
ホームページ >テクノロジー周辺機器 >AI >Transformer ランクを下げると、特定のレイヤー内の 90% 以上のコンポーネントの削除を減らすことなく、LLM を維持しながらパフォーマンスが向上します。
Transformer ランクを下げると、特定のレイヤー内の 90% 以上のコンポーネントの削除を減らすことなく、LLM を維持しながらパフォーマンスが向上します。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-01-13 21:51:06770ブラウズ
MIT とマイクロソフトは共同研究を実施し、追加のトレーニングなしで大規模な言語モデルのタスクのパフォーマンスを向上させ、そのサイズを縮小できることがわかりました。
大規模モデルの時代、Transformer は独自の機能で科学研究分野全体をサポートします。 Transformer ベースの言語モデル (LLM) は、その導入以来、さまざまなタスクで優れたパフォーマンスを実証してきました。 Transformer の基礎となるアーキテクチャは、自然言語モデリングと推論のための最先端のテクノロジとなり、コンピュータ ビジョンや強化学習などの分野で大きな可能性を示しています
しかし、現在の Transformer アーキテクチャは非常に大きく、通常はトレーニングと推論に多くのコンピューティング リソースを必要とします。
次のように書き換えます: より多くのパラメーターまたはデータでトレーニングされた Transformer は他のモデルよりも明らかに能力が高いため、これを行うのは理にかなっています。ただし、Transformer ベースのモデルとニューラル ネットワークでは、学習した仮説を維持するためにすべての適応パラメーターを保持する必要はないことが、ますます多くの研究で示されています。
