
ホームページ >テクノロジー周辺機器 >AI >小さくても強力なモデルが増加中: TinyLlama と LiteLlama が人気の選択肢になる
小さくても強力なモデルが増加中: TinyLlama と LiteLlama が人気の選択肢になる

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-14 12:27:151489ブラウズ
現在、研究者はコンパクトで高性能な小型モデルに焦点を当て始めていますが、誰もがパラメータサイズが数百億、さらには数千億に達する大規模なモデルを研究しています。
小型モデルは、スマートフォン、IoT デバイス、組み込みシステムなどのエッジ デバイスで広く使用されています。これらのデバイスは多くの場合、コンピューティング能力とストレージ容量が限られており、大規模な言語モデルを効率的に実行できません。したがって、小さなモデルを研究することが特に重要になります。
次に紹介する 2 つの研究は、小規模モデルのニーズを満たす可能性があります。
TinyLlama-1.1B
シンガポール工科デザイン大学 (SUTD) の研究者らは最近、11 億パラメータの言語である TinyLlama をリリースしました。モデルは約 3 兆個のトークンで事前トレーニングされています。

- #論文アドレス: https://arxiv.org/pdf/2401.02385.pdf
- プロジェクトアドレス: https://github.com/jzhang38/TinyLlama/blob/main/README_zh-CN.md
