このロボットはキャシーと名付けられ、かつて 100 メートル走で世界記録を樹立しました。最近、カリフォルニア大学バークレー校の研究者は、このアルゴリズムのための新しい深層 強化学習 アルゴリズムを開発しました。これにより、急旋回などのスキルを習得し、さまざまな干渉に抵抗できるようになりました。
 #既に実行されている数十年かかりましたが、さまざまな運動能力の堅牢な制御を可能にする普遍的なフレームワークはまだありません。この課題は、二足歩行ロボットの作動不足のダイナミクスの複雑さと、各運動スキルに関連するさまざまな計画から生じます。
#既に実行されている数十年かかりましたが、さまざまな運動能力の堅牢な制御を可能にする普遍的なフレームワークはまだありません。この課題は、二足歩行ロボットの作動不足のダイナミクスの複雑さと、各運動スキルに関連するさまざまな計画から生じます。 研究者たちが解決したいと考えている重要な問題は、高次元の人間サイズの二足歩行ロボットのソリューションをどのように開発するかということです。歩く、走る、跳ぶなど、多様で機敏で堅牢な脚の動きのスキルをどのように制御するか?
#最近の研究が良い解決策を提供するかもしれません。 この研究では、バークレーやその他の機関の研究者が強化学習 (RL) を使用して、現実世界の高次元非線形二足歩行ロボットのコントローラーを作成し、上記の問題に対処しています。課題。これらのコントローラーは、ロボットの固有受容情報を活用して時間の経過とともに変化する不確実なダイナミクスに適応すると同時に、新しい環境や設定にも適応して、二足歩行ロボットの機敏性を活用して予期せぬ状況でも堅牢な動作を示すことができます。さらに、私たちのフレームワークは、さまざまな二足歩行スキルを再現するための一般的なレシピを提供します。 論文タイトル: 多用途、動的、堅牢な二足歩行制御のための強化学習
