
ホームページ >テクノロジー周辺機器 >AI >情報の壁を突破せよ!衝撃の大規模3Dビジュアライゼーションツールがリリース!
情報の壁を突破せよ!衝撃の大規模3Dビジュアライゼーションツールがリリース!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-16 12:15:211218ブラウズ
最近、ニュージーランド出身の若者、ブレンダン・バイクロフトがテクノロジー界にブームを巻き起こしました。彼が作成した「Large Model 3D Visualization」と呼ばれるプロジェクトは、Hacker News のリストでトップになっただけでなく、その衝撃的な効果はさらに驚くべきものでした。このプロジェクトを通じて、LLM (Large Language Model) がどのように機能するかをわずか数秒で完全に理解できます。
あなたがテクノロジー愛好家であろうとなかろうと、このプロジェクトは前例のない視覚的な饗宴と認知的啓発をもたらします。この素晴らしい作品を一緒に探索しましょう!
はじめに
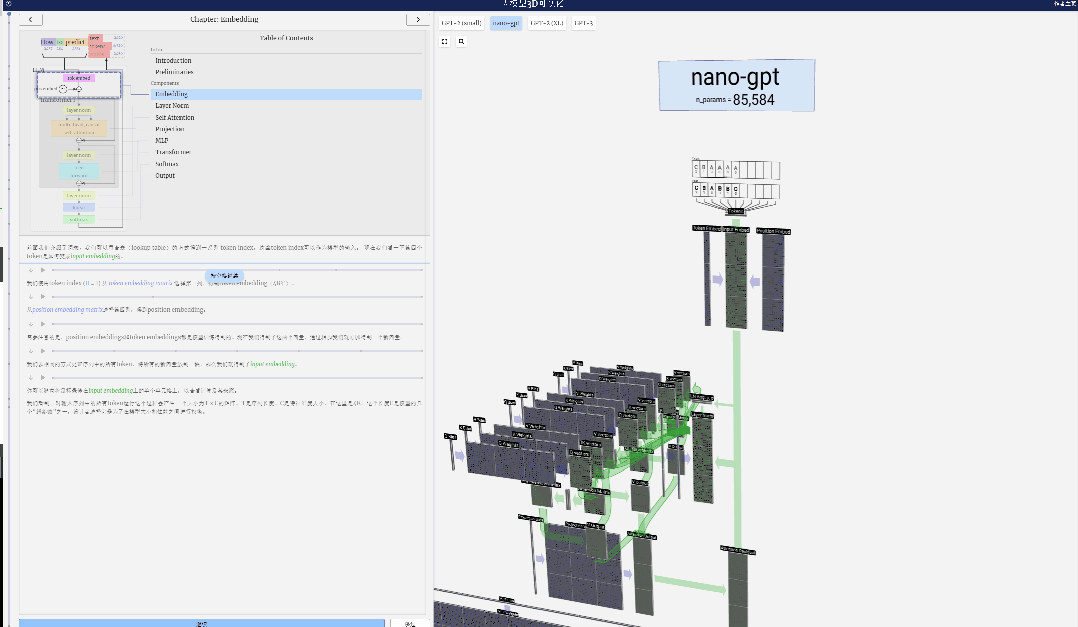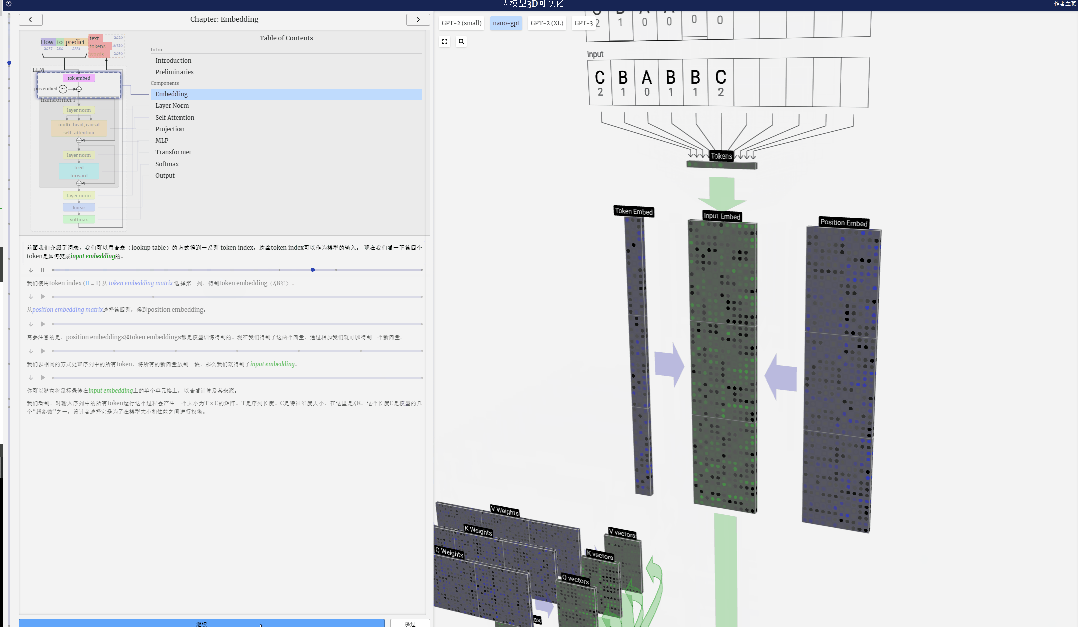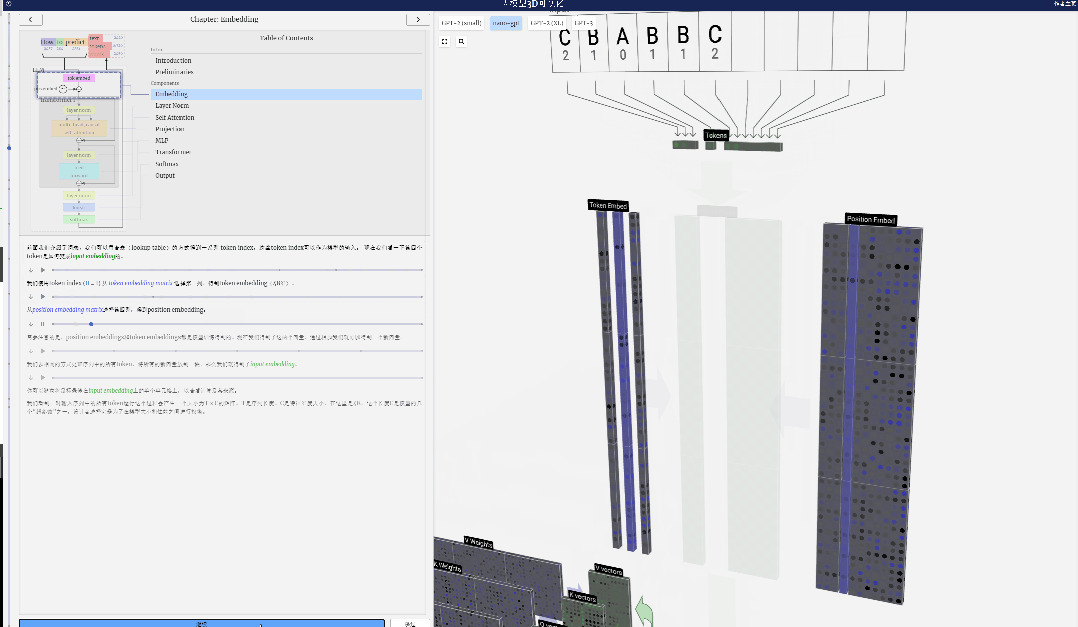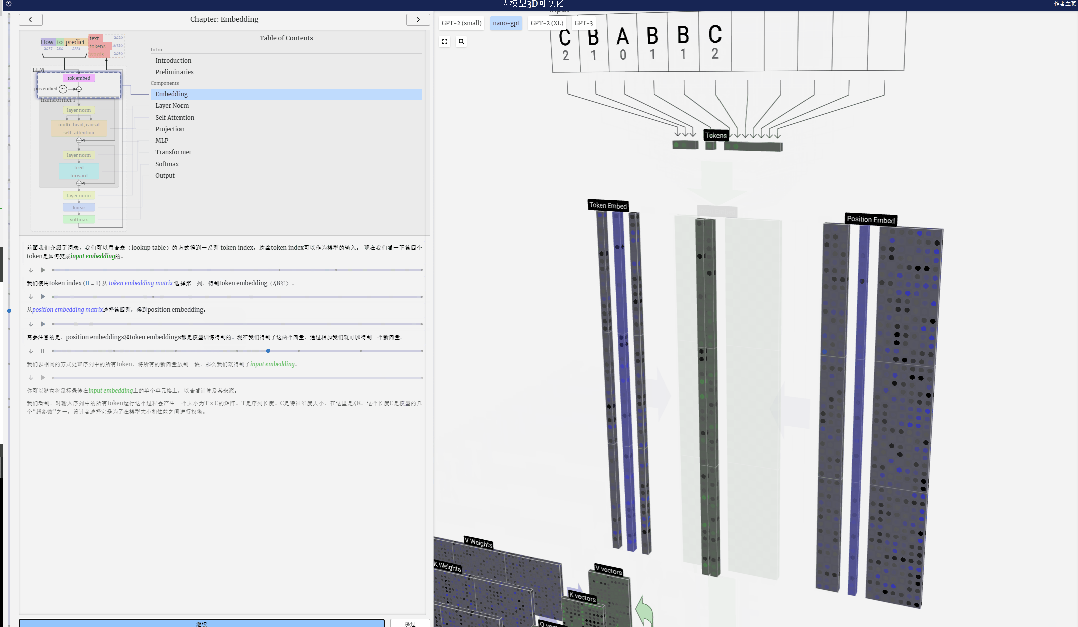
このプロジェクトで、Bycroft は、OpenAI 科学者の Andrej Karpathy が開発した Nano-GPT と呼ばれる軽量 GPT モデルを詳細に分析しました。 GPT モデルの縮小バージョンとして、このモデルには 85,000 個のパラメータしかありません。もちろん、このモデルは OpenAI の GPT-3 や GPT-4 よりもはるかに小さいですが、「スズメは小さいながらもすべての内臓を備えている」と言えます。
Nano-GPT GitHub: https://github.com/karpathy/nanoGPT
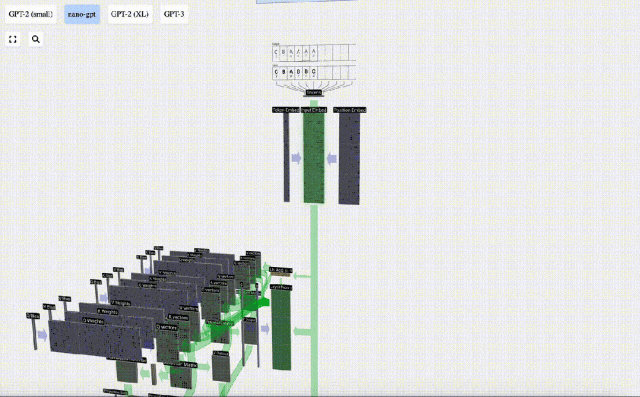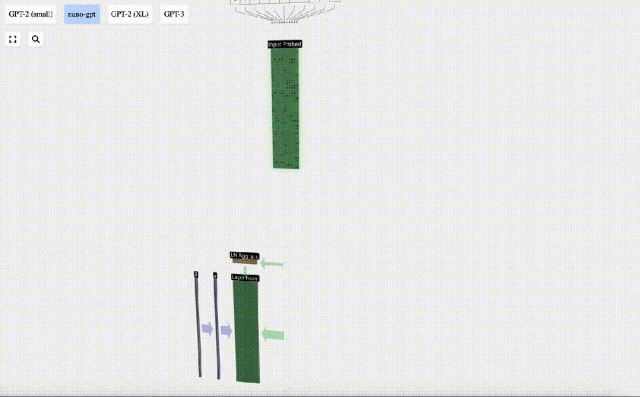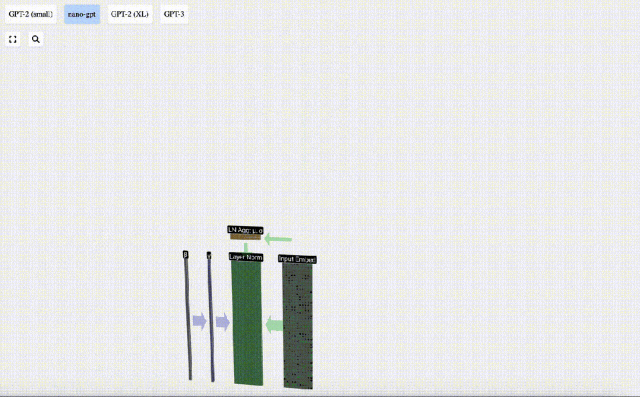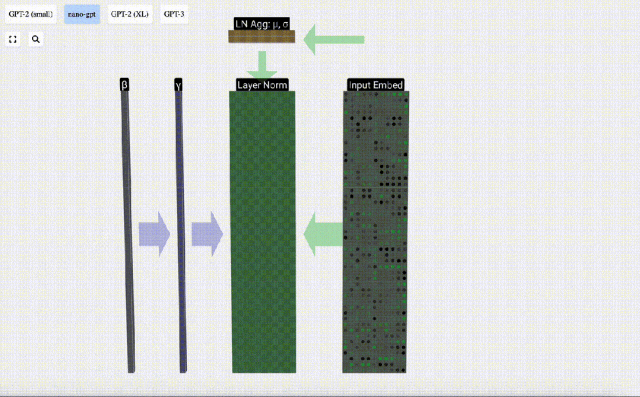
Transformer モデルの各層のデモンストレーションを容易にするために、Bycroft は、 Nano-GPT モデル タスク: モデルの入力は 6 文字「CBABBC」で、出力はアルファベット順に並べられたシーケンスです。たとえば、出力は「ABBBCC」です。
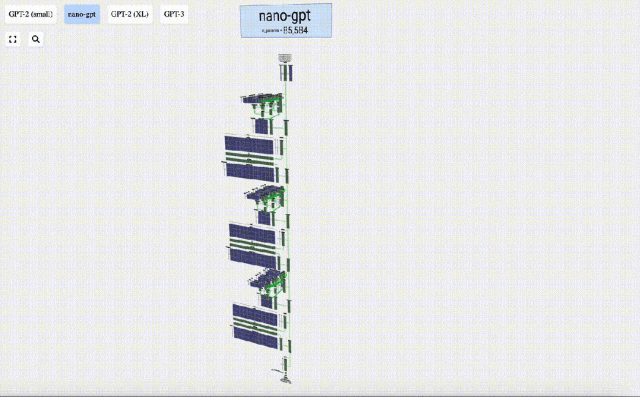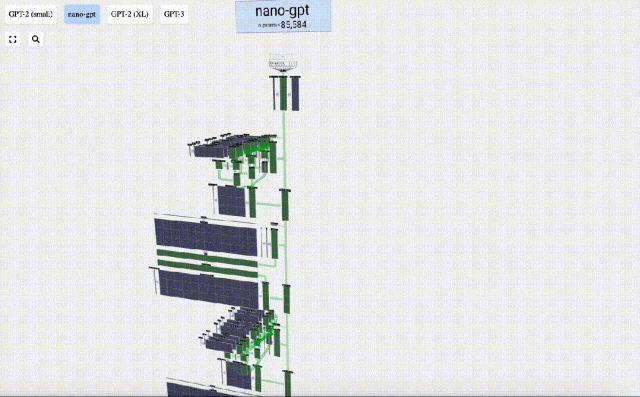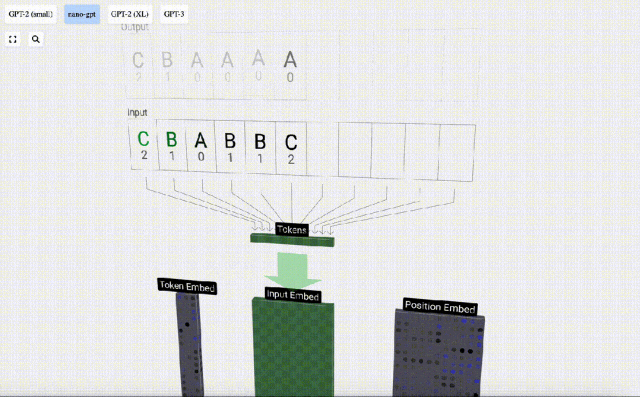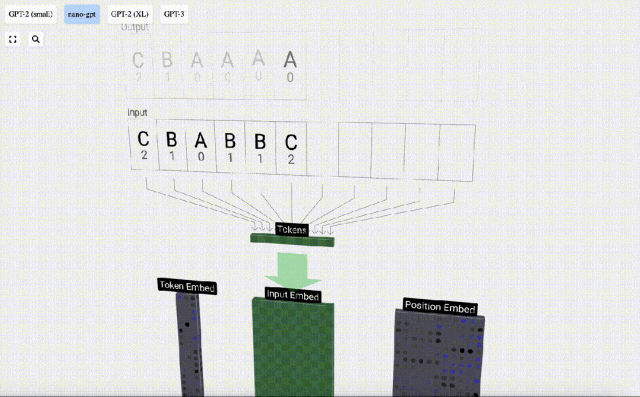
各文字を トークン と呼びます。これらのさまざまな文字が語彙語彙を構成します。
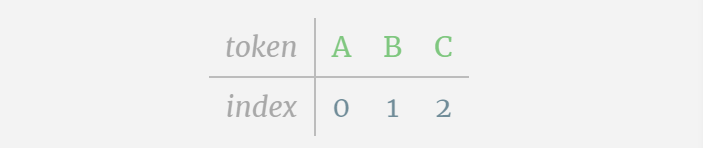
このテーブルでは、各文字に添え字トークン インデックスが割り当てられます。これらの添え字で構成されるシーケンスは、モデルの入力として使用できます。 2 1 0 1 1 2