TinyLlama は Llama 2 アーキテクチャとトークナイザーに基づいており、Llama を使用する多くのオープン ソース プロジェクトと簡単に統合できます。さらに、TinyLlama にはパラメータが 11 億個しかなく、サイズも小さいため、限られた計算量とメモリ フットプリントを必要とするアプリケーションに最適です。
調査では、90 日間で TinyLlama のトレーニングを完了できるのは 16 個の A100-40G GPU のみであることが示されています。

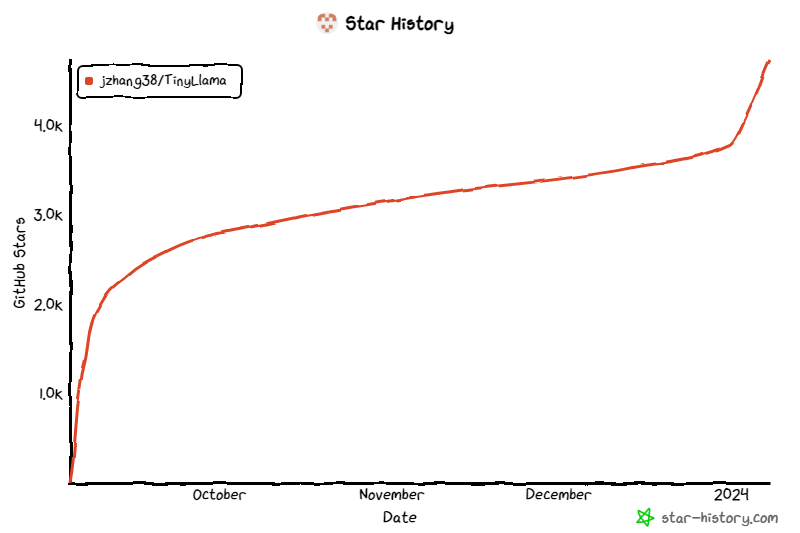
このプロジェクトは開始以来注目を集め続けており、現在の星の数は 4.7,000 に達しています。
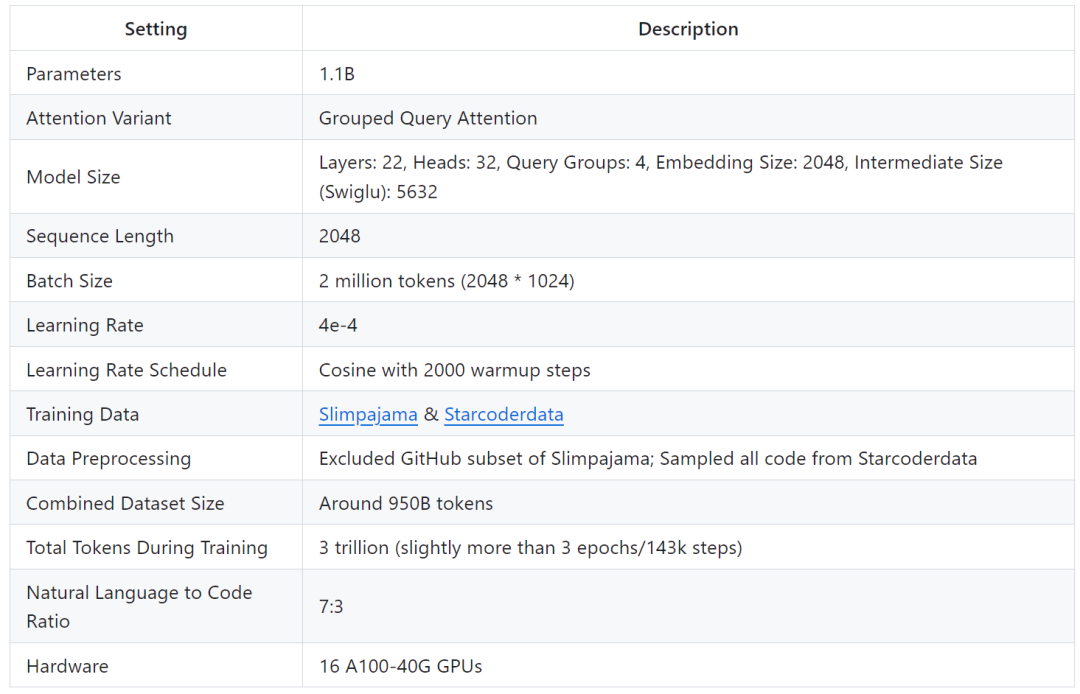
TinyLlama モデル アーキテクチャの詳細は次のとおりです:

トレーニングの詳細は次のとおりです:
研究者は、この研究はトレーニングに大規模なデータセットを使用してマイニングすることを目的としていると述べました。より小さなモデルの可能性。彼らは、スケーリング則で推奨されているよりもはるかに多くのトークンを使用してトレーニングしたときの、より小さなモデルの動作を調査することに重点を置きました。
具体的には、この研究では、1.1B パラメーターを使用して Transformer (デコーダーのみ) モデルをトレーニングするために約 3 兆のトークンを使用しました。私たちの知る限り、このような大量のデータを使用して 1B パラメーターでモデルをトレーニングする試みはこれが初めてです。
TinyLlama は、サイズが比較的小さいにもかかわらず、さまざまなダウンストリーム タスクで非常に優れたパフォーマンスを発揮し、同様のサイズの既存のオープンソース言語モデルを大幅に上回ります。具体的には、TinyLlama は、さまざまなダウンストリーム タスクにおいて OPT-1.3B および Pythia1.4B よりも優れたパフォーマンスを発揮します。
