
ホームページ >テクノロジー周辺機器 >AI >LeCun 氏は、拡散モデルを使用してネットワーク パラメーターを生成し、You Yang チームの新しい研究を賞賛しています
LeCun 氏は、拡散モデルを使用してネットワーク パラメーターを生成し、You Yang チームの新しい研究を賞賛しています

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-02-26 08:10:03592ブラウズ
Sora によって生成されたビデオに衝撃を受けた人は、ビジュアル生成における拡散モデルの大きな可能性を理解していることになります。もちろん、普及モデルの可能性はこれにとどまらず、他の多くの分野への応用も期待されています。その他の事例については、当サイトの最新レポート「爆発空を支える技術」のレビューを参照してください。普及モデルの最新開発方向》。
最近、シンガポール国立大学、カリフォルニア大学バークレー校、およびメタ AI リサーチの You Yang チームによって実施された研究により、ニューラル ネットワークのモデル パラメーターの生成に使用される拡散モデルの新しい用途が発見されました。

論文アドレス: https://arxiv.org/pdf/2402.13144.pdf
プロジェクトアドレス: https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
論文タイトル: Neural Network Diffusion
このアプローチにより、既存のニューラル ネットワークを使用して新しいモデルを簡単に生成できるようです。 Yann LeCun はこれを高く評価し、共有しています。生成されたモデルは、元のモデルのパフォーマンスを維持するだけでなく、それを超える可能性もあります。
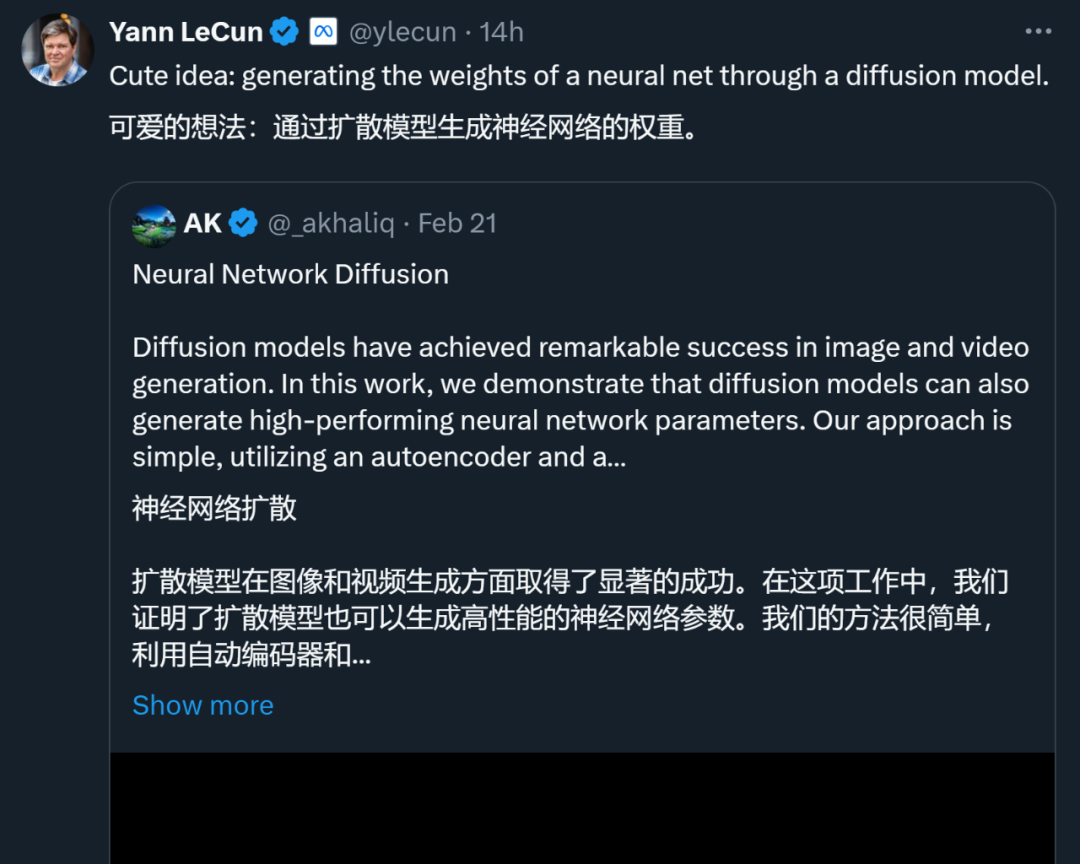
拡散モデルはもともと非平衡熱力学の概念から派生したものです。 2015 年、Jascha Sohl-Dickstein らは論文「非平衡熱力学を使用した深層教師なし学習」で初めて拡散プロセスを使用して入力から徐々にノイズを除去し、鮮明な画像を実現しました。
DDPM や DDIM などのその後の研究作業により、拡散モデルが最適化され、そのトレーニング パラダイムに順方向プロセスと逆方向プロセスの明確な特性が与えられました。
当時、拡散モデルによって生成される画像の品質はまだ理想的なものではありませんでした。