- 論文リンク:https://arxiv.org/pdf/2401.16889.pdf
論文詳細
#トルク制御される人間サイズの二足歩行ロボットの高次元性と非線形性は、コントローラーにとっては最初は障害になるように見えるかもしれませんが、これらの特性により、高度な制御を通じて複雑な実装が可能になるという利点があります。ロボットの次元ダイナミクス、機敏な動作。
#このコントローラーがロボットに与えるスキル (安定した立ち方、歩行、走行、ジャンプなど) を図 1 に示します。これらのスキルは、実際の展開時に堅牢性を維持しながら、さまざまな速度と高さで歩く、さまざまな速度と方向で走る、さまざまなターゲットにジャンプするなど、さまざまなタスクを実行するために使用することもできます。この目的を達成するために、研究者らはモデルフリー RL を使用して、ロボットがシステムのフルオーダー ダイナミクスを試行錯誤を通じて学習できるようにしています。実際の実験に加えて、脚の動きの制御に RL を使用する利点が詳細に分析され、適応性や堅牢性などの利点を活用するための学習プロセスを効果的に構築する方法が詳細に検討されます。
ユニバーサル二足歩行制御のための RL システムを図 2 に示します。 セクション 4 まず、モーション制御におけるロボットの I/O 履歴の利用について紹介し、このセクションでは、ロボットの長期 I/O 履歴が、制御と RL の両方の観点からリアルタイム制御プロセスにおけるシステムの同定と状態推定を実現できることを示します。 セクション 5 では、研究の核心である、二足歩行ロボットの長期および短期 I/O 二重履歴を利用した新しい制御アーキテクチャを紹介します。具体的には、この制御アーキテクチャはロボットの長期履歴だけでなく、短期履歴も活用します。
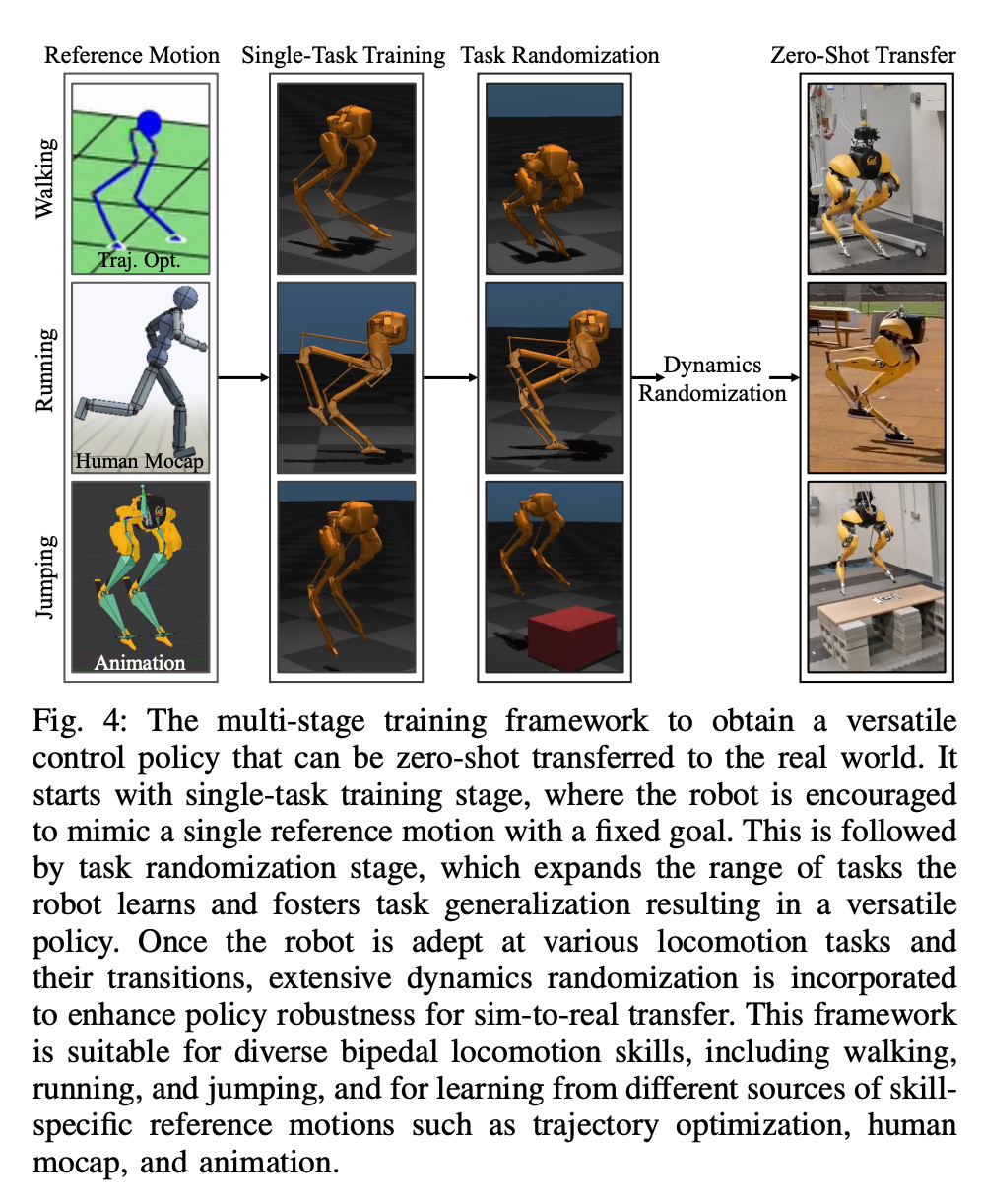
