
OpenAI と Microsoft Sentinel の概要

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-13 12:07:111835ブラウズ
OpenAI と Microsoft Sentinel に関するシリーズへようこそ! OpenAI の GPT3 ファミリなどの大規模言語モデル (LLM) は、テキストの要約、人間のような会話、コードの解析とデバッグ、その他多くの例などの革新的な使用例で一般の人々の想像力を引き継いでいます。私たちは、ChatGPT が脚本や詩を書き、音楽を作曲し、エッセイを書き、さらにはコンピューター コードをある言語から別の言語に翻訳するのを見てきました。
この素晴らしい可能性を利用して、セキュリティ オペレーション センターのインシデント対応担当者を支援できたらどうでしょうか?もちろん、それは可能です - そしてそれは簡単です! Microsoft Sentinel には、Azure Logic Apps を利用した自動化プレイブックに実装できる OpenAI GPT3 モデル用の組み込みコネクタがすでに含まれています。これらの強力なワークフローは、簡単に作成して SOC 操作に統合できます。今日は、OpenAI コネクタを見て、簡単な使用例を使用して、その構成可能なパラメータのいくつかを調べます。これは、Sentinel イベントに関連する MITRE ATT&CK ポリシーを説明するものです。
始める前に、いくつかの前提条件について説明します:
- Microsoft Sentinel インスタンスをまだお持ちでない場合は、無料の Azure アカウントを使用してインスタンスを作成し、「開始する」に従ってください。 Sentinel を使用してすぐに始めましょう。
- Microsoft Sentinel Training Lab からの事前に記録されたデータを使用して、プレイブックをテストします。
- GPT3 接続用の API キーを持つ個人の OpenAI アカウントも必要です。