さらに、TinyLlama は、フラッシュ アテンション 2、FSDP (Fully Sharded Data Parallel)、xFormers など、さまざまな最適化手法も使用します。
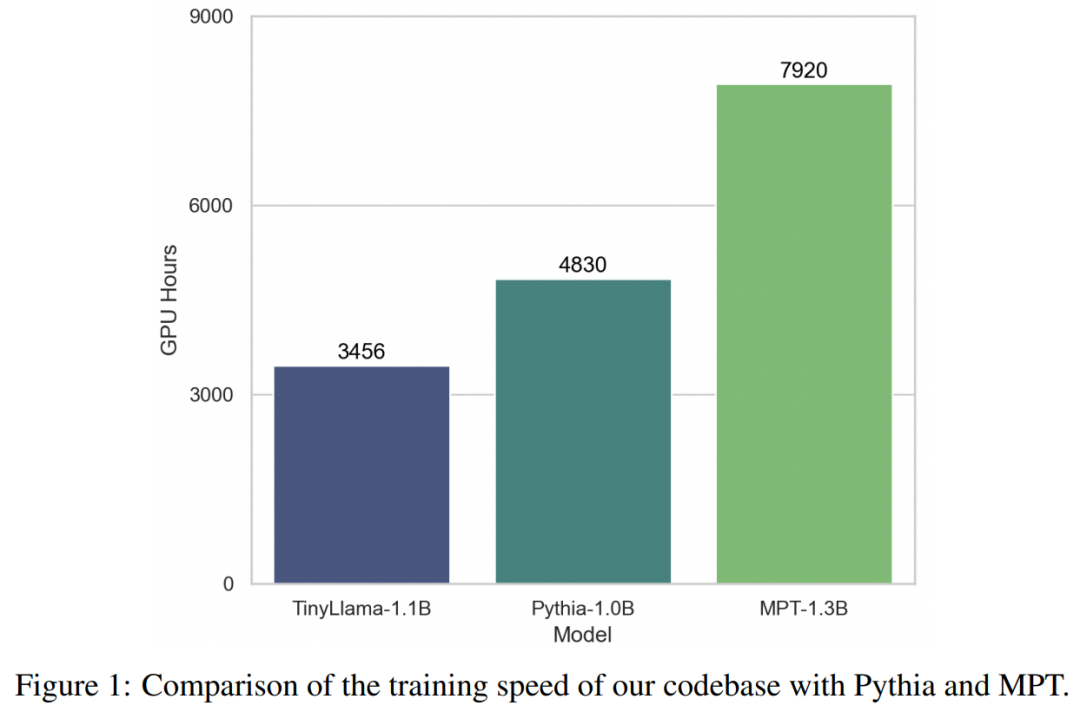
これらのテクノロジーのサポートにより、TinyLlama のトレーニング スループットは、A100-40G GPU あたり 1 秒あたり 24,000 トークンに達します。たとえば、TinyLlama-1.1B モデルでは、300B トークンに必要な A100 GPU 時間はわずか 3,456 時間ですが、Pythia では 4,830 時間、MPT では 7,920 時間かかります。これは、この研究の最適化の有効性と、大規模なモデルのトレーニングで大幅な時間とリソースを節約できる可能性を示しています。
TinyLlama は、24,000 トークン/秒/A100 のトレーニング速度を達成します。この速度は、ユーザーが 8 台の A100 で 11 億のパラメーターと 220 億のトークンを使用してチンチラを 32 時間でトレーニングできるのと同じです。 -最適なモデル。同時に、これらの最適化によりメモリ使用量も大幅に削減され、GPU あたりのバッチ サイズ 16,000 トークンを維持しながら、11 億のパラメーター モデルを 40 GB GPU に詰め込むことができます。バッチ サイズを少し小さく変更するだけで、RTX 3090/4090 で TinyLlama をトレーニングできます。