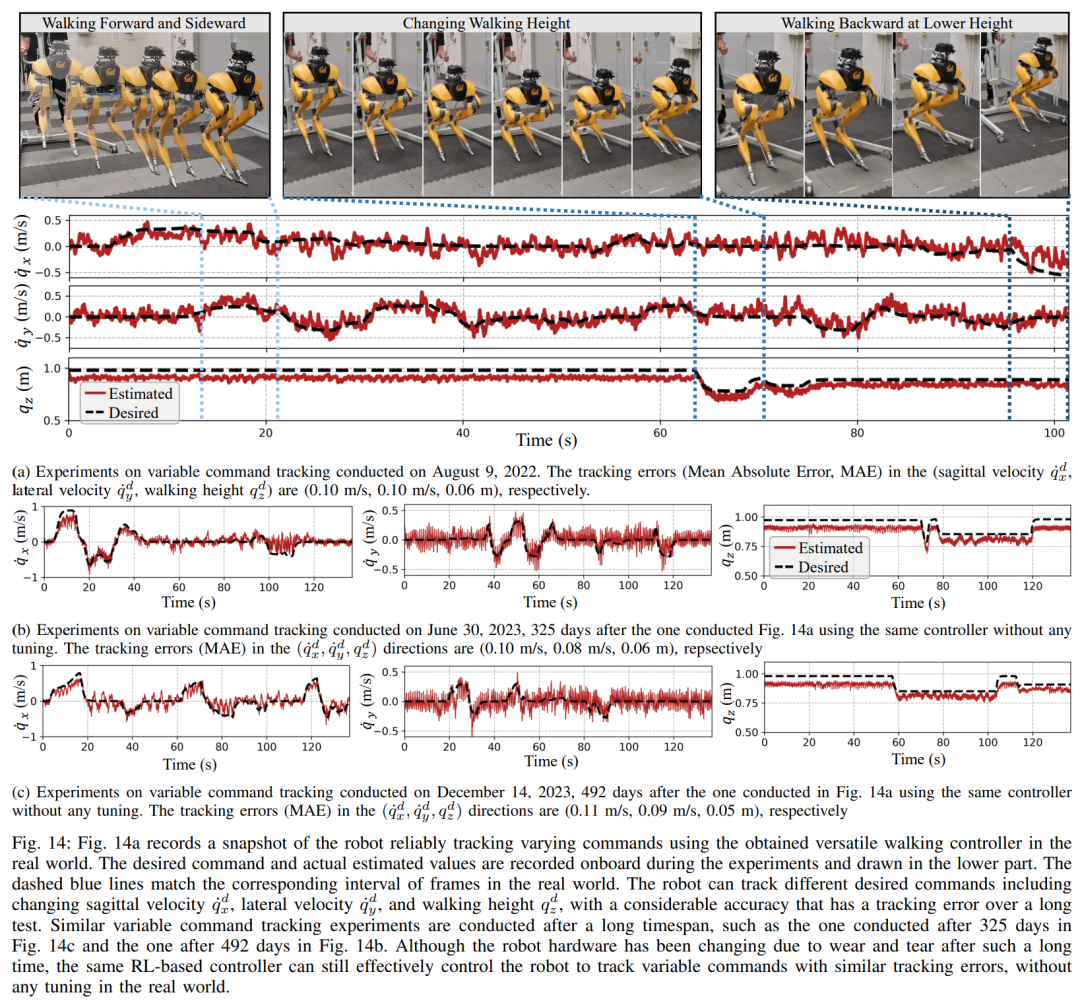
この二重履歴構造では、長期履歴がもたらします。適応性 (セクション 8 で検証) の短期履歴は、より優れたリアルタイム制御を可能にすることで、長期履歴 (セクション 7 で検証) の利用を補完します。 # セクション 6 では、ディープ ニューラル ネットワークで表される制御戦略をモデルフリー RL を通じて最適化する方法について説明します。研究者らは、さまざまなタスクを達成するために高度に動的な運動スキルを活用できるコントローラーの開発を目的としていたため、このセクションのトレーニングは多段階のシミュレーション トレーニングを特徴としています。このトレーニング戦略は、ロボットが固定タスクに集中するシングルタスク トレーニングから始まり、次にロボットが受けるトレーニング タスクを多様化するタスクのランダム化、最後にロボットの動的パラメーターを変更する動的ランダム化という構造化されたコースを提供します。このトレーニング戦略は、次のような多機能な制御戦略を提供できます。さまざまなタスクを実行し、ロボット ハードウェアのゼロショット移行を実現します。さらに、タスクのランダム化は、さまざまな学習タスク間で一般化することにより、結果として得られるポリシーの堅牢性も強化します。 研究によると、この堅牢性によりロボットは外乱に従順に動作でき、動的ランダム化によって引き起こされる外乱に対して「直交」します。これについてはセクション 9 で検証します。 研究者らは、このフレームワークを使用して、二足歩行ロボット Cassie の歩行、走行、ジャンプのスキルに関する多機能戦略を取得しました。第 10 章では、現実世界におけるこれらの制御戦略の有効性を評価します。 研究者たちは、現実世界を含むロボットについて広範な実験を実施しました。歩く、走る、跳ぶなど複数の能力が試される世界。