



GPT-4 は、リリース以来世界で最も強力な言語モデルの 1 つとみなされていますが、残念ながら一連の信頼の危機を経験しました。
今年初めの「断続的インテリジェンス」インシデントを OpenAI による GPT-4 アーキテクチャの再設計と結び付けると、GPT-4 が「怠惰」になったという最近の報告があります。噂はさらに興味深いものです。誰かがテストした結果、GPT-4 に「冬休みです」と伝えると、冬眠状態に入ったかのように怠惰になることがわかりました。
新しいタスクにおけるモデルのゼロサンプルのパフォーマンスが低いという問題を解決するには、次の方法を採用できます。 1. データの強化: 既存のデータを拡張および変換することで、モデルの汎化能力を高めます。たとえば、画像データは、回転、拡大縮小、平行移動などによって、または新しいデータ サンプルを合成することによって変更できます。 2. 転移学習: 他のタスクでトレーニングされたモデルを使用して、そのパラメーターと知識を新しいタスクに転送します。これにより、既存の知識と経験を活用して改善できます。
最近、カリフォルニア大学サンタクルーズ校の研究者らは、パフォーマンスの根本的な理由を説明できる可能性がある新しい発見を論文で発表しました。 GPT-4の分解。

「LLM は、トレーニング データの作成日より前にリリースされたデータセットで驚くほど優れたパフォーマンスを発揮することがわかりました。データセットは後でリリースされました。」
「既知の」タスクでは良好なパフォーマンスを発揮しますが、新しいタスクではパフォーマンスが低下します。これは、LLM が近似検索に基づいて知性を模倣する方法にすぎず、主に理解レベルを問わず物事を暗記することを意味します。
はっきり言って、LLM の汎化能力は「言われているほど強力ではない」です。基礎がしっかりしていないため、実戦では必ずミスが発生します。
この結果の主な原因の 1 つは、データ汚染の一種である「タスク汚染」です。これまでよく知られてきたデータ汚染はテスト データ汚染です。これは、トレーニング前のデータにテスト データの例とラベルが含まれていることです。 「タスクの汚染」とは、タスクのトレーニング例がトレーニング前のデータに追加されることで、ゼロサンプルまたは少数サンプルの方法での評価が現実的で効果的ではなくなります。
研究者は、論文で初めてデータ汚染問題の体系的な分析を実施しました:

論文リンク: https://arxiv.org/pdf/2312.16337.pdf
論文を読んだ後、誰かが「悲観的に」言いました:
これは、継続的に学習する能力、つまり ML モデル トレーニング後に重みは固定されますが、入力分布は変化し続けるため、モデルがこの変化に適応し続けることができない場合、モデルは徐々に低下します。
これは、プログラミング言語が常に更新されるにつれて、LLM ベースのコーディング ツールも劣化することを意味します。これが、このような壊れやすいツールに過度に依存する必要がない理由の 1 つです。
これらのモデルを継続的に再トレーニングするコストは高くつくため、遅かれ早かれ、誰かがこれらの非効率な方法を諦めるでしょう。
以前のエンコード タスクに重大な中断やパフォーマンスの損失を引き起こすことなく、変化する入力分布に確実かつ継続的に適応できる ML モデルはまだありません。
そして、これは生物学的ニューラル ネットワークが得意とする分野の 1 つです。生物学的ニューラル ネットワークの強力な汎化能力により、さまざまなタスクを学習すると、システムのパフォーマンスがさらに向上します。これは、1 つのタスクから得られた知識が、「メタ学習」と呼ばれる学習プロセス全体の改善に役立つためです。
「タスク汚染」の問題はどれくらい深刻ですか?紙面の内容を見てみましょう。
モデルとデータセット
実験では 12 個のモデルが使用されています (表 1 を参照)。そのうちの 5 つは独自のものです。 GPT-3 シリーズ モデルのうち 7 つは、ウェイトに自由にアクセスできるオープン モデルです。