実験では、この研究は主に純粋な言語を対象としています。約 10 億のパラメータを含むデコーダ アーキテクチャ モデル。具体的には、この研究では TinyLlama を OPT-1.3B、Pythia-1.0B、および Pythia-1.4B と比較しました。
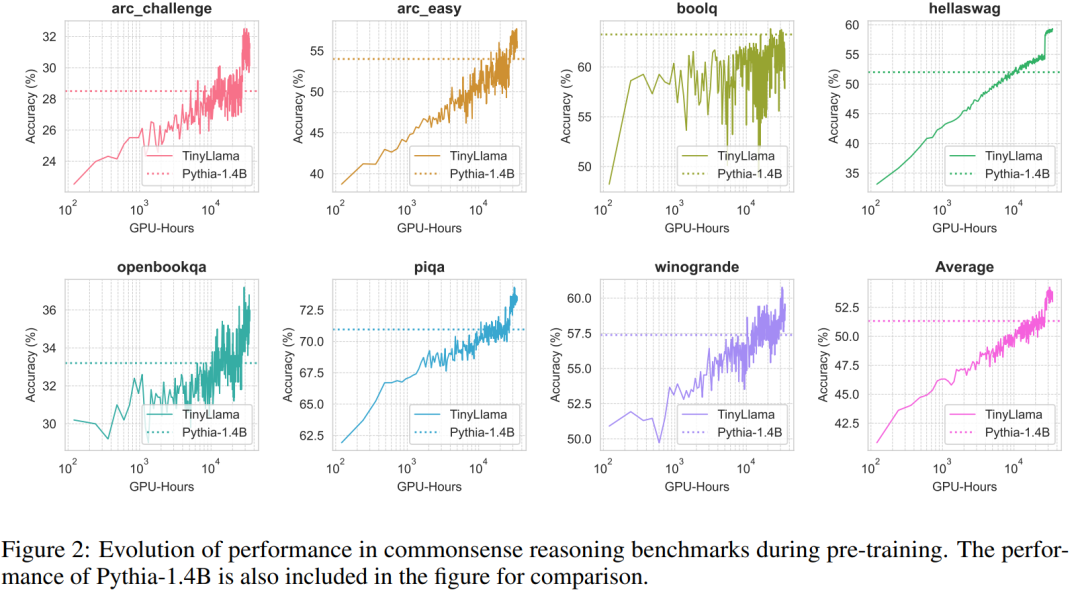
常識推論タスクにおける TinyLlama のパフォーマンスを以下に示しますが、TinyLlama は多くのタスクでベースラインを上回り、最高の平均スコアを達成していることがわかります。

さらに、研究者らは、図 2 に示すように、事前トレーニング中に常識推論ベンチマークで TinyLlama の精度を追跡しました。 TinyLlama の精度はコンピューティング リソースの増加とともに向上し、ほとんどのベンチマークで Pythia-1.4B の精度を上回ります。
#表 3 は、TinyLlama が既存のモデルと比較して優れた問題解決能力を示していることを示しています。
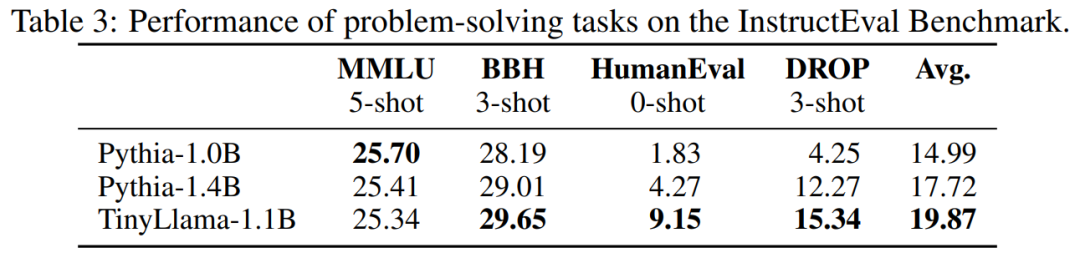
手の早いネチズンはすでに使い始めています。ランニング効果は驚くほど良好で、GTX3060 で実行すると、次の速度で実行できます。 136 トーク/秒。
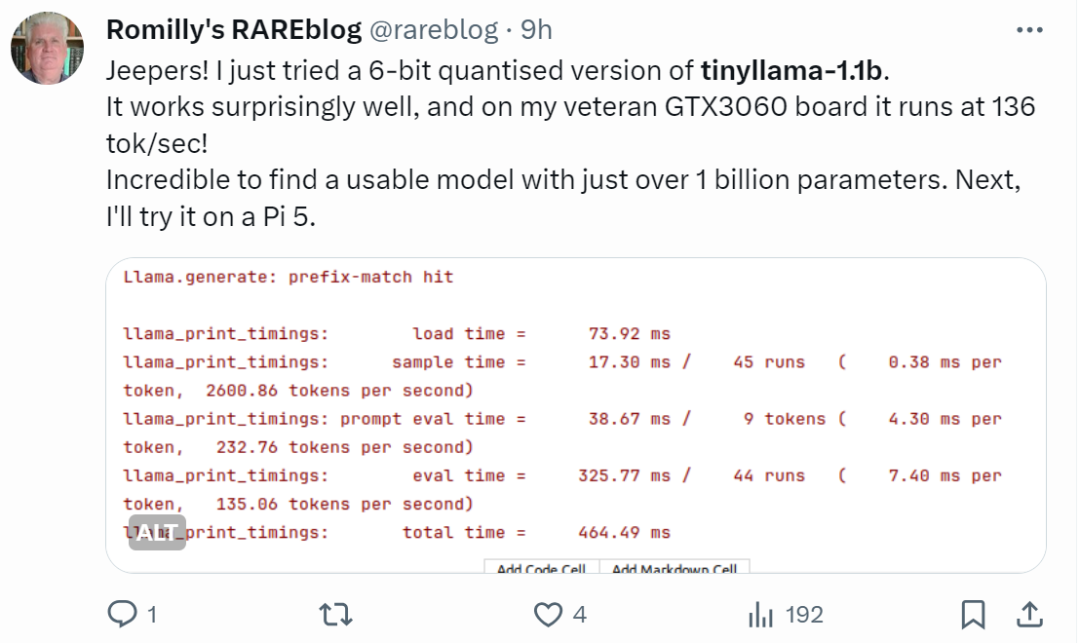
「本当に早いですね!」
