
ホームページ >テクノロジー周辺機器 >AI >検出能力を効率的に向上: 200 メートルを超える小さなターゲットの検出を突破
検出能力を効率的に向上: 200 メートルを超える小さなターゲットの検出を突破

- PHPz転載
- 2024-01-15 19:51:291115ブラウズ
この記事は自動運転ハート公式アカウントの許可を得て転載しておりますので、転載については転載元にご連絡ください。
LiDAR 点群に基づく 3D 物体検出は常に非常に古典的な問題であり、学界と産業界の両方が精度、速度、堅牢性を向上させるためにさまざまなモデルを提案してきました。ただし、屋外環境が複雑なため、屋外点群に対する物体検出のパフォーマンスはあまり良くありません。 LIDAR 点群は本質的にまばらです。この問題を的を絞った方法で解決するにはどうすればよいでしょうか?この論文は、時系列情報の集約に基づいて情報を抽出するという独自の答えを示しています。
#1. 論文情報

 #この論文では、自動運転における重要な課題、つまり周囲環境の 3 次元表現を正確に作成することについて説明します。これは自動運転車の信頼性と安全性にとって重要です。特に、自動運転車は、車両や歩行者などの周囲の物体を認識し、それらの位置、サイズ、方向を正確に判断できる必要があります。通常、このタスクを達成するには、ディープ ニューラル ネットワークを使用して LiDAR データを処理します。
#この論文では、自動運転における重要な課題、つまり周囲環境の 3 次元表現を正確に作成することについて説明します。これは自動運転車の信頼性と安全性にとって重要です。特に、自動運転車は、車両や歩行者などの周囲の物体を認識し、それらの位置、サイズ、方向を正確に判断できる必要があります。通常、このタスクを達成するには、ディープ ニューラル ネットワークを使用して LiDAR データを処理します。
既存の文献のほとんどは、単一フレーム方法、つまり一度に 1 つのセンサーでスキャンされたデータを使用する方法に焦点を当てています。この方法は、最大 75 メートルの距離にあるオブジェクトを含む従来のベンチマークで良好にパフォーマンスを発揮します。ただし、LIDAR 点群は本質的に、特に長距離ではまばらです。したがって、論文では、長距離 (たとえば、最大 200 メートル) の検出に 1 回のスキャンだけを使用するだけでは十分ではないと述べています。これは、点群密度を高め、距離測定の精度を向上させるには、マルチフレーム融合手法が必要であることを意味します。複数のタイムステップからのスキャンデータを登録して融合することにより、より完全かつ正確なシーンの再構成と距離測定の結果を取得できます。このような方法は、長距離の目標検出や障害物回避などのタスクにおいて、より高い信頼性と堅牢性を備えています。したがって、この論文の貢献は、マルチフレーム フュージョンに基づく方法を提案することです。
この問題を解決するための 1 つの方法は、点群集約を通じて LIDAR スキャン データを継続的に取得し、それによってより高密度の入力を取得することです。ただし、このアプローチは計算コストが高く、ネットワーク内の集約を最大限に活用できません。したがって、明らかな代替策は、情報を徐々に蓄積することによってこの問題を解決する再帰的アプローチを採用することです。再帰的手法では、時間の経過とともに情報が継続的に更新され、より正確で包括的な結果が得られます。再帰的手法を使用すると、大量の入力データを効率的に処理でき、計算効率が向上します。このようにして、問題を解決しながらコンピューティング リソースを節約できます。