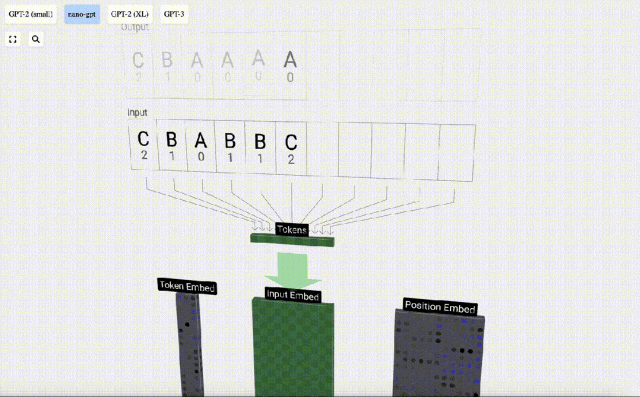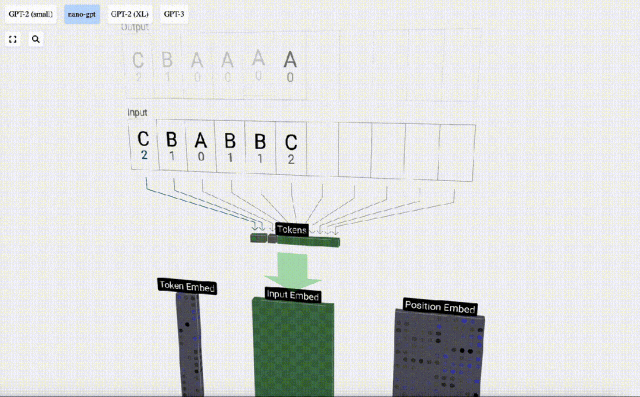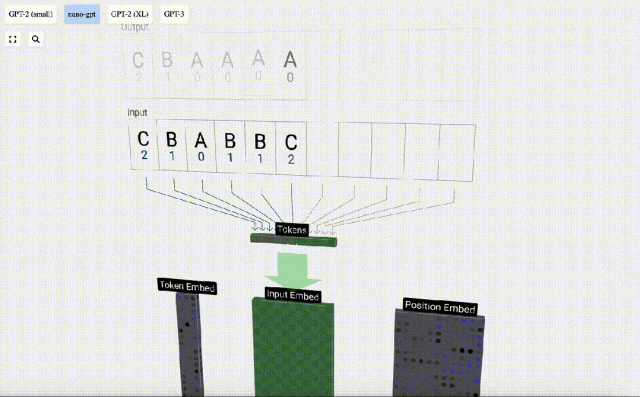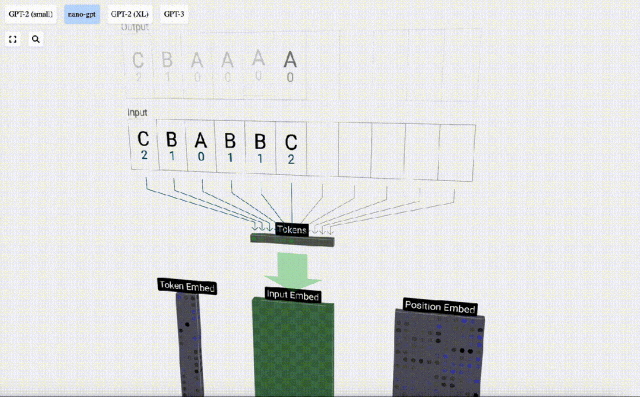
3D 視覚化では、各緑色のセルは計算された数値を表します。青いセルはモデルの重みを表します。
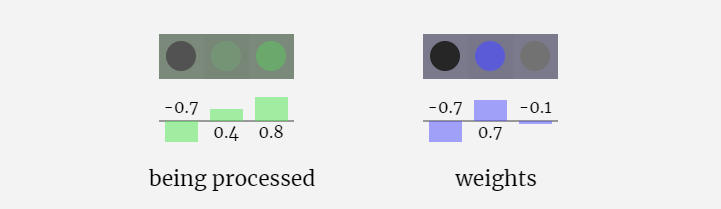
#シーケンス処理では、まず各数値を C 次元のベクトルに変換する処理を埋め込みといいます。 Nano-GPT では、この埋め込みの次元は通常 48 次元です。この埋め込み操作により、各数値は C 次元空間のベクトルとして表現されるため、その後の処理と分析が向上します。
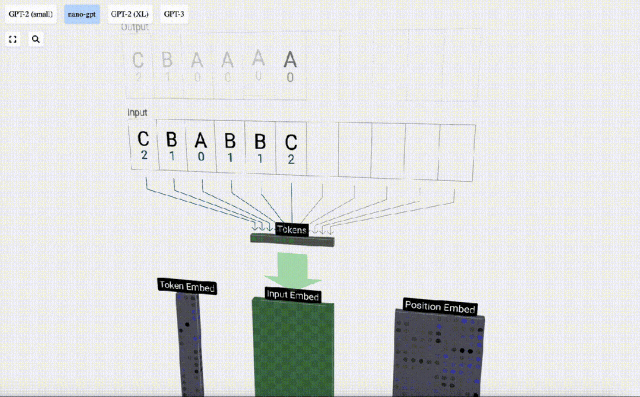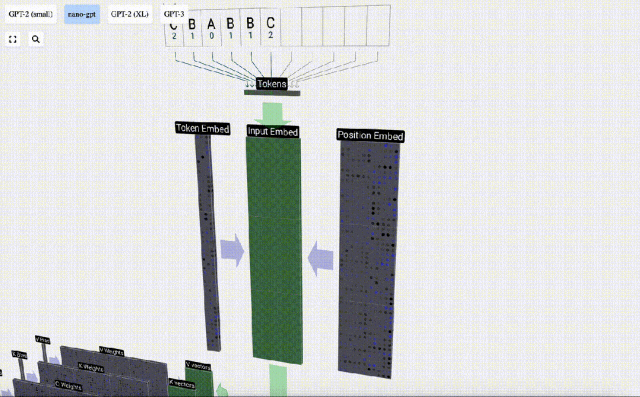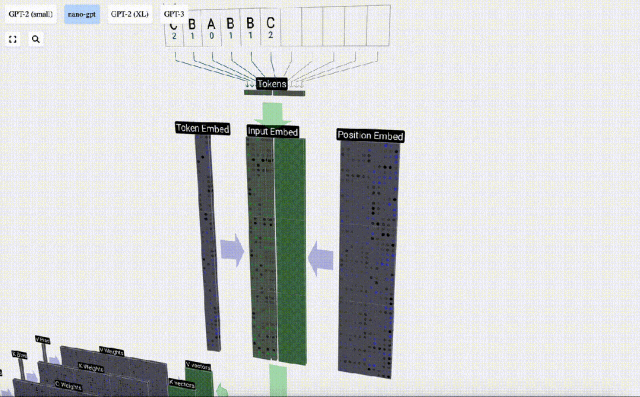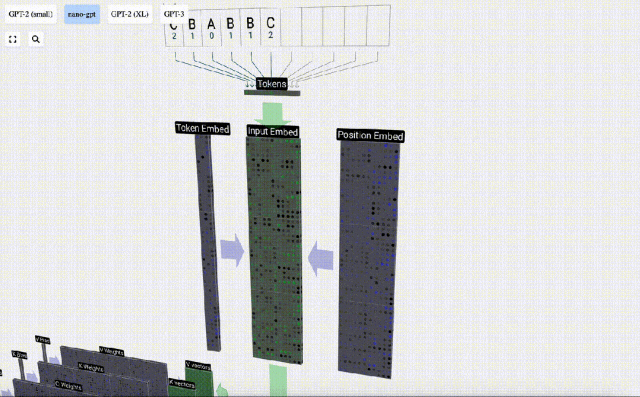
埋め込みは、一般にトランスフォーマーと呼ばれる一連の中間モデル層の計算を経て、最終的に最下位層に到達します。

「では、出力は何でしょうか?」
モデルの出力は、シーケンス内の次のトークンです。したがって、最後に、次のトークンが A B C である確率値を取得します。
この例では、6 番目の位置モデルは高い確率で A を出力します。ここで、A を入力としてモデルに渡し、プロセス全体を繰り返すことができます。
さらに、GPT-2 および GPT-3 の視覚化効果も表示されます。
- GPT-3 には 1,750 億個のパラメータがあり、モデル層は 8 列で画面全体を密にカバーしています。
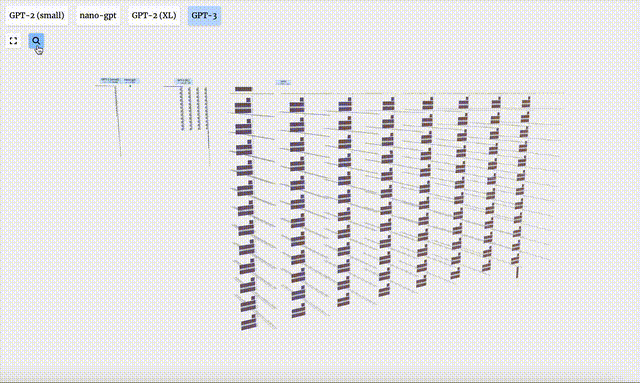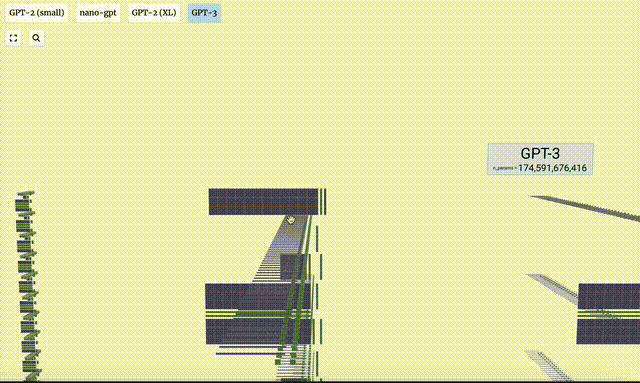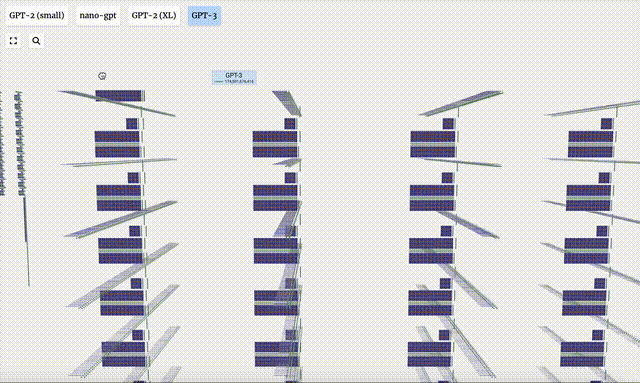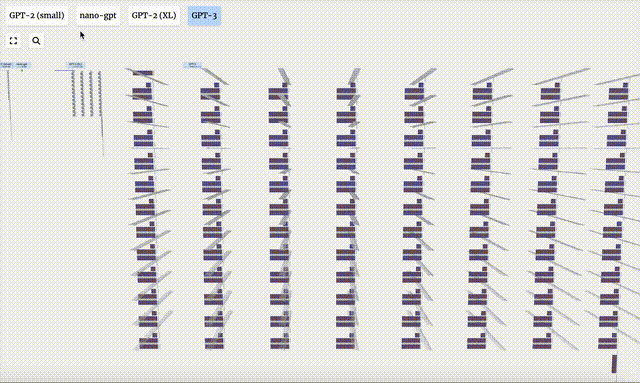
- GPT-2 モデルのパラメータ バージョンが異なると、アーキテクチャに大きな違いが見られます。ここでは、GPT-2 (XL) の 150 億のパラメーターと GPT-2 (Small) の 1 億 2,400 万のパラメーターを例として取り上げます。

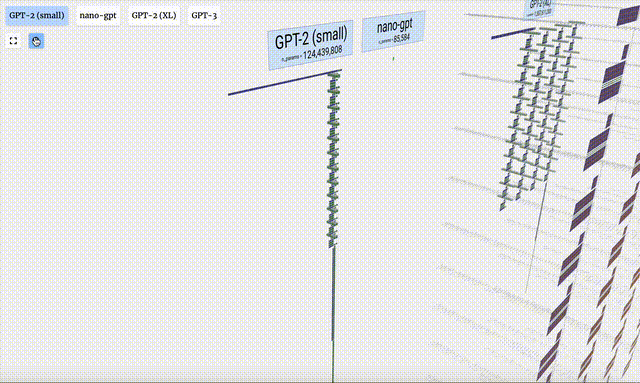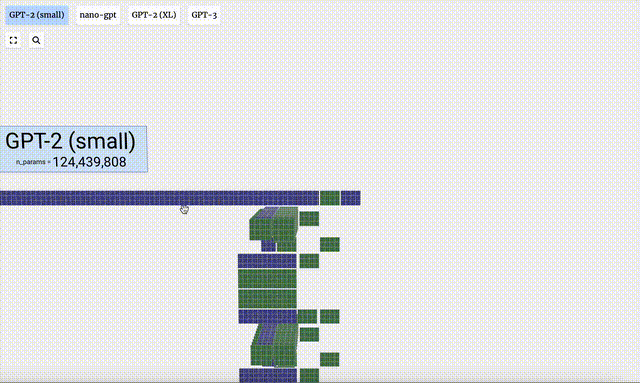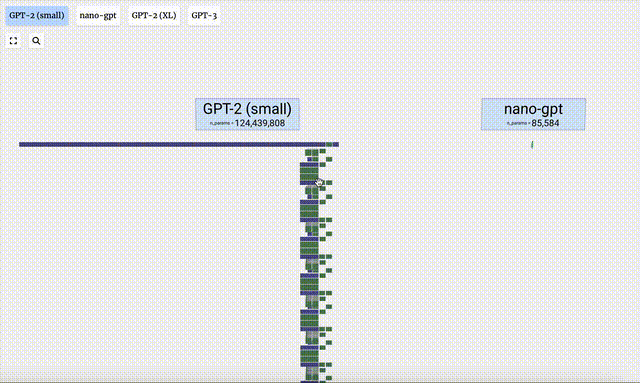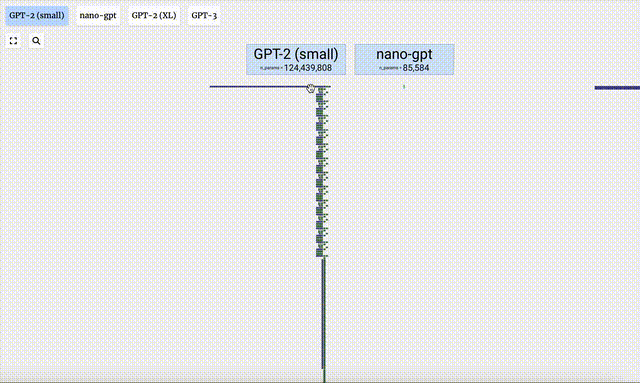
この視覚化はトレーニングではなくモデル推論 (推論) に主に焦点を当てていることに注意してください。機械学習プロセス全体のほんの一部です。さらに、ここでは、モデルの重みが事前にトレーニングされており、モデル推論を使用して出力を生成すると仮定しています。
埋め込み
前述したように、単純なルックアップ テーブル (ルックアップ テーブル) を使用してトークンを一連の整数にマッピングする方法。