TinyLlama のリリースにより、SLM (Small Language Model) が広く注目を集め始めました。テキサス工科大学と A&M 大学の Xiaotian Han 氏は、SLM-LiteLlama をリリースしました。 4 億 6,000 万個のパラメータがあり、1T トークンでトレーニングされています。これは Meta AI の LLaMa 2 のオープンソース フォークですが、モデル サイズが大幅に小さくなっています。
 # プロジェクトアドレス: https://huggingface.co/ahxt/LiteLlama-460M-1T
# プロジェクトアドレス: https://huggingface.co/ahxt/LiteLlama-460M-1T
#LiteLlama-460M-1T は RedPajama データセットでトレーニングされ、GPT2Tokenizer を使用してテキストをトークン化します。著者は MMLU タスクでモデルを評価し、その結果を次の図に示します。パラメータの数を大幅に減らしても、LiteLlama-460M-1T は他のモデルと同等以上の結果を達成できます。
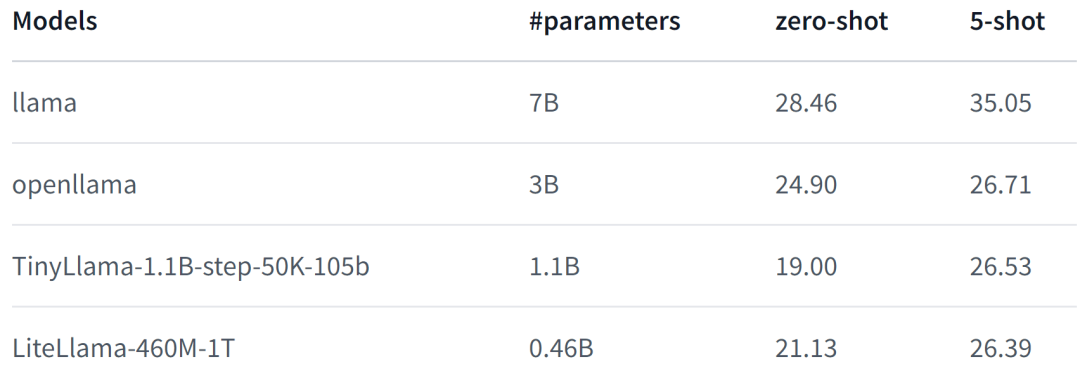 モデルの性能は次のとおりです。詳細については、
モデルの性能は次のとおりです。詳細については、
を参照してください。
https://www.php.cn/link/05ec1d748d9e3bbc975a057f7cd02fb6 LiteLlama の規模が大幅に縮小されたことに直面して、一部のネチズンは4GB のメモリで動作しますか?あなたも知りたいと思ったら、ぜひ試してみてはいかがでしょうか。 

以上が小さくても強力なモデルが増加中: TinyLlama と LiteLlama が人気の選択肢になるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。