


TaskWeaver: データ分析と業界のカスタマイズを容易にして優れたエージェント ソリューションを構築するオープン ソース フレームワーク

データ分析は常に現代社会において重要なツールであり、本質を深く理解し、パターンを発見し、意思決定を導くのに役立ちます。ただし、データ分析プロセスは複雑で時間がかかることが多いため、データと直接対話できるインテリジェントなアシスタントが期待されています。大規模言語モデル (LLM) の発展により、仮想アシスタントや Copilot などのインテリジェント エージェントが次々に登場し、自然言語の理解と生成におけるパフォーマンスは驚異的です。しかし、残念なことに、既存のエージェント フレームワークは、複雑なデータ構造 (DataFrame、ndarray など) の処理と、まさにデータ分析や専門分野における中心的な要件であるドメイン知識の導入において依然として困難に直面しています。
タスク実行時の音声アシスタントのボトルネック問題をより適切に解決するために、Microsoft は TaskWeaver と呼ばれるエージェント フレームワークを立ち上げました。このフレームワークはコードファーストであり、複数のデータ構造と動的なプラグインの選択をサポートしながら、ユーザーの自然言語リクエストを実行可能なコードにインテリジェントに変換できます。さらに、TaskWeaver は、大規模な言語モデルの可能性を最大限に活用して、さまざまな分野の計画プロセスに従って専門的に適応させることもできます。 TaskWeaver はオープンソース フレームワークとして、特定の分野の知識を組み込むことができるカスタマイズ可能なサンプルとプラグインを提供し、ユーザーがパーソナライズされた仮想アシスタントを簡単に作成できるようにします。 TaskWeaver の発売により、音声アシスタントのインテリジェンス レベルが効果的に向上し、パーソナライズされた仮想アシスタントに対するユーザーの高まるニーズに応えます。

- 論文: TaskWeaver: コードファースト エージェント フレームワーク
- 論文のアドレス: https ://export.arxiv.org/abs/2311.17541
TaskWeaver プロジェクトは GitHub でオープンソース化されており、リリース当日に GitHub トレンド リストに掲載されました。現在、このプロジェクトは 29,000 個のスターを獲得しており、良い反響を得ています。また、SAPデータ分析にTaskWeaverを活用するなど、LinkedInなどのソーシャルプラットフォームでも実践事例がいくつかあります。これらのケースは、TaskWeaver の有用性と価値を示しています。