- また、ChatGPT と Sentinel を使用したイベントの処理に関する Antonio Formato の優れたブログをチェックすることを強くお勧めします。Antonio は、これまでに参照した Sentinel のほぼすべての OpenAI モデルに実装されている非常に便利な多目的マニュアルを紹介しています。
基本的なインシデント トリガー プレイブックから始めます ([センチネル] > [自動化] > [作成] > [インシデント トリガーを含むプレイブック])。
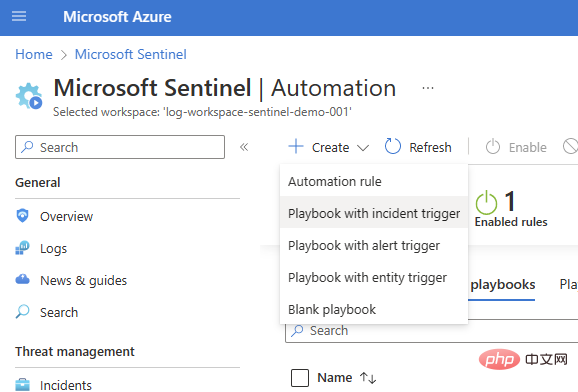
サブスクリプションとリソース グループを選択し、プレイブック名を追加して、[接続] タブに移動します。 1 つまたは 2 つの認証オプションを備えた Microsoft Sentinel が表示されます (この例ではマネージド ID を使用しています)。ただし、まだ接続がない場合は、Logic Apps デザイナーで Sentinel 接続を追加することもできます。
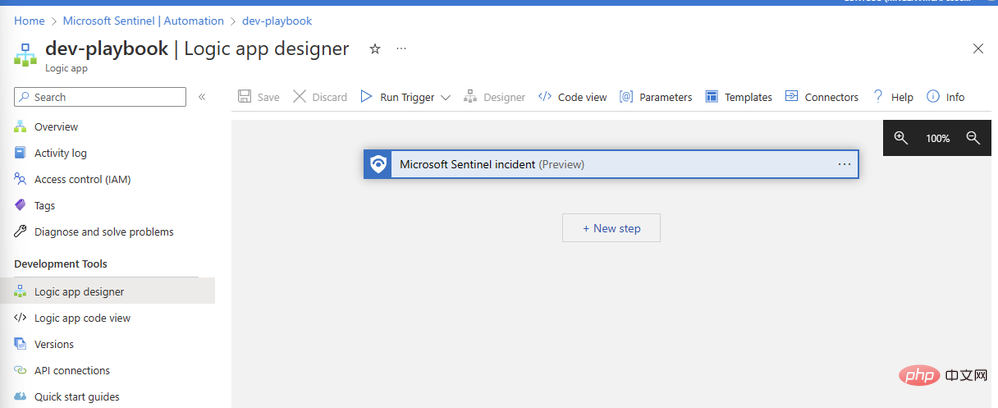 #OpenAI コネクタを追加しましょう。 [新しいステップ] をクリックし、検索ボックスに「OpenAI」と入力します。上部ペインにコネクタが表示され、その下に「イメージの作成」と「GPT3 プロンプトを完了する」という 2 つのアクションが表示されます。
#OpenAI コネクタを追加しましょう。 [新しいステップ] をクリックし、検索ボックスに「OpenAI」と入力します。上部ペインにコネクタが表示され、その下に「イメージの作成」と「GPT3 プロンプトを完了する」という 2 つのアクションが表示されます。
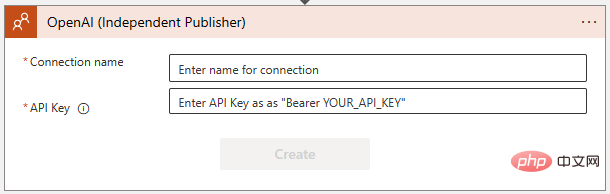 「GPT3 プロンプトを完了する」を選択します。 」。次に、次のダイアログ ボックスで OpenAI API への接続を作成するように求められます。まだ作成していない場合は、https://platform.openai.com/account/api-keys でキーを作成し、安全な場所に保管してください。