GuidedDiffusion この研究では、広範なアブレーション研究を実施し、より優れたアーキテクチャを発見しています。この先駆的な研究により、拡散モデルが画質において GAN ベースの手法を超えることが可能になり始めています。 GLIDE、Imagen、DALL・E 2、Stable Diffusion などの新しいモデルでは、すでにフォトリアリスティックな画像を生成できます。
拡散モデルは視覚生成の分野では大きな成功を収めていますが、他の分野ではその可能性は比較的十分に活用されていません。
シンガポール国立大学、カリフォルニア大学バークレー校、メタ AI リサーチによる最近の研究では、高性能モデル パラメーターを生成するという拡散モデルの驚くべき能力が発見されました。
このタスクは従来のビジュアル生成タスクとは根本的に異なることを知っておく必要があります。パラメーター生成タスクは、特定のタスクで適切に実行されるニューラル ネットワーク パラメーターを作成することに重点を置いています。研究者らはこれまでに、確率的ニューラル ネットワークやベイジアン ニューラル ネットワークなど、アプリオリかつ確率的モデリングの観点からこのタスクを研究してきました。しかし、これまで拡散モデルを使用してパラメータを生成することを研究した人はいませんでした。
図 1 に示すように、ニューラル ネットワークのトレーニング プロセスと拡散モデルを注意深く観察すると、拡散ベースの画像生成方法と確率的勾配降下 (SGD) 学習プロセスにはいくつかの点があることがわかります。共通: 1) ニューラルネットワーク 拡散モデルの学習過程とその逆過程はいずれもランダムノイズ/初期化から特定の分布への変換過程とみなすことができる; 2) ノイズを複数回追加することで、高画質な画像と高性能パラメータは、ガウス分布などの単純な分布に劣化させることができます。
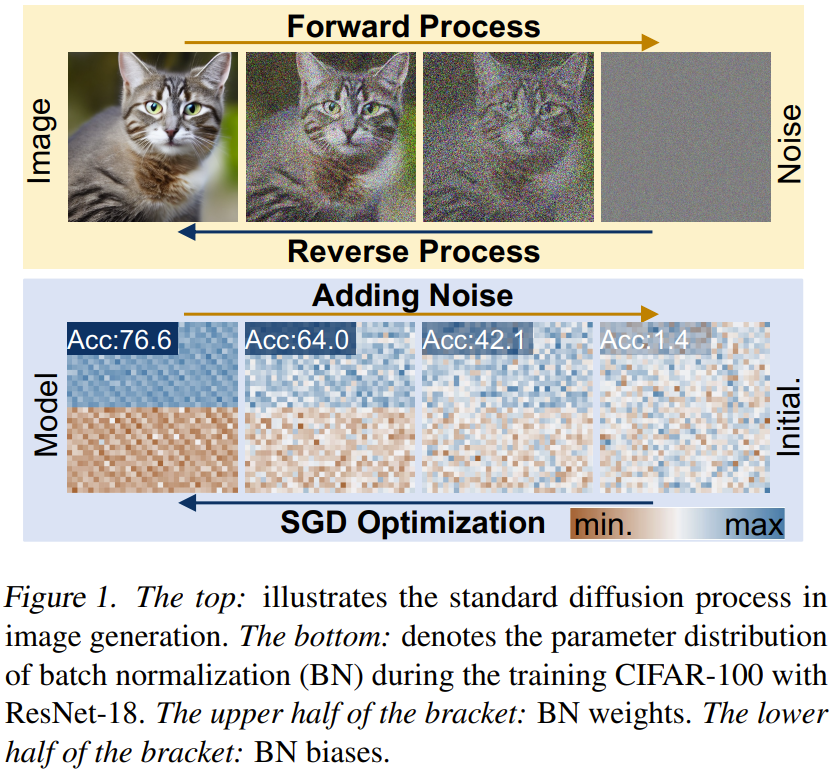
チームは、上記の観察に基づいてパラメータ生成の新しい方法、ニューラル ネットワーク拡散 (p-diff と略称) を提案しました。ここで、p はパラメータを指します。
この方法の考え方は非常に単純です。拡散モデルは特定のランダム分布を特定の分布に変換できるため、標準の暗黙的拡散モデルを使用してニューラル ネットワークのパラメーター セットを合成します。 。
彼らのアプローチはシンプルです。オートエンコーダーと標準の潜在拡散モデルを組み合わせて使用し、高性能のパラメーター分布を学習します。