一般に、モデルをトレーニングする場合、過剰なパラメーター化は非常に問題があるようです。便利ですが、これらのモデルは推論前に大幅に枝刈りされる可能性があります。研究によると、ニューラル ネットワークでは、パフォーマンスを大幅に低下させることなく、重みの 90% 以上を削除できることがわかっています。この現象は、モデル推論を支援する枝刈り戦略に対する研究者の関心を引き起こしました。
MIT と Microsoft の研究者は、論文「真実はそこにあります: 層選択的ランク削減による言語モデルの推論の改善により、驚くべき結果が得られました」と書いています。 Transformer モデルの特定のレイヤーを慎重にプルーニングすると、特定のタスクにおけるモデルのパフォーマンスが大幅に向上することがわかりました。

論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2312.13558.pdf
-
論文のホームページ: https://pratyushasharma.github.io/laser/
研究では、この単純な介入を LASER (Layer Selective Rank Reduction) と呼んでいます。 LLM の特性は、特異値分解を通じて Transformer モデルの特定の層の学習重み行列の高次成分を選択的に削減することで大幅に改善されます。この操作は、追加のパラメーターやデータなしでモデルのトレーニングが完了した後に実行できます。
操作中に、モデル固有の重み行列とレイヤーで重みの削減が実行されます。この研究では、多くの同様のマトリックスの重量を大幅に削減できることも判明しており、通常、コンポーネントの 90% 以上が除去されるまでパフォーマンスの低下は観察されません。また、これらの削減によって精度が大幅に向上する可能性があることも判明しました。この発見は次のように考えられます。自然言語に限定されず、強化学習でもパフォーマンスの向上が見られます。
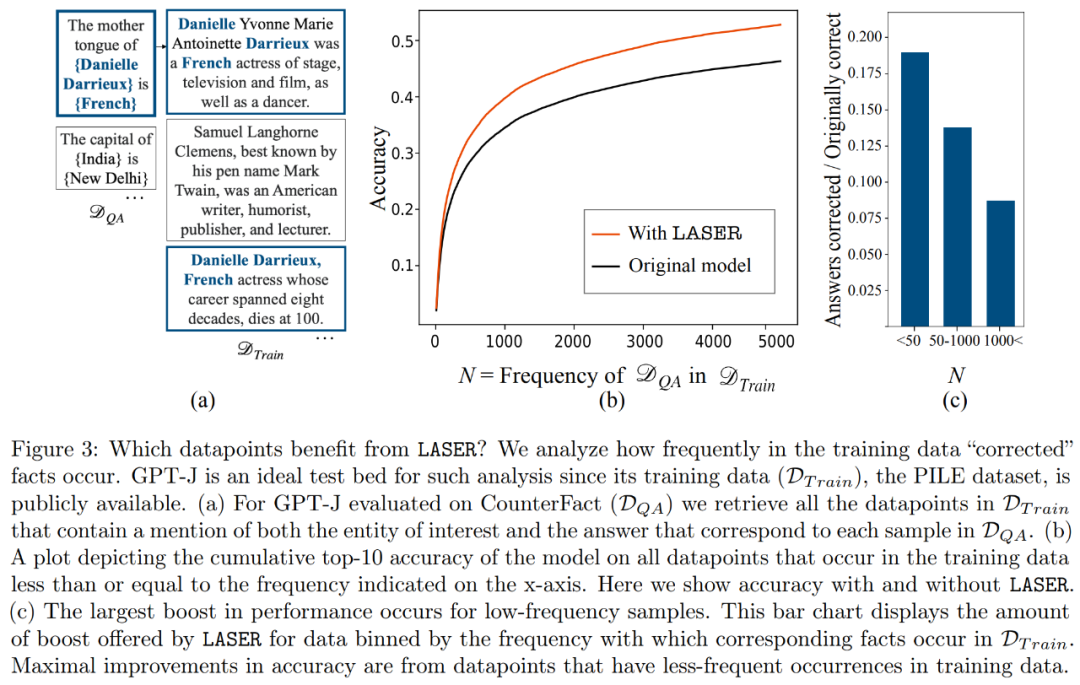