これらの整数、つまりトークン インデックスは、モデルが整数を認識するのは最初で唯一です。以降は浮動小数点数(10進数)を使った演算となります。
ここでは、4 番目のトークン (インデックス 3) を例として、入力埋め込みの 4 番目の列ベクトルを生成するためにそれがどのように使用されるかを確認します。

まず、トークン インデックス (ここでは例として B=1 が使用されています) を使用して、トークン埋め込み行列から 2 番目の列を選択し、サイズ C= の列を取得します。 48 (48 次元) ベクトル。トークン埋め込みと呼ばれます。

次に、位置埋め込み行列から 4 番目の列を選択します (「ここでは主に 4 番目の位置にある (t = 3) トークン B に注目するため」)、同様に、サイズ C=48 (48 次元) の列ベクトルを位置埋め込みと呼びます。

位置埋め込みとトークン埋め込みはどちらもモデル トレーニングによって取得されることに注意してください (青で示されます)。これら 2 つのベクトルができたので、それらを追加することで、サイズ C=48 の新しい列ベクトルを取得できます。

次に、同じプロセスでシーケンス内のすべてのトークンを処理し、トークンの値とその位置を含むベクトルのセットを作成します。

上の図からわかるように、入力シーケンス内のすべてのトークンに対してこのプロセスを実行すると、サイズ TxC の行列が生成されます。このうち、Tは系列長を表す。 C はチャネルを表しますが、フィーチャ、ディメンション、または埋め込みサイズとも呼ばれます。この場合は 48 です。この長さ C は、モデルのいくつかの「ハイパーパラメータ」の 1 つであり、モデルのサイズとパフォーマンスの間のトレードオフを提供するために設計者によって選択されます。
次元 TxC のこの行列は入力埋め込みであり、モデルを通じて渡されます。
ちょっとしたヒント: 入力埋め込みの単一セルの上にマウスを置くと、計算とそのソースが表示されます。
レイヤー正規化レイヤーノルム
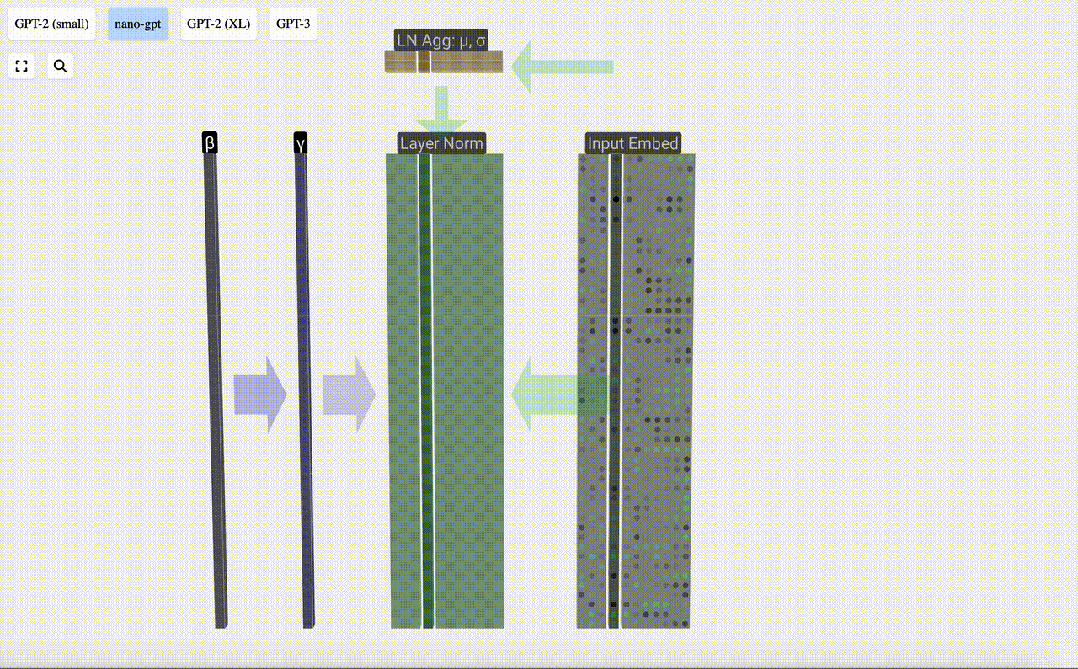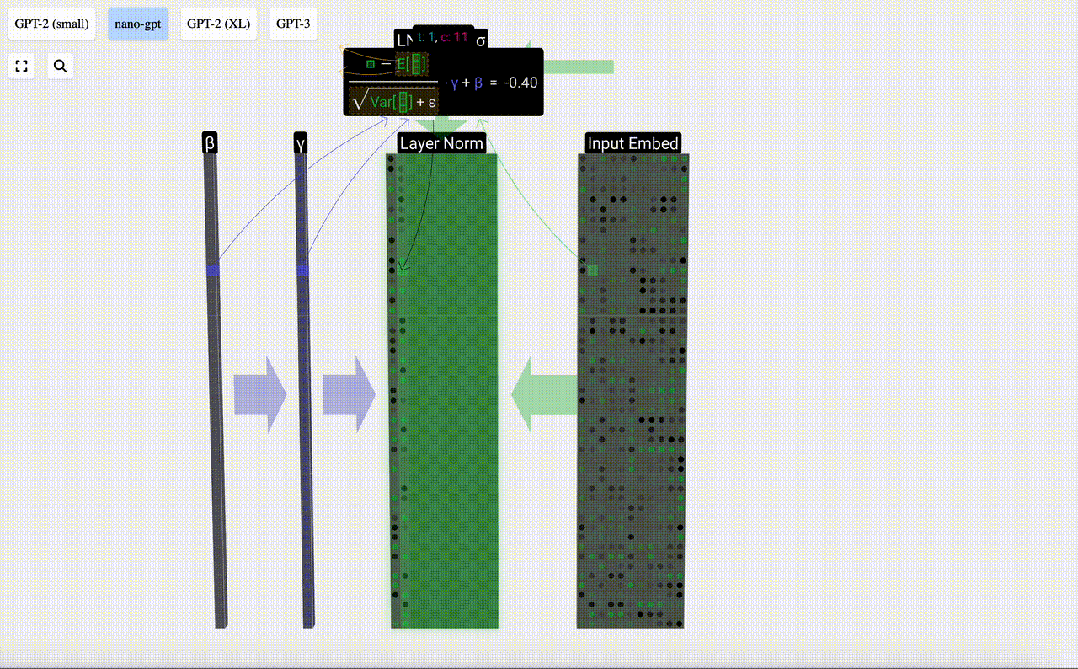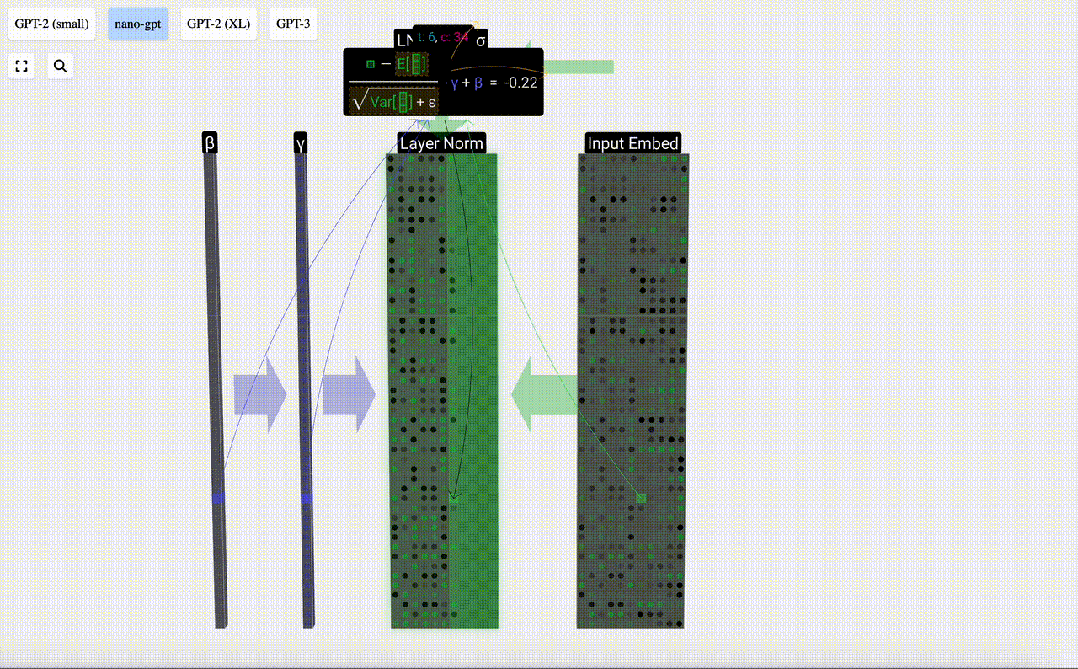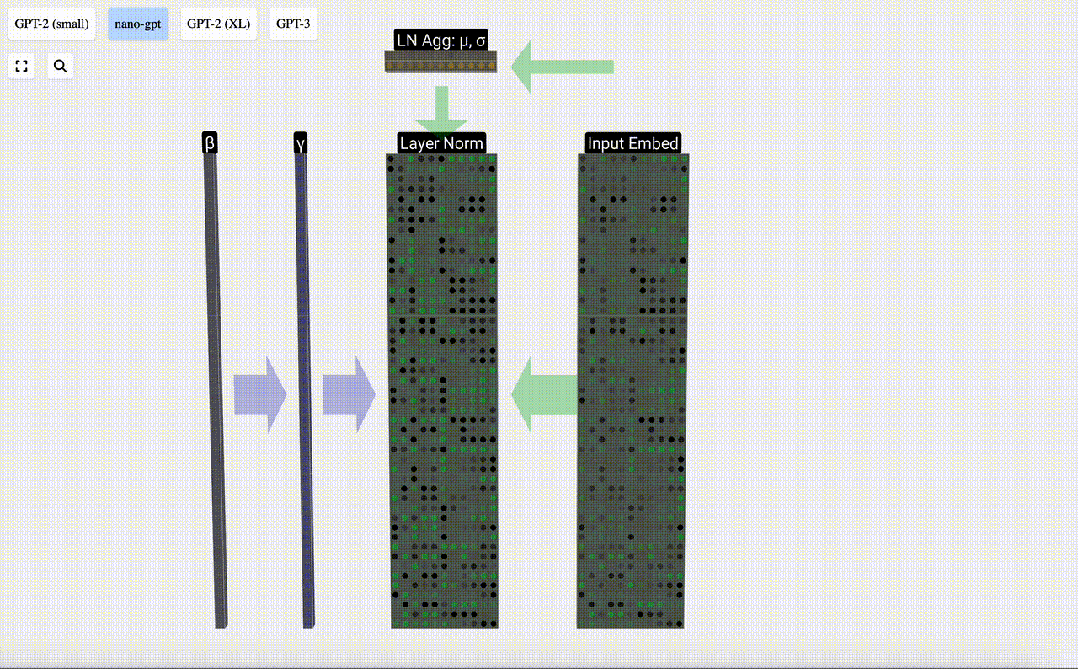
以前に取得した入力埋め込み行列は、Transformer レイヤーの入力です。
Transformer レイヤーの最初のステップは、入力埋め込み行列に対してレイヤー正規化を実行することです。これは、入力行列の各列の値を正規化する操作です。
正規化はディープ ニューラル ネットワーク トレーニングにおける重要なステップであり、トレーニング プロセス中のモデルの安定性の向上に役立ちます。
行列の列を個別に見てみましょう。以下では 4 番目の列を例として取り上げます。
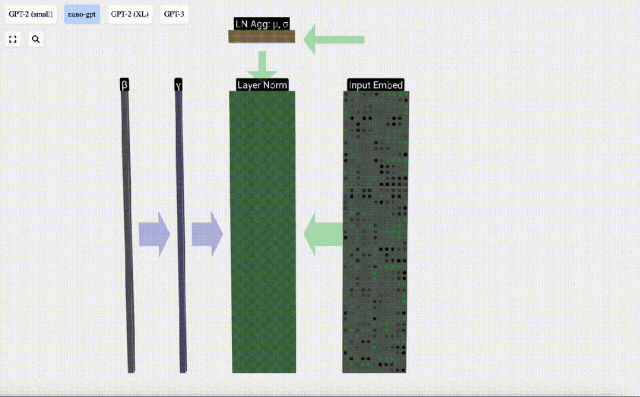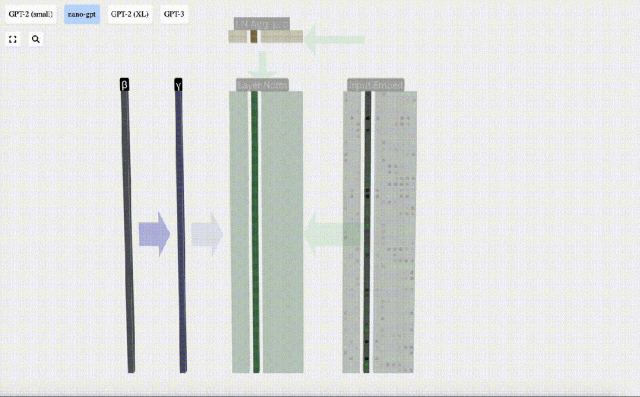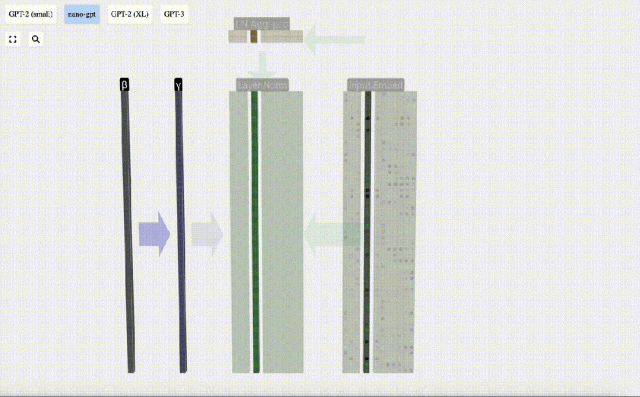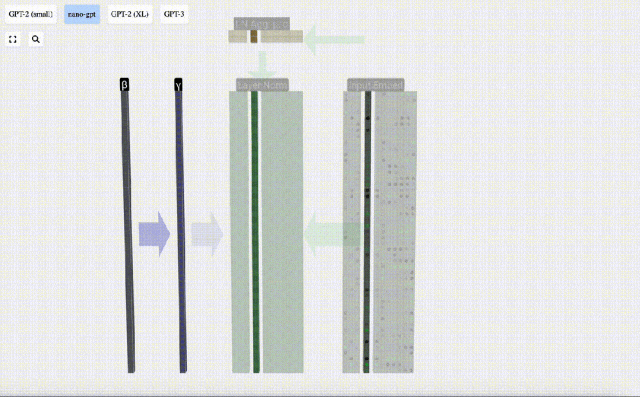
正規化の目標は、各列の平均値を 0、標準偏差を 1 にすることです。これを実現するには、各列の平均と標準偏差を計算し、対応する平均を減算し、各列の対応する標準偏差で割ります。