「GPT3 プロンプトを完了する」を選択します。 」。次に、次のダイアログ ボックスで OpenAI API への接続を作成するように求められます。まだ作成していない場合は、https://platform.openai.com/account/api-keys でキーを作成し、安全な場所に保管してください。
OpenAI API キーを追加するときは、指示に正確に従ってください。「Bearer」という単語、その後にスペース、その後にキー自体が必要です。 ## ## ###########成功!これで、プロンプトに対する GPT3 テキスト補完の準備が整いました。 AI モデルに Sentinel イベントに関連する MITRE ATT&CK 戦略とテクニックを解釈させたいので、動的コンテンツを使用して Sentinel からイベント戦略を挿入する簡単なプロンプトを作成しましょう。
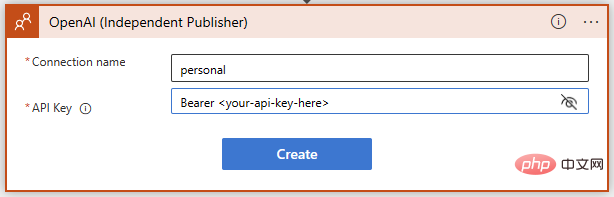 もうすぐ完了です。ロジック アプリを保存し、Microsoft Sentinel Events に移動してテスト実行します。私のインスタンスには Microsoft Sentinel Training Lab からのテスト データがあるため、悪意のある受信トレイ ルールのアラートによってトリガーされたイベントに対してこのプレイブックを実行します。
もうすぐ完了です。ロジック アプリを保存し、Microsoft Sentinel Events に移動してテスト実行します。私のインスタンスには Microsoft Sentinel Training Lab からのテスト データがあるため、悪意のある受信トレイ ルールのアラートによってトリガーされたイベントに対してこのプレイブックを実行します。