まず、SGD オプティマイザーを使用してトレーニングされたモデル パラメーターのサブセットについて、これらのパラメーターの潜在表現を抽出するようにオートエンコーダーがトレーニングされます。次に、標準の潜在拡散モデルを使用して、ノイズから開始して潜在表現を合成します。最後に、トレーニングされたオートエンコーダーを使用して合成された潜在表現が処理され、新しい高性能モデル パラメーターが取得されます。
この新しいメソッドは、次の 2 つの特徴を示します。1) 複数のデータセットおよびアーキテクチャ上で、そのパフォーマンスは数秒以内にトレーニング データ (つまり、SGD オプティマイザーによってトレーニングされたモデル) に匹敵し、さらにはそれを上回ります。 2) 生成されたモデルはトレーニングされたモデルとはまったく異なります。これは、新しい方法がトレーニング サンプルを記憶する代わりに新しいパラメーターを合成できることを示しています。
ニューラル ネットワークの拡散
#拡散モデルの紹介
拡散モデルは通常、順方向プロセスと逆方向プロセスで構成されます。 、これらのプロセスは複数ステップのチェーンプロセスを形成し、タイムステップごとにインデックスを付けることができます。
転送プロセス。サンプル x_0 〜 q(x) が与えられると、順方向プロセスではガウス ノイズを T ステップで徐々に追加して、x_1、x_2...x_T を取得します。
逆のプロセス。順方向プロセスとは異なり、逆方向プロセスの目標は、x_t 内のノイズを再帰的に除去できるノイズ除去ネットワークをトレーニングすることです。このプロセスは複数のステップの逆であり、t は T から 0 まで減少します。
ニューラル ネットワーク拡散手法の概要
ニューラル ネットワーク拡散 (p-diff) この新しい手法の目標は、ランダム ノイズに基づいて高性能パラメータを生成することです。図 2 に示すように、このメソッドはパラメータ オートエンコーダとパラメータ生成の 2 つのプロセスで構成されます。
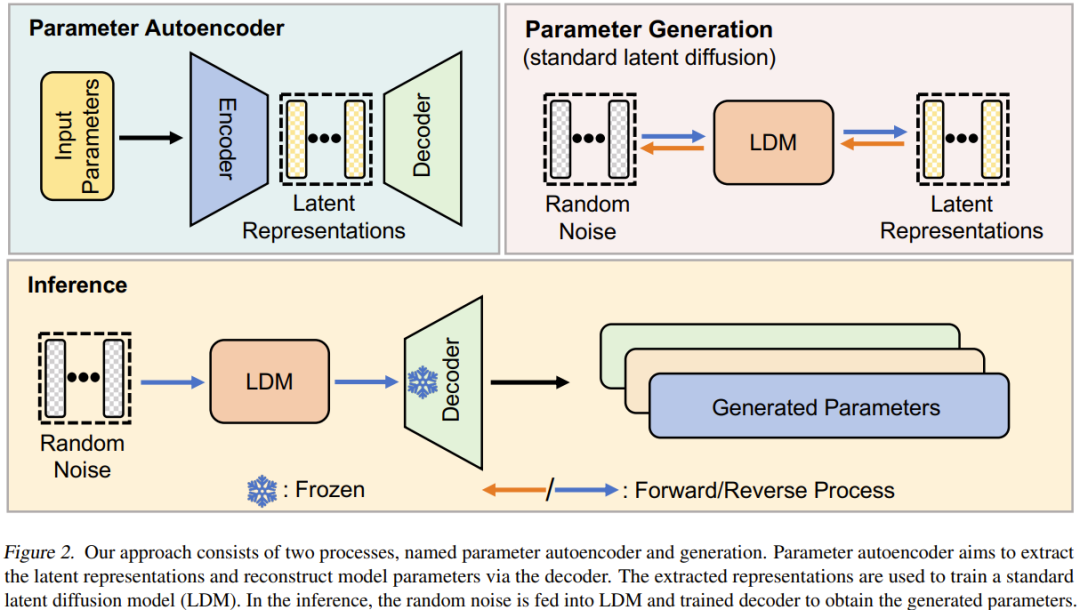
トレーニングされた高性能モデルのセットが与えられた場合、まずそのパラメーターのサブセットを選択し、それらを 1 次元ベクトルに平坦化します。
その後、エンコーダーを使用してこれらのベクトルの暗黙的表現が抽出され、デコーダーはこれらの暗黙的表現に基づいてパラメーターを再構築します。
