


ロボットにあなたの「ここにいます」を感知させます。清華大学のチームは何百万ものシナリオを使用して、人間と機械の普遍的なハンドオーバーを作成します。

清華大学学際情報研究所の研究者らは、ロボットがユニバーサルビジョンベースの人間と機械の引き継ぎ戦略を学習できるようにすることを目的とした「GenH2R」と呼ばれるフレームワークを提案した。この戦略により、ロボットは多様な形状と複雑な動作軌道を持つさまざまな物体をより確実に捕捉できるようになり、人間とコンピューターのインタラクションに新たな可能性をもたらします。この研究は、人工知能分野の発展に重要なブレークスルーをもたらし、現実のシナリオでのロボットの応用に大きな柔軟性と適応性をもたらします。

身体化インテリジェンス (身体化 AI) の時代の到来に伴い、私たちは知的体が環境と積極的に対話することを期待しています。この過程では、ロボットを人間の生活環境に統合し、人間と対話する(ヒューマン・ロボット・インタラクション)ことが重要になっています。私たちは、人間の行動と意図を理解し、人間の期待に最も応える方法で人間のニーズに応え、人間を身体化された知能の中心に置く方法 (人間中心の身体化 AI) を考える必要があります。重要なスキルの 1 つは、一般化可能な人間からロボットへのハンドオーバーであり、これにより、ロボットが人間とより適切に連携して、料理、家の整理整頓、家具の組み立てなどのさまざまな一般的な日常業務を完了できるようになります。
大規模モデルの爆発的な開発は、大量の高品質データからの大規模学習が一般知能に移行する可能性があることを示しています。では、一般知能は巨大ロボットによって取得できるのでしょうかデータと大規模な戦略の模倣? 人間と機械の引き継ぎスキル?しかし、現実世界でのロボットと人間の間の大規模な対話型学習は危険で費用がかかることを考えると、機械は人間に害を及ぼす可能性が高くなります。 シミュレーション環境で学習し、キャラクターシミュレーションと動的把握動作計画を使用して、大量の多様なロボット学習データを自動的に提供し、これらのデータを実際のロボットに適用します。この学習ベースの手法は「Sim-to」と呼ばれます。 -Real Transfer」は、ロボットと人間の間の協調的なインタラクション能力を大幅に向上させ、より高い信頼性を実現します。

そこで、シミュレーション、デモンストレーション、模倣の 3 つの観点から始めて「GenH2R」フレームワークが提案されました。エンドツーエンドのアプローチに基づいて、あらゆる把持方法、あらゆるハンドオーバー軌道、あらゆるオブジェクト形状に対する普遍的なハンドオーバーを初めて学習
: 1) 「GenH2R-Sim」環境で数百万レベルを提供 さまざまな複雑なシミュレーション生成が容易な引継ぎシナリオ、2) 視覚と行動の連携に基づく一連の自動化された専門家デモンストレーション (Expert Demonstration) 生成プロセスの導入、3) 4D 情報と予測支援 (点群時間) に基づく模倣学習の使用 (Imitation Learning) ) 方法。
SOTA メソッド (CVPR2023 ハイライト) と比較して、さまざまなテスト セットにおける GenH2R のメソッドの平均成功率は 14% 増加し、時間は 13% 短縮され、実際にはマシン 実験ではパフォーマンスがより堅牢になります。
紙のアドレス: https://arxiv.org/abs/2401.00929
紙のホームページ: https://GenH2R.github.io
- #紙のビデオ: https://youtu.be/BbphK5QlS1Y
- #メソッドの紹介
- #まだレベルをクリアしていないプレイヤーを助けるために、「シミュレーション環境」の詳細について学びましょう。 (GenH2R-Sim)」のパズルの解き方。
高品質で大規模な人間の手オブジェクト データセットを生成するために、GenH2R-Sim 環境は、把握ポーズと動作軌跡の両方の観点からシーンをモデル化します。
GenH2R-Sim は、把握姿勢に関して、ShapeNet から豊富な 3D オブジェクト モデルを導入し、引き継ぎに適した 3266 個の日常オブジェクトを選択し、器用な把握の生成手法 (DexGraspNet) を使用します。人間の手で物体を掴むシーンが合計 100 万件生成されました。動きの軌跡に関しては、GenH2R-Sim は複数の制御点を使用して複数の滑らかなベジェ曲線を生成し、人間の手や物体の回転を導入して、手で運ばれた物体のさまざまな複雑な動きの軌跡をシミュレートします。