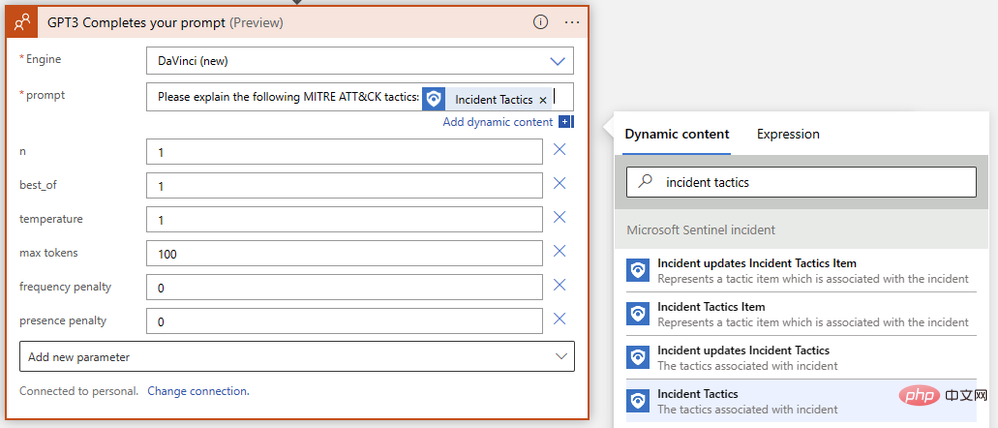 なぜプレイブックに結果を含むコメントまたはタスクを追加する 2 番目のアクションを構成しなかったのか疑問に思われるかもしれません。そこには到達しますが、最初に、プロンプトが AI モデルから適切なコンテンツを返すことを確認したいと思います。プレイブックに戻り、新しいタブで概要を開きます。実行履歴に緑色のチェックマークが付いている項目が表示されるはずです:
なぜプレイブックに結果を含むコメントまたはタスクを追加する 2 番目のアクションを構成しなかったのか疑問に思われるかもしれません。そこには到達しますが、最初に、プロンプトが AI モデルから適切なコンテンツを返すことを確認したいと思います。プレイブックに戻り、新しいタブで概要を開きます。実行履歴に緑色のチェックマークが付いている項目が表示されるはずです:
項目をクリックして、ロジック アプリの実行に関する詳細を表示します。任意の操作ブロックを展開して、詳細な入出力パラメーターを表示できます。
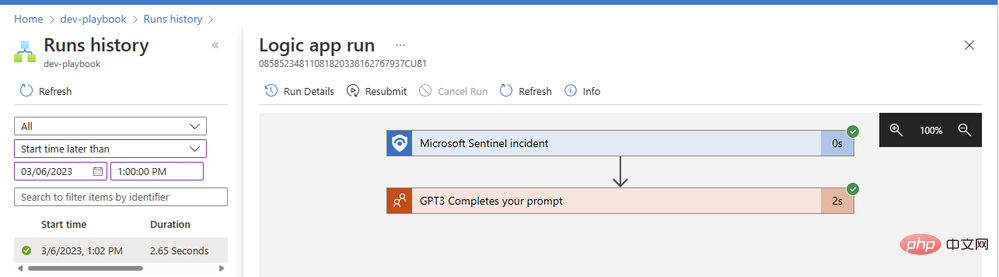
GPT3 操作は、正常に完了するまでにわずか 2 秒かかりました。アクション ブロックをクリックして展開し、その入力と出力の詳細を確認してみましょう。
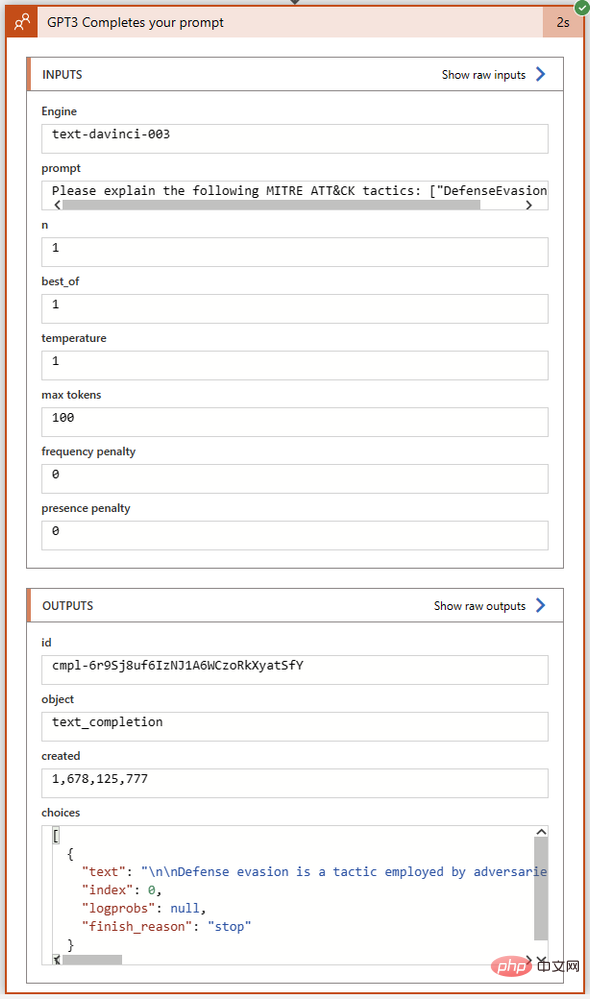
[出力] セクションの [選択] フィールドを詳しく見てみましょう。ここで、GPT3 は完了ステータスおよびエラー コードとともに完了テキストを返します。 Choices 出力の全文を Visual Studio Code にコピーしました。
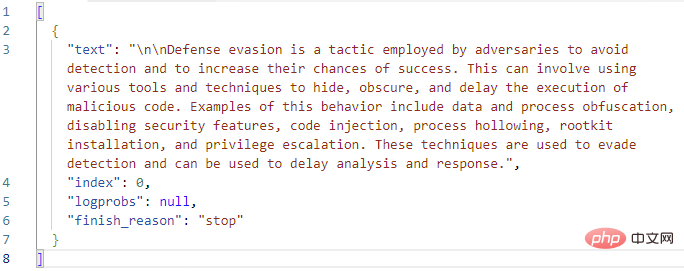
これまでのところ、うまくいきました。 GPT3 は、「防御回避」の MITRE 定義を正しく拡張します。論理アクションをプレイブックに追加して、この回答テキストを含むイベント コメントを作成する前に、GPT3 アクション自体のパラメーターをもう一度見てみましょう。 OpenAI テキスト補完アクションには、エンジンの選択とプロンプトを除いて、合計 9 つのパラメーターがあります。
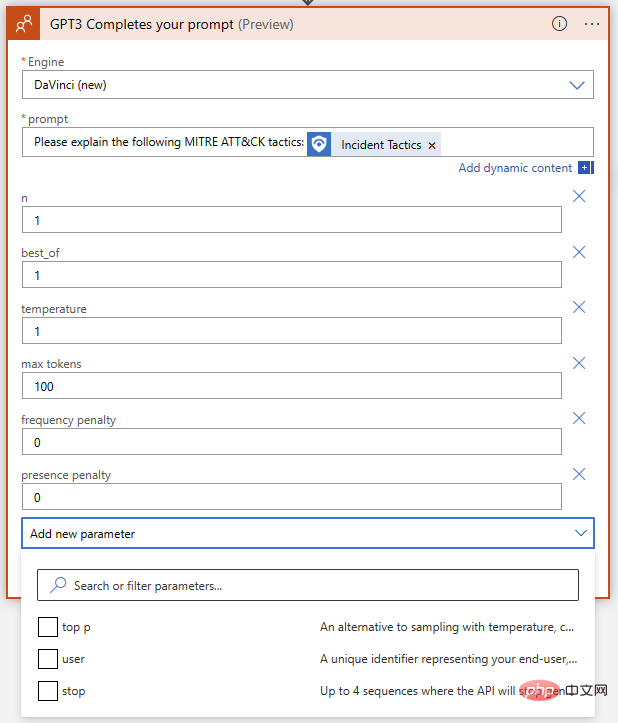
