



画像からビデオへの生成 (I2V) タスクは、静止画像を動的なビデオに変換することを目的とした、コンピューター ビジョンの分野における課題です。このタスクの難しさは、画像コンテンツの信頼性と視覚的な一貫性を維持しながら、単一の画像から時間次元で動的な情報を抽出して生成することです。既存の I2V 手法では、多くの場合、この目標を達成するために複雑なモデル アーキテクチャと大量のトレーニング データが必要になります。
最近、Kuaishou が主導した新しい研究成果「I2V アダプター: ビデオ拡散モデルのための汎用画像対ビデオ アダプター」が発表されました。この研究では、革新的な画像からビデオへの変換方法を導入し、軽量のアダプター モジュールである I2V アダプターを提案します。このアダプター モジュールは、既存のテキストからビデオへの生成 (T2V) モデルの元の構造と事前トレーニングされたパラメーターを変更することなく、静止画像を動的なビデオに変換できます。この方法は、画像からビデオへの変換の分野で幅広い応用の可能性があり、ビデオ作成、メディアコミュニケーション、その他の分野にさらなる可能性をもたらす可能性があります。研究成果の公開は、画像・映像技術の発展を促進する上で非常に意義があり、関連分野の研究者にとって有効なツールや手法を提供します。

- #論文アドレス: https://arxiv.org/pdf/2312.16693 .pdf
- プロジェクトのホームページ: https://i2v-adapter.github.io/index.html
- コードアドレス: https://github.com/I2V-Adapter/I2V-Adapter-repo
既存のメソッドとの比較 他つまり、I2V アダプターはトレーニング可能なパラメーターの点で大幅な改善を行い、パラメーターの最小数は 22M に達しましたが、これは主流のソリューションである Stable Video Diffusion のわずか 1% にすぎません。同時に、このアダプターは、Stable Diffusion コミュニティによって開発されたカスタマイズされた T2I モデル (DreamBooth、Lora など) および制御ツール (ControlNet など) とも互換性があります。研究者らは実験を通じて、高品質のビデオコンテンツの生成における I2V アダプターの有効性を証明し、I2V 分野でクリエイティブなアプリケーションの新たな可能性を切り開きました。