使用されている戦略はすべて、シミュレーション トレーニング後、さらに調整することなく現実世界のロボットを効果的に制御できます。 図 14a に示すように、歩行戦略は有効性を示しています。ロボットのさまざまな命令を効果的に制御した後、テスト全体を通じて追跡誤差は非常に低くなりました (追跡誤差は MAE の値によって評価されます)。
さらに、ロボット戦略は長期間にわたって一貫して良好に機能し、325 日後および 492 日後でも可変コマンドの追跡を維持できます (図 14c および 14c)。図 14b に示すように。この期間中のロボットのダイナミクスの大幅な累積変化にも関わらず、図 14a の同じコントローラーは、追跡誤差の低下を最小限に抑えながら、さまざまな歩行タスクを効果的に管理し続けます。
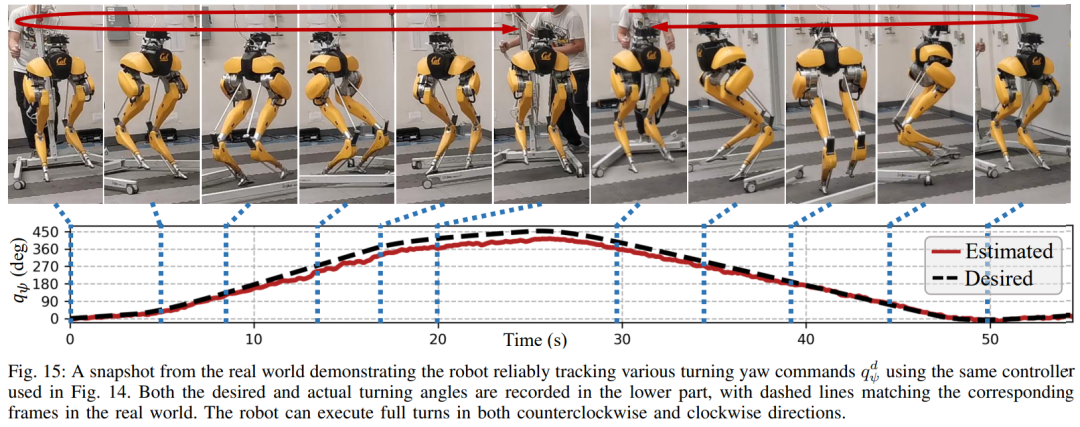
図 15 に示すように、この研究で使用された戦略はロボットの信頼性の高い制御を示し、ロボットが時計回りまたは反時計回りのさまざまな回転コマンドを正確に追跡できるようになりました。
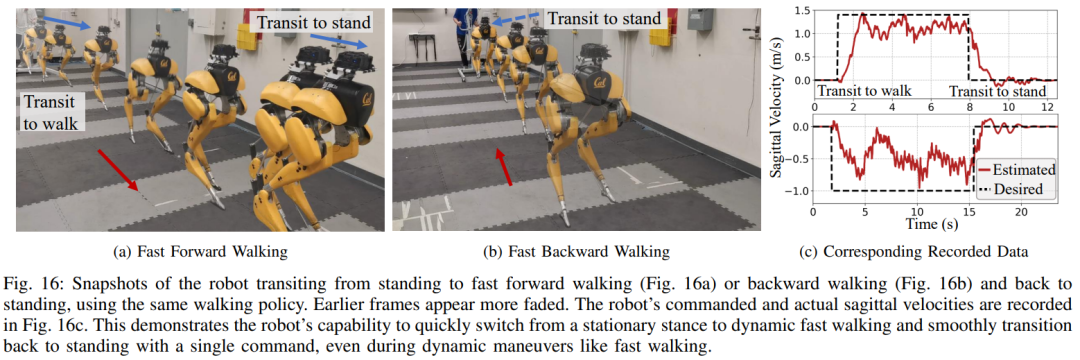
早歩きの実験。実験では、中程度の歩行速度に加えて、図 16 に示すように、前方および後方に高速歩行動作を実行するようにロボットを制御する使用された戦略の能力も実証しました。ロボットは、静止状態から平均 1.14 m/s (追跡コマンドでは 1.4 m/s が必要) という前方歩行速度に素早く到達し、コマンドに応じて素早く立位姿勢に戻ることもできます。 、図 16a に示すように、データ レコードは図 16c にあります。
平坦でない地形では (トレーニングなし)、下の図に示すように、ロボットは階段や下り坂を効果的に後ろ向きに歩くこともできます。
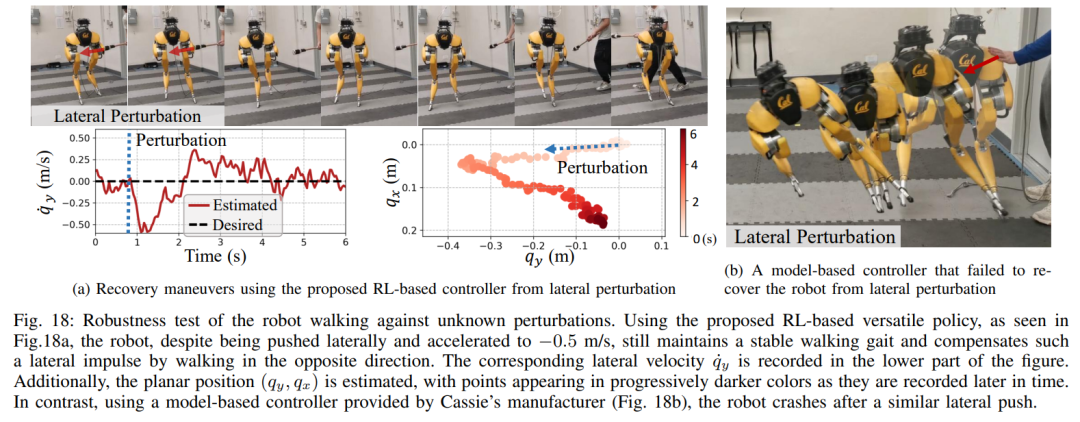