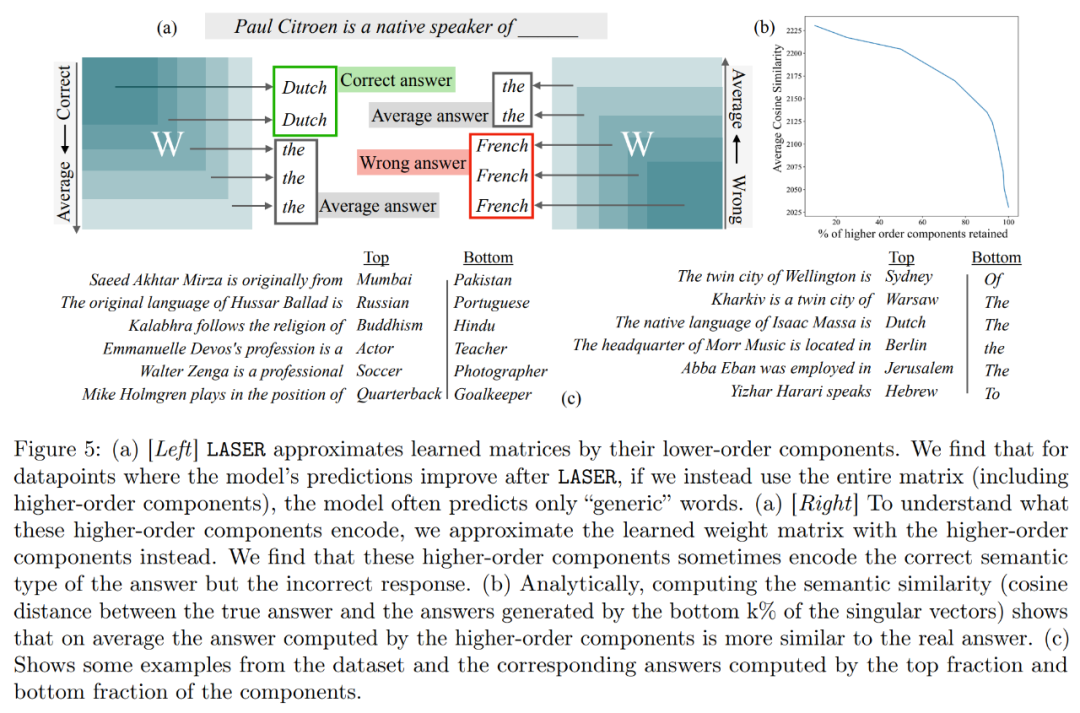
さらに、この研究では、上位コンポーネントに何が格納されているかを推測し、パフォーマンスを向上させるために削除できるようにすることを試みています。この研究では、LASER は正しい質問に答えましたが、介入前は、元のモデルは主に高頻度の単語 (「the」、「of」など) で応答しており、それらの単語は意味論的なタイプが質問と同じではなかったことがわかりました。つまり、これらのコンポーネントにより、モデルは介入なしで無関係な高頻度単語を生成します。
ただし、ある程度のランク削減を行うことで、モデルの答えを正解に変えることができます。
これを理解するために、この研究では、残りのコンポーネントが個別にエンコードするものについても調査し、高次の特異ベクトルのみを使用して重み行列を近似します。これらのコンポーネントは、正解と同じ意味カテゴリ内の異なる応答または共通の高頻度単語を記述していることが判明しました。
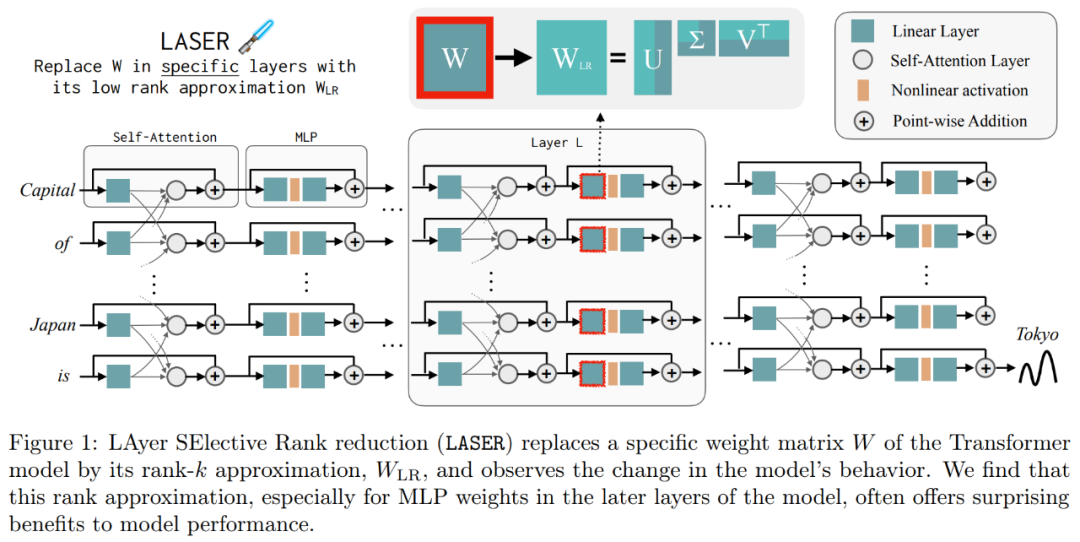
これらの結果は、ノイズの多い高次成分が低次成分と組み合わされると、それらの矛盾する応答により、不正確である可能性がある平均的な答えが生成されることを示唆しています。図 1 は、Transformer のアーキテクチャと LASER の手順を視覚的に表したものです。ここでは、多層パーセプトロン (MLP) の特定の層の重み行列が、その低ランク近似によって置き換えられます。
レーザーの概要レーザー介入について詳しく説明します。シングルステップの LASER 介入は、パラメータ τ、層の数 ℓ、および削減ランク ρ を含むトリプレット (τ、ℓ、ρ) によって定義されます。これらの値は合わせて、低ランク近似によって置き換えられる行列と近似の程度を記述します。研究者は、パラメータのタイプに基づいて介入する行列のタイプを分類します。