この記事では、スパース コンボリューション、アテンション モジュール、3D コンボリューションなど、検出範囲を拡大するための他の手法についても触れています。ただし、これらの方法ではターゲット ハードウェアの互換性の問題が無視されることがよくあります。ニューラル ネットワークを展開およびトレーニングする場合、使用されるハードウェアによって、サポートされる操作と遅延が大幅に異なる場合があります。たとえば、Nvidia Orin DLA などのターゲット ハードウェアは、スパース コンボリューションやアテンションなどの操作をサポートしていないことがよくあります。さらに、3D コンボリューションなどのレイヤーの使用は、リアルタイムの遅延要件により実現できない場合があります。したがって、2D 畳み込みなどの単純な演算を使用する必要性が高くなります。
この論文では、新しい時間再帰モデル TimePillars を提案しています。これは、共通のターゲット ハードウェアでサポートされている一連の操作を尊重し、2D 畳み込みに依存し、ポイントピラー (Pillar) 入力表現と畳み込み再帰ユニットに基づいています。 。自己動き補償は、単一の畳み込みと補助学習を利用して、リカレント ユニットの隠れた状態に適用されます。この操作の正確さを保証するために補助タスクを使用することは、アブレーション研究を通じて適切であることが示されています。この論文では、パイプライン内の再帰的モジュールの最適な配置についても調査し、ネットワークのバックボーンと検出ヘッドの間に配置すると最高のパフォーマンスが得られることを明確に示しています。この論文では、新しくリリースされた Zenseact Open Dataset (ZOD) について、TimePillars メソッドの有効性を実証しています。シングルフレームおよびマルチフレームのポイントアンドピラー ベースラインと比較して、TimePillars は、特に重要な自転車と歩行者のカテゴリにおける長距離 (最大 200 メートル) の検出において、評価パフォーマンスの大幅な向上を実現します。最後に、TimePillars はマルチフレーム ポイント ピラーよりも遅延が大幅に低いため、リアルタイム システムに適しています。
この論文では、3D LIDAR オブジェクト検出タスクを解決するために、TimePillars と呼ばれる新しい時間再帰モデルを提案します。シングルフレームおよびマルチフレームのポイントピラー ベースラインと比較して、TimePillars は長距離検出で大幅に優れたパフォーマンスを示し、一般的なターゲット ハードウェアでサポートされる一連の操作を尊重します。この論文では、新しい Zenseact オープン データセット上で 3D LIDAR 物体検出モデルを初めてベンチマークしています。ただし、この論文の限界は、他のセンサー入力を包括的に考慮せずに LIDAR データのみを考慮していること、およびそのアプローチが単一の最先端のベースラインに基づいていることです。それにもかかわらず、著者らは、自分たちのフレームワークは一般的なものであり、将来のベースラインの改善が全体的なパフォーマンスの向上につながると信じています。
3. 方法
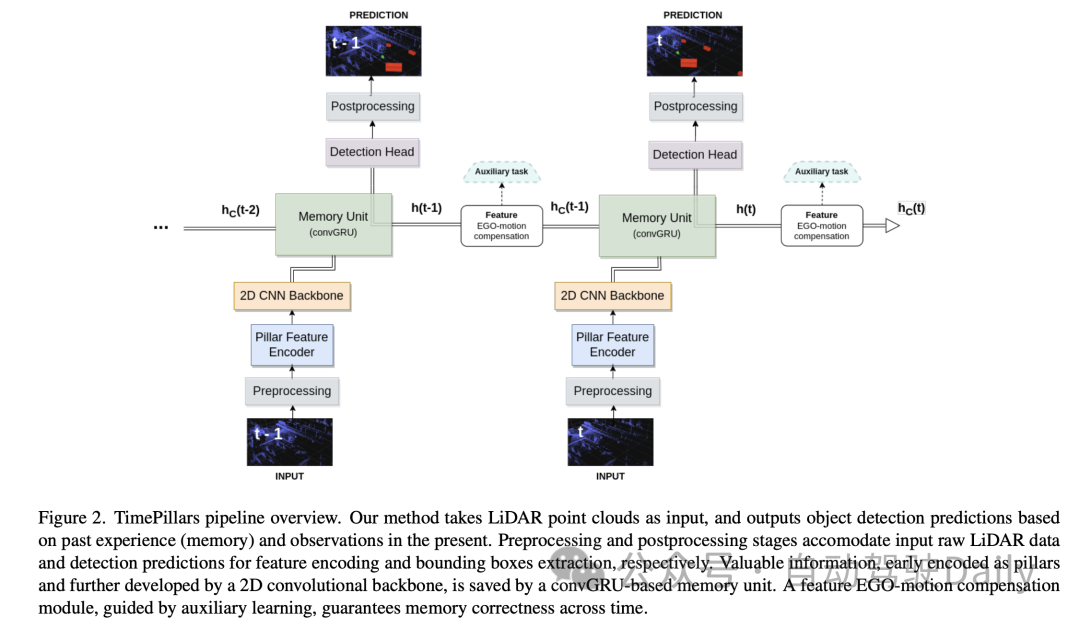
3.1 入力前処理