妨害防止。たとえばパルス外乱の場合、研究者はロボットが歩行している間にあらゆる方向からロボットに短期的な外乱を加えます。図 18a に記録されているように、所定の位置で歩行している間に、ロボットにかなりの横方向摂動力がかかり、最大横方向速度は 0.5 m/s です。混乱にもかかわらず、ロボットは横方向の逸脱からすぐに回復しました。図 18a に示すように、ロボットは反対の横方向に巧みに動き、摂動を効果的に補償し、安定した定位置歩行を回復します。
連続外乱試験中、人間はロボットベースに外乱力を加え、ロボットにその場で歩行するよう命令しながらロボットをランダムな方向に引きずりました。図 19a に示すように、ロボットが通常に歩くとき、Cassie のベースには連続的な横方向の抗力がかかります。結果は、ロボットがバランスを失うことなく、これらの外力の方向に従うことで、これらの外力に追従することを示しています。これは、安全な人間とロボットの相互作用を実現するための二足歩行ロボットの制御などの潜在的な応用において、この論文で提案した強化学習ベースの戦略の利点も示しています。
ロボットが二足歩行戦略を使用する場合、2 分で34 400 メートル走を数秒で、100 メートル走を 27.06 秒で、最大 10 度の傾斜で走ったなどの記録を達成しました。
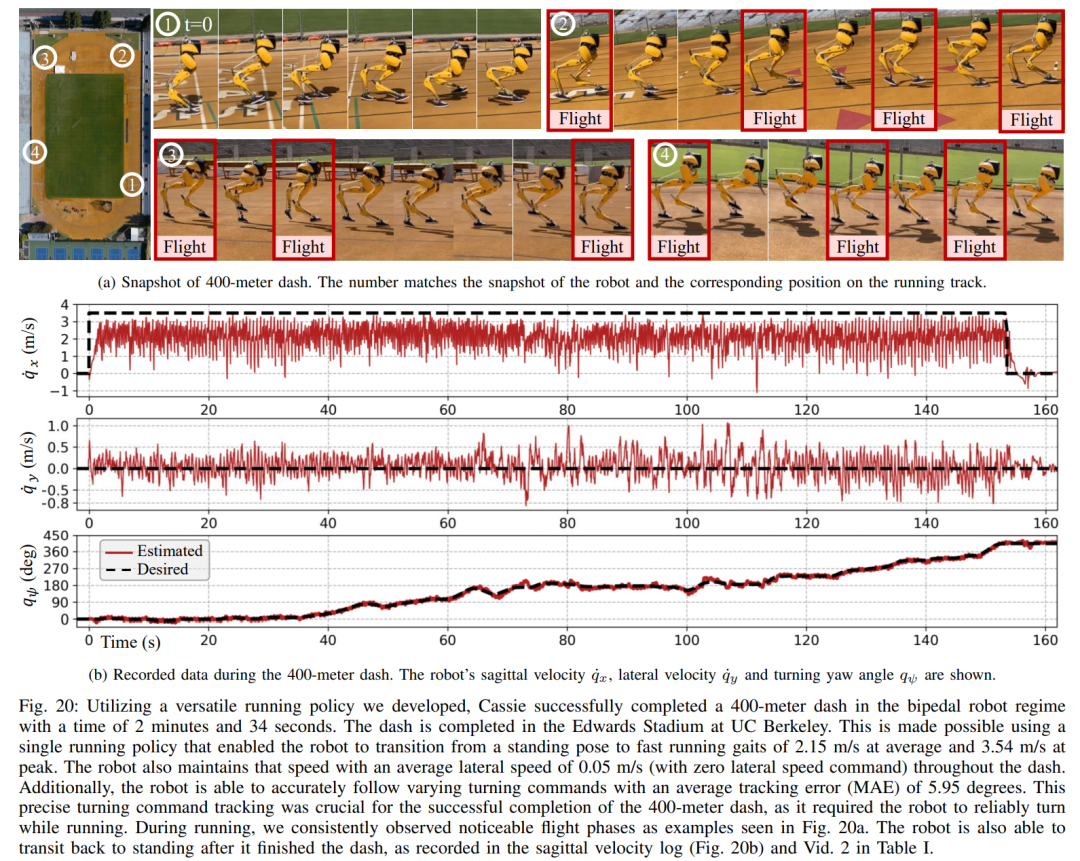
400 メートル ダッシュ: この研究では、図 20 に示すように、標準的な屋外トラックで 400 メートル ダッシュを完走するための一般的なランニング戦略を最初に評価しました。テスト全体を通じて、ロボットは、オペレーターが 3.5 m/s の速度で発行したさまざまな回転コマンドに同時に応答するように命令されました。ロボットは立位姿勢から走行歩行へスムーズに移行することができます (図 20a 1)。