これらは何を意味し、どのように調整すれば、最良の結果は?各パラメータが結果に与える影響を理解するために、OpenAI API Playground にアクセスしてみましょう。ロジック アプリが実行される入力フィールドに正確なプロンプトを貼り付けることができますが、[送信] をクリックする前にパラメーターが一致していることを確認する必要があります。 Azure Logic App OpenAI Connector と OpenAI Playground のパラメーター名を比較した簡単な表を次に示します。
| #Azure Logic App Connector | OpenAIPlayground | 説明 |
| Engine | Model | は完成したモデルを生成します。 OpenAI コネクタでは、「text-davinci-003」、「text-davinci-002」、「text -curie」に対応して、Leonardo da Vinci (new)、Leonardo da Vinci (old)、Curie、Babbage、または Ada を選択できます。 Playground の -001' 、 'text-babbage-001' および 'text-ada-001'。 |
| n | N/A | プロンプトごとに生成する補完の数。これは、プレイグラウンドでプロンプトを複数回再入力することと同じです。 |
| Best | (同じ) | 複数の補完を生成し、最良のものを返します。使用には注意してください。これには大量のトークンがかかります。 |
| 温度 | (同じ) | 応答のランダム性 (または創造性) を定義します。 0 に設定すると、モデルが常に最も信頼できる選択を返す、高度に決定的なプロンプト完了が繰り返されます。よりランダム性を高めた最大限のクリエイティブな応答を得るには 1 に設定するか、必要に応じてその中間の値に設定します。 |