この論文の「入力前処理」の部分では、著者は以下の方法を採用しています。入力された点群データの処理には「柱状化」技術が使用されます。この方法は、垂直方向 (z 軸) の高さを固定したまま、点群を水平方向 (x 軸と y 軸) のみに垂直な柱状構造にセグメント化する従来のボクセル化とは異なります。そうすることで、ネットワーク入力の次元の一貫性が維持され、2D 畳み込みを使用した効率的な処理が可能になります。
ただし、Pillarisation には多くの空の列が生成され、データが非常にまばらになるという問題が 1 つあります。この問題を解決するために、この論文では動的ボクセル化技術の使用を提案しています。この手法により、各列のポイント数を事前に定義する必要がなくなり、各列での切り捨てや塗りつぶしの操作が不要になります。代わりに、点群データ全体が、必要な合計点数 (ここでは 200,000 点に設定) に一致するように処理されます。この前処理方法の利点は、情報の損失が最小限に抑えられ、生成されたデータ表現がより安定して一貫性のあるものになることです。
3.2 モデル アーキテクチャ
次に、モデル アーキテクチャについて、著者は、柱特徴エンコーダ (Pillar Feature Encoder)、2D 畳み込みニューラル ネットワーク (CNN) バックボーン、および検出ヘッド ニューラル ネットワーク アーキテクチャ。
- Pillar Feature Encoder: この部分は、前処理された入力テンソルを Bird's Eye View (BEV) 擬似イメージにマッピングします。動的ボクセル化を使用した後、それに応じて簡略化された PointNet が調整されます。入力は 1D 畳み込み、バッチ正規化、ReLU アクティベーション関数によって処理され、形状 のテンソルが生成されます。ここで、 はチャネル数を表します。最後の散乱最大レイヤーの前に、最大プーリングがチャネルに適用され、形状 の潜在空間が形成されます。初期テンソルは としてエンコードされ、前の層の後で になるため、最大プーリング操作は削除されます。
- バックボーン: 優れた深度効率により、元のコラム論文で提案された 2D CNN バックボーン アーキテクチャを使用します。潜在空間は 3 つのダウンサンプリング ブロック (Conv2D-BN-ReLU) を使用して削減され、3 つのアップサンプリング ブロックと転置畳み込みを使用して復元され、出力形状は になります。
- メモリ ユニット: システムのメモリをリカレント ニューラル ネットワーク (RNN) としてモデル化します。具体的には、ゲート付きリカレント ユニットの畳み込みバージョンである畳み込み GRU (convGRU) を使用します。畳み込み GRU の利点は、空間データ特性を維持しながら勾配消失問題を回避し、効率を向上できることです。 LSTM などの他のオプションと比較して、GRU はゲート数が少ないため、トレーニング可能なパラメーターが少なく、メモリ正則化手法 (隠れ状態の複雑さを軽減する) と考えることができます。同様の性質の演算をマージすることにより、必要な畳み込み層の数が減り、ユニットの効率が向上します。
- 検出ヘッド: SSD (シングルショット マルチボックス検出器) への簡単な変更。 SSD の中心概念、つまり領域提案のないシングルパスは維持されますが、アンカー ボックスの使用は排除されます。グリッド内の各セルの予測を直接出力すると、セルのマルチオブジェクト検出機能は失われますが、退屈で不正確なことが多いアンカー ボックス パラメーターの調整が回避され、推論プロセスが簡素化されます。線形層は、分類と位置特定 (位置、サイズ、角度) 回帰のそれぞれの出力を処理します。サイズのみ活性化関数(ReLU)を用いて負の値をとらないようにしています。さらに、関連文献とは異なり、この論文では、車両の走行方向の正弦成分と余弦成分を独立して予測し、それらから角度を抽出することにより、直接角度回帰の問題を回避しています。