図 20b に示すように、ロボットは平均推定動作速度 2.15 m/s まで加速し、推定ピーク速度 3.54 m/s に達しました。この戦略により、ロボットはさまざまな回転コマンドに正確に従いながら、400 メートルの走行全体を通じて望ましい速度を維持することができました。
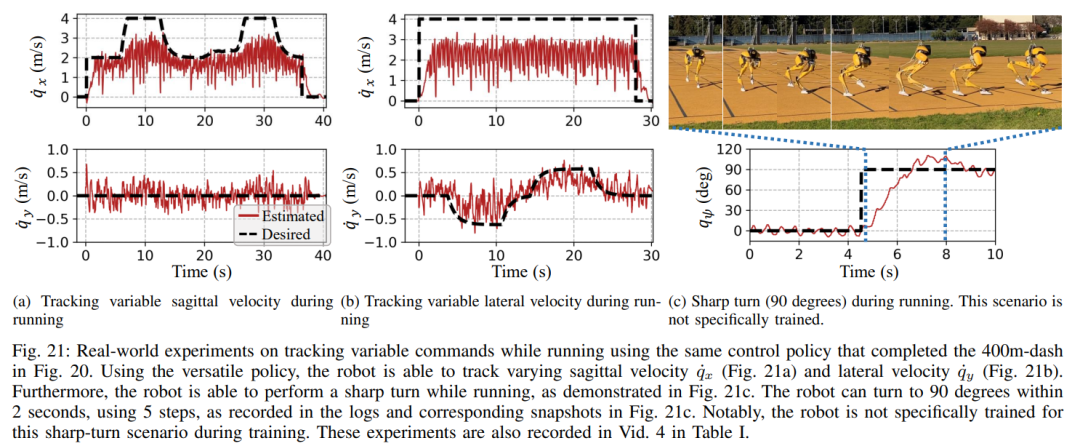
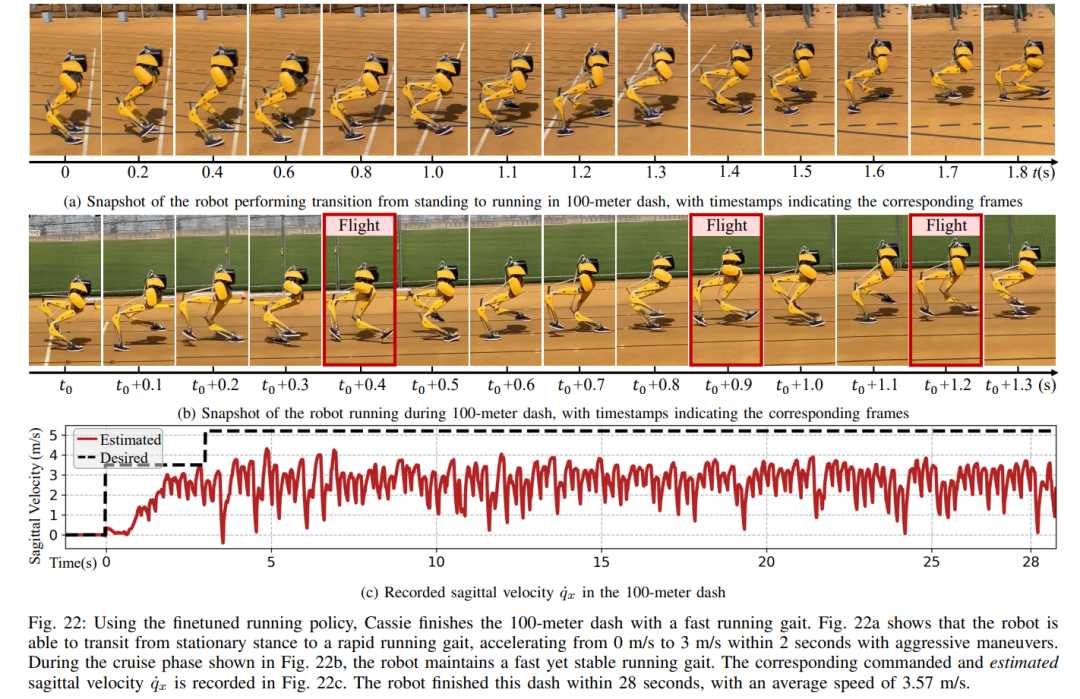
提案されたランニング戦略の制御下で、キャシーは 400 メートルのスプリントを 2 分 34 秒で完了し、その後立位に移行することができました。 研究ではさらに、図 21c に記録されているように、ロボットにヨー コマンドのステップ変化を 0 度から 90 度まで直接与えて急旋回テストを実施しました。 。ロボットはこのようなステップコマンドに応答し、2 秒と 5 ステップで急角度の 90 度回転を完了できます。 100 メートル走: 図 22 に示すように、提案された走行戦略を展開することにより、ロボットは約 28 秒で 100 メートル走を完了し、タイムを達成しました。 27.06 秒 最速の実行時間。 実験を通じて、研究者らはロボットにジャンプを訓練することが難しいことを発見しました。回転しながら同時に高台にジャンプすることもできるが、提案されたジャンプ戦略は、1.4メートルのジャンプや0.44メートルの高台へのジャンプなど、ロボットのさまざまな二足歩行ジャンプを実現する。 ジャンプと回転: 図 25a に示すように、単一のジャンプ戦略を使用して、ロボットは、60 度回転しながらその場でジャンプするなど、さまざまな指定されたターゲット ジャンプを実行できます。後ろにジャンプして0.3メートル後ろに着地するなど。 