上記のアプローチの背後にある考慮事項は、ゼロショット評価と少数ショット評価では、モデルがトレーニング中に一度も見たことがないか、数回しか見たことがないタスクについての予測を行う必要があるということです。完了すべき特定のタスクにさらされることで、学習能力の公正な評価が保証されます。ただし、汚染されたモデルは、事前トレーニング中にタスク例に基づいてトレーニングされているため、実際にさらされていない、または数回しかさらされていない能力があるかのような錯覚を与える可能性があります。時系列のデータセットでは、重複や異常が明らかになるため、このような不一致を検出するのは比較的簡単です。
#測定方法 研究者らは、「タスクの汚染」を測定するために 4 つの方法を使用しました。- トレーニング データの検査: タスク トレーニングのサンプルのトレーニング データを検索します。
- タスク例の抽出: 既存のモデルからタスク例を抽出します。命令調整されたモデルのみを抽出でき、この分析はトレーニング データやテスト データの抽出にも使用できます。タスクの汚染を検出するために、抽出されたタスクの例が既存のトレーニング データの例と正確に一致する必要はないことに注意してください。タスクを実証するあらゆる例は、ゼロショット学習と少数ショット学習の混入の可能性を示しています。
- メンバーの推論: この方法はビルド タスクにのみ適用されます。入力インスタンスのモデル生成コンテンツが元のデータセットとまったく同じであることを確認します。正確に一致する場合、それが LLM トレーニング データのメンバーであると推測できます。これは、生成された出力が完全に一致するかどうかチェックされるという点で、タスク例の抽出とは異なります。オープンエンド生成タスクでの完全一致は、モデルが「超能力」を持ち、データで使用されている正確な表現を知っている場合を除き、モデルがトレーニング中にこれらの例を見たということを強く示唆します。 (これはビルド タスクにのみ使用できることに注意してください。)
- 時系列分析: 既知の時間枠中にトレーニング データが収集されたモデル セットの場合、既知のリリース日のデータセットでパフォーマンスを測定します。汚染の証拠については、一時的な証拠チェックを使用します。