研究者は、MLP と次から構成されるアテンション層で構成される W = {W_q, W_k, W_v, W_o, U_in, U_out} の行列に焦点を当てます。の行列。階層の数は、研究者の介入の階層を表します (最初の階層には 0 から始まるインデックスが付けられます)。たとえば、Llama-2 には 32 層あるため、ℓ ∈ {0, 1, 2,・・・31} となります。
最終的に、ρ ∈ [0, 1) は、低ランクの近似を行うときに最大ランクのどの部分を保存する必要があるかを示します。たとえば、
と仮定すると、行列の最大ランクは d です。研究者らはこれを ⌊ρ・d⌋- 近似に置き換えました。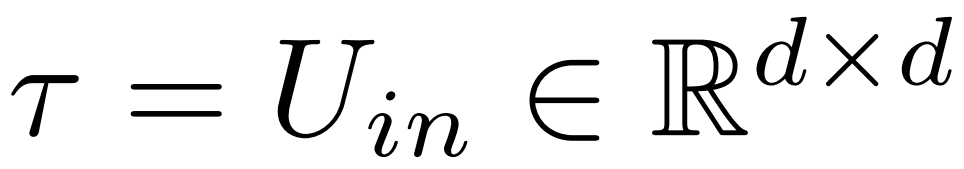 下の図 1 は LASER の例であり、この図では、τ = U_in および ℓ = L は、L^ 番目の層の Transformer ブロック内の MLP の最初の層の重み行列の更新を表します。別のパラメーターは、ランク k 近似の k を制御します。
下の図 1 は LASER の例であり、この図では、τ = U_in および ℓ = L は、L^ 番目の層の Transformer ブロック内の MLP の最初の層の重み行列の更新を表します。別のパラメーターは、ランク k 近似の k を制御します。
LASER は、ネットワーク内の特定の情報の流れを制限し、予期せぬパフォーマンス上の大幅な利点をもたらす可能性があります。これらの介入は簡単に組み合わせることができるため、一連の介入を任意の順序で適用できます。 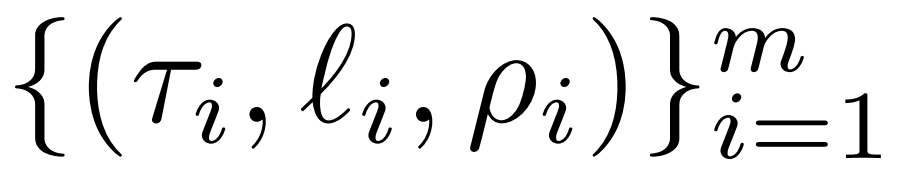
元の意味を変更しないようにするには、内容を中国語に書き直す必要があります。元の文を表示する必要はありません