次に、標準的な潜在拡散モデルがトレーニングされ、ランダム ノイズに基づいてこの潜在表現が合成されます。
トレーニング後、p-diff を使用して、ランダム ノイズ → 逆プロセス → トレーニングされたデコーダー → 生成されたパラメーターという連鎖プロセスを通じて新しいパラメーターを生成できます。
実験
チームは論文の中で詳細な実験設定を提供しており、他の研究者が結果を再現するのに役立ちます。詳細については、元の論文を参照してください。更新されます。その結果とアブレーション研究に焦点を当ててください。
結果
表 1 は、8 つのデータセットと 6 つのアーキテクチャにおける 2 つのベースライン手法による結果の比較です。

これらの結果に基づいて、次のことがわかります。 1) ほとんどの実験ケースでは、新しい方法は 2 つのベースライン方法と同等かそれ以上の結果を達成できます。これは、新しく提案された方法が高性能パラメータの分布を効率的に学習し、ランダムノイズに基づいてより良いモデルを生成できることを示しています。 2) 新しい方法は、複数の異なるデータセットに対して良好なパフォーマンスを示します。これは、この方法が良好な汎化パフォーマンスを備えていることを示しています。
アブレーションの研究と分析
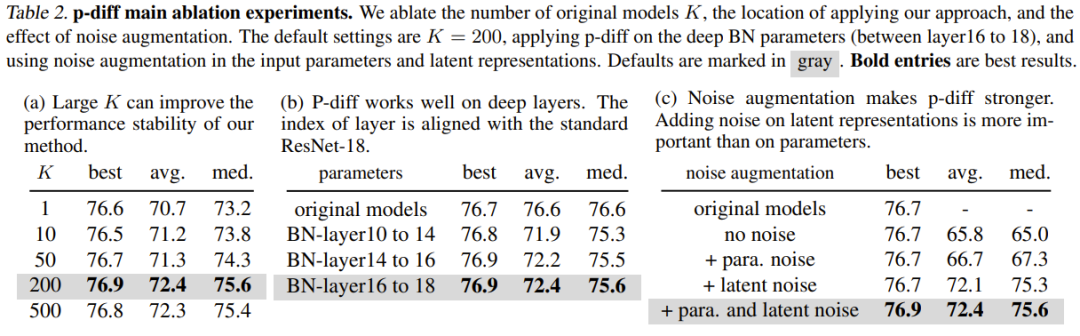
表 2(a) は、さまざまなトレーニング データ サイズ (つまり、トレーニング データの数) の結果を示しています。オリジナルモデル)の影響。ご覧のとおり、元のモデルの数が異なる場合の最良の結果間のパフォーマンスの差は、実際にはそれほど大きくありません。
他の正規化層の深さでの p-diff の有効性を研究するために、チームは他の浅いパラメータを合成するための新しい方法のパフォーマンスも調査しました。同数のBNパラメータを保証するために、チームは3セットのBN層(異なる深さの層の間に位置する)に対して新しく提案された方法を実装しました。実験結果を表 2(b) に示しますが、BN 層設定のすべての深さにおいて、新しい方法のパフォーマンス (最高の精度) が元のモデルのパフォーマンスより優れていることがわかります。
ノイズ強化の目的は、トレーニングされたオートエンコーダーの堅牢性と汎化能力を向上させることです。研究チームは、入力パラメータと暗黙的表現へのノイズ強調の適用に関するアブレーション研究を実施しました。結果を表2(c)に示す。