高台へのジャンプ: 図 25b に示すように、ロボットは、前方 1 メートルまたは前方 1.4 メートルなど、さまざまな場所にあるターゲットに正確にジャンプできます。また、0.44 メートルの高さまでジャンプするなど、さまざまな高さの場所にジャンプすることもできます (ロボット自体の高さがわずか 1.1 メートルであることを考慮します)。 以上があなたと一緒に走ると速くて安定します、ロボットのランニングパートナーがここにありますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


 #既に実行されている数十年かかりましたが、さまざまな運動能力の堅牢な制御を可能にする普遍的なフレームワークはまだありません。この課題は、二足歩行ロボットの作動不足のダイナミクスの複雑さと、各運動スキルに関連するさまざまな計画から生じます。
#既に実行されている数十年かかりましたが、さまざまな運動能力の堅牢な制御を可能にする普遍的なフレームワークはまだありません。この課題は、二足歩行ロボットの作動不足のダイナミクスの複雑さと、各運動スキルに関連するさまざまな計画から生じます。 
 セクション 4 まず、モーション制御におけるロボットの I/O 履歴の利用について紹介し、このセクションでは、ロボットの長期 I/O 履歴が、制御と RL の両方の観点からリアルタイム制御プロセスにおけるシステムの同定と状態推定を実現できることを示します。
セクション 4 まず、モーション制御におけるロボットの I/O 履歴の利用について紹介し、このセクションでは、ロボットの長期 I/O 履歴が、制御と RL の両方の観点からリアルタイム制御プロセスにおけるシステムの同定と状態推定を実現できることを示します。 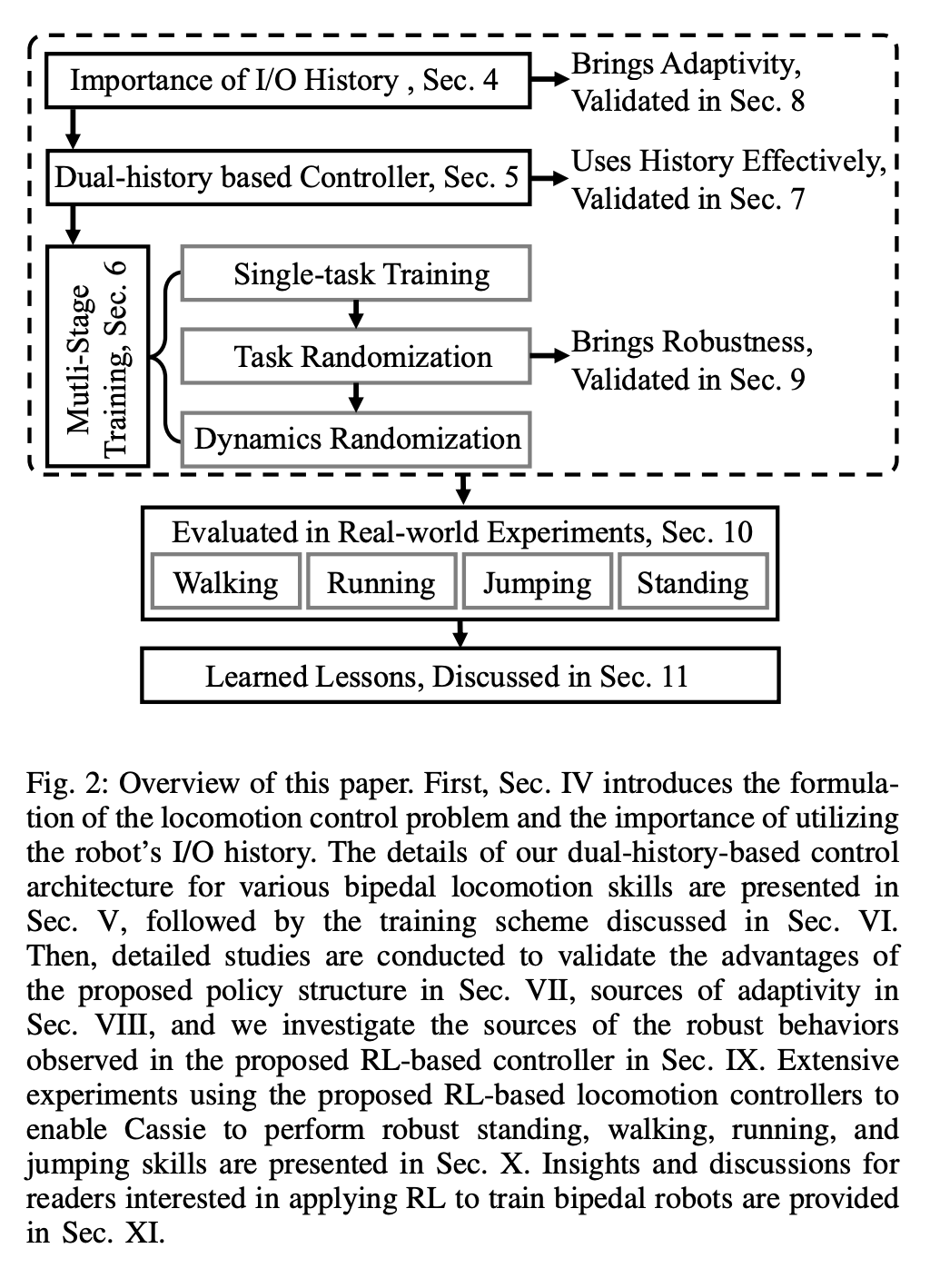 セクション 5 では、研究の核心である、二足歩行ロボットの長期および短期 I/O 二重履歴を利用した新しい制御アーキテクチャを紹介します。具体的には、この制御アーキテクチャはロボットの長期履歴だけでなく、短期履歴も活用します。