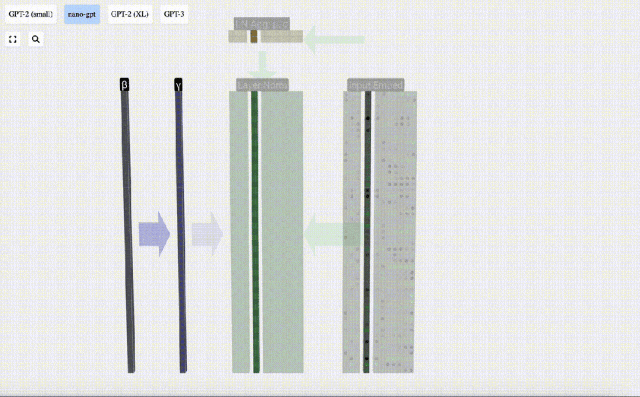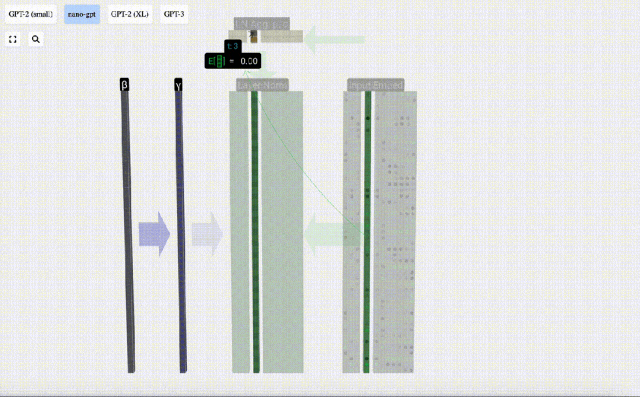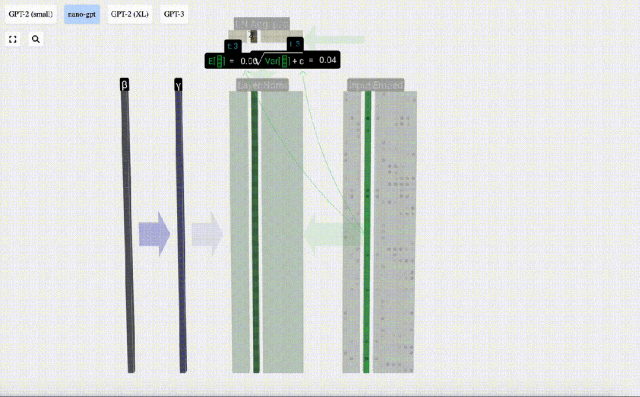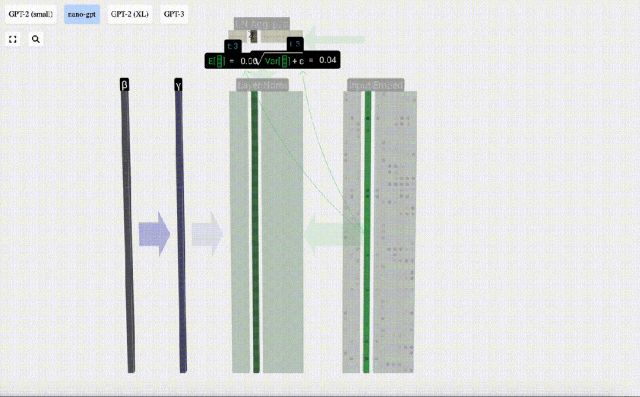
ここでは、E[x] は平均を表すために使用され、Var[x] は分散 (標準偏差の 2 乗) を表すために使用されます。 epsilon(ε = 1×10^-5) は 0 による除算エラーを防ぐためのものです。
正規化結果を計算して保存し、学習重みweight(γ)を乗算し、バイアスbias(β)を加算して、最終的な正規化結果を取得します。
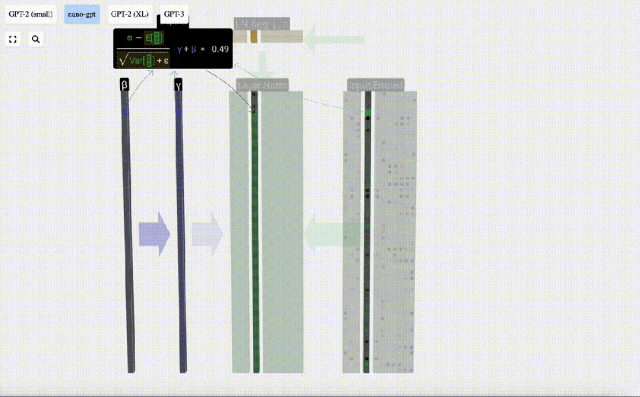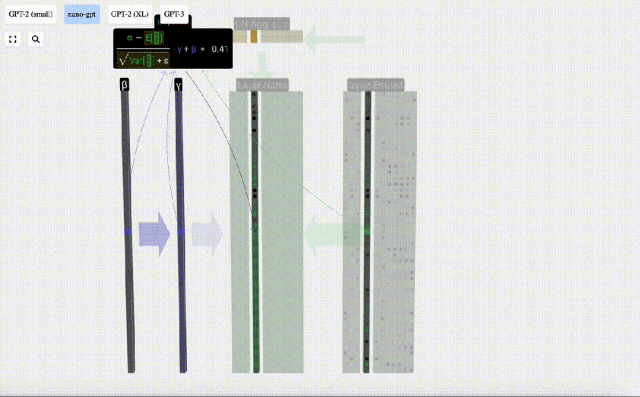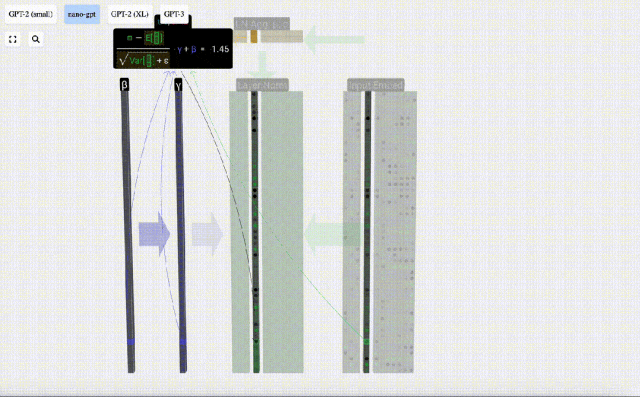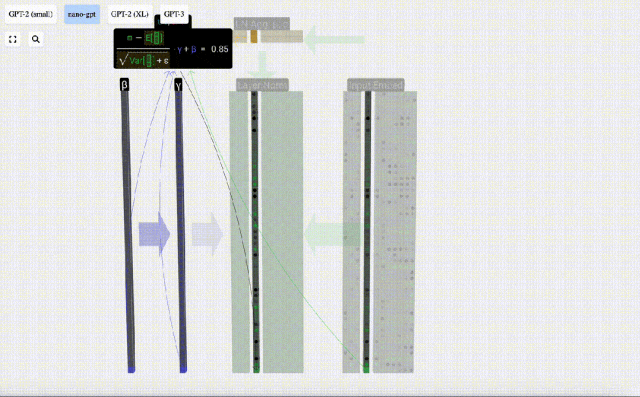
最後に、入力埋め込み行列の各列に対して正規化操作を実行して、正規化された入力埋め込みを取得し、それをセルフアテンション層に渡します。
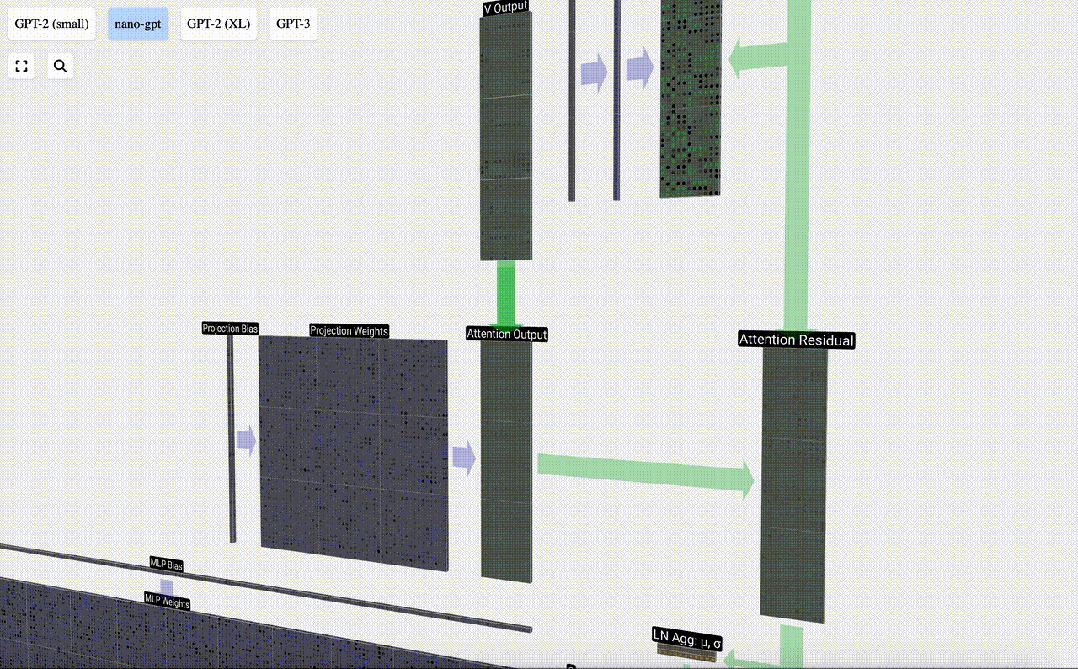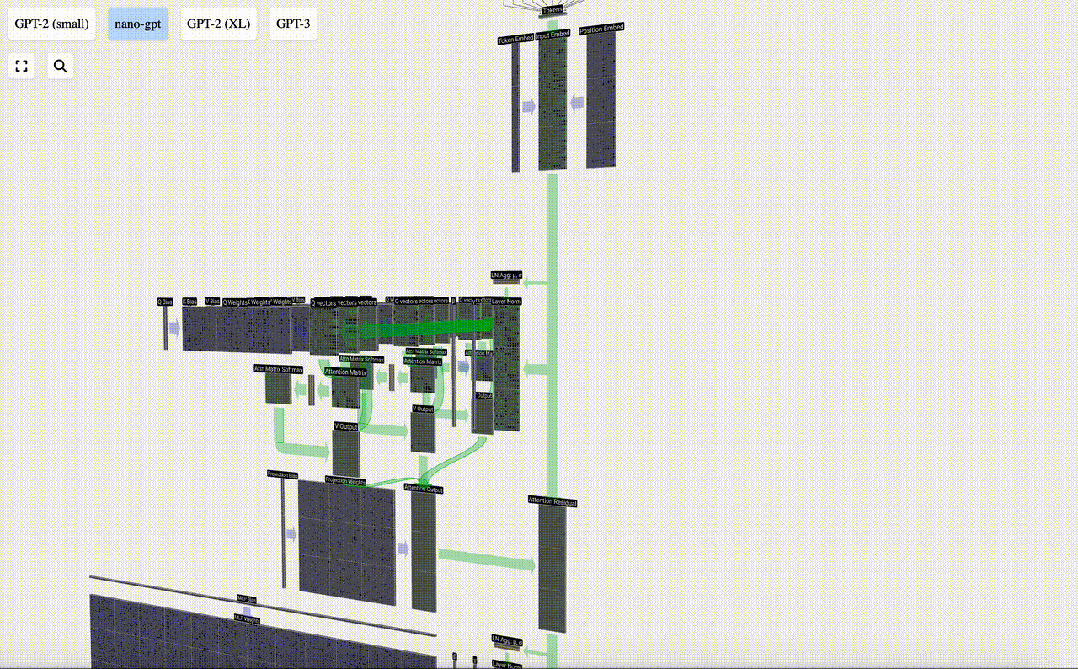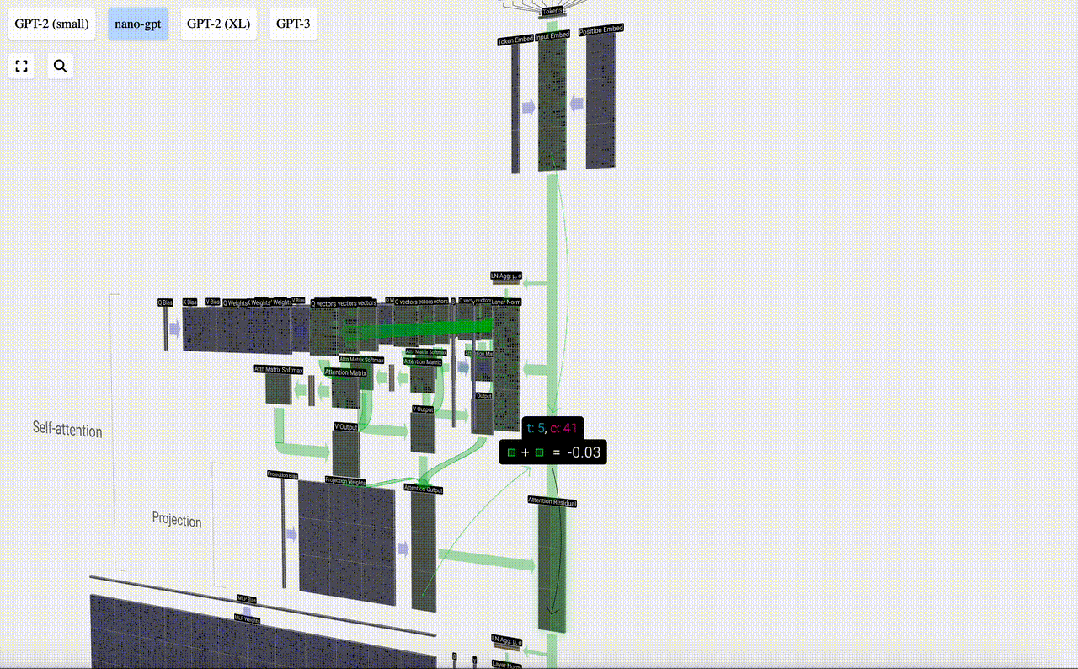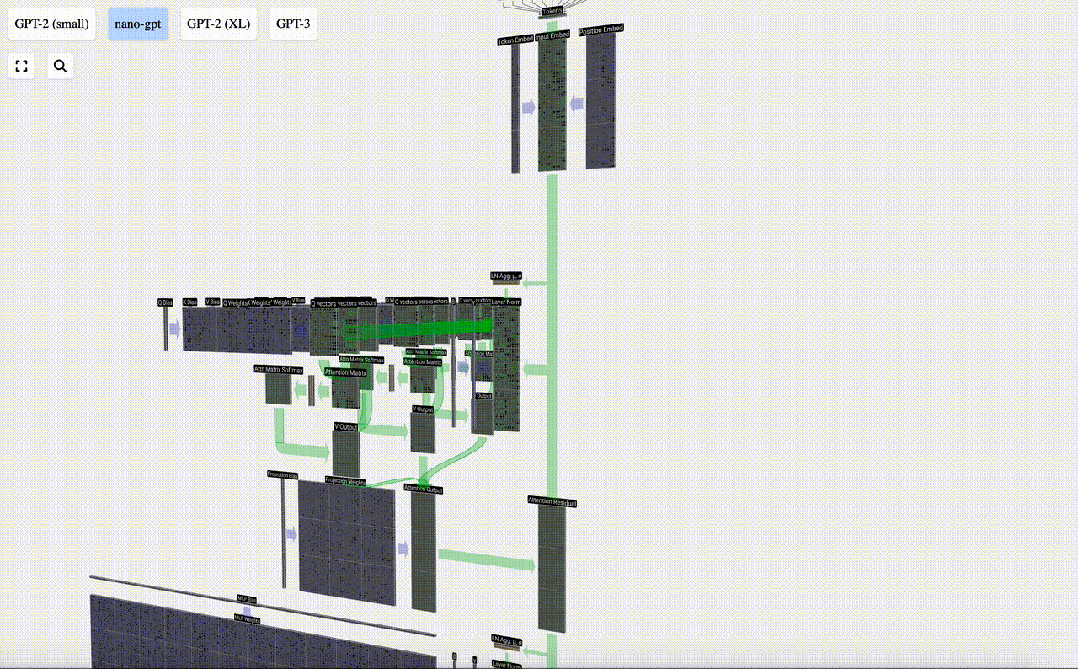
セルフ アテンション
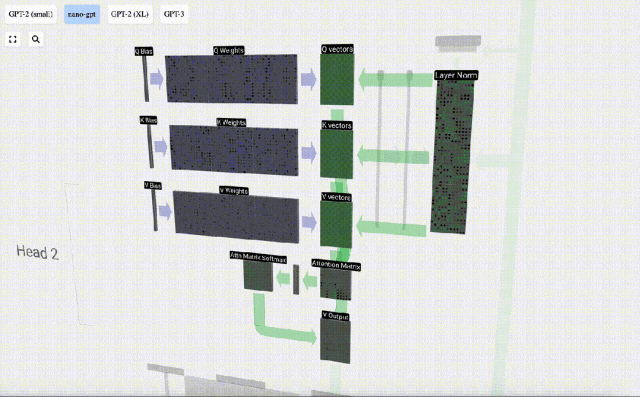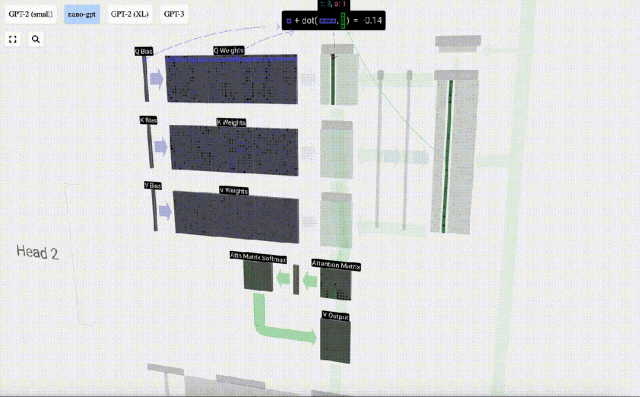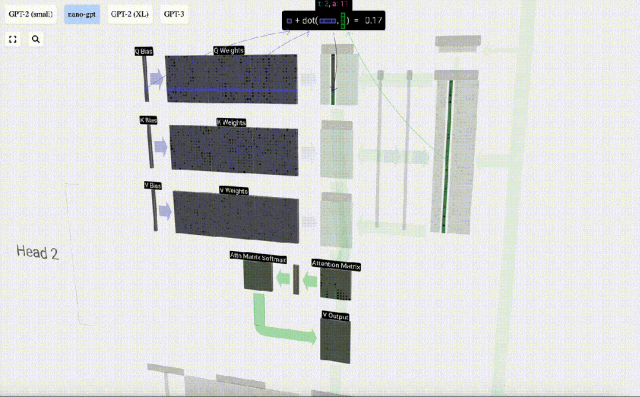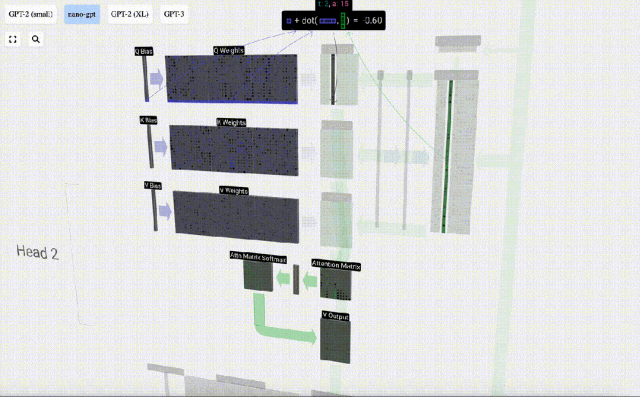
セルフ アテンション レイヤーは、おそらく Transformer のコア部分です。この段階では、入力埋め込み内の列は相互に「通信」できますが、他の段階では各列は独立して存在します。
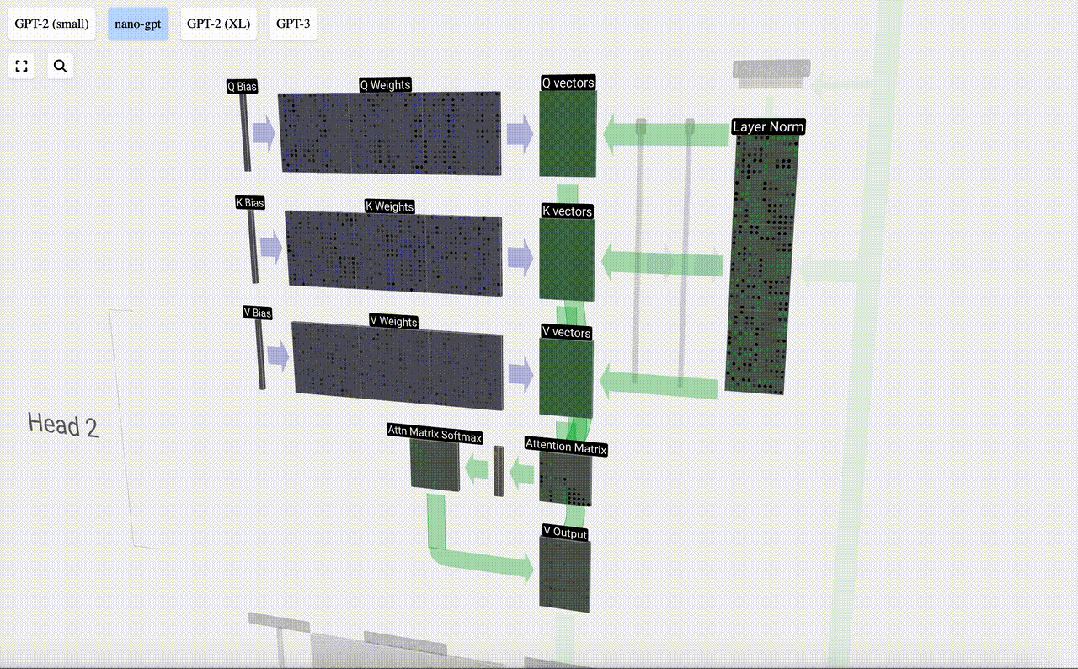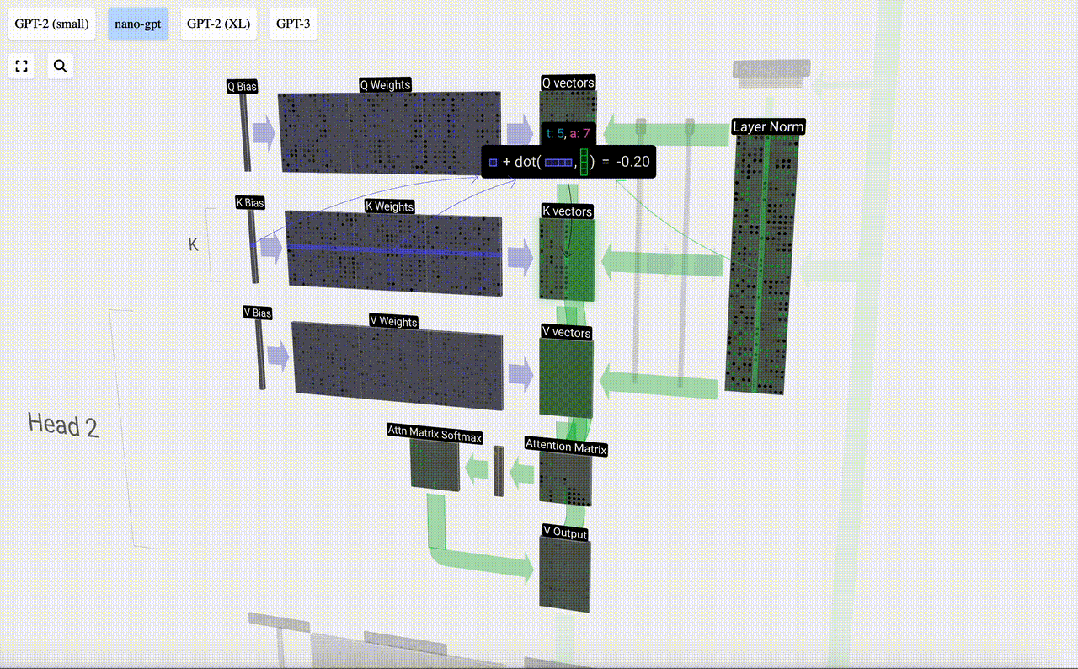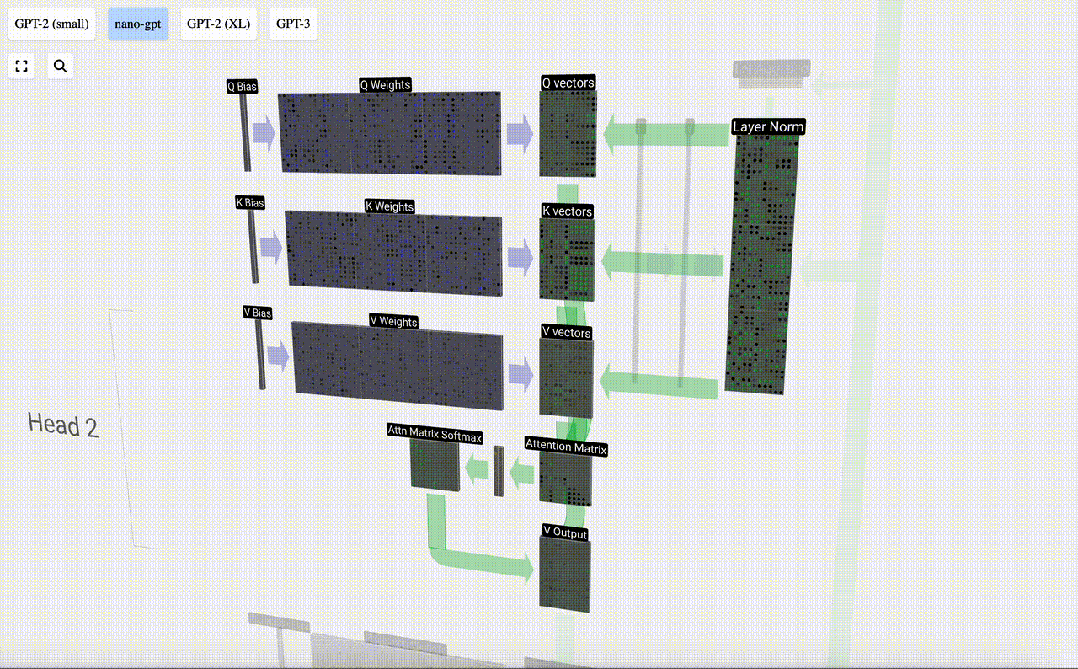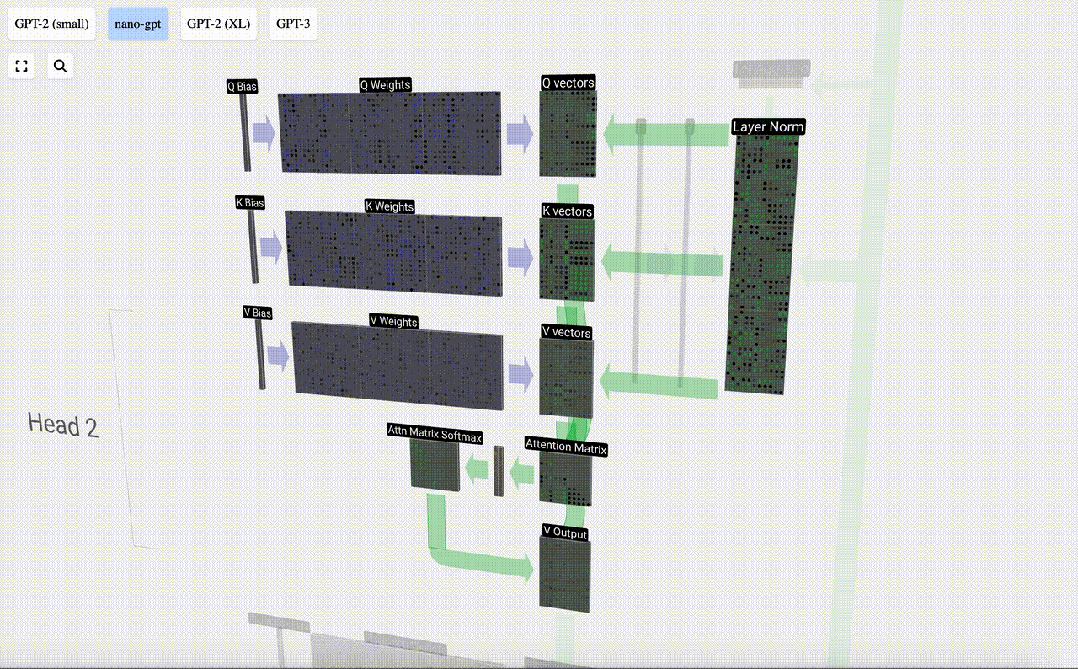
セルフ アテンション レイヤーは複数のセルフ アテンション ヘッドで構成されており、この例では 3 つのセルフ アテンション ヘッドがあります。各ヘッダーの入力は入力埋め込みの 1/3 ですが、ここではそのうちの 1 つにのみ焦点を当てます。

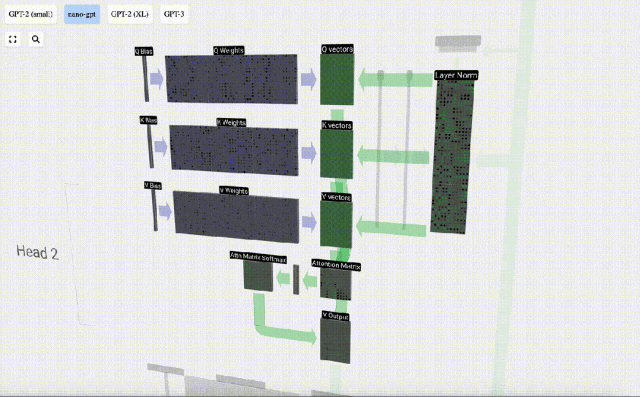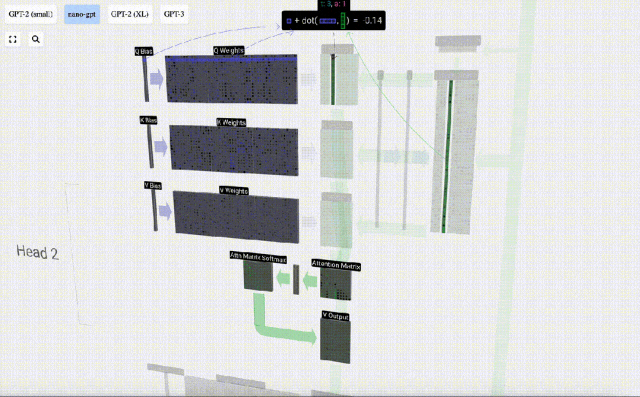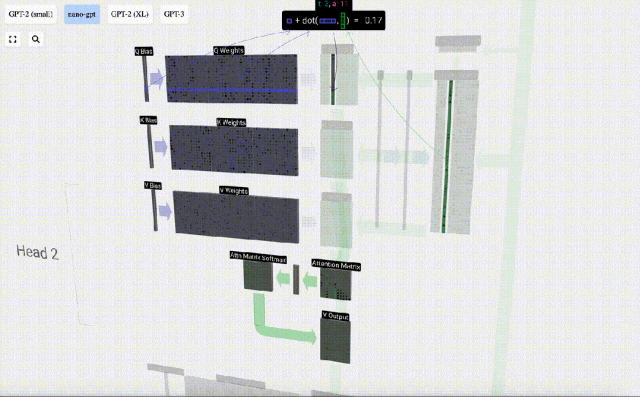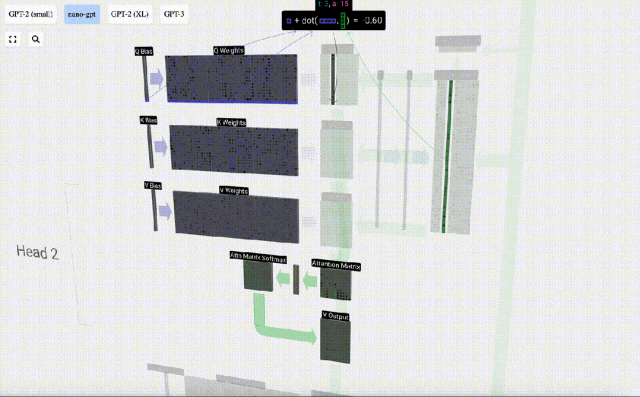
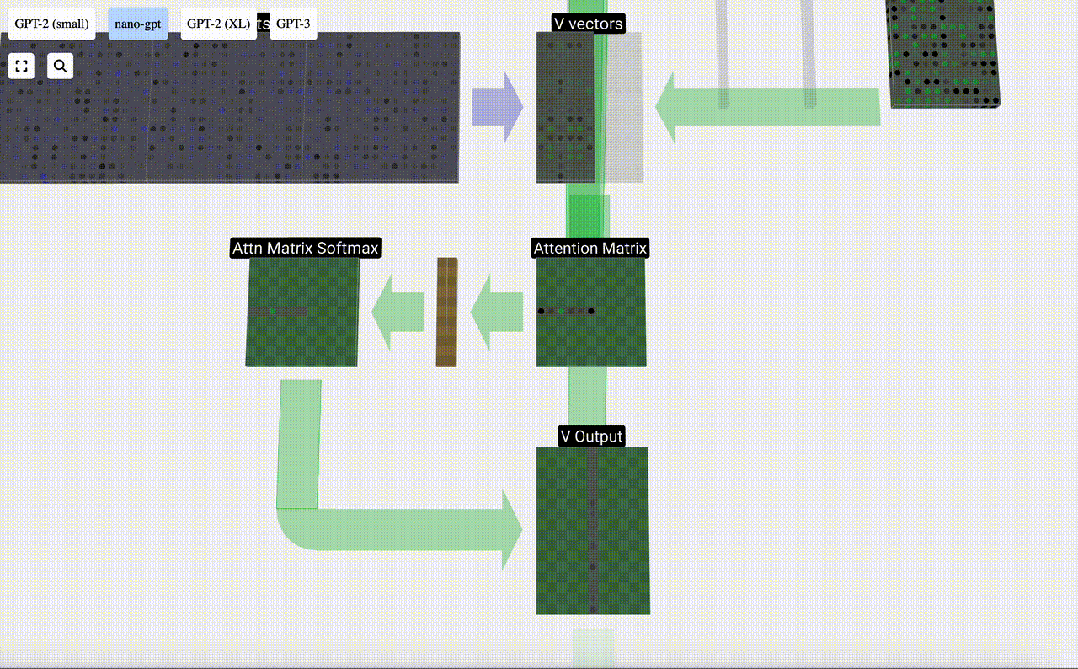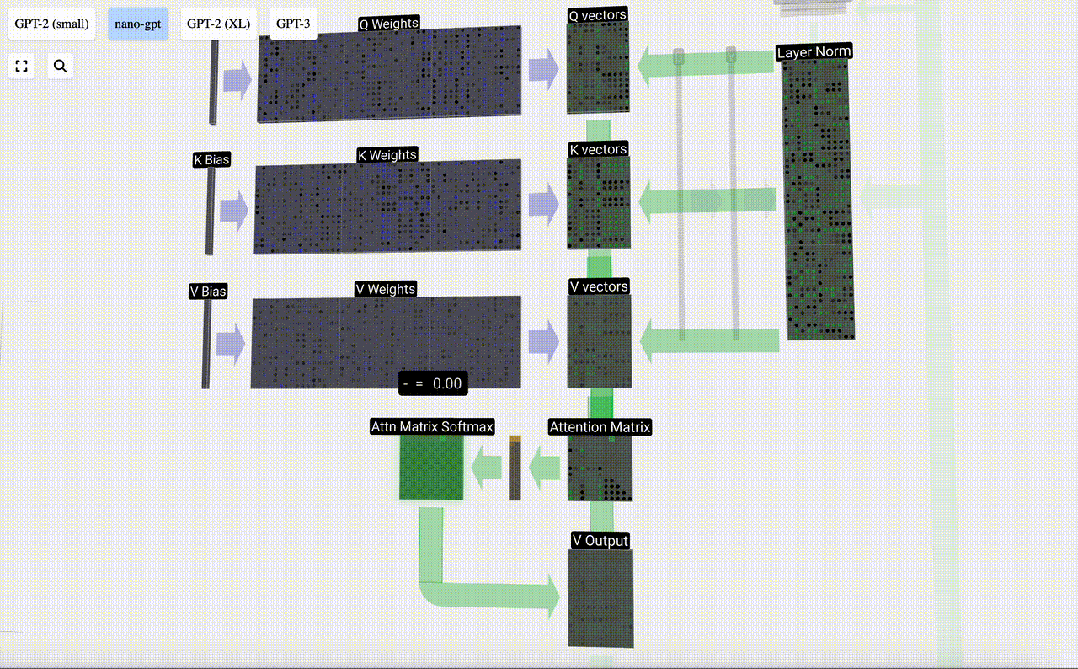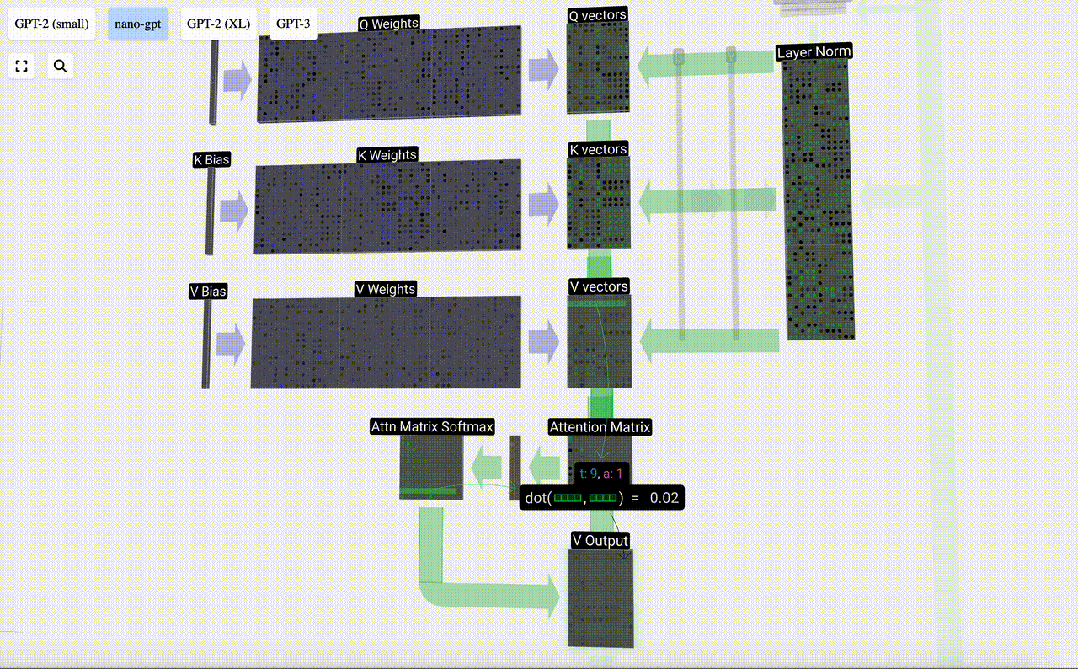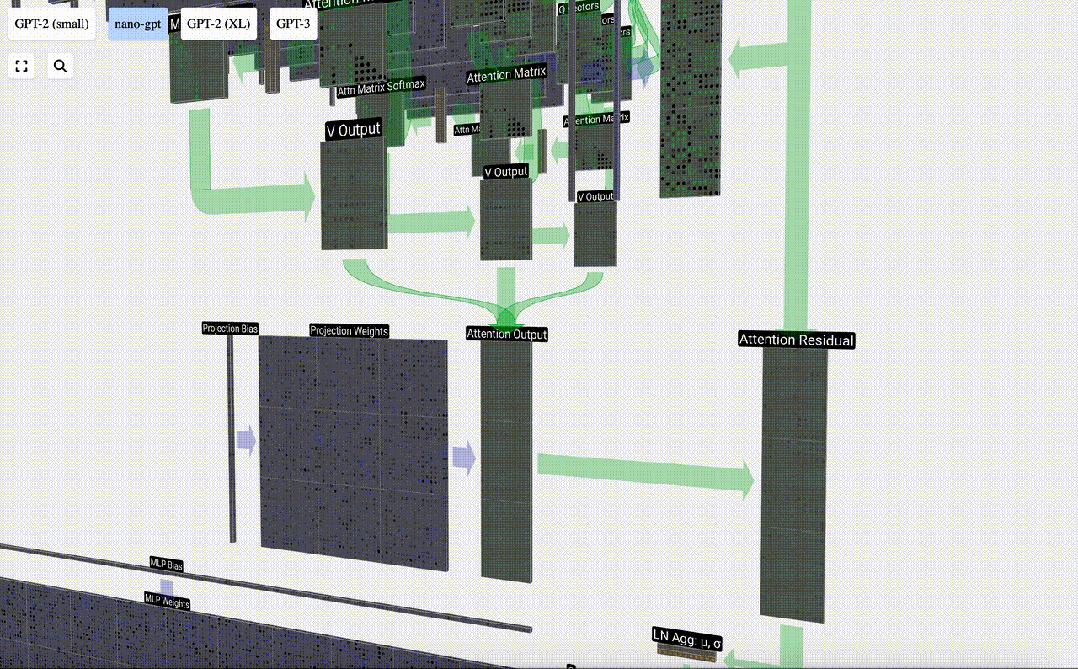