これまでに、モデル パラメーターのサブセット (つまり、バッチ正規化パラメーター) を合成する際の新しい方法の有効性を実験で評価しました。したがって、この方法を使用してモデルの全体的なパラメータを合成できるか?と尋ねずにはいられません。
この質問に答えるために、チームは 2 つの小さなアーキテクチャ、MLP-3 と ConvNet-3 を使用して実験を実施しました。このうち、MLP-3 には 3 つの線形層と ReLU 活性化関数が含まれ、ConvNet-3 には 3 つの畳み込み層と 1 つの線形層が含まれます。前述のトレーニング データ収集戦略とは異なり、チームは 200 の異なるランダム シードに基づいてこれらのアーキテクチャをゼロからトレーニングしました。
表 3 は、新しい方法と 2 つのベースライン方法 (元の方法およびアンサンブル方法) を比較した実験結果を示しています。 CIFAR-10/100 上の ConvNet-3 と、CIFAR-10 および MNIST 上の MLP-3 の結果とパラメータ数の比較を報告します。

これらの実験は、モデル パラメーター全体を合成する際の新しい方法の有効性と一般化能力を示しています。これは、新しい方法がベースライン方法と同等かそれ以上のパフォーマンスを達成することを意味します。 . .これらの結果は、新しい方法の実用的な応用可能性を実証することもできます。
しかし、チームは論文の中で、現時点では ResNet、ViT、ConvNeXt などの大規模なアーキテクチャの全体的なパラメータを合成することができないとも述べています。これは主に GPU メモリの制限によって制限されます。
なぜこの新しい方法が効果的にニューラル ネットワーク パラメーターを生成できるのかについて、チームはその理由を調査し分析しようとしました。彼らは、図 3 に示すように、3 つのランダム シードを使用して ResNet-18 をゼロからトレーニングし、そのパラメーターを視覚化しました。
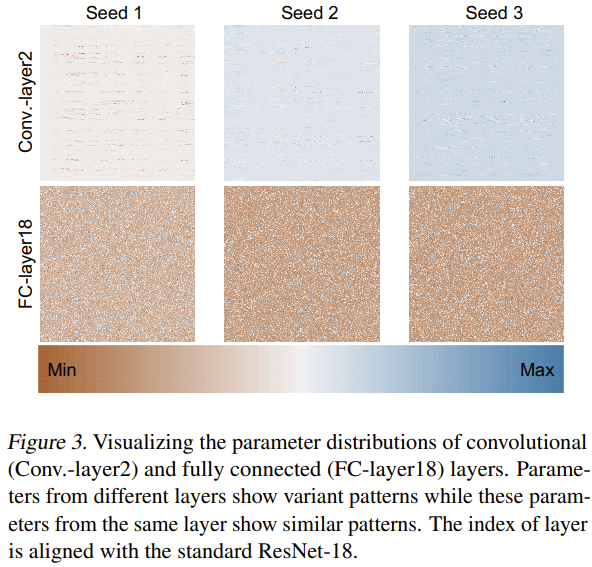
彼らは、最小-最大正規化法を通じて、さまざまな層のパラメータ分布のヒート マップを取得しました。畳み込み層 (Conv.-layer2) と全結合層 (FC-layer18) の視覚化結果に基づいて、特定のパラメーター パターンがこれらの層に存在することがわかります。これらのパターンを学習することで、新しい方法は高性能のニューラル ネットワーク パラメーターを生成できます。
p-diff それは純粋に記憶に基づいているのでしょうか?
