示しています。これらのリクエストには、2 つのチャット セッション、少数ショットの学習クエリのバッチ、および自己一貫性のあるサンプリングが含まれます。ツリーの各エッジには、トークンの部分文字列またはシーケンスを表すラベルがあります。ノードはさまざまな状態を反映するために色分けされています。緑は新しく追加されたノードを示し、青はその時点でアクセスされたキャッシュされたノードを示し、赤は削除されたノードを示します。
フロントエンド: SGLang で LLM プログラミングが簡単に
フロントエンドでは、この研究では、高度なプロンプトの表現を可能にする Python に埋め込まれたドメイン固有言語である SGLang を提案しています。技術、制御フロー、マルチモダリティ、制約のデコード、および外部インタラクション。 SGLang 関数は、OpenAI、Anthropic、Gemini、ネイティブ モデルなどのさまざまなバックエンドを通じて実行できます。
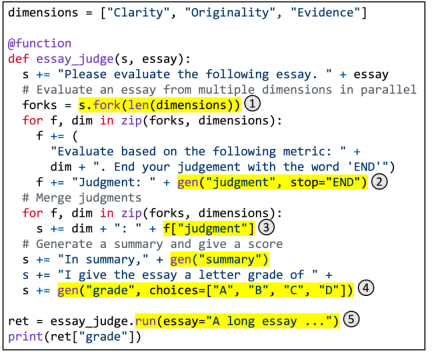
#図 5. SGLang を使用した多次元記事スコアリングの実装。 #図 5 に具体的な例を示します。ブランチ解決マージプロンプトテクノロジーを利用して、多次元の記事スコアリングを実現します。この機能は、LLM を使用して複数の側面に沿って記事の品質を評価し、判断を組み合わせて要約を生成し、最終的な評点を割り当てます。強調表示された領域は、SGLang API の使用法を示しています。 (1) fork はプロンプトの複数の並列コピーを作成します。 (2) gen は LLM 生成を呼び出し、結果を変数に格納します。この呼び出しは非ブロッキングであるため、複数のビルド呼び出しをバックグラウンドで同時に実行できます。 (3) [変数名] は生成された結果を取得します。 (4) 世代に制約を課すことを選択します。 (5) run はパラメータを使用して SGLang 関数を実行します。
このような SGLang プログラムがある場合、インタプリタを通じて実行することも、データ フロー グラフとしてトレースしてグラフ エグゼキュータを使用して実行することもできます。後者の場合、コードの移動、命令の選択、自動チューニングなどの潜在的なコンパイラ最適化のためのスペースが広がります。
SGLang の構文はガイダンスから大きく影響を受けており、新しいプリミティブが導入されており、プロシージャ内の並列処理やバッチ処理も処理されます。これらすべての新機能は、SGLang の優れたパフォーマンスに貢献します。
ベンチマーク研究チームは、一般的な LLM ワークロードでシステムをテストし、達成されたスループットを報告しました。
具体的には、この調査では、FP16 精度を使用したテンソル並列処理により、1 台の NVIDIA A10G GPU (24GB) で Llama-7B と 8 台の NVIDIA A10G GPU で Mixtral-8x7B をテストしました。また、vllm v0.2.5、ガイダンス v0.1.8、およびベースライン システムとして Hugging Face TGI v1.3.0。
図 1 と 2 に示すように、SGLang はすべてのベンチマークでベースライン システムを上回り、スループットが 5 倍向上しました。また、レイテンシー、特に最初のトークンのレイテンシーに関しても優れたパフォーマンスを発揮し、プレフィックス キャッシュ ヒットが大きな利点をもたらす可能性があります。これらの改善は、RadixAttendant の KV キャッシュの自動再利用、インタプリタによって可能になるプログラム内並列処理、およびフロントエンド システムとバックエンド システムの共同設計によるものです。さらに、アブレーション研究では、キャッシュ ヒットがない場合でも、実行時に RadixAttendance が常に有効になるような重大なオーバーヘッドがないことが示されています。
参考リンク: https://lmsys.org/blog/2024-01-17-sglang/
以上がスループットが5倍に向上 バックエンドシステムとフロントエンド言語を共同設計するためのLLMインターフェースが登場。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム
 AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM
AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM主要なエンタープライズ分析プラットフォームAlteryxのCEOであるAndy Macmillanとの私の最近の会話は、AI革命におけるこの重要でありながら過小評価されている役割を強調しました。 MacMillanが説明するように、生のビジネスデータとAI-Ready情報のギャップ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

WebStorm Mac版
便利なJavaScript開発ツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

Dreamweaver Mac版
ビジュアル Web 開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