| 最大トークン数 | 最大長 | トークン形式で指定された ChatGPT 応答の最大長。トークンは約 4 文字に相当します。 ChatGPT はトークン価格設定を採用しており、この記事の執筆時点では 1000 トークンのコストは 0.002 ドルです。 API 呼び出しのコストには、ヒント付きのトークン長と応答が含まれるため、応答あたりのコストを最低に維持したい場合は、1000 からヒント付きのトークン長を引いて応答の上限を設定します。 |
| 周波数ペナルティ | (同じ) | 0 から 2 までの数値。値が大きいほど、モデルがその行をそのまま繰り返す可能性は低くなります (その行の同義語や言い換えを見つけようとします)。 |
| ペナルティあり | (同) | 0から2までの数字。値が高くなるほど、モデルが応答ですでに言及されたトピックを繰り返す可能性が低くなります。 |
| トップ | (同じ) | 温度を使用しない場合、「創造性」への反応を設定する別の方法。このパラメータは、確率に基づいて可能な回答トークンを制限します。1 に設定すると、すべてのトークンが考慮されますが、値が小さいほど、可能な回答のセットが上位 X% に減ります。 |
| ユーザー | 該当なし | 一意の識別子。 API キーはすでに識別文字列として使用されているため、このパラメーターを設定する必要はありません。 |
| 停止 | シーケンスの停止 | 最大 4 つのシーケンスでモデルの応答を終了します。 |
次の OpenAI API Playground 設定を使用して、ロジック アプリケーションのアクションと一致させましょう:
- モデル: text-davinci-003
- 温度: 1
- 最大長さ: 100
これは GPT3 エンジンから得られた結果です。
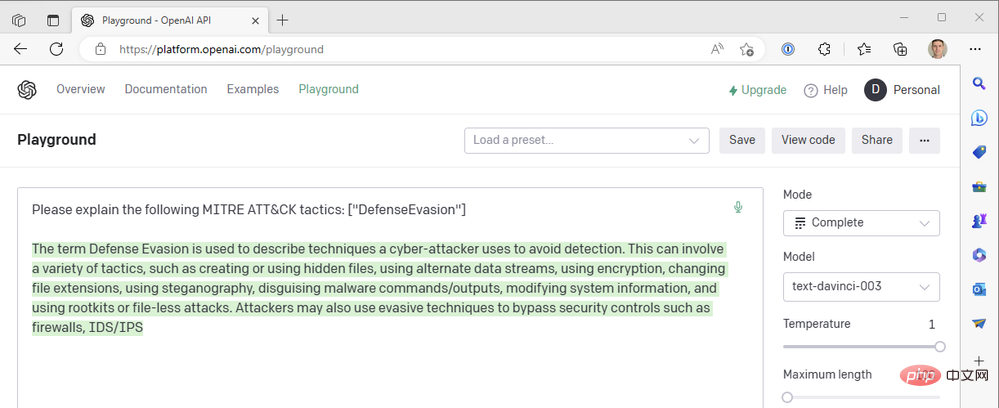
応答が文の途中で切り詰められているように見えるため、最大長パラメータを増やす必要があります。それ以外の場合、この応答はかなり良好に見えます。可能な限り最高の温度値を使用していますが、より確実な応答を得るために温度を下げるとどうなるでしょうか?例として温度 0 を考えます。
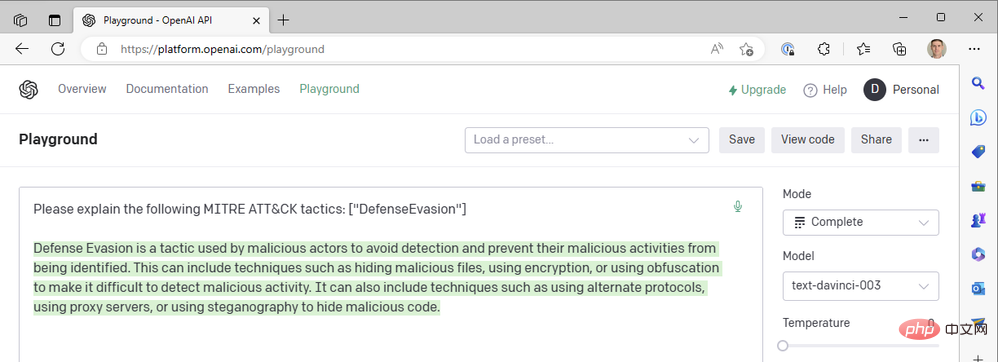