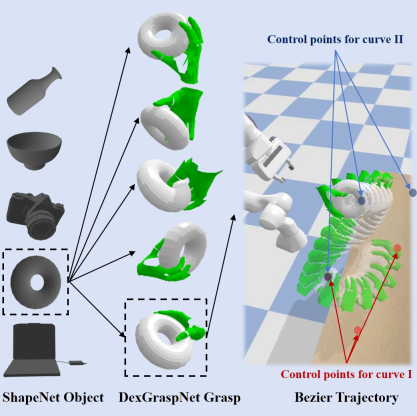
GenH2R-Sim の 100 万シーンでは、モーション軌跡 (1,000 対 100 万) やオブジェクトの数 (20) の点でも最新作をはるかに上回っています。 vs 3266)、また、実際の状況に近いインタラクティブな情報(ロボットアームが対象物に十分近づくと、人間は動きを止めて引き継ぎが完了するのを待つなど)も導入しています。単純な軌跡再生よりも。シミュレーションによって生成されたデータは完全に現実的ではありませんが、実験結果によると、大規模なシミュレーション データは小規模な実際のデータよりも学習に適しています。
#B. 蒸留に有益な専門家事例の大規模な生成
大規模なデータに基づく人間の手と物体の動きの軌跡データ、GenH2R は多数の専門家の例を自動的に生成します。 GenH2R が求める「専門家」は、改良されたモーション プランナー (OMG プランナーなど) です。これらのメソッドは非学習で、制御に最適化されており、視覚点群に依存しません。多くの場合、いくつかのシーン状態 (ターゲットの掴み位置など) が必要です。オブジェクトの)。)。その後のビジュアル ポリシー ネットワークが学習に有益な情報を確実に抽出できるようにするために、重要なのは、「専門家」によって提供される例にビジョンとアクションの相関関係があることを確認することです。計画中に最終着地点がわかっている場合、ロボット アームは視覚を無視して最終位置に直接計画を立てて「待ち続ける」ことができます。これにより、ロボットのカメラが物体を認識できなくなる可能性があります。この例は、下流の視覚戦略ネットワーク; 物体の位置に基づいてロボットアームの計画を頻繁に変更すると、ロボットアームが不連続に動いたり、奇妙な形状になったりして、合理的な把握を完了できなくなる可能性があります。
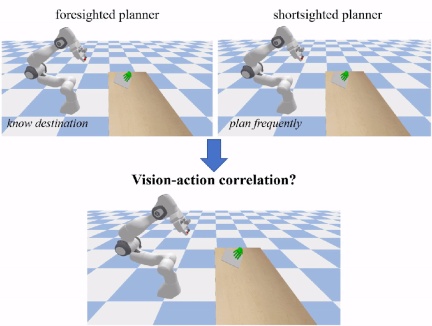
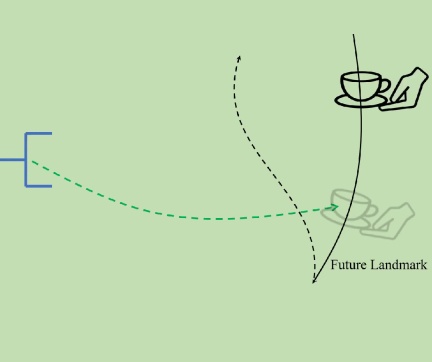
蒸留に適したエキスパートのサンプルを生成するために、GenH2R では Landmark Planning を導入しています。人間の手の動きの軌跡は、ランドマークを分割マークとして、軌跡の滑らかさと距離に応じて複数のセグメントに分割されます。各セグメントでは、人間の手の軌道は滑らかで、専門家の手法によりランドマーク ポイントに向かって計画されます。このアプローチにより、視覚とアクションの相関性とアクションの連続性の両方が保証されます。
C. 予測支援型 4D 模倣学習ネットワーク
に基づく大規模な専門家の例では、GenH2R は模倣学習手法を使用して 4D ポリシー ネットワークを構築し、観察された時系列点群情報をジオメトリとモーションに分解します。各フレームの点群について、前のフレームの点群と反復最近接点アルゴリズムの間の姿勢変換が計算されて、各点の流れ情報が推定され、各フレームの点群がすべて動きの特性を持つようになります。次に、PointNet を使用して点群の各フレームをエンコードし、最終的に必要な 6D 自己中心アクションをデコードするだけでなく、オブジェクトの将来の姿勢の予測も出力し、将来の手やオブジェクトの動きを予測するポリシー ネットワークの能力を強化します。 。
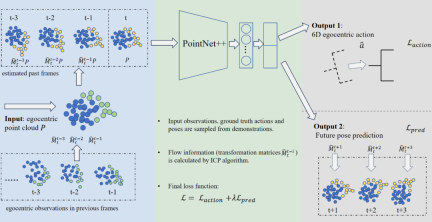
より複雑な 4D バックボーン (Transformer ベースなど) とは異なり、このネットワーク アーキテクチャは推論速度が速く、オブジェクトの受け渡しに適しています。この種の人間とコンピューターの対話シナリオでは、低遅延が必要であると同時に、タイミング情報を効果的に利用して、簡素さと効率性のバランスを実現できます。
#実験
A. シミュレーション環境実験
GenH2R とSOTA 手法をさまざまな設定で比較しましたが、GenH2R-Sim で小規模な実データをトレーニングに使用する手法と比較して、大規模なシミュレーション データをトレーニングに使用する手法は、大きな利点 (さまざまなテスト セットでの成功率) を達成できます。平均で 14% 増加し、時間は 13% 短縮されます)。