安定拡散による時間モデリング
画像生成と比較して、ビデオ生成は、ビデオ フレーム間の時間的一貫性をモデル化するという独特の課題に直面しています。現在の手法のほとんどは、ビデオ内のタイミング情報をモデル化するタイミング モジュールを導入することにより、安定拡散や SDXL などの事前トレーニングされた T2I モデルに基づいています。もともとカスタマイズされた T2V タスク用に設計されたモデルである AnimateDiff からインスピレーションを受けており、T2I モデルから分離されたタイミング モジュールを導入することでタイミング情報をモデル化し、スムーズなビデオを生成する元の T2I モデルの機能を保持します。したがって、研究者らは、事前トレーニングされた時間モジュールは普遍的な時間表現と見なすことができ、微調整することなく、I2V 生成などの他のビデオ生成シナリオに適用できると考えています。したがって、研究者らは事前トレーニングされた AnimateDiff タイミング モジュールを直接使用し、そのパラメーターを固定したままにしました。
アテンション レイヤー用アダプター
I2V タスクのもう 1 つの課題は、入力画像の ID 情報を維持することです。 。現在の主な解決策は 2 つあります。1 つは、事前トレーニングされた画像エンコーダーを使用して入力画像をエンコードし、クロスアテンション メカニズムを通じてエンコードされた特徴をモデルに注入してノイズ除去プロセスをガイドするもので、もう 1 つは画像をチャネル次元のノイズを含む入力と連結され、後続のネットワークに一緒に供給されます。ただし、前者の方法では、画像エンコーダーが基礎となる情報をキャプチャすることが難しいため、生成されたビデオ ID が変更される可能性がありますが、後者の方法では、多くの場合、T2I モデルの構造とパラメーターの変更が必要となるため、トレーニング コストが高くなり、パフォーマンスが低下します。互換性。上記の問題を解決するために、研究者たちは I2V アダプターを提案しました。具体的には、研究者は入力画像とノイズを含む入力を並行してネットワークに入力します。モデルの空間ブロックでは、すべてのフレームが最初のフレーム情報をさらにクエリします。つまり、キーと値の特徴はノイズのない最初のフレームから取得されます。 、そして出力結果は元のモデルのセルフアテンションに追加されます。このモジュールの出力マッピング行列はゼロで初期化され、出力マッピング行列とクエリ マッピング行列のみがトレーニングされます。入力画像の意味論的情報に対するモデルの理解をさらに強化するために、研究者らは、画像の意味論的特徴を注入するための事前トレーニング済みコンテンツ アダプター (この記事では IP アダプター [8] を使用します) を導入しました。
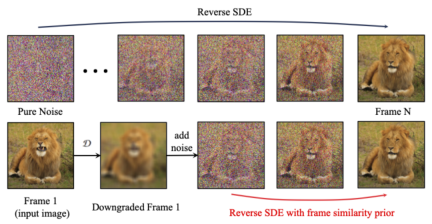
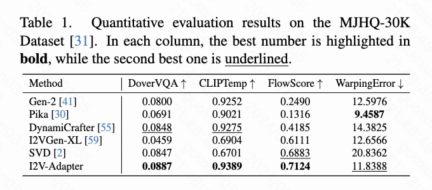
フレーム類似度優先順位 生成された結果の安定性をさらに高めるために、研究者は、は、フレーム間の事前類似性を使用して、生成されたビデオの安定性と動きの強さのバランスを取ることを提案しました。重要な前提は、次の図に示すように、比較的低いガウス ノイズ レベルでは、ノイズのある最初のフレームとノイズのある後続のフレームが十分に近いということです。 したがって、研究者は、すべてのフレームが同様の構造を持ち、一定量のガウス ノイズを追加すると区別できなくなると想定し、したがって、ノイズを加えた入力画像を後続のフレームのアプリオリ入力として使用できると考えています。高周波情報による誤解を避けるために、研究者らはガウスぼかし演算子とランダムマスク混合も使用しました。具体的には、操作は次のようになります。 #実験結果 この記事では、DoverVQA (美的スコア)、CLIPTemp (最初のフレームの一貫性)、FlowScore (動作範囲)、および WarppingError (動作エラー) の 4 つの定量的指標を計算しました。生成されたビデオ。表 1 は、I2V アダプターが最高の美的スコアを獲得し、最初のフレームの一貫性の点ですべての比較スキームを上回っていることを示しています。さらに、I2V アダプターによって生成されたビデオは、最大の動き振幅と比較的低い動き誤差を持ち、このモデルが時間的な動きの精度を維持しながら、よりダイナミックなビデオを生成できることを示しています。 #定性的結果
##ControlNet あり (左が入力、右が出力): ## この文書では、画像からビデオへの生成タスク用のプラグアンドプレイの軽量モジュールである I2V アダプターを提案します。この方法では、元の T2V モデルの空間ブロックとモーション ブロックの構造とパラメーターを固定し、ノイズのない最初のフレームとノイズのある後続のフレームを並列に入力し、アテンション メカニズムを通じてすべてのフレームがノイズのない最初のフレームと相互作用できるようにします。したがって、時間的に一貫性があり、最初のフレームと一貫性のあるビデオが生成されます。研究者は、定量的および定性的な実験を通じて、I2V タスクにおけるこの方法の有効性を実証しました。さらに、その分離設計により、ソリューションを DreamBooth、Lora、ControlNet などのモジュールと直接組み合わせることができ、ソリューションの互換性を証明し、カスタマイズされた制御可能な画像からビデオの生成に関する研究を促進します。 