- #プロジェクト ホームページ: https://microsoft.github.io/TaskWeaver/
- プロジェクト アドレス: https://github.com/microsoft/TaskWeaver
販売データに隠された秘密の追跡
Xiaoya はビジネス アナリストであり、彼女の仕事の 1 つは異常を探すことです。最近の販売データを分析し、それらの異常に基づいて企業が販売戦略を調整できるようにします。すべての販売データは SQL データベースに安全に保存されます。彼女は、AI アシスタントとの自然言語コミュニケーションを通じて、データを簡単に抽出して分析できるようにしたいと考えています。特に重要なのは、販売の世界では異常が独特であるという事実であるため、彼女は、AI アシスタントがカスタマイズされた異常検出アルゴリズムを使用してこの問題を解決できることを望んでいます。以下は、Xiaoya と AI アシスタントの間のチャット記録 (図 1) であり、両者の間のやり取りを示しています。 Xiaoya: こんにちは。データベースから売上データを抽出して分析するのを手伝ってもらいたいのですが。 AI アシスタント: わかりました。すぐにデータベースから対応するデータを抽出します。抽出したデータは後ほど確認のため提示させていただきます。 シャオヤ:ありがとうございます。 (しばらくして) AIアシスタント:データベースから売上データを抽出しましたが、データの概要は以下の通りですのでご確認ください。 (AIアシスタントが表示するデータの概要) Xiaoya: データは良好のようです。異常の検出と分析を続けてください。 AI アシスタント: 分かりました。カスタム異常検出アルゴリズムを使用して分析を実行し、できるだけ早く直感的な視覚化を示します。 (しばらくして) AI アシスタント: 分析が完了しました。次の視覚化結果をご覧ください。 (AI アシスタントが結果を視覚的に表示) シャオヤ: ご協力ありがとうございました!これらの結果は私にとって非常に貴重です。 AI アシスタント: お手伝いさせていただきます。さらにご質問がある場合、またはさらなる分析が必要な場合は、お気軽にお知らせください。 シャオヤ: もちろん、サポートに感謝します。
 #図 1. ストーリーの例での会話の記録
#図 1. ストーリーの例での会話の記録
エージェント フレームワークに必要なスキル?
上記の Xiaoya のストーリーを通じて、エージェント フレームワークに必要ないくつかのコア機能を整理しました。
1. プラグインのサポート: 上記のストーリーでは、エージェントはデータベースからデータを取得し、指定された異常検出アルゴリズムを使用する必要があります。これらのタスクを実行するには、スマート アシスタントが「query_database」プラグインや「anomaly_detection」プラグインなどのカスタム プラグインを定義して呼び出すことができる必要があります。
2. 豊富なデータ構造のサポート: エージェントは、配列、行列、テーブル データなどの複雑なデータ構造を処理する必要があります。 、したがって、予測、クラスタリングなどの高度なデータ処理をスムーズに実行できます。さらに、このデータは異なるプラグイン間でシームレスに受け渡される必要があります。ただし、既存のエージェント フレームワークのほとんどは、データ分析の中間結果を Prompt でテキストに変換するか、最初にローカル ファイルとして保存し、必要に応じて読み取ります。ただし、これらの方法ではエラーが発生したり、プロンプトの単語数の制限を超えたりする可能性があります。
3. ステートフル実行: エージェントは多くの場合、複数ラウンドの反復でユーザーと対話し、以下に基づいてコードを生成して実行する必要があります。ユーザー入力です。したがって、これらのコードの実行状態は、セッションが終了するまでセッション全体にわたって保存される必要があります。
4. まず理由を考えてから行動する (ReAct) : エージェントは ReAct の能力を備えている必要があります。つまり、まず理由を観察し、これは、不確実性が存在する一部のシナリオでは非常に必要です。たとえば、上記の例では、通常、データベース内のデータ スキーマ (スキーマ) が多様であるため、エージェントはまずデータ スキーマ情報を取得し、どの列が適切であるかを理解し (ユーザーに確認し)、次に対応する列を確認する必要があります。異常検出アルゴリズムに入力される名前にすることができます。
5. 任意のコードの生成: 事前定義されたプラグインではユーザーのリクエストを満たすことができない場合があり、エージェントはそれを実行できる必要があります。ユーザーの一時的なニーズに対処するためのコードを生成します。上記の例では、エージェントは検出された異常を視覚化するコードを生成する必要がありますが、このプロセスはプラグインの助けを借りずに実現されます。
6. ドメイン知識の統合: エージェントは、特定の分野の知識を統合するための体系的なソリューションを提供する必要があります。これにより、LLM はより適切な計画を立て、ツールを正確に呼び出すことができるようになり、特に業界に合わせたシナリオで信頼性の高い結果が得られます。
TaskWeaver のコア アーキテクチャを明らかにする
図 2 は、TaskWeaver の全体的なアーキテクチャ (プランナー、コード インタープリター インタープリター)、およびメモリ モジュールを示しています。 (メモリ)。
プランナーはシステムの頭脳のようなもので、次の 2 つの主要な役割があります: 1) 計画を立てる、つまりユーザーのニーズをサブタスクに分割し、これらのサブタスクを 1 つずつ送信します。コードインタープリタ、およびプラン実行プロセス全体で必要に応じてプランを自己調整します。 2) ユーザーに応答し、コードインタープリタのフィードバック結果をユーザーが理解しやすい回答に変換し、それをユーザーに送信します。ユーザー。
コード インタープリターは、主に 2 つのコンポーネントで構成されます。コード ジェネレーター (コード ジェネレーター) は、プランナーによって送信されたサブタスクを受け取り、既存の利用可能なプラグインおよびドメイン固有のタスクと組み合わせられます。対応するコード ブロックを生成するため、コード エグゼキューター (Code Executor) は、生成されたコードを実行し、セッション全体で実行状態を維持する責任を負います。このため、複雑なデータ構造は、プロンプトやファイル システムを経由せずにメモリ内で渡すことができます。これは、Jupyter Notebook での Python プログラミングに似ており、ユーザーがセルにコードのスニペットを入力すると、プログラムの内部状態が逐次実行中に保存され、後続のプロセスで参照できます。実装に関しては、各セッションで、コード実行プログラムはコードを実行するための独立した Python プロセスを持ち、同時に複数のユーザーをサポートします。
メモリ モジュールは主に、実行結果など、システム全体の動作中に役立つ情報を保存し、さまざまなモジュールによって書き込みおよび読み取りが可能です。短期記憶には主に、現在のセッションにおけるユーザーとTaskWeaver間の通信記録や、モジュール間の通信記録が含まれます。長期記憶には、ユーザーが事前にカスタマイズできるドメイン知識や、対話プロセス中に要約されたいくつかの経験などが含まれます。
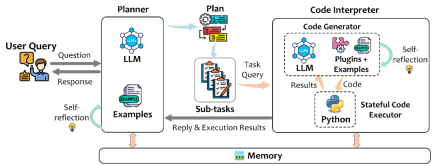
#図 2. TaskWeaver の全体的なアーキテクチャ図
基本的なアーキテクチャに加えて、TaskWeaver には多くのユニークなデザインもあります。たとえば、セッション圧縮によりテキスト サイズが削減され、より多くの会話ターンが可能になり、動的なプラグイン選択によりユーザーのリクエストに基づいて適切なプラグインが自動的に選択されるため、より多くのカスタム プラグインを統合できるようになります。さらに、TaskWeaver は、ユーザーが使用中にコマンドを入力することによってトリガーできるエクスペリエンス保存機能もサポートしており、現在のセッションでのユーザーのエクスペリエンスと教訓を要約し、次のセッションでの間違いの繰り返しを回避し、真のパーソナライゼーションを実現します。 TaskWeaverはセキュリティ面でも慎重に設計されており、例えばPythonモジュールのホワイトリストをユーザーが指定でき、生成されたコードがホワイトリスト外のモジュールを参照した場合にはエラーが発生するため、セキュリティリスクが軽減されます。
TaskWeaver の特定のプロセス
図 3 は、前述のサンプル タスクを完了する TaskWeaver のプロセスの一部を示しています。
まず、プランナーはユーザーの入力を受け取り、各モジュールの機能説明と計画例に基づいて具体的な計画を生成します。この計画には 4 つのサブタスクが含まれており、その 1 つ目はデータベースからデータを抽出し、データ スキーマを記述することです。
コード ジェネレーターは、機能の説明と関連するすべてのプラグインの定義に基づいてコードを生成します。このコードは、sql_pull_data プラグインを呼び出してデータを DataFrame に保存し、データ スキーマの説明を提供します。
最後に、生成されたコードは実行のためにコード エグゼキューターに送信され、完了した結果はプランナーに送信されて、プランを更新するか、次のサブタスクに進みます。図の実行結果は、DataFrame に 2 つの列 (日付と値) があることを示しています。プランナは、これらの列が正しいかどうかをユーザーにさらに確認することも、anomaly_detection プラグインを呼び出す次のステップに直接進むこともできます。

