
ホームページ >テクノロジー周辺機器 >AI >OpenAI がセキュリティ チームを強化し、危険な AI に拒否権を与える
OpenAI がセキュリティ チームを強化し、危険な AI に拒否権を与える

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-12-19 17:30:411379ブラウズ
運用中のモデルは、「セキュリティ システム」チームによって管理されます。開発中の最先端モデルには、モデルがリリースされる前にリスクを特定して定量化する「準備」チームがいます。次に、「スーパー アライメント」チームがあり、「スーパー インテリジェンス」モデルの理論的ガイドラインに取り組んでいます。
セキュリティ諮問グループを再編成し、技術チームの上に位置し、経営陣に勧告を行い、取締役会に拒否権を与えるOpenAI は、有害な人工知能の脅威から守るために、内部セキュリティ プロセスを強化していると発表しました。彼らは「セキュリティ諮問グループ」と呼ばれる新しい部門を創設し、テクノロジーチームの上に位置し、経営陣にアドバイスを提供し、取締役会の拒否権を与える予定だ。この決定は現地時間 12 月 18 日に発表されました
このアップデートが懸念を引き起こしているのは、OpenAI CEO の Sam Altman が取締役会によって解任されたことが主な理由であり、これは大規模モデルのセキュリティ問題に関連しているようです。 OpenAI取締役会の2人の「失速」メンバー、イリヤ・サツクビ氏とヘレン・トナー氏が、ハイレベルの刷新を受けて取締役の座を失った
この投稿では、OpenAI が、ますます強力になるモデルによってもたらされる壊滅的なリスクを OpenAI がどのように追跡、評価、予測し、防御するのかについて、最新の「準備フレームワーク」について説明します。壊滅的リスクの定義は何ですか? OpenAI は、「私たちが壊滅的リスクと呼んでいるものは、数千億ドルの経済損失をもたらしたり、多くの人に重傷を負わせたり死亡させたりする可能性のあるリスクを指します。これには存続リスクも含まれますが、これに限定されません。」
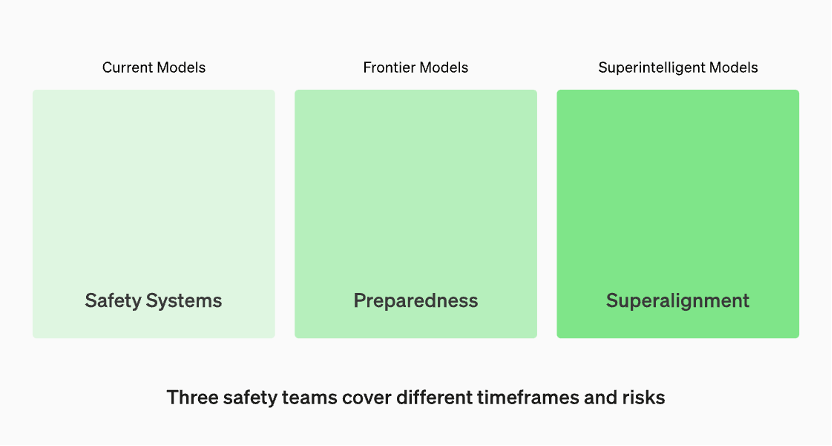
OpenAI 公式 Web サイトの情報によると、運用中のモデルは「セキュリティ システム」チームによって管理されています。開発段階では、モデルのリリース前にリスクを特定し評価する「準備」と呼ばれるチームが存在します。さらに、「スーパーアライメント」と呼ばれるチームがあり、「超インテリジェント」モデルの理論的ガイドラインに取り組んでいます。
OpenAI チームは、サイバーセキュリティ、説得力 (偽情報など)、モデルの自律性 (自律的に行動する能力)、CBRN (化学的、生物学的、放射性物質、核の脅威など) の 4 つのリスク カテゴリに従って各モデルを評価します。新しい病原体を作り出す能力)
OpenAI は、その仮定においてさまざまな緩和策を考慮しています。たとえば、モデルはナパーム弾やパイプ爆弾の製造プロセスの記述について合理的な留保を維持しています。既知の緩和策を考慮した後でもモデルが「高」リスクがあると評価された場合、そのモデルは導入されません。また、モデルに「重大な」リスクがある場合、それ以上開発されません
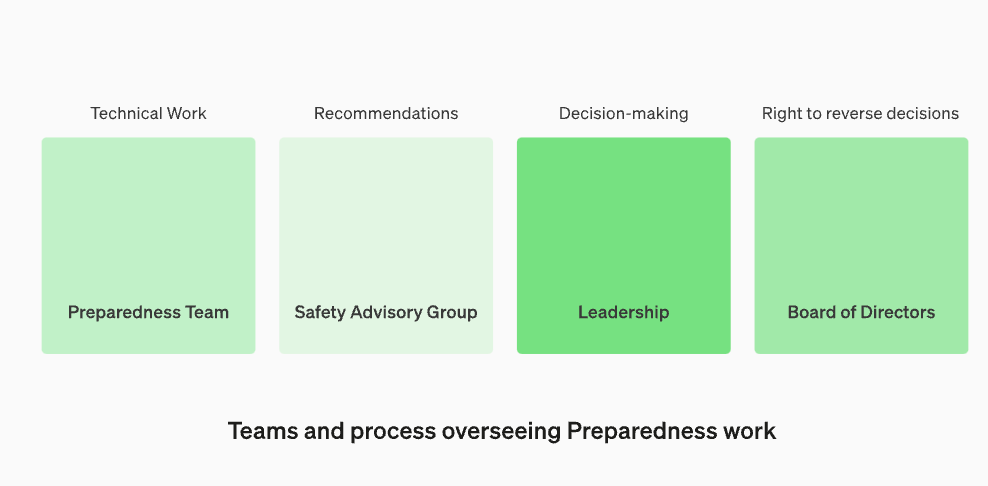
モデルを作成する人全員が、モデルを評価して推奨事項を作成するのに最適な人物であるとは限りません。このため、OpenAIは「機能横断型セキュリティ諮問グループ」と呼ばれるチームを設立し、研究者の報告書を技術レベルから検討し、より高い視点からの提言を行い、「未知の部分」の一部を明らかにしたいと考えている。 「 」
このプロセスでは、これらの推奨事項が取締役会と経営陣の両方に送信され、業務を継続するか停止するかを決定する必要がありますが、取締役会にはそれらの決定を取り消す権限があります。これにより、リスクの高い製品やプロセスが取締役会の知らないうちに承認されることを防ぎます
しかし、外部の世界は依然として、専門委員会が勧告を出し、その情報に基づいて CEO が決定を下した場合、OpenAI の取締役会には本当に反論して行動を起こす権利があるのだろうか、と懸念しています。もしそうなら、一般の人々はそれについて聞くでしょうか?現在、独立した第三者監査を求めるという OpenAI の約束を除けば、その透明性の問題は実際には真に対処されていません。