3.3 特徴エゴモーション補償
論文のこの部分では、著者は、畳み込み GRU によって出力される隠れ状態特徴 (次の座標系) を処理する方法について説明します。前のフレームが表現されました。直接保存して次の予測の計算に使用すると、エゴモーションにより空間的な不一致が発生します。
変換を実行するには、さまざまな手法を適用できます。理想的には、修正されたデータはネットワーク内で変換されるのではなく、ネットワークに供給されます。ただし、これは論文で提案されている方法ではありません。推論プロセスの各ステップで隠れ状態をリセットし、以前の点群を変換し、それらをネットワーク全体に伝播する必要があるからです。これは非効率であるだけでなく、RNN を使用する目的を損なってしまいます。したがって、ループ コンテキストでは、補償を機能レベルで行う必要があります。これにより、仮説的な解決策はより効率的になりますが、問題はより複雑になります。従来の内挿方法を使用して、変換された座標系の特徴を取得できます。
対照的に、この論文は、Chen らの研究に触発されて、畳み込み演算と補助タスクを使用して変換を実行することを提案しています。前述の研究の限られた詳細を考慮して、この論文では、この問題に対するカスタマイズされた解決策を提案しています。
この論文で採用されているアプローチは、追加の畳み込み層を通じて特徴変換を実行するために必要な情報をネットワークに提供することです。 2 つの連続するフレーム間の相対変換行列、つまり特徴を正常に変換するために必要な操作が最初に計算されます。次に、そこから 2D 情報 (回転および移動部分) を抽出します。
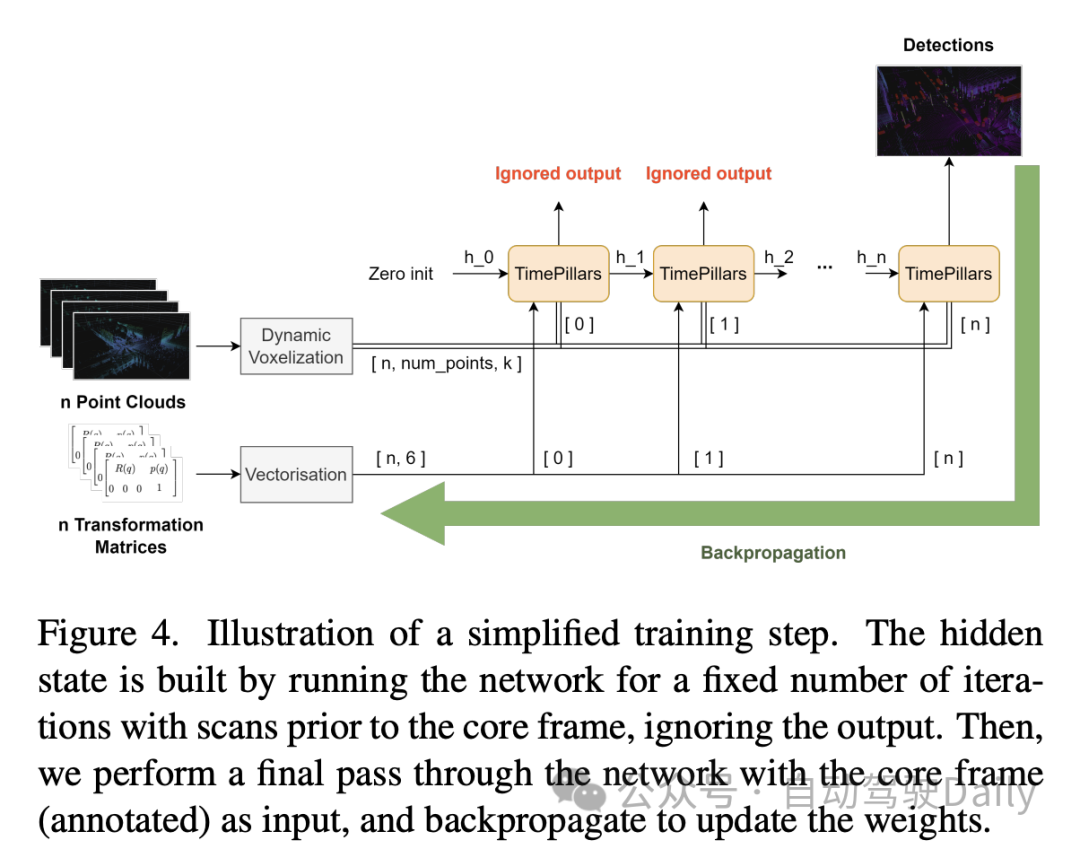
4. 実験
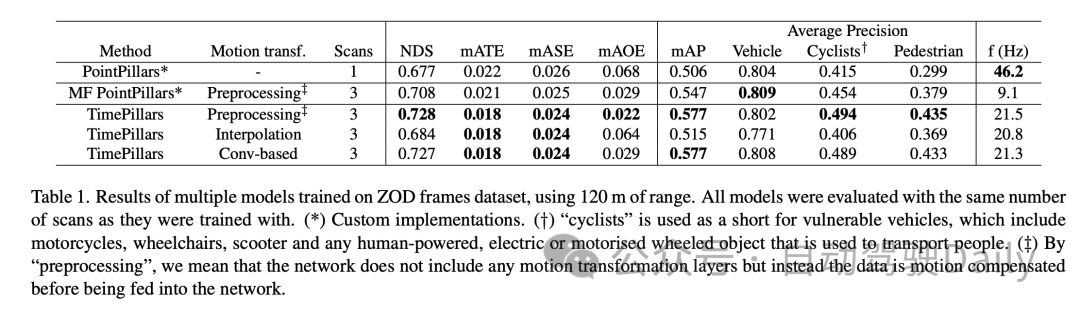

さまざまな距離範囲でのパフォーマンスの比較では、TimePillars が各範囲でより優れたパフォーマンスを発揮していることがわかります。車両カテゴリの場合、0 ~ 50 メートル、50 ~ 100 メートル、および 100 メートルを超える範囲での TimePillars の検出精度は、それぞれ 0.884、0.776、0.591 であり、すべて同じ範囲の PointPillars のパフォーマンスよりも優れています。これは、TimePillars が近距離と遠距離の両方で車両検出の精度が高いことを示しています。 TimePillars は、脆弱な車両 (オートバイ、車椅子、電動スクーターなど) を扱う際にも優れた検出パフォーマンスを実証しました。特に 100 メートル以上の範囲では、TimePillars の検出精度は 0.178 であるのに対し、PointPillars はわずか 0.036 であり、長距離検出において大きな利点を示しています。歩行者検出についても、TimePillars は特に 50 ~ 100 メートルの範囲で優れたパフォーマンスを示し、検出精度は 0.350 でしたが、PointPillars はわずか 0.211 でした。より長い距離 (100 メートル以上) であっても、TimePillars は一定レベルの検出 (精度 0.032) を達成しますが、PointPillars はこの距離では検出能力がゼロです。