温度=0 では、このプロンプトを何回再生成しても、ほぼ同じ結果が得られます。これは、GPT3 に技術用語の定義を依頼するときにうまく機能します。MITRE ATT&CK 戦術としての「防御回避」の意味には大きな違いはないはずです。頻度ペナルティを追加して、モデルが同じ単語を再利用する傾向 (「技術的なもの」) を減らすことで、応答の可読性を向上させることができます。周波数ペナルティを最大 2 に増やしてみましょう:
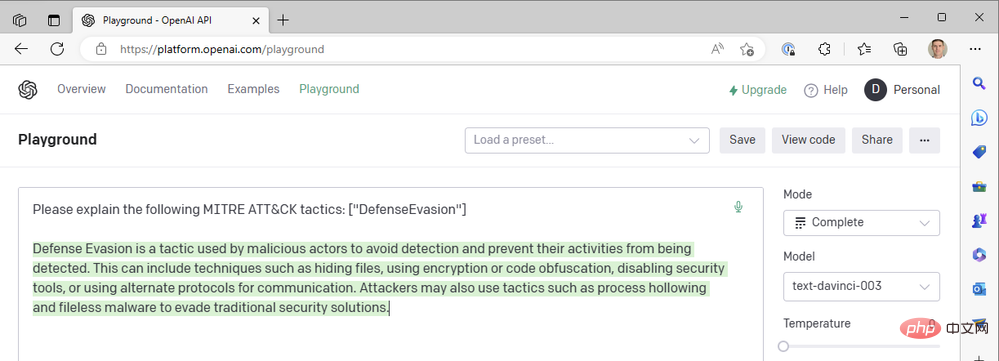
これまで、作業を迅速に行うために最新の da Vinci モデルのみを使用してきました。 OpenAI のより高速で安価なモデル (Curie、Babbage、Ada など) のいずれかにドロップダウンするとどうなるでしょうか?モデルを「text-ada-001」に変更して、結果を比較してみましょう。
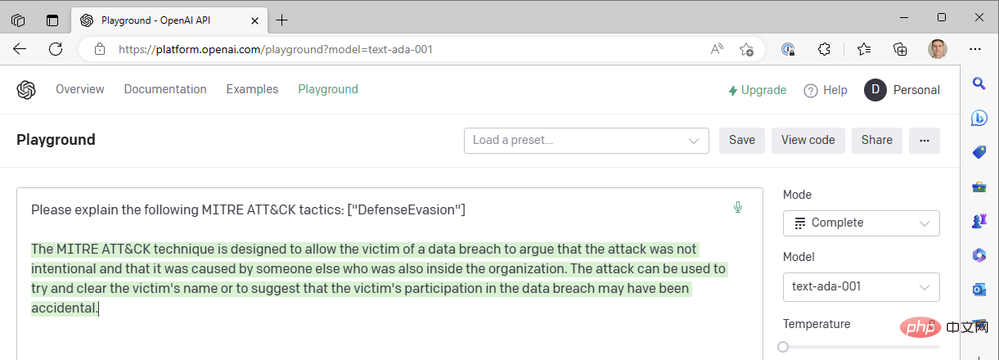
まあ... そうではありません。 Babbage を試してみましょう:
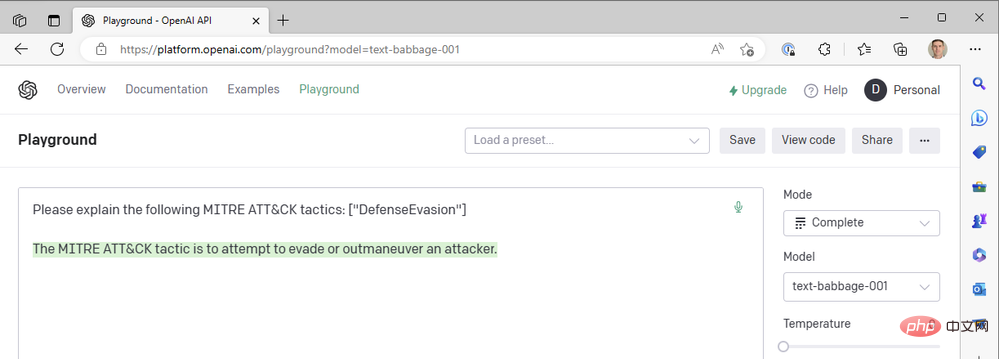
Babbage も、私たちが探している結果を返してくれないようです。もしかしたらキュリーの方が良かったのかな?
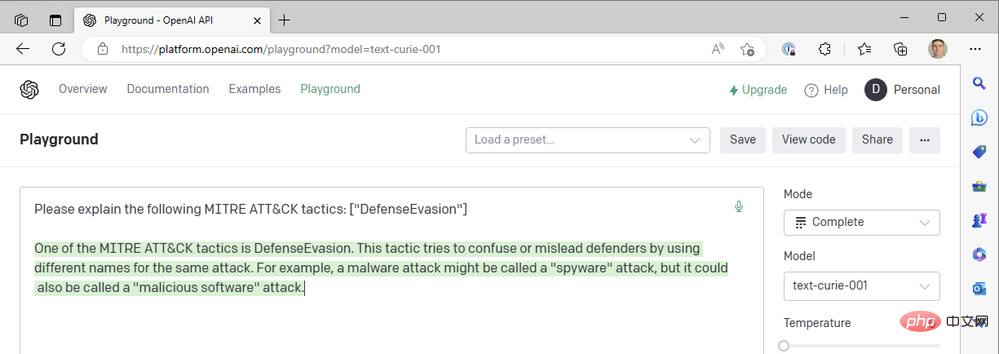
悲しいことに、キュリー夫人もレオナルド・ダ・ヴィンチが定めた基準を満たしていませんでした。確かに高速ですが、セキュリティ イベントにコンテキストを追加するユースケースでは、1 秒未満の応答時間に依存していません。概要の正確性の方が重要です。私たちは、ダ ヴィンチ モデル、低温および高周波罰の成功した組み合わせを引き続き使用します。
ロジック アプリに戻って、プレイグラウンドから検出した設定を OpenAI アクション ブロックに転送しましょう。
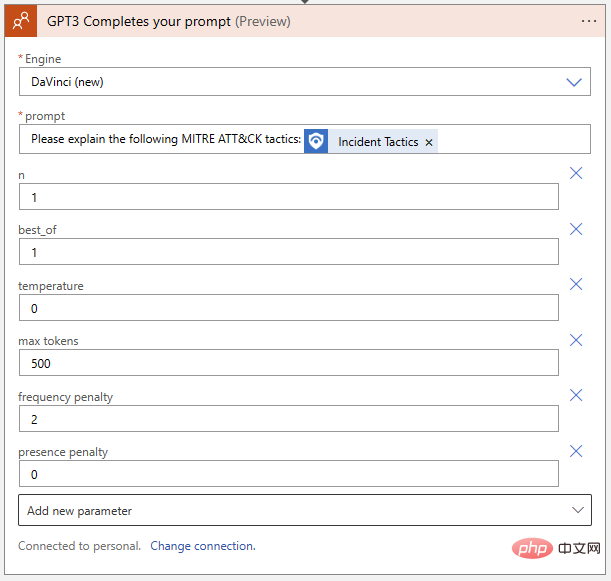