最初のステップは、正規化された入力埋め込み行列の列 C から列ごとに 3 つのベクトル (QKV:
- Q) を生成することです。 : クエリ ベクトル
- K: キー ベクトル キー ベクトル
- V: 値ベクトル値ベクトル
これらのベクトルを生成するには、行列とベクトルの乗算が必要です。バイアスが追加されています。 。各出力ユニットは入力ベクトルの線形結合です。
たとえば、クエリ ベクトルの場合、Q 重み行列の行と入力行列の列の間のドット積演算によって完成します。
#ドット積の演算は非常に簡単です。つまり、対応する要素を乗算して加算します。
これは、各出力要素が入力ベクトル内のすべての要素の影響を受けることを確認するための一般的で簡単な方法です (この影響は重みによって決まります)。そのため、ニューラルネットワークによく登場します。
ニューラル ネットワークでは、モデルがデータを処理するときに入力シーケンスのあらゆる部分を考慮できるため、このメカニズムが頻繁に発生します。この包括的な注意メカニズムは、特にテキストや時系列などの連続データを処理する場合、多くの最新のニューラル ネットワーク アーキテクチャの中核となります。
Q、K、V ベクトルの出力ユニットごとにこれを繰り返します。
Q (クエリ)、K の使用方法(キー) ベクトルと V (値) ベクトル?これらの名前はヒントを与えてくれます。「キー」と「値」は、キーが値にマッピングされる辞書タイプを彷彿とさせます。次に、値を見つけるために使用するのが「クエリ」です。

セルフ アテンションの場合、単一のベクトル (項) を返すのではなく、ベクトル (項) の重み付けされた組み合わせを返します。この重みを見つけるには、Q ベクトルと各 K ベクトルの間の内積を計算し、重み付けして正規化し、最後に対応する V ベクトルを乗算して加算します。

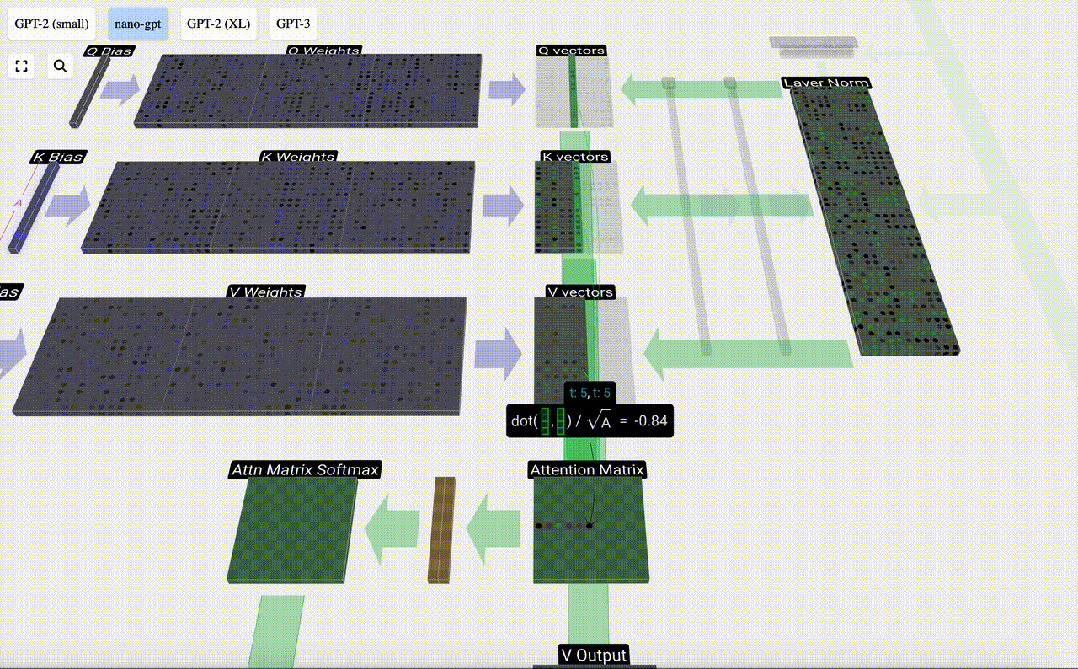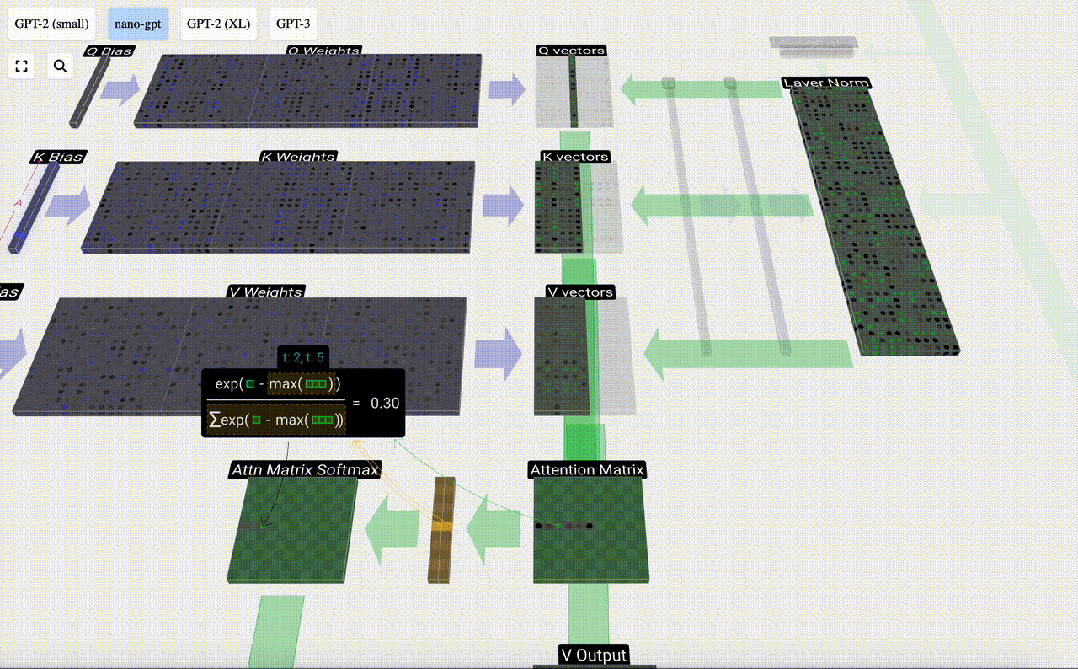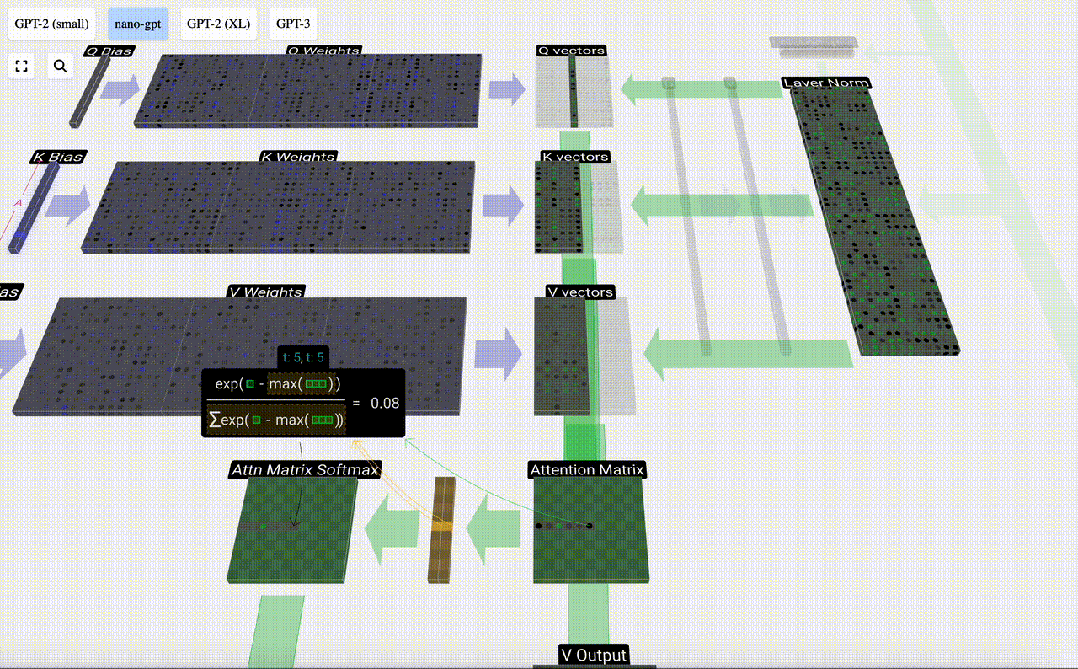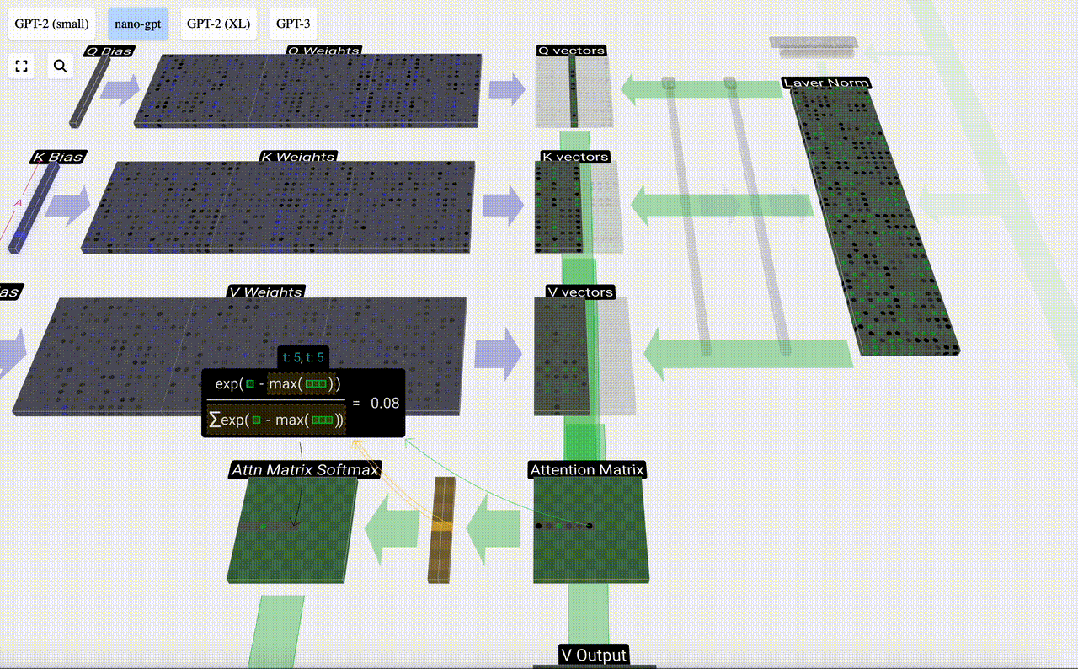
6 番目の列 (t=5) を例にとると、クエリはこの列から開始されます:
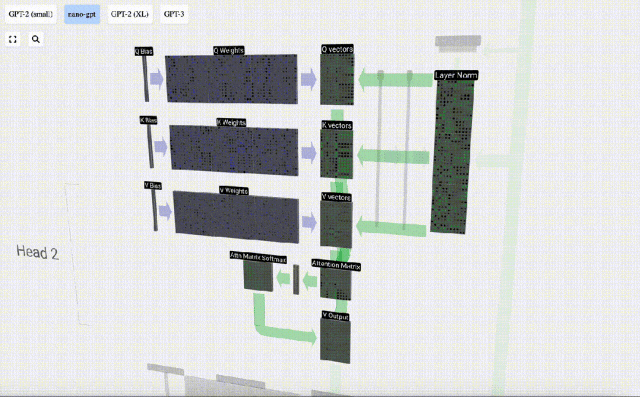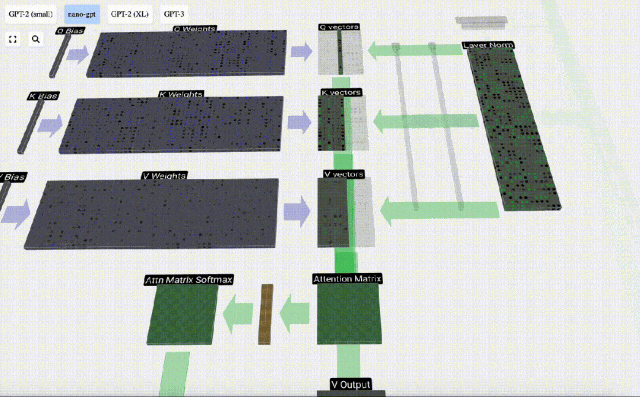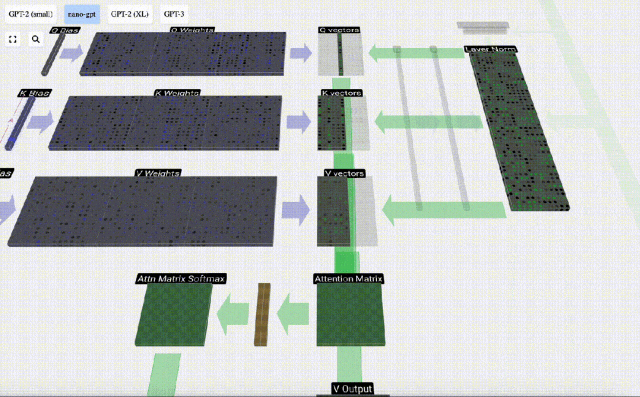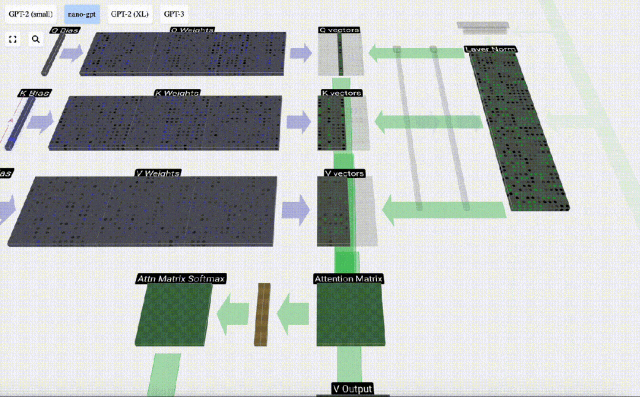
なぜなら アテンション行列の存在により、KV の最初の 6 列をクエリでき、Q 値が現在の時刻になります。
まず、現在の列 (t=5) の Q ベクトルと前の列 (最初の 6 列) の K ベクトルの間のドット積を計算します。これは、注目行列の対応する行 (t=5) に格納されます。
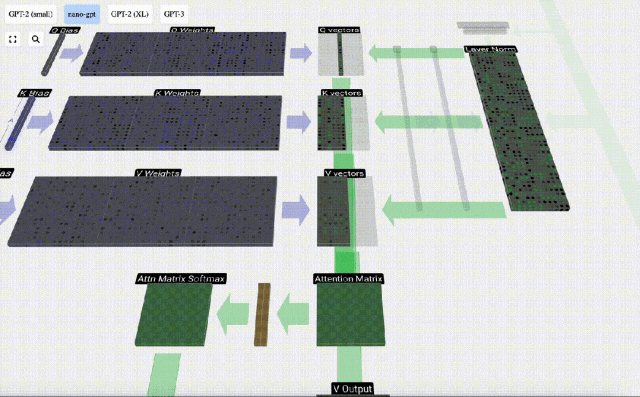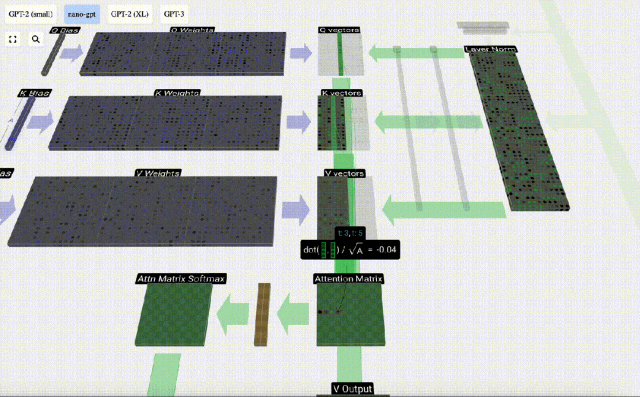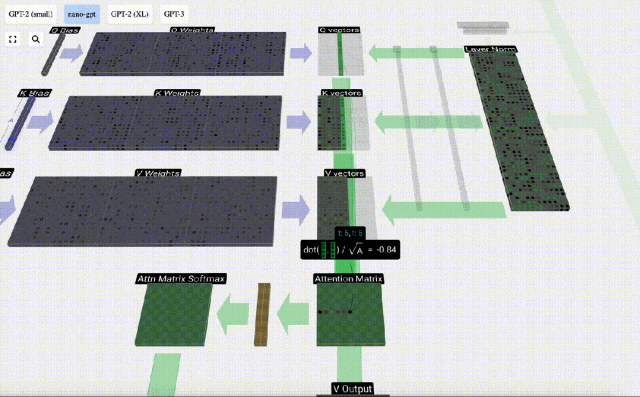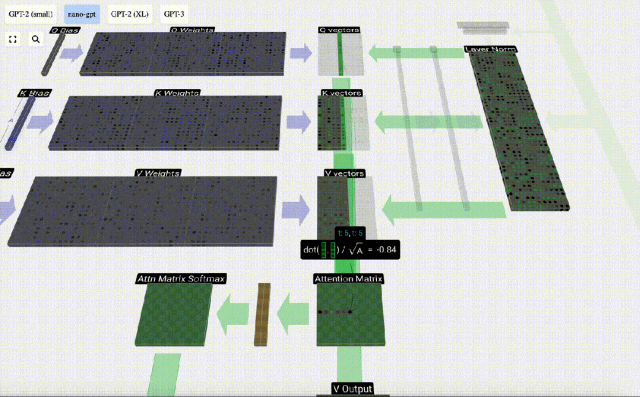
