

Google の 10M コンテキスト ウィンドウが RAG を破壊している?ジェミニはソラに脚光を奪われたことで過小評価されているのでしょうか?

最近最も憂鬱な会社と言われるには、Google もその 1 つであるに違いありません。自社の Gemini 1.5 リリース直後、AI業界の「王鳳」ともいえるOpenAIのSora社に盗まれてしまいました。
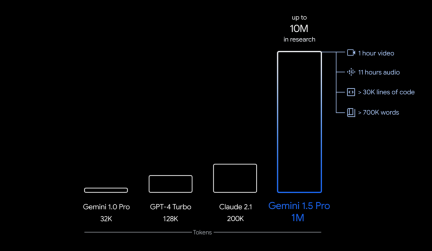
具体的には、Google が今回リリースしたのは、初期テスト用の Gemini 1.5 の最初のバージョンである Gemini 1.5 Pro です。これは、Google のこれまでで最大のモデルである 1.0 Ultra と同様のパフォーマンス レベルを備えた中規模のマルチモーダル モデル (テキスト、ビデオ、オーディオにわたる) であり、長期コンテキストの理解における画期的な実験的機能が導入されています。最大 100 万トークン (1 時間のビデオ、11 時間のオーディオ、30,000 行を超えるコード、または 700,000 ワードに相当) を安定して処理できますが、制限は 1,000 万トークン (「ロード・オブ・ザ・リング」に相当) " trilogy)、最長コンテキスト ウィンドウの記録を樹立しました。
さらに、500 ページの文法書、2,000 の対訳項目、および 400 の追加の対訳文だけで学習できます。言語(インターネット上に関連情報はありません)は、翻訳の点で人間の学習者に近いレベルに達しています。
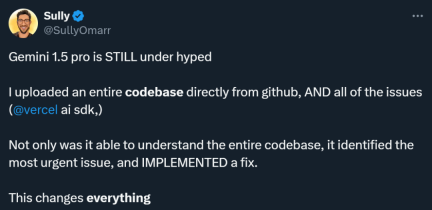
Gemini 1.5 Pro を使用したことのある多くの人は、このモデルが過小評価されていると考えています。誰かが実験を行い、Github からダウンロードした完全なコード ベースと関連する問題を Gemini 1.5 Pro に入力しました。結果は驚くべきものでした。コード ベース全体を理解しただけでなく、最も緊急な問題を特定して修正することもできました。 . .
別のコード関連のテストでは、Gemini 1.5 Pro はコード ベース内で最も関連性の高いサンプルをすばやく見つけることができる優れた検索機能を実証しました。さらに、深い理解を示し、アニメーションを制御するコードを正確に見つけて、パーソナライズされたコードの提案を提供することができます。同様に、Gemini 1.5 Pro は優れたクロスモード機能も実証しており、スクリーンショットを通じてデモ コンテンツを正確に特定でき、画像コードを編集するためのガイダンスを提供できます。

# このようなモデルはみんなの注目を集めるはずです。さらに、Gemini 1.5 Pro の超長いコンテキストを処理できる能力により、多くの研究者が従来の RAG 手法は依然として必要なのかと考え始めたことも注目に値します。
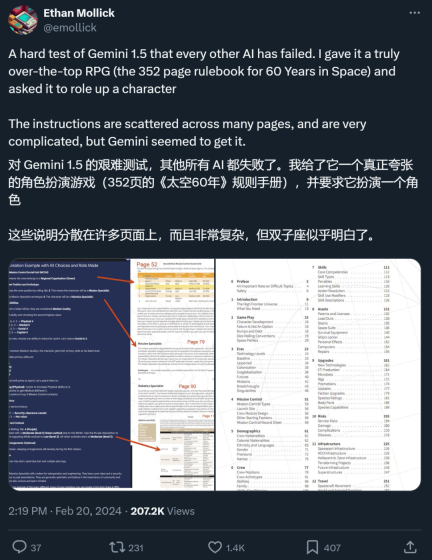
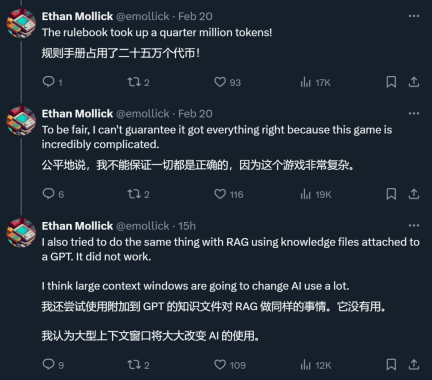
ある X ネチズンは、彼が実施したテストで、Gemini は超長いコンテキストをサポートする 1.5 であると述べました。確かに、Pro は RAG ではできないことを実現します。
RAG はロング コンテキスト モデルによって強制終了されますか?
「1,000 万のトークン コンテキスト ウィンドウを持つモデルでは、既存の RAG フレームワークのほとんどが不要になります。つまり、1,000 万のトークン コンテキストが RAG を無効にします。」エディンバラ氏は、Gemini 1.5 Pro を評価する投稿で次のように書いています。