ロジック アプリも次のようにする必要があります。イベントのレビューを書くことができます。 [新しいステップ] をクリックし、Microsoft Sentinel コネクタから [イベントにコメントを追加] を選択します。
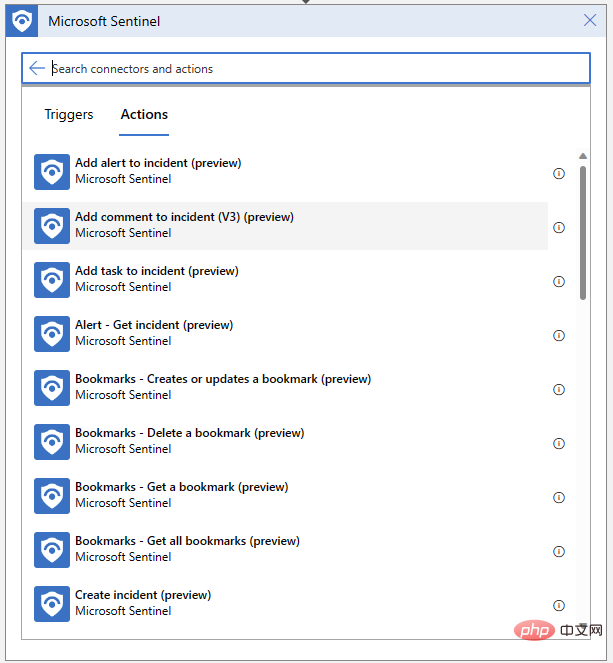
イベント ARM 識別子を指定し、コメント メッセージを作成するだけです。まず、動的コンテンツのポップアップ メニューで「Event ARM ID」を検索します。
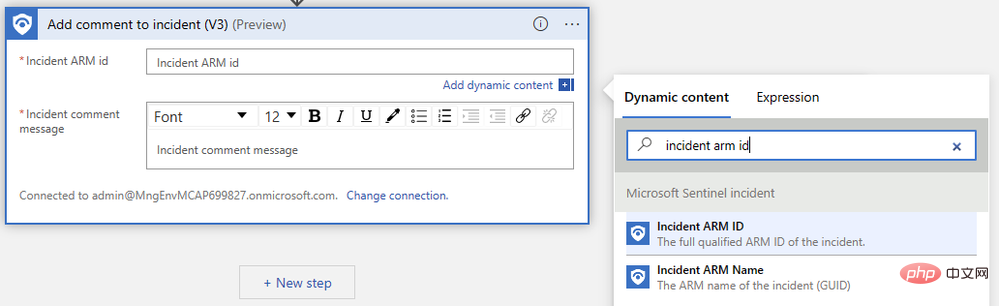
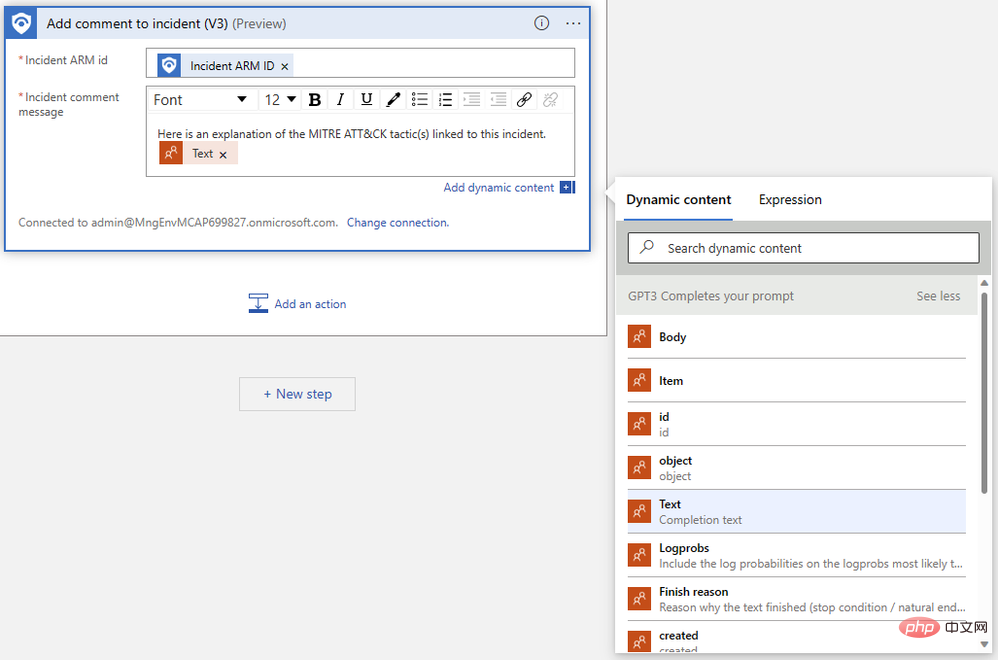
次に、前の手順で出力した「テキスト」を見つけます。出力を確認するには、「もっと見る」をクリックする必要がある場合があります。ロジック アプリ デザイナーは、同じプロンプトに対して複数の補完が生成される場合を処理するために、コメント アクションを "For each" ロジック ブロックに自動的にラップします。
完成したロジック アプリは次のようになります。
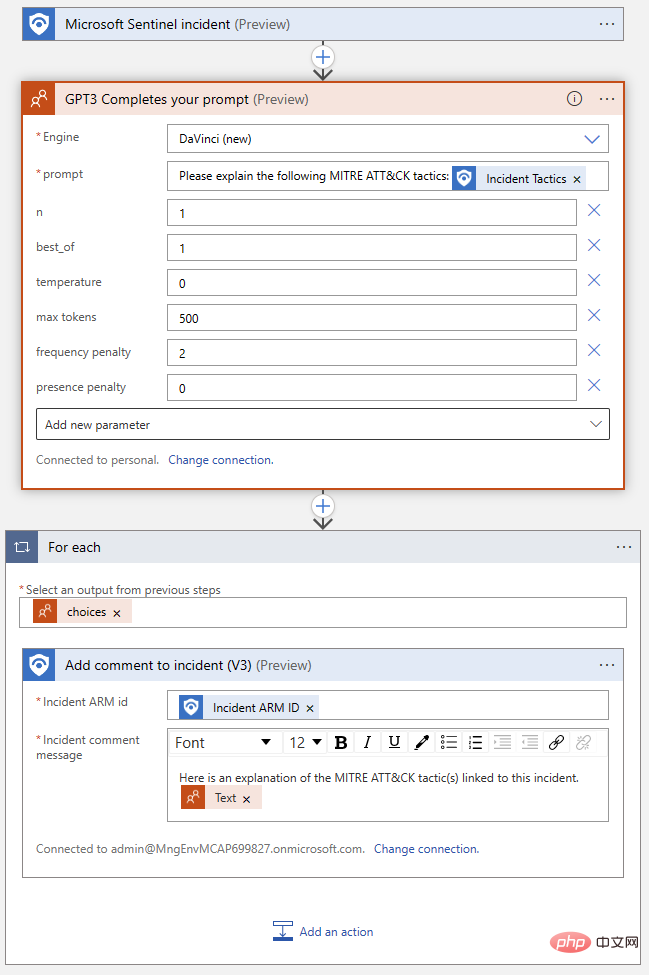
もう一度テストしてみましょう。その Microsoft Sentinel イベントに戻り、プレイブックを実行します。ロジック アプリの実行履歴に再び正常に完了し、イベント アクティビティ ログに新しいコメントが表示されるはずです。
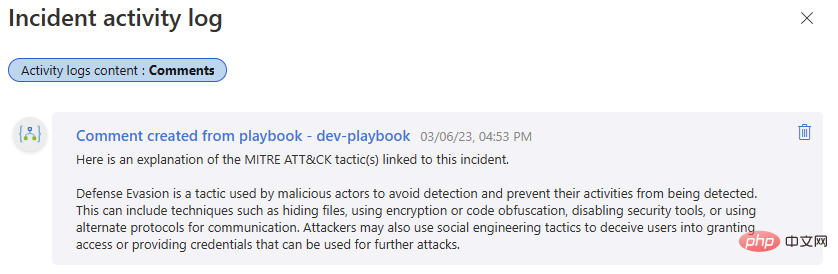
これまで当社と連絡を取り合ってきた方は、OpenAI GPT3 を Microsoft Sentinel と統合できるようになり、セキュリティ調査に価値を加えることができます。次回の記事もお楽しみに。そこでは、OpenAI モデルを Sentinel と統合し、セキュリティ プラットフォームを最大限に活用できるワークフローを解放するさらなる方法について説明します。
以上がOpenAI と Microsoft Sentinel の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。