#内積のサイズは、2 つのベクトル間の類似性を測定します。内積が大きいほど、それらはより類似していることになります。
そして、Q ベクトルのみが過去の K ベクトルで操作され、因果的な自己注意になります。言い換えれば、トークンは「将来の情報を見る」ことができません。
したがって、ドット積を見つけた後、sqrt(A) で除算します (A は QKV ベクトルの長さです。このスケーリングは、正規化の次のステップで大きな値が使用されるのを防ぐために行われます) (ソフトマックス) 優勢。
次に、ソフトマックス演算を実行して、値の範囲を 0 ~ 1 に減らします。
#最後に、この列 (t=5) の出力ベクトルを取得できます。正規化されたアテンション行列の (t=5) 行を見て、各要素を他の列の対応する V ベクトルと乗算します。
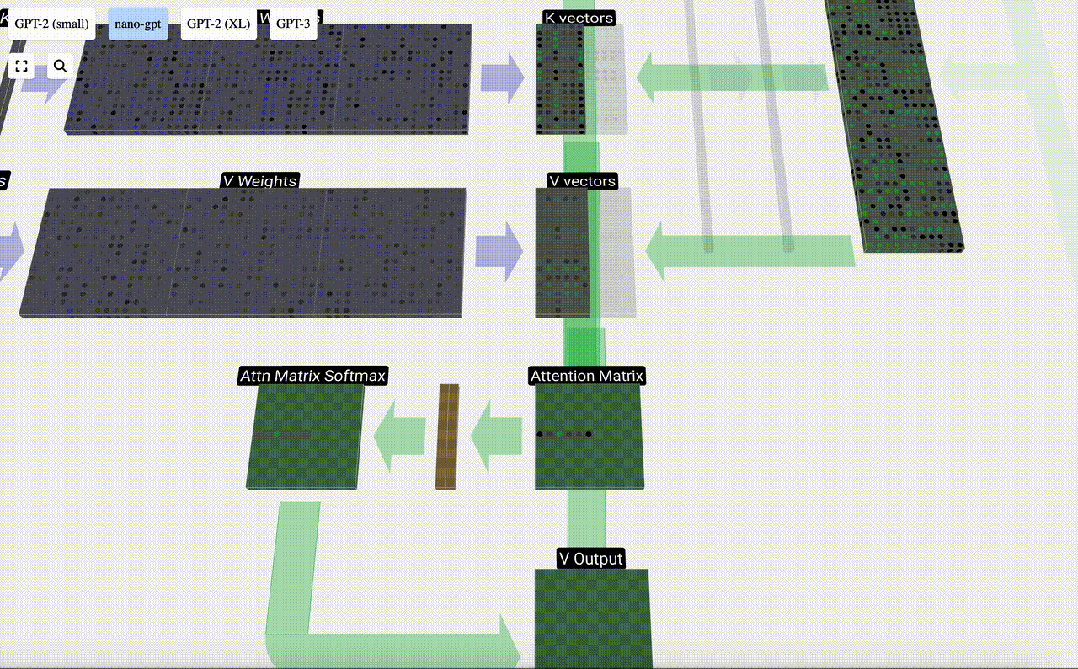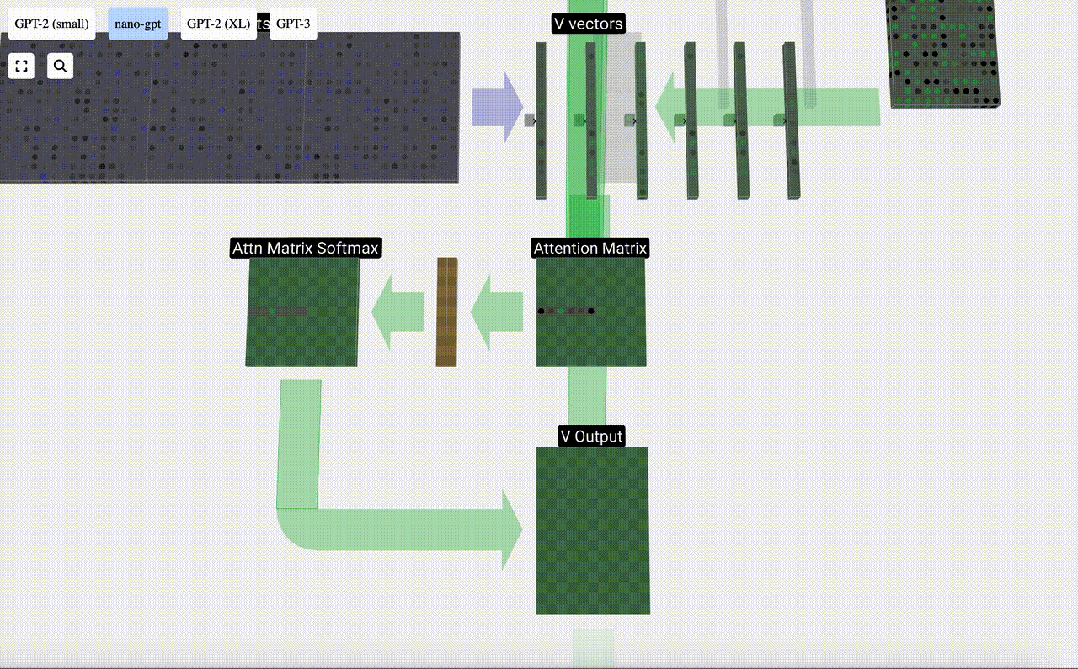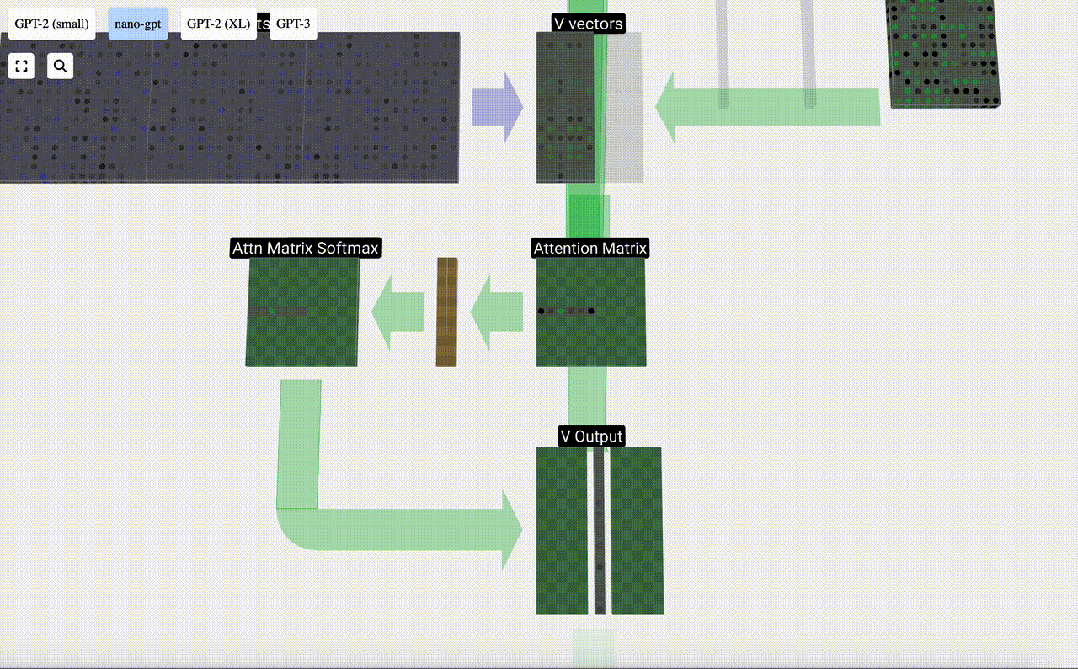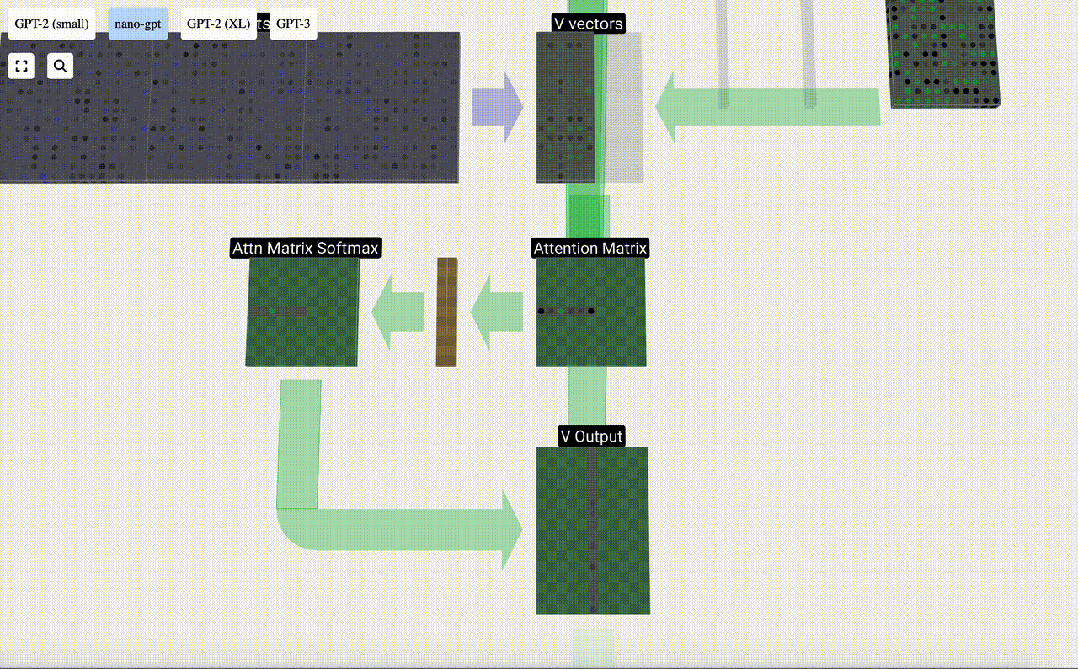
これらのベクトルを追加して出力ベクトルを取得します。したがって、出力ベクトルは高解像度の V ベクトルが大半を占めます。
次に、これをすべての列に適用します。
Self Attendant レイヤーのヘッダーの処理プロセスです。 「つまり、セルフ アテンションの主な目的は、各列が他の列から関連情報を見つけてその値を抽出することです。これは、そのクエリ ベクトルと他の列のキーを比較することによって行われます。追加された制限は、次のことしかできないことです。過去を見てください。」
投影
セルフ アテンション操作の後、各ヘッドから出力を取得します。これらの出力は、Q ベクトルと K ベクトルの影響を受けて適切にブレンドされた V ベクトルです。各ヘッドの出力ベクトルをマージするには、単純にそれらを積み重ねます。したがって、t=4 では、長さ A=16 の 3 つのベクトルを重ね合わせて、長さ C=48 の 1 つのベクトルを形成します。
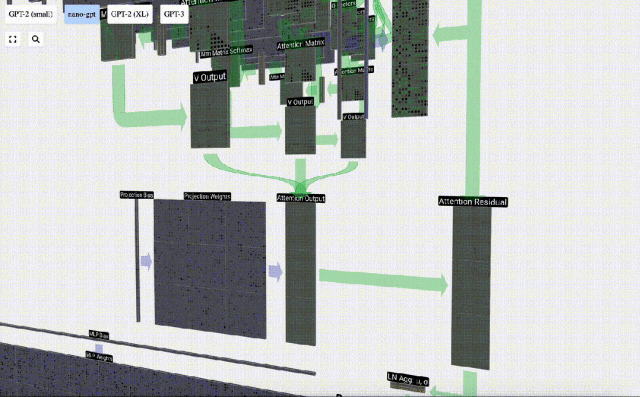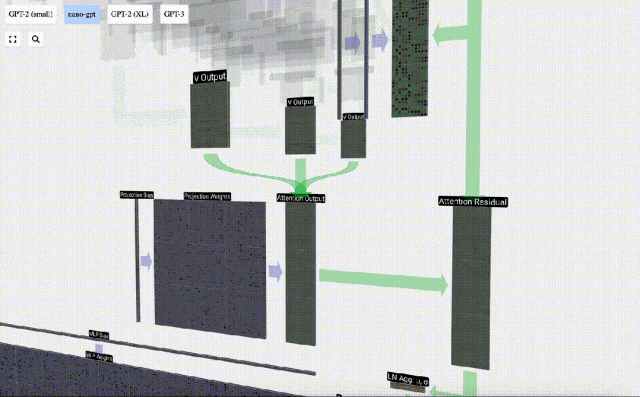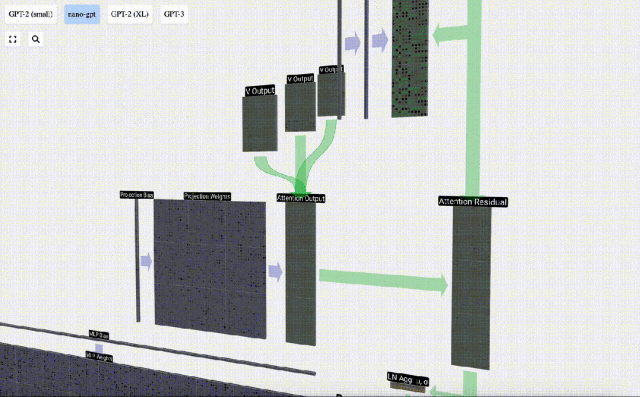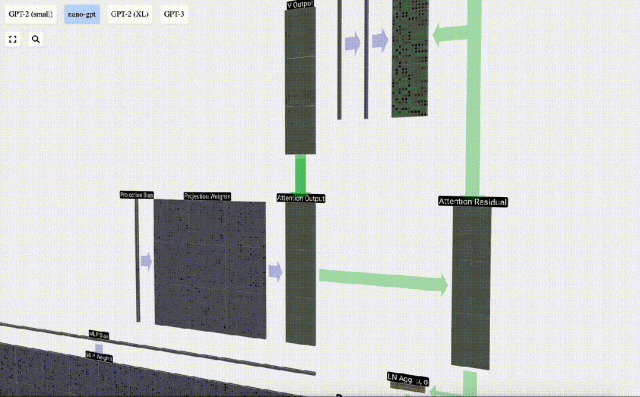
GPT では、head 内のベクトルの長さ (A=16) が C/num_heads に等しいことに注意してください。これにより、それらを重ね合わせたときに元の長さ C が得られます。
これに基づいて投影を実行し、このレイヤーの出力を取得します。これは、列ごとの単純な行列とベクトルの乗算にバイアスを加えたものです。
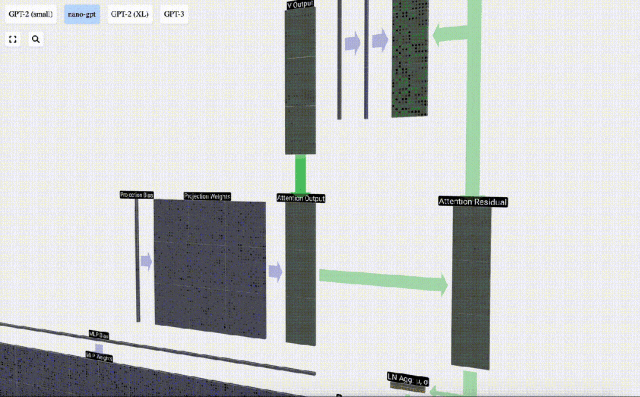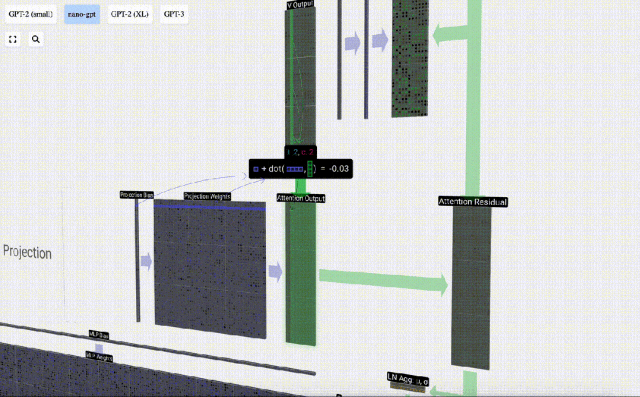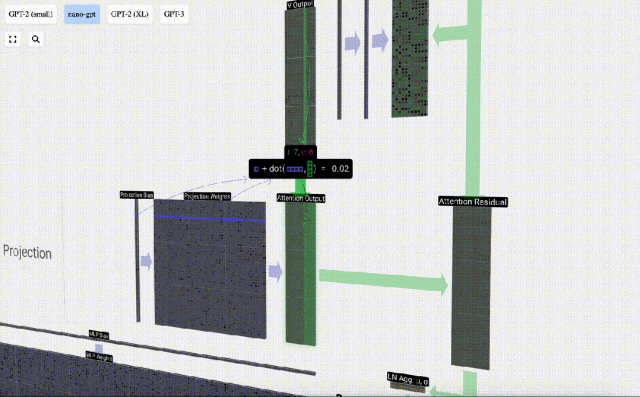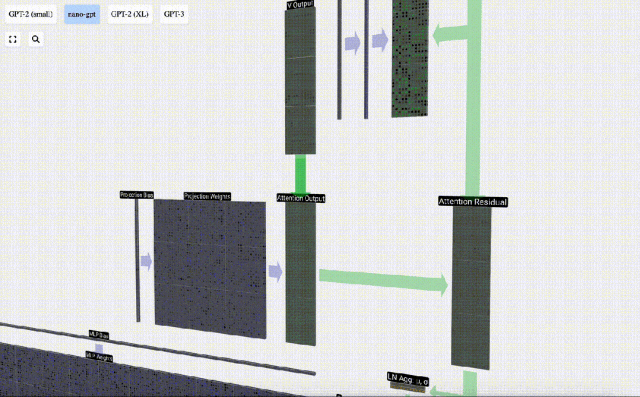
これで、Self Attend の出力が得られました。
この出力を次のステージに直接渡すのではなく、要素として入力埋め込みに追加します。緑色の垂直矢印で表されるこのプロセスは、残留接続または残留経路と呼ばれます。