実際のデータ テスト セット s0 では、GenH2R メソッドはより複雑なオブジェクトを正常に引き渡すことができ、グリッパーがオブジェクトに近い場合に頻繁に姿勢を調整する必要がないように、事前に姿勢を調整できます。物体: ###############
シミュレーション データ テスト セット t0 (GenH2R-sim によって導入) では、GenH2R のメソッドは、より合理的な進入軌道を達成するために、物体の将来の姿勢を予測できます。
#実際のデータ テスト セット t1 (GenH2R-sim は HOI4D から導入され、以前の研究の s0 テスト セットより約 7 倍大きい) では、GenH2R のメソッドを目に見えないものに一般化できます。さまざまな幾何学的形状を持つ現実世界のオブジェクト。 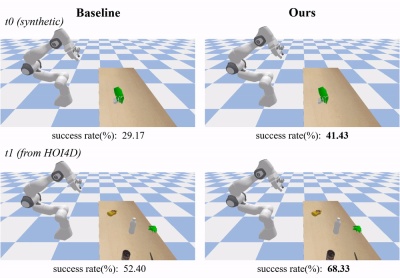
B. 実機実験
GenH2R は、学習した戦略を実世界のロボット アームに同時に展開しますそして「シミュレーションからリアルへ」のジャンプを完了します。
より複雑な運動軌跡 (回転など) の場合、GenH2R の戦略はより強い適応性を示し、より複雑な形状の場合、GenH2R の方法はより強い適応性を示します。
##GenH2R は、さまざまなハンドオーバー オブジェクトの実機テストとユーザー調査を完了し、強力な堅牢性を実証しています。

#実験や方法の詳細については、論文のホームページを参照してください。
チーム紹介
この論文は、清華大学 3DVICI 研究室、上海人工知能研究所、上海 Qizhi Research Institute からのものです。清華大学の学生、Wang Zifan (共著)、Chen Junyu (共著)、Chen Ziqing と Xie Pengwei が担当し、講師は Yi Li と Chen Rui です。
清華大学の 3 次元ビジョン コンピューティングおよび機械知能研究所 (略称 3DVICI 研究所) は、清華大学学際情報研究所の下にある人工知能研究所です。イ・リー教授。 3DVICI Lab は、人工知能における一般的な 3 次元視覚とインテリジェント ロボット インタラクションに関する最先端の課題を目指しており、その研究方向性は身体化された知覚、インタラクションの計画と生成、人間と機械のコラボレーションなどをカバーしており、アプリケーションと密接に関連しています。ロボット工学、仮想現実、自動運転などの分野。このチームの研究目標は、インテリジェント エージェントが 3 次元世界を理解し、対話できるようにすることであり、その結果は主要なトップ コンピュータ会議やジャーナルで発表されています。
以上がロボットにあなたの「ここにいます」を感知させます。清華大学のチームは何百万ものシナリオを使用して、人間と機械の普遍的なハンドオーバーを作成します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIセラピストがここにいます:あなたが知る必要がある14の画期的なメンタルヘルスツールApr 30, 2025 am 11:17 AM
AIセラピストがここにいます:あなたが知る必要がある14の画期的なメンタルヘルスツールApr 30, 2025 am 11:17 AM訓練を受けたセラピストの人間のつながりと直観を提供することはできませんが、多くの人々は、比較的顔のない匿名のAIボットと心配や懸念を共有することを快適に共有していることが研究で示されています。 これが常に良いかどうか
 食料品の通路にAIを呼びますApr 30, 2025 am 11:16 AM
食料品の通路にAIを呼びますApr 30, 2025 am 11:16 AM数十年の技術である人工知能(AI)は、食品小売業界に革命をもたらしています。 大規模な効率性の向上とコスト削減から、さまざまなビジネス機能にわたる合理化されたプロセスまで、AIの影響はUndeniablです
 あなたの精神を持ち上げるために生成的なAIからPEPの話をするApr 30, 2025 am 11:15 AM