OpenAI の「Readiness Framework」には、次の 5 つの重要な要素が含まれています。
1. 評価と採点私たちはモデルを評価し、「スコアカード」を継続的に更新します。トレーニング中の効率的な計算を 3 倍にするなど、すべての最先端のモデルを評価します。私たちはモデルの限界を押し広げます。これらの調査結果は、最新モデルのリスクを評価し、提案された緩和策の有効性を測定するのに役立ちます。私たちの目標は、エッジ特有の不安を検出してリスクを効果的に軽減することです。モデルの安全性レベルを追跡するために、リスク「スコアカード」と詳細なレポートを作成します
すべての最先端モデルを評価するには、「スコアカード」が必要です
リスクしきい値を設定する目的は、意思決定を行ってリスクを管理する際に明確な境界線を持つことです。リスクしきい値とは、組織または個人が特定の状況下で許容するリスクの最大レベルを指します。リスクのしきい値を設定すると、組織や個人がリスクを軽減または回避するためにいつ行動が必要かを特定できるようになります。リスクしきい値の設定は、リスク評価の結果、関連する規制やポリシー、組織または個人のリスク許容度に基づいて行う必要があります。リスクしきい値を設定するときは、リスク管理手段の有効性と適用性を確保するために、さまざまなリスクの種類の特性と影響を考慮する必要があります。最後に、組織または個人のリスク管理目標との一貫性を保つために、設定されたリスクしきい値を定期的に評価および調整する必要があります。
セキュリティ対策を発動するリスクしきい値を設定します。当社は、サイバーセキュリティ、CBRN (化学、生物学、放射線、核の脅威)、説得、およびモデルの自律性という予備的な追跡カテゴリに基づいて、リスク レベルのしきい値を設定します。 4 つのセキュリティ リスク レベルを指定し、緩和後のスコアが「中」以下のモデルのみをデプロイでき、緩和後のスコアが「高」以下のモデルのみをさらに開発できます。高いリスクまたは重大なリスク (事前緩和) を持つモデルについては、追加のセキュリティ対策も実装します

技術作業と安全に関する意思決定を監督するための運営体制を再設定する
当社は、セキュリティに関する意思決定の技術的な作業と運用構造を監督する専門チームを設立します。準備チームは、最先端モデルの機能の限界を調査し、評価と包括的なレポートを実施するための技術的な作業を推進します。この技術的な作業は、OpenAI セキュリティ モデルの開発と展開の決定にとって重要です。私たちはすべての報告書を検討し、経営陣と取締役会の両方に報告するために、部門横断的なセキュリティ諮問グループを設立しています。意思決定者はリーダーシップですが、取締役会は決定を覆す権限を持っています
セキュリティの強化と対外的な説明責任の強化
私たちは、安全性と外部の説明責任を向上させるためのプロトコルを開発します。当社は定期的にセキュリティ訓練を実施し、当社のビジネスと当社の文化をストレステストします。一部のセキュリティ問題はすぐに発生する可能性があるため、緊急の問題にフラグを立てて迅速に対応することができます。 OpenAI 外部の人々からフィードバックを受け取り、資格のある独立した第三者によるレビューを受けることが有益であると私たちは信じています。今後も他のメンバーにレッド チームを形成してもらい、モデルを評価してもらい、更新情報を外部に共有する予定です
その他の既知および未知のセキュリティ リスクを軽減します:
当社は、その他の既知および未知のセキュリティ リスクの軽減を支援します。私たちは外部関係者と緊密に連携するだけでなく、セキュリティ システムなどの社内チームと緊密に連携して、実際の不正行為を追跡していきます。また、スーパーアライメントと協力して、緊急のミスアライメントのリスクを追跡します。また、スケールの法則で以前に成功したのと同様に、モデルのスケールに応じてリスクがどのように進化するかを測定し、リスクを事前に予測するのに役立つ新しい研究も開拓しています。最後に、私たちは継続的なプロセスに取り組み、新たな「未知の未知の問題」を解決しようとします。
以上がOpenAI がセキュリティ チームを強化し、危険な AI に拒否権を与えるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。