 # #パーソナライズされた T2I あり (左が入力、右が出力):
# #パーソナライズされた T2I あり (左が入力、右が出力): 





概要
以上がSD コミュニティの I2V アダプター: 設定不要、プラグアンドプレイ、Tusheng ビデオ プラグインと完全に互換性ありの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM
AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM「AI-Ready労働力」という用語は頻繁に使用されますが、サプライチェーン業界ではどういう意味ですか? サプライチェーン管理協会(ASCM)のCEOであるAbe Eshkenaziによると、批評家ができる専門家を意味します
 1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM
1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM分散型AI革命は静かに勢いを増しています。 今週の金曜日、テキサス州オースティンでは、ビテンサーのエンドゲームサミットは極めて重要な瞬間を示し、理論から実用的な応用に分散したAI(DEAI)を移行します。 派手なコマーシャルとは異なり
 Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AM
Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AMエンタープライズAIはデータ統合の課題に直面しています エンタープライズAIの適用は、ビジネスデータを継続的に学習することで正確性と実用性を維持できるシステムを構築する大きな課題に直面しています。 NEMOマイクロサービスは、NVIDIAが「データフライホイール」と呼んでいるものを作成することにより、この問題を解決し、AIシステムがエンタープライズ情報とユーザーインタラクションへの継続的な露出を通じて関連性を維持できるようにします。 この新しく発売されたツールキットには、5つの重要なマイクロサービスが含まれています。 NEMOカスタマイザーは、より高いトレーニングスループットを備えた大規模な言語モデルの微調整を処理します。 NEMO評価者は、カスタムベンチマークのAIモデルの簡素化された評価を提供します。 Nemo Guardrailsは、コンプライアンスと適切性を維持するためにセキュリティ管理を実装しています
 aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AM
aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AMAI:芸術とデザインの未来 人工知能(AI)は、前例のない方法で芸術とデザインの分野を変えており、その影響はもはやアマチュアに限定されませんが、より深く影響を与えています。 AIによって生成されたアートワークとデザインスキームは、広告、ソーシャルメディアの画像生成、Webデザインなど、多くのトランザクションデザインアクティビティで従来の素材画像とデザイナーに迅速に置き換えられています。 ただし、プロのアーティストやデザイナーもAIの実用的な価値を見つけています。 AIを補助ツールとして使用して、新しい美的可能性を探求し、さまざまなスタイルをブレンドし、新しい視覚効果を作成します。 AIは、アーティストやデザイナーが繰り返しタスクを自動化し、さまざまなデザイン要素を提案し、創造的な入力を提供するのを支援します。 AIはスタイル転送をサポートします。これは、画像のスタイルを適用することです
 エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM
エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM最初はビデオ会議プラットフォームで知られていたZoomは、エージェントAIの革新的な使用で職場革命をリードしています。 ZoomのCTOであるXD Huangとの最近の会話は、同社の野心的なビジョンを明らかにしました。 エージェントAIの定義 huang d
 大学に対する実存的な脅威Apr 26, 2025 am 11:08 AM
大学に対する実存的な脅威Apr 26, 2025 am 11:08 AMAIは教育に革命をもたらしますか? この質問は、教育者と利害関係者の間で深刻な反省を促しています。 AIの教育への統合は、機会と課題の両方をもたらします。 Tech Edvocate NotesのMatthew Lynch、Universitとして
 プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM
プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM米国における科学的研究と技術の開発は、おそらく予算削減のために課題に直面する可能性があります。 Natureによると、海外の雇用を申請するアメリカの科学者の数は、2024年の同じ期間と比較して、2025年1月から3月まで32%増加しました。以前の世論調査では、調査した研究者の75%がヨーロッパとカナダでの仕事の検索を検討していることが示されました。 NIHとNSFの助成金は過去数か月で終了し、NIHの新しい助成金は今年約23億ドル減少し、3分の1近く減少しました。リークされた予算の提案は、トランプ政権が科学機関の予算を急激に削減していることを検討しており、最大50%の削減の可能性があることを示しています。 基礎研究の分野での混乱は、米国の主要な利点の1つである海外の才能を引き付けることにも影響を与えています。 35
 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

WebStorm Mac版
便利なJavaScript開発ツール
ホットトピック
 7727
7727 15164314139752129025123329
15164314139752129025123329