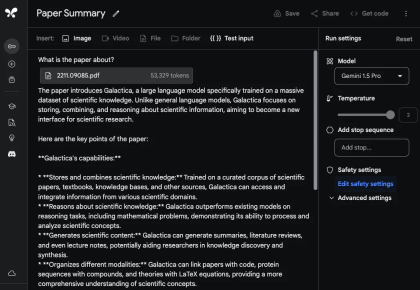
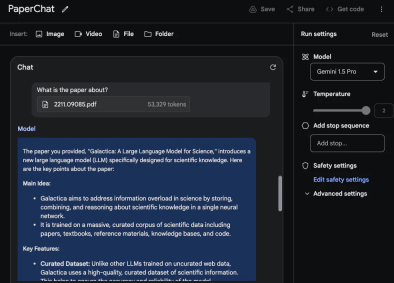
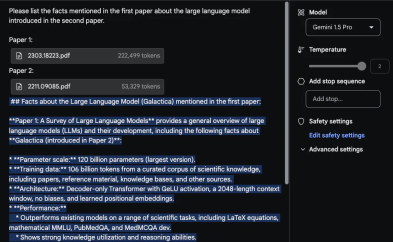
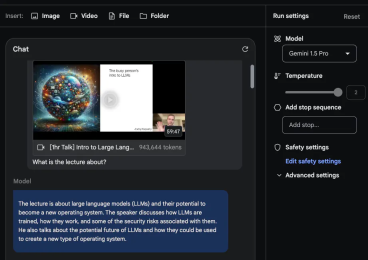
RAG は「Retrieval-Augmented Generation」の略称で、中国語に訳すと「検索強化世代」となります。 RAG は通常、コンテキスト関連情報の取得と、取得した知識を使用した生成プロセスのガイドという 2 つの段階で構成されます。たとえば、従業員として、「従業員ハンドブック」を読まずに、大手モデルに「うちの会社では遅刻に対する罰則は何ですか?」と直接質問しても、大手モデルは答える方法がありません。ただし、RAG メソッドの助けを借りて、最初に検索モデルで「従業員ハンドブック」の中で最も関連性の高い回答を検索させ、次に質問と見つかった関連性の高い回答を生成モデルに送信して、大規模なモデルを可能にすることができます。回答を生成します。これにより、以前の多くの大きなモデルのコンテキスト ウィンドウが十分に大きくない (たとえば、「従業員ハンドブック」を収容できない) という問題が解決されましたが、RAGfangfa ではコンテキスト間の微妙なつながりを捉えることができませんでした。 Fu Yao 氏は、モデルが 1,000 万個のトークンのコンテキスト情報を直接処理できれば、関連情報を見つけて統合するために追加の検索手順を実行する必要はないと考えています。ユーザーは、必要なすべてのデータをコンテキストとしてモデルに直接入力し、通常どおりモデルを操作できます。 「大規模な言語モデル自体がすでに非常に強力な検索機能を備えているのに、なぜわざわざ弱い検索機能を構築し、チャンク化、埋め込み、インデックス付けなどに多くのエンジニアリングエネルギーを費やす必要があるのでしょうか?」と彼は書き続けました。 #しかし、フーヤオの見解は多くの研究者によって反論されています。彼は、反対意見の多くは合理的であると述べ、また、これらの意見を体系的に整理しました: 1. コストの問題: 批評家は、RAG がロング コンテキスト モデルよりも安価であると指摘しています。傅耀氏はこれを認めたが、さまざまなテクノロジーの開発の歴史を比較し、低コストモデル(BERT-smallやn-gramなど)は確かに安いが、AI開発の歴史の中では先進テクノロジーのコストははるかに高いと指摘した。最終的には減ります。同氏の主張は、まずスマートモデルの性能を追求し、その後技術の進歩によってコストを削減するというものだ。なぜなら、安価なモデルをスマートにするよりも、スマートモデルを安くする方がはるかに簡単だからである。 #2. 検索と推論の統合: Fu Yao 氏は、ロング コンテキスト モデルでは復号化プロセス全体で検索と推論を組み合わせることができると強調しました。 RAG のみ開始時に取得します。長いコンテキストモデルは各レイヤーおよび各トークンで取得できるため、事前推論の結果に基づいて取得する情報を動的に決定することができ、検索と推論のより緊密な統合が実現されます。 3. サポートされるトークンの数: RAG によってサポートされるトークンの数は数兆に達していますが、ロング コンテキスト モデルは現在数百万をサポートしています。Fu Yao は、入力ドキュメント間で自然に分散されると考えています。 、取得する必要があるケースのほとんどは 100 万レベル未満です。同氏は例として法的文書の分析や機械学習を挙げ、これらの場合の入力量は数百万を超えることはないと信じていた。 #4. キャッシュ メカニズム: 長いコンテキスト モデルではドキュメント全体の再入力が必要になるという問題について、Fu Yao 氏は次のように指摘しました。いわゆる KV (キー値) キャッシュ メカニズム、複雑なキャッシュおよびメモリ階層は、入力を 1 回読み取るだけで済み、後続のクエリで KV キャッシュを再利用できるように設計できます。同氏はまた、KV キャッシュは大きくなる可能性があるものの、将来的には効率的な KV キャッシュ圧縮アルゴリズムが登場すると楽観的であると述べました。 5. 検索エンジンを呼び出す必要性: 彼は、短期的には、検索のために検索エンジンを呼び出すことが依然として必要であることを認めました。しかし、彼は、言語モデルが Google 検索インデックス全体に直接アクセスしてすべての情報を吸収するという大胆なアイデアを提案しました。これは、AI テクノロジーの将来性に対する大きな想像力を反映しています。 #6. パフォーマンスの問題: Fu Yao 氏は、現在の Gemini 1.5 は 1M コンテキストの処理が遅いことを認めていますが、高速化については楽観的であり、ロング コンテキスト モデルの速度は向上すると信じています。将来的には大幅に改善され、最終的には RAG と同等の速度に達する可能性があります。 Fu Yao に加えて、AI ブロガー @ など、他の多くの研究者も X プラットフォーム上の RAG の見通しについて意見を表明しています。エルヴィス。 全体として、彼はロング コンテキスト モデルが RAG に取って代わることができるとは考えていません。その理由は次のとおりです。 1. 具体的なデータタイプ 課題: @elvis は、データが複雑な構造を持ち、定期的に変更され、重要な時間次元 (コードの編集/変更や Web ログなど) を持つシナリオを提示しました。このタイプのデータは、過去のデータ ポイントに接続される可能性があり、将来的にはさらに多くのデータ ポイントに接続される可能性があります。 @elvis は、データが LLM には複雑すぎる可能性があり、そのようなデータには現在の最大コンテキスト ウィンドウが適用できないため、今日の長いコンテキスト言語モデルだけではそのようなデータに依存するユースケースを処理できないと考えています。この種のデータを扱う場合、最終的には何らかの賢い検索メカニズムが必要になる場合があります。 2. 動的情報の処理: 今日のロングコンテキスト LLM は、静的情報 (書籍、ビデオ録画、PDF など) の処理には優れていますが、高度に処理することは困難です。動的な情報や知識はまだ実際にはテストされていません。 @elvis は、いくつかの課題 (「途中で失われる」など) を解決し、より複雑な構造化された動的データを扱うことに向けて前進するだろうが、道のりはまだ長いと信じています。 3. @elvis は、この種の問題を解決するために、RAG とロング コンテキスト LLM を組み合わせて強力なシステムを構築できることを提案しました。重要な履歴情報を効果的かつ効率的に取得して分析します。同氏は、これでも多くの場合十分ではない可能性があると強調した。特に大量のデータは急速に変化する可能性があるため、AI ベースのエージェントではさらに複雑さが増します。 @elvis は、複雑なユースケースの場合、すべてを置き換える汎用または長いコンテキストの LLM ではなく、これらのアイデアの組み合わせになる可能性が高いと考えています。 4. さまざまなタイプの LLM の需要: @elvis さんは、すべてのデータが静的であるわけではなく、多くのデータは動的であると指摘しました。これらのアプリケーションを検討するときは、ビッグ データの 3 つの V、つまり速度、量、多様性に留意してください。 @elvis は、検索会社で働いた経験からこの教訓を学びました。彼は、さまざまな種類の LLM がさまざまな種類の問題の解決に役立つと信じており、1 つの LLM がすべてを支配するという考えから離れる必要があります。 @elvis は、Oriol Vinyals (Google DeepMind の研究担当副社長) の言葉を引用して締めくくり、現在でも 100 万件以上を処理できると指摘しました。トークンのコンテキストでは、RAG の時代はまだ終わっていません。実はRAGには非常に優れた機能がいくつかあります。これらのプロパティはロング コンテキスト モデルによって強化できるだけでなく、RAG によってもロング コンテキスト モデルを強化できます。 RAG を使用すると、関連情報を見つけることができますが、モデルがこの情報にアクセスする方法は、データ圧縮により制限されすぎる可能性があります。ロング コンテキスト モデルは、最新の CPU で L1/L2 キャッシュとメイン メモリが連携して動作する仕組みと似ており、このギャップを埋めるのに役立ちます。この協調モデルでは、キャッシュとメイン メモリがそれぞれ異なる役割を果たしますが、相互に補完し合うことで、処理速度と効率が向上します。同様に、RAG とロング コンテキストを組み合わせて使用すると、より柔軟で効率的な情報の取得と生成が実現し、それぞれの利点を最大限に活用して複雑なデータやタスクを処理できます。 「RAGの時代が終わるかどうか」はまだ決まっていないようです。しかし多くの人は、Gemini 1.5 Pro は非常に長いコンテキスト ウィンドウ モデルとして実際に過小評価されていると言っています。 @elvis もテスト結果を報告しました。 ##長いドキュメント分析機能 #Gemini 1.5 Pro のドキュメントの処理と分析能力を実証するために、@elvis は非常に基本的な質問に答えるタスクから始めました。彼は PDF ファイルをアップロードし、「この論文は何について書かれていますか?」という簡単な質問をしました。 モデルの応答は、ギャラクティカの論文の許容できる要約を提供するため、正確かつ簡潔です。上の例では Google AI Studio の自由形式のプロンプトを使用していますが、チャット形式を使用してアップロードされた PDF を操作することもできます。これは、提供されているドキュメントから回答を得たい質問がたくさんある場合に非常に便利な機能です。 長いコンテキスト ウィンドウを最大限に活用するために、@elvis は次にテスト用に 2 つの PDF をアップロードし、両方の PDF にまたがる質問をしました。 Gemini 1.5 Pro の応答は妥当です。興味深いことに、最初の論文 (LLM に関するレビュー論文) から抽出された情報は表から得られています。 「アーキテクチャ」情報も正しいようです。ただし、「パフォーマンス」の部分は最初の論文には含まれていなかったため、ここには含まれません。このタスクでは、「2 番目の論文で導入された大規模言語モデルについて、1 番目の論文で言及された事実を列挙してください」というプロンプトを先頭に置き、論文に「論文 1」「論文 2」などのラベルを付けることが重要です。 」。このラボに関連するもう 1 つのフォローアップ タスクは、一連の論文とその要約方法に関する指示をアップロードして、関連する作業を作成することです。もう 1 つの興味深いタスクは、レビューに新しい LLM 論文を含めるようモデルに要求しました。 #ビデオの理解
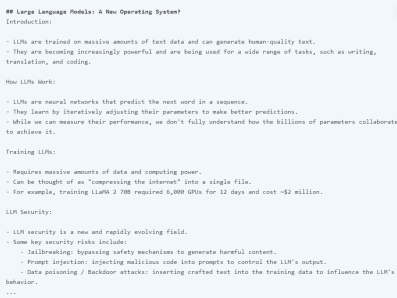
特定の詳細が重要な場合は、モデルがさまざまな理由で「幻覚」を示したり、誤った情報を取得したりする場合があることに注意してください。たとえば、モデルに「講義でラマ 2 について報告された FLOP は何ですか?」という質問をした場合、その答えは「講義では、ラマ 2 70B のトレーニングには約 1 兆 FLOP が必要であると報告されています」となり、これは不正確です。正解は「~1e24 FLOPs」です。技術レポートには、ビデオに関する特定の質問をされたときに、これらのロングコンテキスト モデルがつまずく例が多数含まれています。 次のタスクは、ビデオからテーブル情報を抽出することです。テスト結果は、モデルが正しい詳細と不正確な詳細を含むテーブルを生成できることを示しています。たとえば、テーブルの列は正しいが、行の 1 つのラベルが間違っています (つまり、Concept Resolution は Coref Resolution である必要があります)。テスターは、これらの抽出タスクの一部を他のテーブルや他の異なる要素 (テキスト ボックスなど) でテストし、同様の不一致を発見しました。 技術レポートに記載されている興味深い例の 1 つは、特定のシーンまたはタイムスタンプに基づいてビデオから詳細を取得するモデルの機能です。最初の例では、テスターはモデルに特定の部分がどこから始まるかを尋ねます。モデルさんは正解しました。
@elvis 氏は、テストの第 2 ラウンドを開始したと述べました。興味のある学生は X プラットフォームにアクセスして視聴することができます。 






Gemini 1.5 Pro 予備評価レポート
以上がGoogle の 10M コンテキスト ウィンドウが RAG を破壊している?ジェミニはソラに脚光を奪われたことで過小評価されているのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム
 AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM
AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM主要なエンタープライズ分析プラットフォームAlteryxのCEOであるAndy Macmillanとの私の最近の会話は、AI革命におけるこの重要でありながら過小評価されている役割を強調しました。 MacMillanが説明するように、生のビジネスデータとAI-Ready情報のギャップ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

メモ帳++7.3.1
使いやすく無料のコードエディター

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