図 3. TaskWeaver の内部ワークフロー
ドメインの知識を TaskWeaver に注入するにはどうすればよいでしょうか?
大規模なモデル アプリケーションにおいて、ドメイン固有の知識を統合する主な目的は、業界のカスタマイズにおける LLM の汎化パフォーマンスを向上させることです。 TaskWeaver は、ドメインの知識をモデルに注入する 3 つの方法を提供します。
-
プラグインを使用したカスタマイズ: ユーザーはカスタマイズ可能 ドメインの統合プラグインの形での知識。プラグインには、API の呼び出し、特定のデータベースからのデータの取得、特定の機械学習アルゴリズムやモデルの実行など、さまざまな形式があります。プラグインのカスタマイズは比較的簡単で、プラグインに関する基本情報 (プラグイン名、関数の説明、入力パラメータ、戻り値など) と Python 実装を指定するだけです。
-
例を使用したカスタマイズ: TaskWeaver はユーザーに体系的なインターフェイス (YAML 形式) も提供しますLLM にユーザーのリクエストに応答する方法を教えるため。具体的には、プランナーでの計画と、コードジェネレーターでのコードプログラミングに使用されるサンプルの 2 種類に分類できます。
- # エクスペリエンスの保存 #: TaskWeaver は、ユーザーが現在のセッション プロセスを要約して保存できるようにサポートします。用語記憶。ユーザーは、自分のドメイン知識を会話として TaskWeaver に「教え」、その会話をエクスペリエンスとして保存できます。その後の使用プロセスでは、エクスペリエンスを動的にロードすることで、専門分野の問題をより適切に完了できます。
#TaskWeaver の使用方法?
TaskWeaver の完全なコードは、GitHub でオープン ソースになりました。現在、コマンド ライン起動、Web サービス、Python ライブラリ形式でのインポートの 3 つのソリューションの使用がサポートされています。簡単なインストールの後、ユーザーは LLM API アドレス、キー、モデル名などのいくつかの主要なパラメーターを構成するだけで、TaskWeaver サービスを簡単に開始できます。

TaskWeaver は、データ分析と業界のカスタマイズ シナリオのニーズを満たすように設計された新しいエージェント フレームワーク ソリューションです。ユーザー言語をプログラミング言語に変換することで、「データと対話する」ことが夢ではなく現実になります。
以上がTaskWeaver: データ分析と業界のカスタマイズを容易にして優れたエージェント ソリューションを構築するオープン ソース フレームワークの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム
 AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM
AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM主要なエンタープライズ分析プラットフォームAlteryxのCEOであるAndy Macmillanとの私の最近の会話は、AI革命におけるこの重要でありながら過小評価されている役割を強調しました。 MacMillanが説明するように、生のビジネスデータとAI-Ready情報のギャップ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SublimeText3 中国語版
中国語版、とても使いやすい

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