#2. 研究者は、タスク汚染の可能性を見つけるために、トレーニング データの検査とタスク例の抽出を実施しました。タスクの汚染が考えられない分類タスクでは、ゼロショットか少数ショットかにかかわらず、モデルがタスクの範囲全体で単純多数派ベースラインを超える統計的に有意な改善を達成することはほとんどないことがわかりました (図 2)。
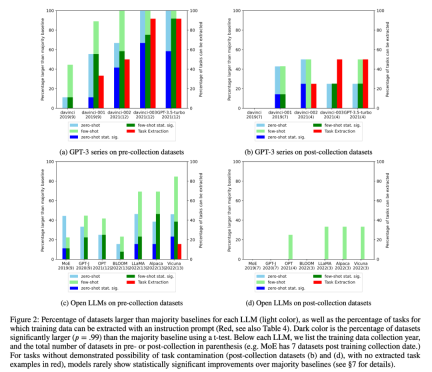
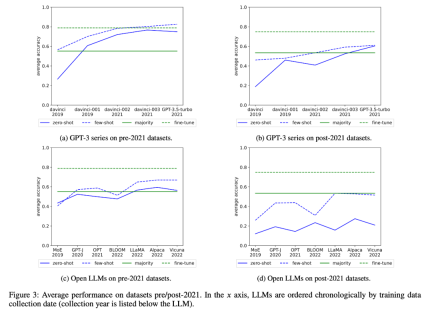
研究者らは、GPT-3 シリーズとオープン LLM の平均パフォーマンスの時間の経過に伴う変化も調べました。図 3 :
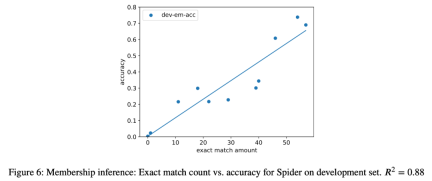
3. ケーススタディとして、研究者はまた、すべてのオブジェクトに対してセマンティック解析タスクを実行しようとしました。推論攻撃では、抽出されたインスタンスの数と最終タスクのモデルの精度の間に強い相関関係 (R=.88) が見つかりました (図 6)。これは、このタスクのゼロショット パフォーマンスの向上がタスクの汚染によるものであることを強く証明しています。
4. 研究者らはまた、GPT-3 シリーズ モデルを注意深く研究し、GPT-3 モデルからトレーニング サンプルを抽出でき、davinci から GPT-3.5-turbo までの各バージョンでトレーニング サンプルを抽出できることを発見しました。抽出された数は増加しています。これは、このタスクにおける GPT-3 モデルのゼロサンプル パフォーマンスの向上と密接に関係しています (図 2)。これは、これらのタスクにおける davinci から GPT-3.5-turbo への GPT-3 モデルのパフォーマンス向上がタスクの汚染によるものであることを強く証明しています。
以上がGPT-4の知能レベルの低下に関する新たな解釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 LM Studioを使用してLLMをローカルに実行する方法は? - 分析VidhyaApr 19, 2025 am 11:38 AM
LM Studioを使用してLLMをローカルに実行する方法は? - 分析VidhyaApr 19, 2025 am 11:38 AM自宅で大規模な言語モデルを簡単に実行する:LM Studioユーザーガイド 近年、ソフトウェアとハードウェアの進歩により、パーソナルコンピューターで大きな言語モデル(LLM)を実行することが可能になりました。 LM Studioは、このプロセスを簡単かつ便利にするための優れたツールです。この記事では、LM Studioを使用してLLMをローカルに実行する方法に飛び込み、重要なステップ、潜在的な課題、LLMをローカルに配置することの利点をカバーします。あなたが技術愛好家であろうと、最新のAIテクノロジーに興味があるかどうかにかかわらず、このガイドは貴重な洞察と実用的なヒントを提供します。始めましょう! 概要 LLMをローカルに実行するための基本的な要件を理解してください。 コンピューターにLM Studiをセットアップします
 Guy Periは、データ変換を通じてMcCormickの未来のフレーバーを支援しますApr 19, 2025 am 11:35 AM
Guy Periは、データ変換を通じてMcCormickの未来のフレーバーを支援しますApr 19, 2025 am 11:35 AMGuy Periは、McCormickの最高情報およびデジタルオフィサーです。彼の役割からわずか7か月後ですが、ペリは同社のデジタル能力の包括的な変革を急速に進めています。データと分析に焦点を当てている彼のキャリアに焦点が当てられています
 迅速なエンジニアリングの感情の連鎖は何ですか? - 分析VidhyaApr 19, 2025 am 11:33 AM
迅速なエンジニアリングの感情の連鎖は何ですか? - 分析VidhyaApr 19, 2025 am 11:33 AM導入 人工知能(AI)は、言葉だけでなく感情も理解し、人間のタッチで反応するように進化しています。 この洗練された相互作用は、AIおよび自然言語処理の急速に進む分野で重要です。 th
 データサイエンスワークフローのための12のベストAIツール-AnalyticsVidhyaApr 19, 2025 am 11:31 AM
データサイエンスワークフローのための12のベストAIツール-AnalyticsVidhyaApr 19, 2025 am 11:31 AM導入 今日のデータ中心の世界では、競争力と効率の向上を求める企業にとって、高度なAIテクノロジーを活用することが重要です。 さまざまな強力なツールにより、データサイエンティスト、アナリスト、開発者が構築、Deplを作成することができます。
 AV BYTE:OpenAIのGPT-4O MINIおよびその他のAIイノベーションApr 19, 2025 am 11:30 AM
AV BYTE:OpenAIのGPT-4O MINIおよびその他のAIイノベーションApr 19, 2025 am 11:30 AM今週のAIの風景は、Openai、Mistral AI、Nvidia、Deepseek、Hugging Faceなどの業界の巨人からの画期的なリリースで爆発しました。 これらの新しいモデルは、TRの進歩によって促進された電力、手頃な価格、アクセシビリティの向上を約束します
 PerplexityのAndroidアプリにはセキュリティの欠陥が感染しているとレポートApr 19, 2025 am 11:24 AM
PerplexityのAndroidアプリにはセキュリティの欠陥が感染しているとレポートApr 19, 2025 am 11:24 AMしかし、検索機能を提供するだけでなくAIアシスタントとしても機能する同社のAndroidアプリは、ユーザーをデータの盗難、アカウントの買収、および悪意のある攻撃にさらす可能性のある多くのセキュリティ問題に悩まされています。
 誰もがAIの使用が上手になっています:バイブコーディングに関する考えApr 19, 2025 am 11:17 AM
誰もがAIの使用が上手になっています:バイブコーディングに関する考えApr 19, 2025 am 11:17 AM会議や展示会で何が起こっているのかを見ることができます。エンジニアに何をしているのか尋ねたり、CEOに相談したりできます。 あなたが見ているところはどこでも、物事は猛烈な速度で変化しています。 エンジニア、および非エンジニア 違いは何ですか
 Rocketpyを使用したロケットの起動シミュレーションと分析-AnalyticsVidhyaApr 19, 2025 am 11:12 AM
Rocketpyを使用したロケットの起動シミュレーションと分析-AnalyticsVidhyaApr 19, 2025 am 11:12 AMRocketpy:A包括的なガイドでロケット発売をシミュレートします この記事では、強力なPythonライブラリであるRocketpyを使用して、高出力ロケット発売をシミュレートすることをガイドします。 ロケットコンポーネントの定義からシミュラの分析まで、すべてをカバーします


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

Dreamweaver Mac版
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