p-diff はニューラルネットワークのパラメータを生成できるようですが、パラメータを生成するのでしょうか、それともパラメータを記憶するだけなのでしょうか?チームはこれについて調査を行い、元のモデルと生成されたモデルの違いを比較しました。
定量的な比較を行うために、彼らは類似性指数を提案しました。簡単に言うと、このインジケーターは、不正確な予測結果の交差対結合 (IoU) 比率を計算することにより、2 つのモデル間の類似性を判断します。次に、それに基づいていくつかの比較研究と視覚化を行いました。比較結果を図 4 に示します。
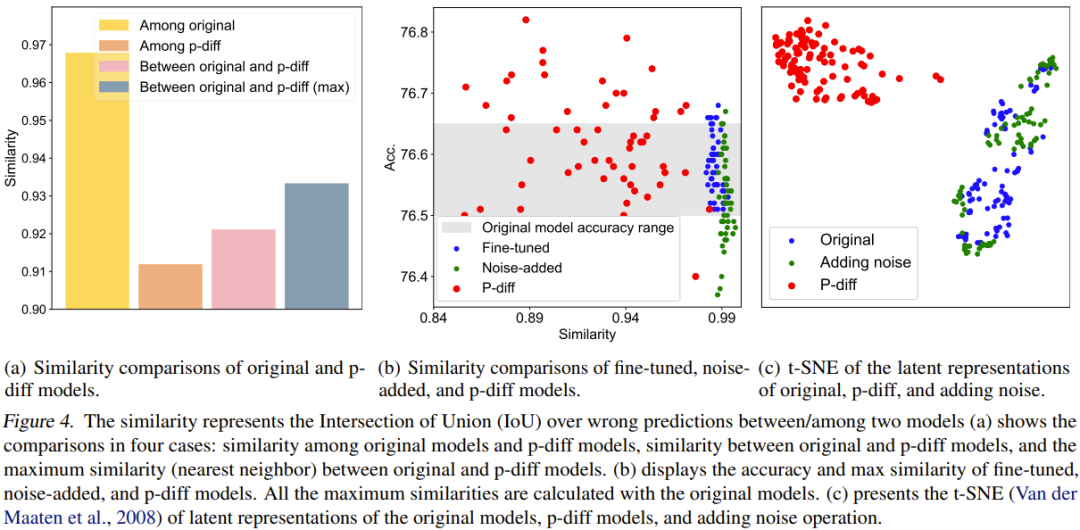
図 4(a) は、元のモデルと p-diff モデルの間の類似性の比較を示しています。これには 4 つの比較スキームが含まれます。
生成されたモデル間の差異は、元のモデル間の差異よりもはるかに大きいことがわかります。さらに、元のモデルと生成されたモデルの間の最大類似度も、元のモデル間の類似度よりも低くなります。これは、p-diff がトレーニング データ (つまり、元のモデル) とは異なる新しいパラメーターを生成できることを示すのに十分です。
チームはまた、新しい手法を、微調整されたモデルとノイズを追加したモデルと比較しました。結果を図 4(b)に示します。
微調整したモデルやノイズを加えたモデルではオリジナルモデルを超えるのは難しいことが分かります。さらに、微調整したモデルやノイズを追加したモデルと元のモデルとの類似性は非常に高く、これら 2 つの操作方法では完全に新しい高性能モデルを得ることができないことがわかります。ただし、新しい方法で生成されたモデルは、元のモデルよりもさまざまな類似点と優れたパフォーマンスを示します。
チームは暗黙的な表現も比較しました。結果を図 4(c) に示します。見てわかるように、p-diff は完全に新しい潜在表現を生成できますが、ノイズを追加するメソッドは元のモデルの潜在表現の周りを補間するだけです。