層正規化と同様、残差ネットワークはディープ ニューラル ネットワークの効果的な学習を実現するために重要です。
自己注意の結果が得られたので、それを Transformer の次の層であるフィードフォワード ネットワークに渡すことができます。
多層パーセプトロン MLP
セルフ アテンションの後、Transformer モジュールの次の部分は MLP (多層パーセプトロン) です。ここでは 2 層の単純なニューラル ネットワークです。
セルフ アテンションと同様に、ベクトルが MLP に入る前にレイヤーの正規化を実行する必要があります。
同時に、MLP では、長さ C=48 の各列ベクトルを次のように (独立して) 処理する必要があります。
- バイアス付きの線形変換を追加します (つまり、 、行列とベクトルの乗算とオフセット演算)、長さ 4 * C のベクトルに変換されます。
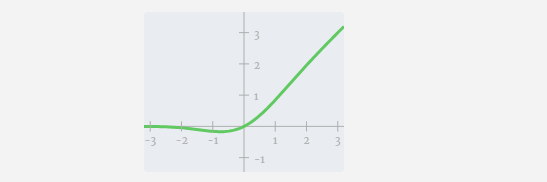
- GELU アクティベーション関数 (要素ごとに適用)。
- バイアスを使用して線形変換を実行し、それを長さ C のベクトルに変換し直します。
ベクトルの 1 つをトレースしましょう:

MLP プロセスは次のとおりです:
最初に行列ベクトルを実行します。乗算とバイアスの加算により、ベクトルは長さ 4*C の行列に拡張されます。 (ここでの出力行列は視覚化のために転置されていることに注意してください)
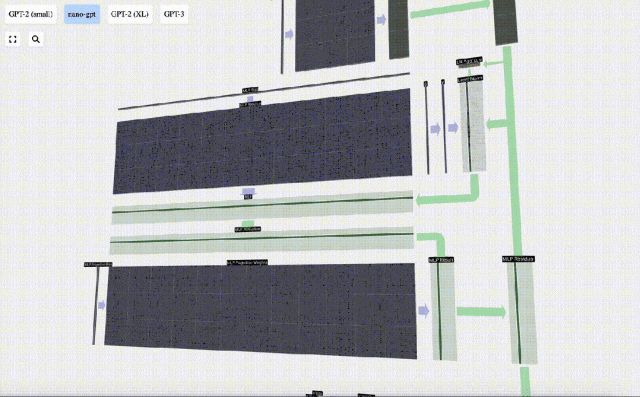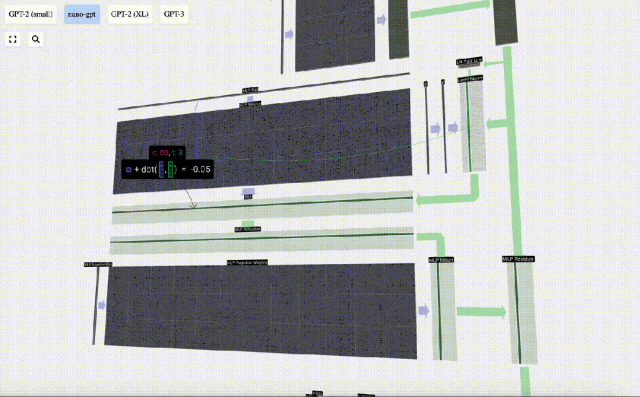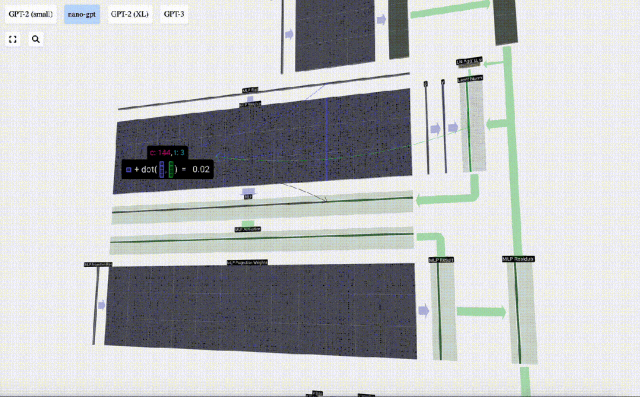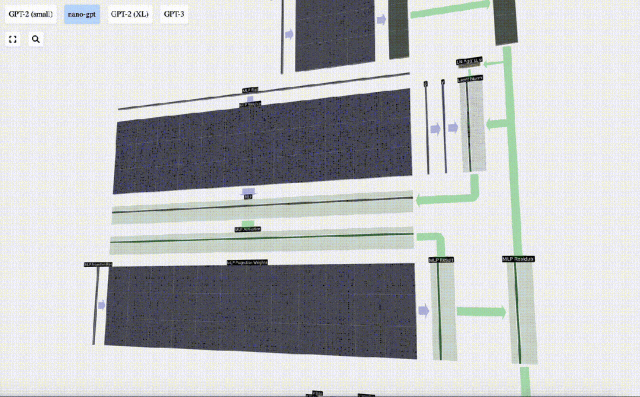
次に、GELU 活性化関数をベクトルの各要素に適用します。これはニューラル ネットワークの重要な部分であり、モデルに非線形性を導入する必要があります。使用される特定の関数 GELU は、ReLU 関数 max(0, x) によく似ていますが、鋭い角ではなく滑らかな曲線を持っています。
次に、ベクトルは、別のバイアスされた行列とベクトルの乗算によって長さ C に射影されます。
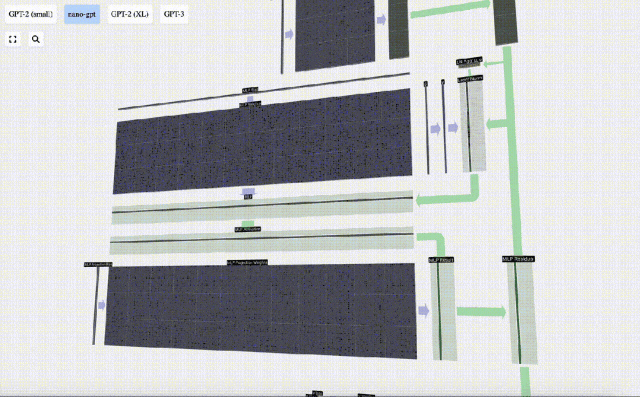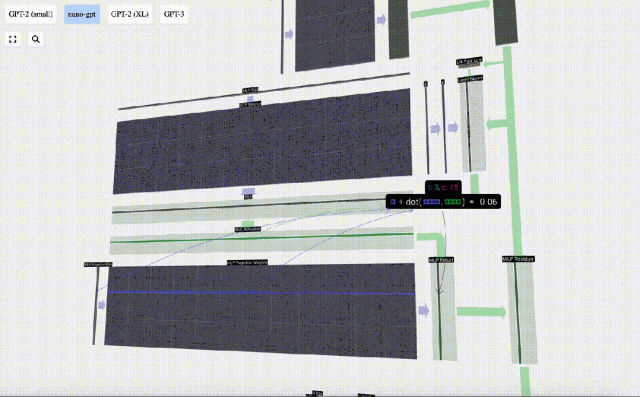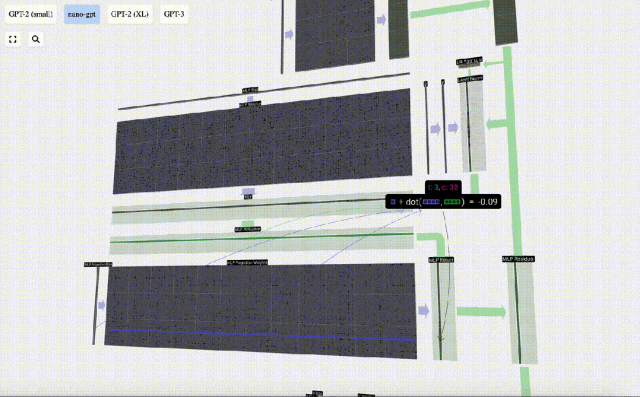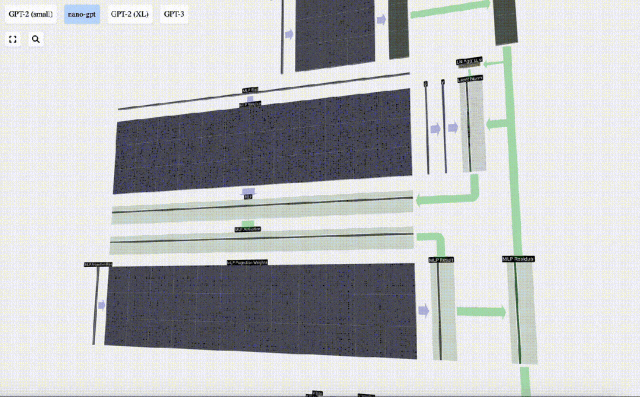
ここにも残差ネットワークがあり、自己注意投影部分と同様に、MLP の結果を要素順に入力に追加します。
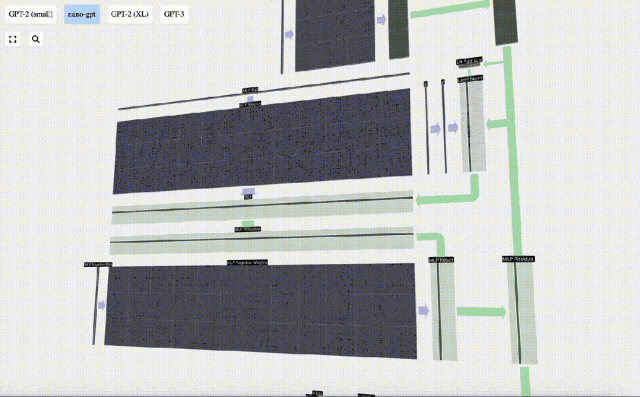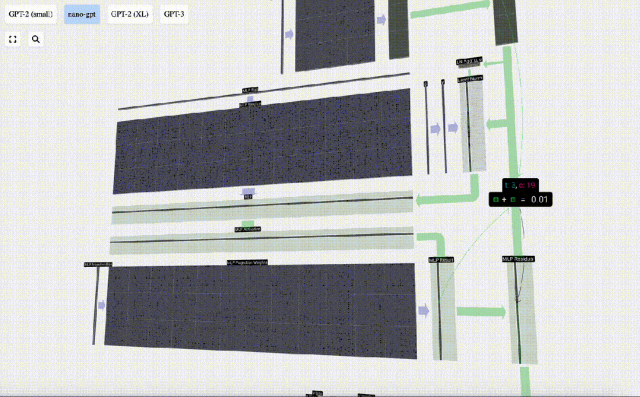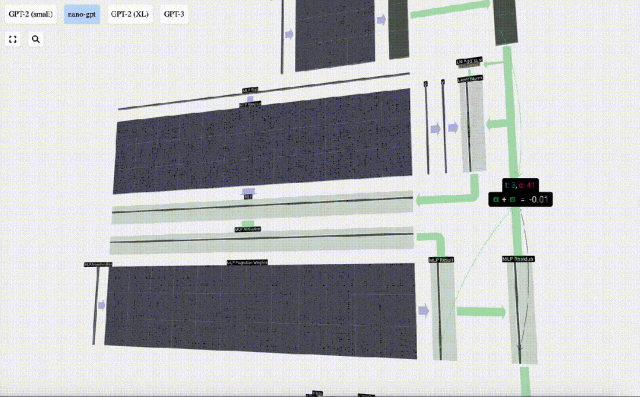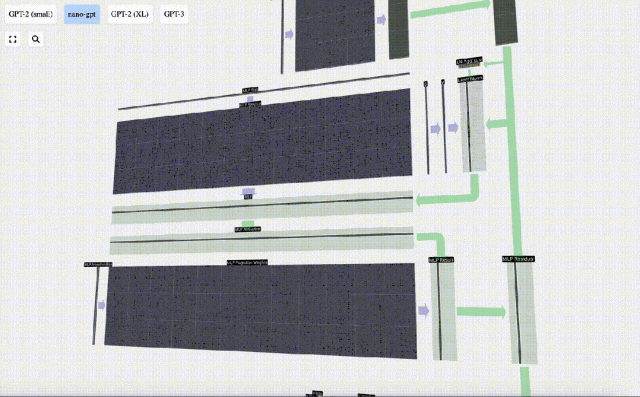
これらの操作を繰り返します。
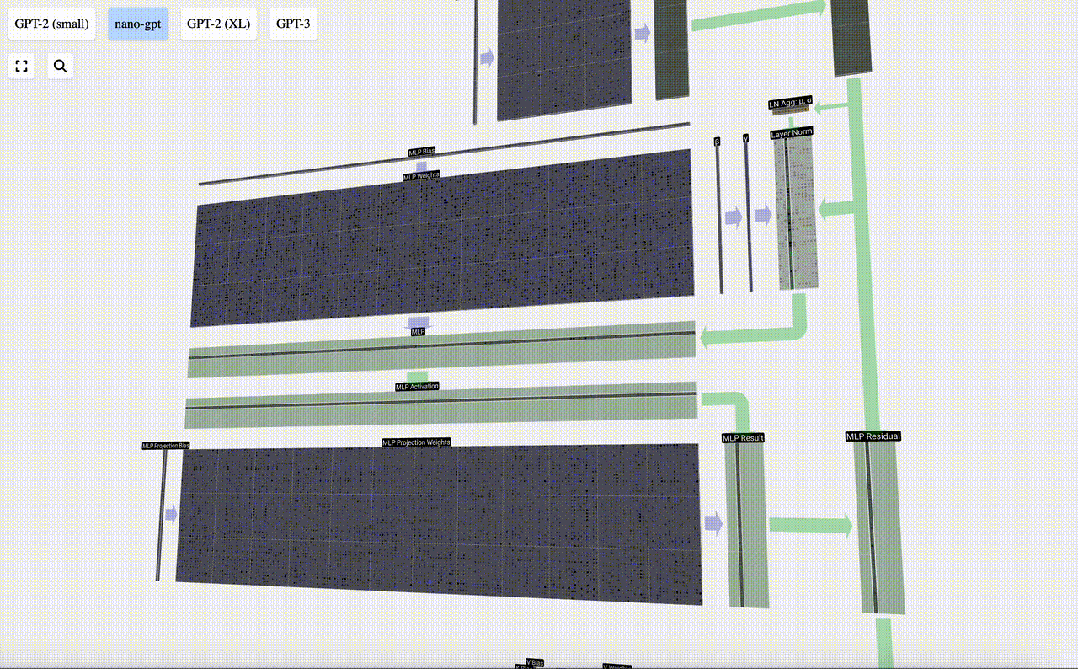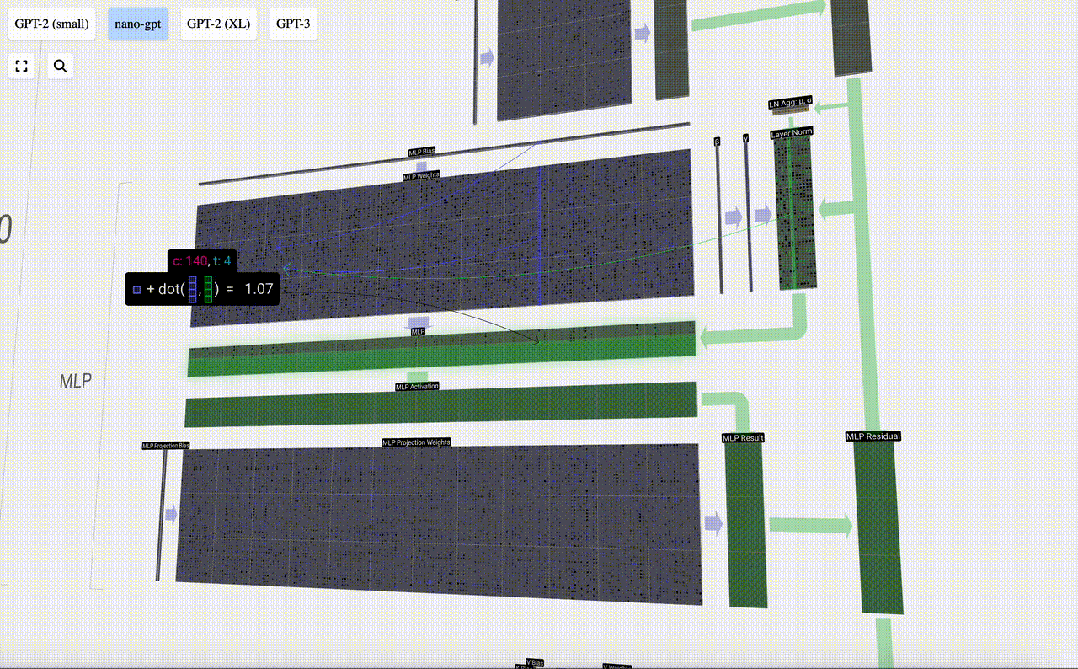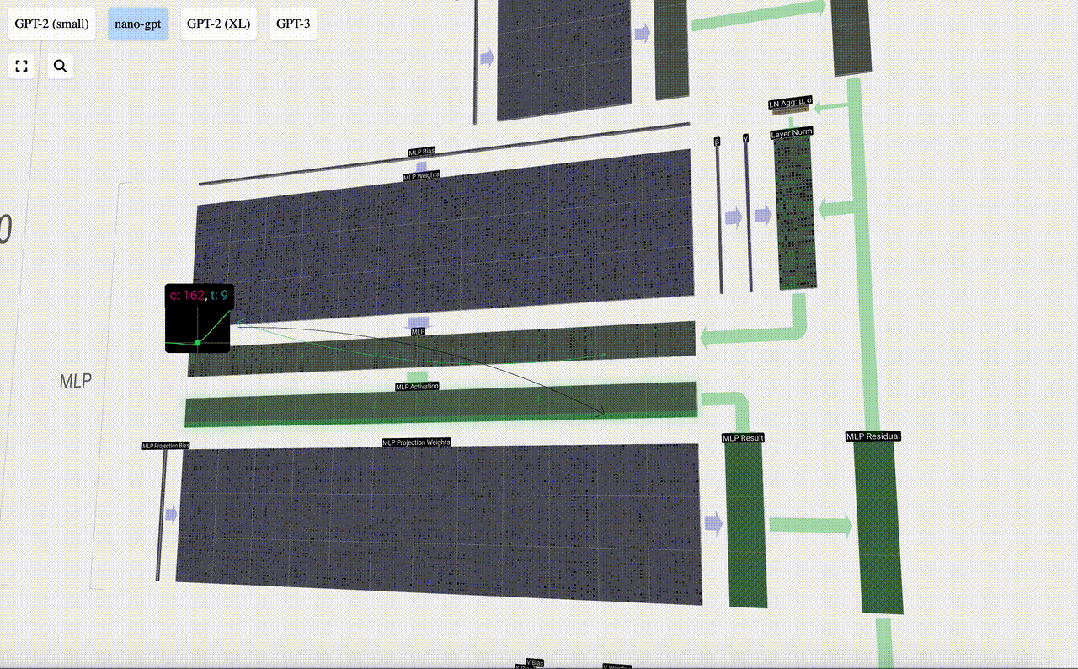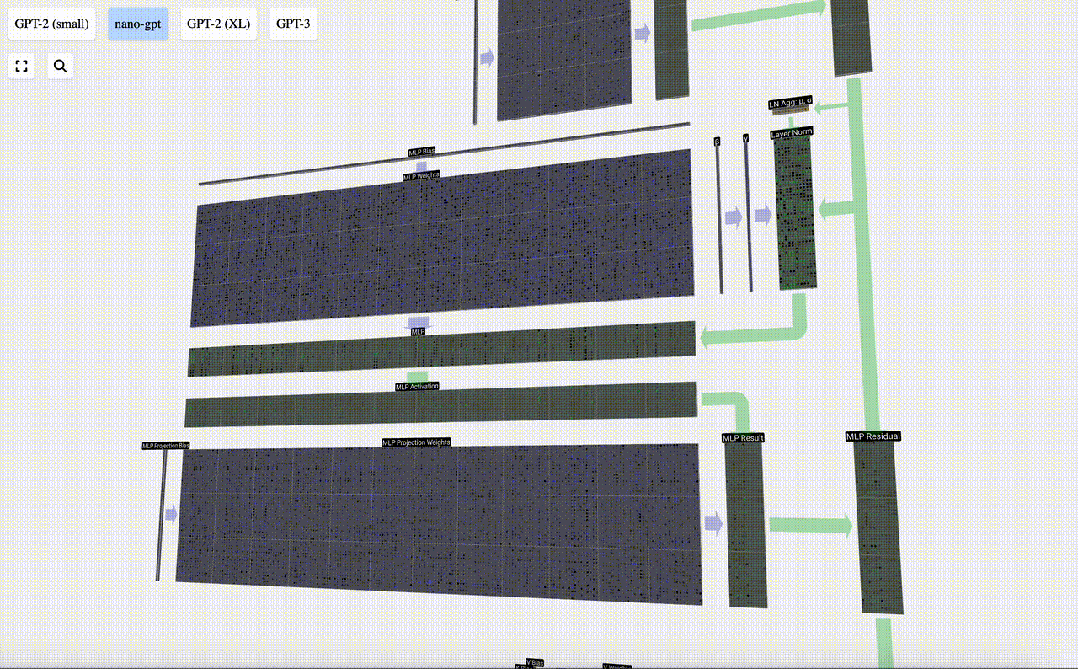