実験部分では、研究者は PILE データセットで事前トレーニングされた GPT-J モデルを使用しました。モデルの層数は 27 で、パラメータは 60 億です。次に、モデルの動作が CounterFact データセットで評価されます。このデータセットには、(トピック、関係、回答) トリプルのサンプルが含まれており、質問ごとに 3 つの言い換えプロンプトが提供されます。 1 つ目は、CounterFact データセット上の GPT-J モデルの分析です。以下の図 2 は、Transformer アーキテクチャの各行列に異なる量のランク削減を適用した結果、データセットの分類損失に与える影響を示しています。 Transformer の各層は 2 層の小さな MLP で構成されており、入力行列と出力行列が個別に示されています。色が異なると、除去されたコンポーネントの割合が異なります。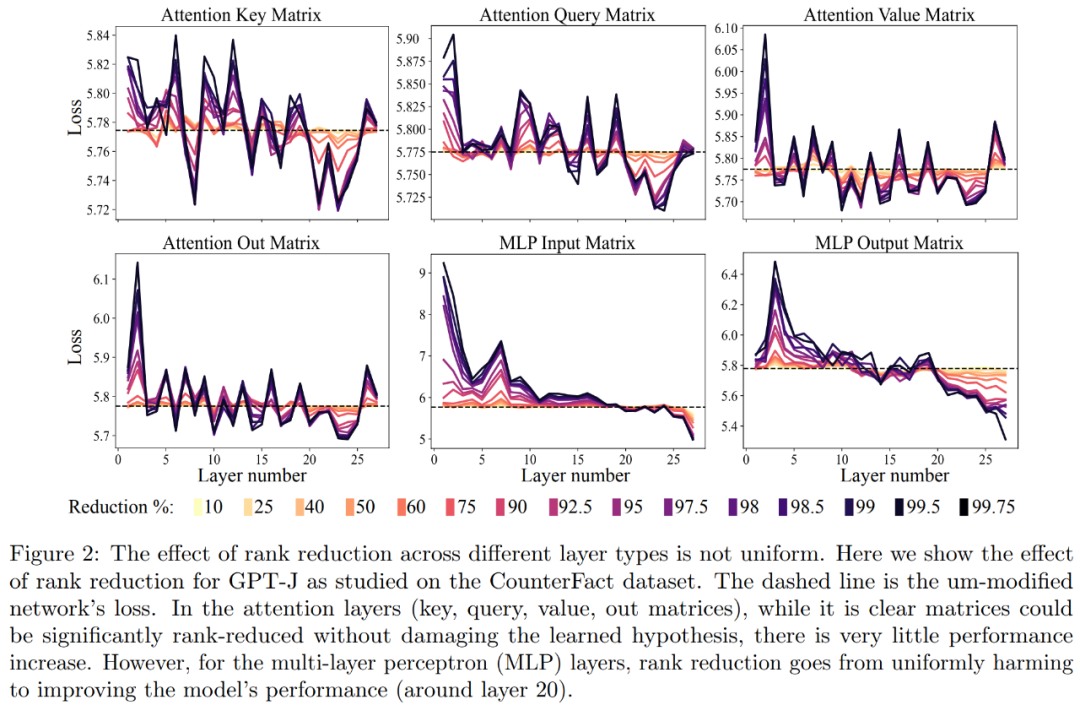
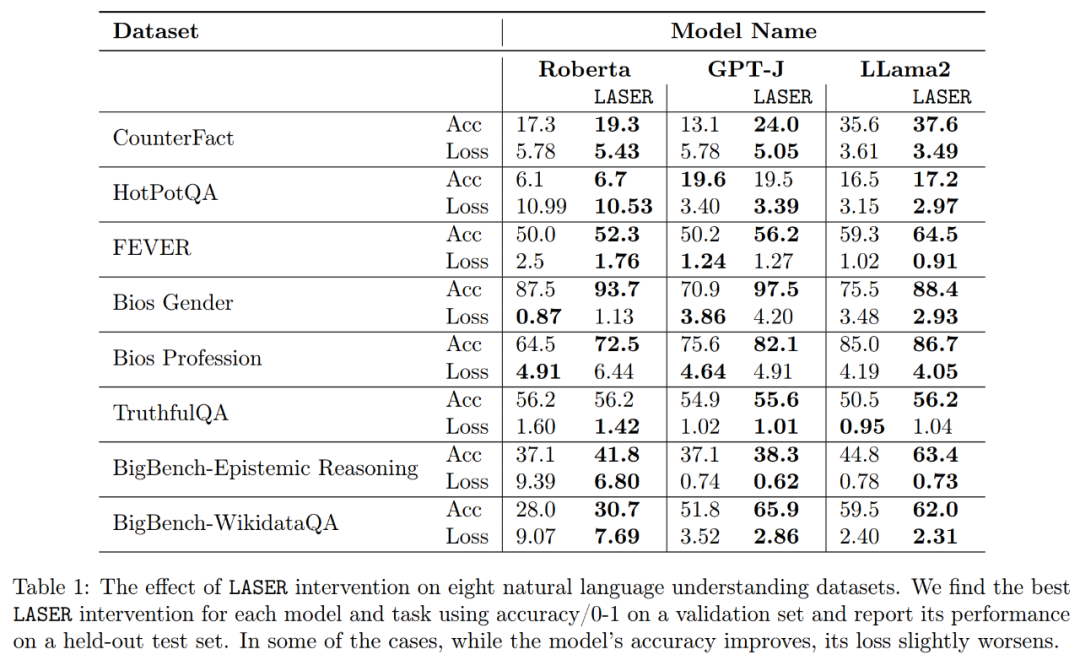
 ##最後に、研究者らは、複数の言語理解タスクに関する 3 つの異なる LLM に対する発見の一般化可能性を評価しました。タスクごとに、精度、分類精度、損失という 3 つの指標を生成してモデルのパフォーマンスを評価しました。上記の表 1 に示すように、ランクの低下が大きくても、モデルの精度は低下しませんが、モデルのパフォーマンスは向上します。
##最後に、研究者らは、複数の言語理解タスクに関する 3 つの異なる LLM に対する発見の一般化可能性を評価しました。タスクごとに、精度、分類精度、損失という 3 つの指標を生成してモデルのパフォーマンスを評価しました。上記の表 1 に示すように、ランクの低下が大きくても、モデルの精度は低下しませんが、モデルのパフォーマンスは向上します。
以上がTransformer ランクを下げると、特定のレイヤー内の 90% 以上のコンポーネントの削除を減らすことなく、LLM を維持しながらパフォーマンスが向上します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。