これらの実験結果は、さまざまな距離範囲での物体検出タスクの処理における TimePillars の優れたパフォーマンスを強調しています。近距離であろうと、より困難な長距離であろうと、TimePillars は、自動運転車の安全性と効率にとって重要な、より正確で信頼性の高い検出結果を提供します。
5. ディスカッション

まず第一に、TimePillars モデルの主な利点は、長距離物体検出の有効性です。 。動的ボクセル化と畳み込み GRU 構造を採用することにより、このモデルは、特に長距離の物体検出において、まばらな LIDAR データをより適切に処理できるようになります。これは、複雑で変化する道路環境で自動運転車を安全に運用するために重要です。さらに、このモデルは、リアルタイム アプリケーションに不可欠な処理速度の面でも優れたパフォーマンスを示します。一方、TimePillars は動き補償に畳み込みベースの方法を採用しており、従来の方法に比べて大幅に改善されています。このアプローチでは、トレーニング中の補助タスクを通じて変換の正確性が保証され、移動オブジェクトを処理する際のモデルの精度が向上します。
ただし、この論文の調査にはいくつかの限界もあります。まず、TimePillars は遠くの物体検出の処理では優れたパフォーマンスを発揮しますが、このパフォーマンスの向上には処理速度がある程度犠牲になる可能性があります。モデルの速度は依然としてリアルタイム アプリケーションに適していますが、シングルフレーム手法と比較すると依然として低下しています。さらに、この論文では主に LiDAR データに焦点を当てており、カメラやレーダーなどの他のセンサー入力は考慮されていないため、より複雑なマルチセンサー環境でのモデルの適用が制限される可能性があります。
つまり、TimePillars は、自動運転車の 3D LIDAR 物体検出、特に長距離検出と動き補償において、大きな利点を示しています。処理速度とマルチセンサー データの処理における制限に若干のトレードオフがあるにもかかわらず、TimePillars は依然としてこの分野で重要な進歩を示しています。
6. 結論
この研究は、過去のセンサー データを考慮することが、現在の情報のみを利用するよりも優れていることを示しています。以前の運転環境情報にアクセスすると、LIDAR 点群のまばらな性質に対処でき、より正確な予測につながります。我々は、リカレントネットワークが後者を達成する手段として適していることを実証します。システム メモリを提供すると、広範な処理を通じてより高密度のデータ表現を作成する点群集約手法と比較して、より堅牢なソリューションが実現します。私たちが提案するメソッド TimePillars は、再帰的問題を解決する方法を実装しています。推論プロセスに 3 つの畳み込み層を追加するだけで、重要な結果を達成し、既存の効率とハードウェア統合仕様が確実に満たされるようにするには、基本的なネットワーク構成要素で十分であることを示します。私たちの知る限り、この研究は、新しく導入された Zenseact オープン データセット上の 3D オブジェクト検出タスクの最初のベンチマーク結果を提供します。私たちの取り組みが将来、より安全で持続可能な道路に貢献できることを願っています。

元のリンク: https://mp.weixin.qq.com/s/94JQcvGXFWfjlDCT77gjlA
以上が検出能力を効率的に向上: 200 メートルを超える小さなターゲットの検出を突破の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。