#MLP 層はここで終了し、最後にトランスフォーマーの出力を取得します。
Transformer
これは完全な Transformer モジュールです!
これらのいくつかのモジュールは GPT モデルの本体を構成し、各モジュールの出力は次のモジュールの出力となります。モジュールに入ります。
ディープラーニングではよくあることですが、これらの各層が何をしているのかを正確に伝えることは困難ですが、一般的なアイデアはいくつかあります。初期の層は低レベルの機能とパターンの学習に焦点を当てる傾向があり、後の層は低レベルの機能とパターンの学習に焦点を当てる傾向があります。層は低レベルの特徴やパターンを学習することに重点を置く傾向がありますが、層はより高いレベルの抽象化や関係を認識して理解することを学びます。自然言語処理のコンテキストでは、下位層は文法、構文、および単純な語彙の関連付けを学習する可能性があり、一方、上位層はより複雑な意味関係、談話構造、および文脈依存の意味を捕捉する場合があります。
Softmax
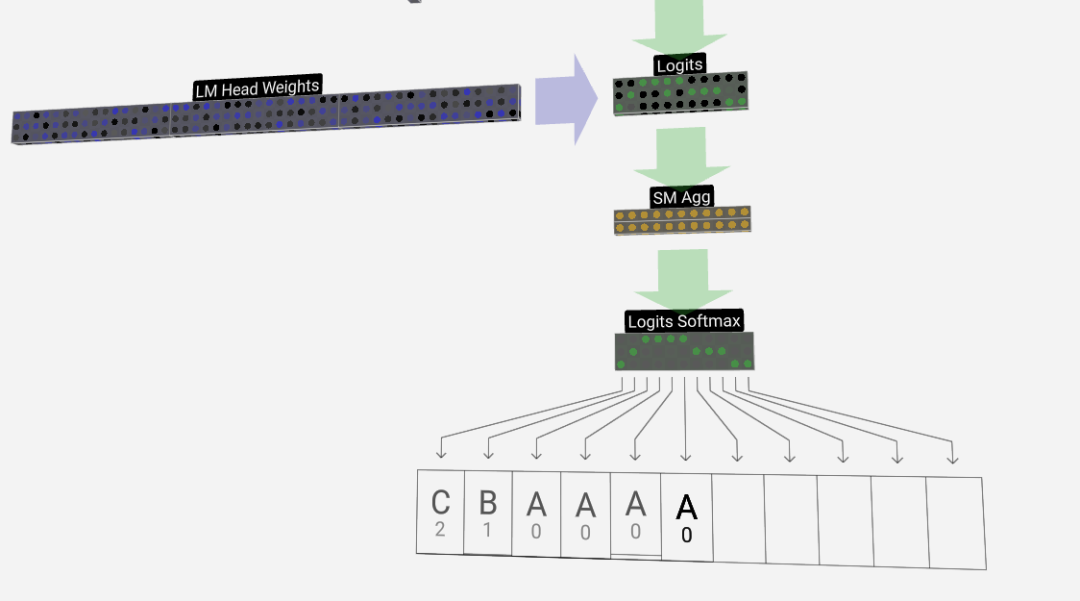
最後のステップは、各トークンの予測確率を出力するソフトマックス操作です。
出力
ついに、モデルの最後に到達します。最後の Transformer の出力は、正則化の層を経て、不偏線形変換が続きます。
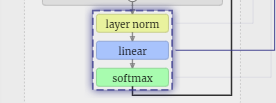
この最後の変換では、各列ベクトルを長さ C から語彙サイズの長さ nvocab に変換します。したがって、実際には語彙内の各単語のスコア ロジッツが生成されます。
これらのスコアをより直観的な確率値に変換するには、最初にソフトマックスを通じて処理する必要があります。したがって、各列について、モデルが語彙内の各単語に割り当てられる確率を取得します。
この特定のモデルでは、3 文字の順序に関するすべての答えを実際に学習しているため、確率は正しい答えに大きく傾いています。
モデルを時間の経過とともに進める場合、最後の列の確率を使用して、シーケンス内に次に追加されるトークンを決定する必要があります。たとえば、モデルに 6 つのトークンを入力した場合、6 列目の出力確率を使用します。
この列の出力は一連の確率値であり、実際にはそこからシーケンス内の次のトークンとして 1 つを選択する必要があります。これは、「分布からのサンプリング」、つまり確率に基づいてトークンをランダムに選択することによって実現されます。たとえば、確率 0.9 のトークンは 90% の確率で選択されます。ただし、常に最も高い確率でトークンを選択するなど、他のオプションもあります。
温度パラメータを使用して、分布の「滑らかさ」を制御することもできます。温度が高いほど分布はより均一になり、温度が低いほど分布は最も高い確率でトークンに集中します。
ソフトマックスを適用する前に、温度パラメーターを使用してロジット (線形変換の出力) を調整します。ソフトマックスのべき乗は、より大きな値に対して大きな増幅効果があるため、すべての値を近づけることでこの種の現象が軽減されます。効果の。 ############写真######
以上が情報の壁を突破せよ!衝撃の大規模3Dビジュアライゼーションツールがリリース!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。