セクション 5 では、研究の核心である、二足歩行ロボットの長期および短期 I/O 二重履歴を利用した新しい制御アーキテクチャを紹介します。具体的には、この制御アーキテクチャはロボットの長期履歴だけでなく、短期履歴も活用します。 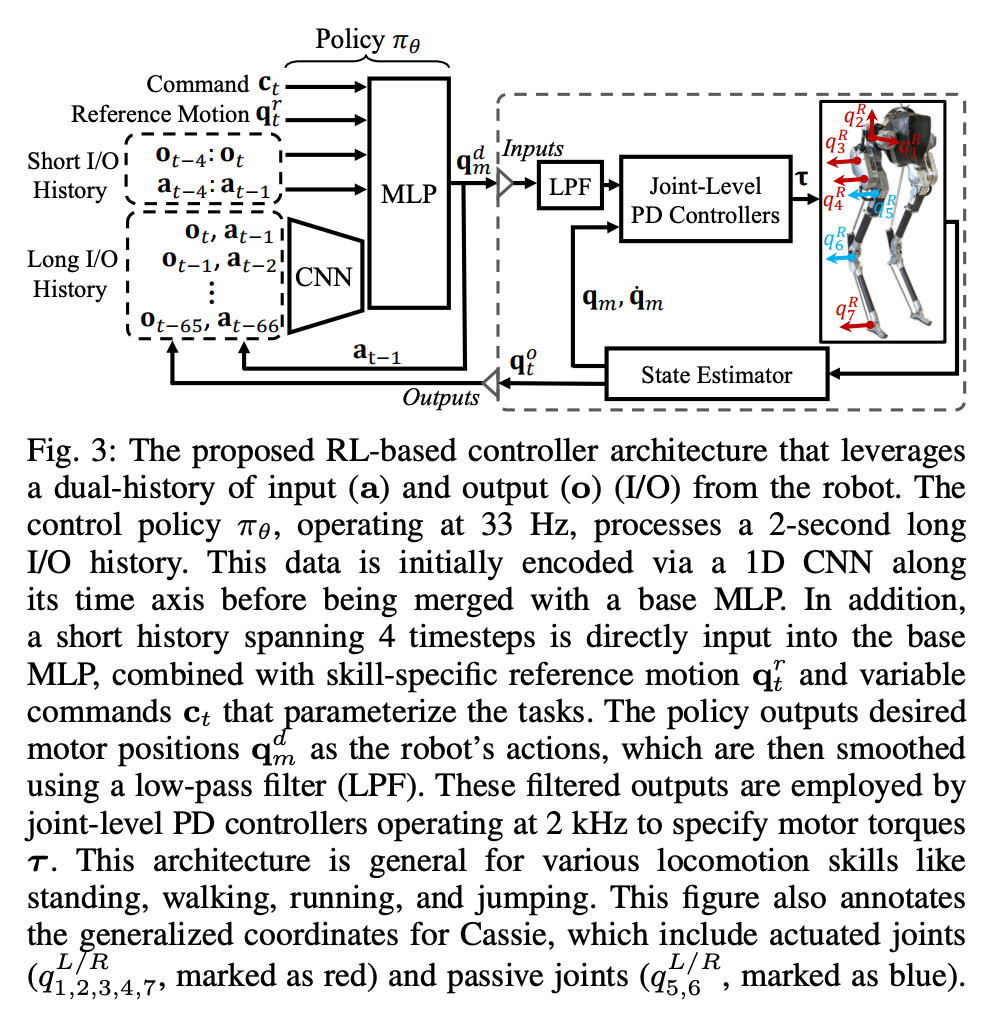 # セクション 6 では、ディープ ニューラル ネットワークで表される制御戦略をモデルフリー RL を通じて最適化する方法について説明します。研究者らは、さまざまなタスクを達成するために高度に動的な運動スキルを活用できるコントローラーの開発を目的としていたため、このセクションのトレーニングは多段階のシミュレーション トレーニングを特徴としています。このトレーニング戦略は、ロボットが固定タスクに集中するシングルタスク トレーニングから始まり、次にロボットが受けるトレーニング タスクを多様化するタスクのランダム化、最後にロボットの動的パラメーターを変更する動的ランダム化という構造化されたコースを提供します。
# セクション 6 では、ディープ ニューラル ネットワークで表される制御戦略をモデルフリー RL を通じて最適化する方法について説明します。研究者らは、さまざまなタスクを達成するために高度に動的な運動スキルを活用できるコントローラーの開発を目的としていたため、このセクションのトレーニングは多段階のシミュレーション トレーニングを特徴としています。このトレーニング戦略は、ロボットが固定タスクに集中するシングルタスク トレーニングから始まり、次にロボットが受けるトレーニング タスクを多様化するタスクのランダム化、最後にロボットの動的パラメーターを変更する動的ランダム化という構造化されたコースを提供します。