あなたの精神を持ち上げるために生成的なAIからPEPの話をするApr 30, 2025 am 11:15 AMそれについて話しましょう。 革新的なAIブレークスルーのこの分析は、さまざまなインパクトのあるAIの複雑さを特定して説明するなど、最新のAIで進行中のForbes列のカバレッジの一部です(こちらのリンクを参照)。さらに、私のコンプのために
 AI駆動のハイパーパーソナリゼーションがすべてのビジネスにとって必須である理由Apr 30, 2025 am 11:14 AM
AI駆動のハイパーパーソナリゼーションがすべてのビジネスにとって必須である理由Apr 30, 2025 am 11:14 AMプロの画像を維持するには、時折ワードローブの更新が必要です。 オンラインショッピングは便利ですが、対面の試練の確実性がありません。 私の解決策? AI駆動のパーソナライズ。 衣類の選択をキュレーションするAIアシスタントが想像しています
 Duolingoを忘れてください:Google Translateの新しいAI機能は言語を教えていますApr 30, 2025 am 11:13 AM
Duolingoを忘れてください:Google Translateの新しいAI機能は言語を教えていますApr 30, 2025 am 11:13 AMGoogle Translateは言語学習機能を追加します Android Authorityによると、App Expert AssemberBugは、Google Translateアプリの最新バージョンには、パーソナライズされたアクティビティを通じてユーザーが言語スキルを向上させるように設計された新しい「実践」モードのテストコードが含まれていることを発見しました。この機能は現在、ユーザーには見えませんが、AssembleDebugはそれを部分的にアクティブにして、新しいユーザーインターフェイス要素の一部を表示できます。 アクティブ化すると、この機能は、「ベータ」バッジでマークされた画面の下部に新しい卒業キャップアイコンを追加し、「実践」機能が最初に実験形式でリリースされることを示します。 関連するポップアッププロンプトは、「あなたのために調整されたアクティビティを練習してください!」を示しています。つまり、Googleがカスタマイズされたことを意味します
 彼らはAIのためにTCP/IPを作成しており、Nandaと呼ばれていますApr 30, 2025 am 11:12 AM
彼らはAIのためにTCP/IPを作成しており、Nandaと呼ばれていますApr 30, 2025 am 11:12 AMMITの研究者は、AIエージェント向けに設計された画期的なWebプロトコルであるNandaを開発しています。 ネットワークエージェントと分散型AIの略であるNandaは、インターネット機能を追加することにより、人類のモデルコンテキストプロトコル(MCP)に基づいて構築され、AI Agenを可能にします
 プロンプト:Deepfake Detectionは活況を呈しているビジネスですApr 30, 2025 am 11:11 AM
プロンプト:Deepfake Detectionは活況を呈しているビジネスですApr 30, 2025 am 11:11 AMメタの最新のベンチャー:chatgptに匹敵するAIアプリ Facebook、Instagram、WhatsApp、およびThreadsの親会社であるMetaは、新しいAIを搭載したアプリケーションを立ち上げています。 このスタンドアロンアプリであるMeta AIは、OpenaiのChatGptと直接競争することを目指しています。 レバー
 ビジネスリーダーのためのAIサイバーセキュリティでの次の2年間Apr 30, 2025 am 11:10 AM
ビジネスリーダーのためのAIサイバーセキュリティでの次の2年間Apr 30, 2025 am 11:10 AMAIサイバー攻撃の上昇する潮をナビゲートします 最近、人類のためのCISOであるジェイソン・クリントンは、機械間通信が増殖すると、これらの「アイデンティティ」を保護するために、非人間のアイデンティティに結びついた新たなリスクを強調しました。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません
ホットトピック
 7861
7861 15164914140452130025124229
15164914140452130025124229