チームはまた、p-diff プロセスの軌跡を視覚化しました。具体的には、推論段階のさまざまなタイムステップで生成されたパラメーターの軌跡をプロットしました。図 5(a) は 5 つの軌跡を示しています (5 つの異なるランダム ノイズ初期化を使用)。図の赤い中央は元のモデルの平均パラメータ、灰色の領域はその標準偏差 (std) です。
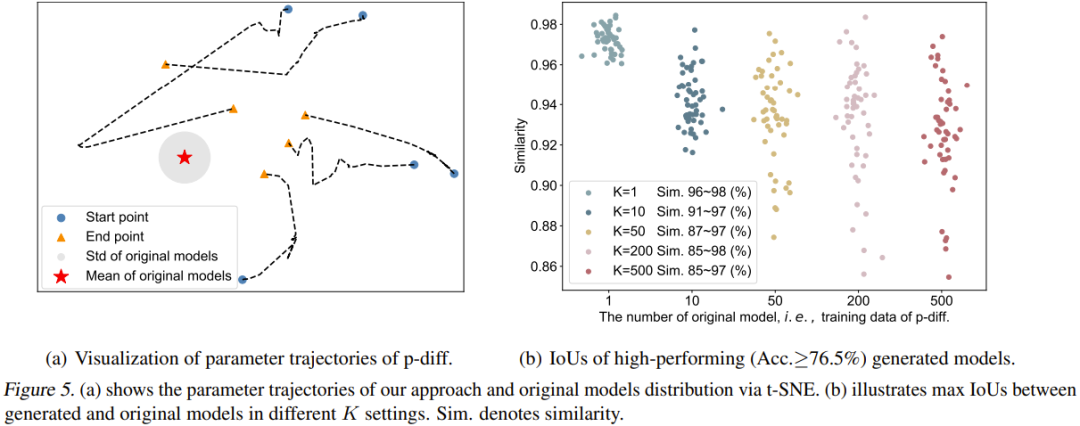
#タイム ステップが増加するにつれて、生成されるパラメーターは全体として元のモデルに近づきます。ただし、これらの軌跡の終点 (オレンジ色の三角形) が平均パラメータからまだある程度の距離があることもわかります。さらに、これら 5 つの軌道の形状も非常に多様です。
最後に、チームは、生成されたモデルの多様性に対する元のモデルの数 (K) の影響を研究しました。図 5(b) は、異なる K に対する元のモデルと生成されたモデルの間の最大の類似性を視覚的に示しています。具体的には、生成された 50 個のモデルのパフォーマンスがすべてのケースで 76.5% を超えるまでパラメーターの生成を続けることで、50 個のモデルを生成しました。
K=1の場合、類似度が非常に高く、範囲が狭いことがわかり、今回生成されたモデルは基本的に元のモデルのパラメータを記憶していることがわかります。 K が増加するにつれて、類似性の範囲も大きくなり、新しい方法が元のモデルとは異なるパラメーターを生成できることを示しています。
以上がLeCun 氏は、拡散モデルを使用してネットワーク パラメーターを生成し、You Yang チームの新しい研究を賞賛していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。