
ホームページ >テクノロジー周辺機器 >AI >QTNet: 点群、画像、マルチモーダル検出器用の新しい時間融合ソリューション (NeurIPS 2023)
QTNet: 点群、画像、マルチモーダル検出器用の新しい時間融合ソリューション (NeurIPS 2023)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-12-15 12:21:311520ブラウズ
事前に書かれた個人的な理解
時系列融合は、自動運転の 3D ターゲット検出の知覚能力を向上させる効果的な方法ですが、現在の方法を応用するとコストがかかります。実際の自動運転シナリオやその他の問題。最新の研究記事「3D オブジェクト検出のためのクエリベースの明示的モーション タイミング フュージョン」では、NeurIPS 2023 で新しいタイミング フュージョン手法を提案しました。この手法は、スパース クエリをタイミング フュージョンの対象とし、明示的なモーション情報を使用してタイミング アテンション マトリックスを生成し、それに適応します。大規模点群の特徴。この方法は、華中科技大学と Baidu の研究者によって提案されたもので、QTNet と呼ばれています。クエリと明示的なモーションに基づいて 3D ターゲットを検出するための時間融合方法です。実験により、QTNet はほとんどコストをかけずに点群、画像、およびマルチモーダル検出器のパフォーマンスを一貫して向上させることができることが証明されました。

- 紙のリンク :https:/ /openreview.net/pdf?id=gySmwdmVDF
- コードリンク: https://github.com/AlmoonYsl/QTNet
問題の背景
現実世界の時間的連続性のおかげで、時間次元の情報により知覚情報がより完全になり、それによってターゲット検出の精度とロバスト性が向上します。たとえば、タイミング情報はターゲット検出の問題の解決に役立ちます。オクルージョン問題を解決し、ターゲットの動作ステータスと速度情報を提供し、ターゲットの永続性と一貫性情報を提供します。したがって、タイミング情報をいかに効率的に活用するかが自動運転の知覚において重要な課題となる。既存のタイミング融合手法は主に 2 つのカテゴリに分類されます。 1 つは高密度 BEV 特徴に基づく時系列融合 (点群/画像時系列融合に適用)、もう 1 つは 3D プロポーザル機能に基づく時系列融合 (主に点群時系列融合手法を対象) です。 BEV の特徴に基づく時間融合の場合、BEV 上のポイントの 90% 以上が背景であるため、このタイプの方法では前景のオブジェクトにあまり注意が払われず、その結果、多くの不必要な計算オーバーヘッドが発生し、最適なパフォーマンスが得られません。 3D プロポーザルに基づく時系列融合アルゴリズムの場合、時間のかかる 3D RoI プーリングを通じて 3D プロポーザル フィーチャを生成します。特にターゲットが多く、点群の数が多い場合、3D RoI プーリングによって生じるオーバーヘッドは実際には非常に高くなります。申請しても受理されにくい場合が多いです。さらに、3D プロポーザル機能はプロポーザルの品質に大きく依存しており、複雑なシーンではプロポーザルの品質が制限されることがよくあります。したがって、現在の方法では、時間的融合を効率的に導入して、非常に低いオーバーヘッドの方法で 3D ターゲット検出のパフォーマンスを向上させることは困難です。
効率的なタイミング融合を実現するにはどうすればよいでしょうか?
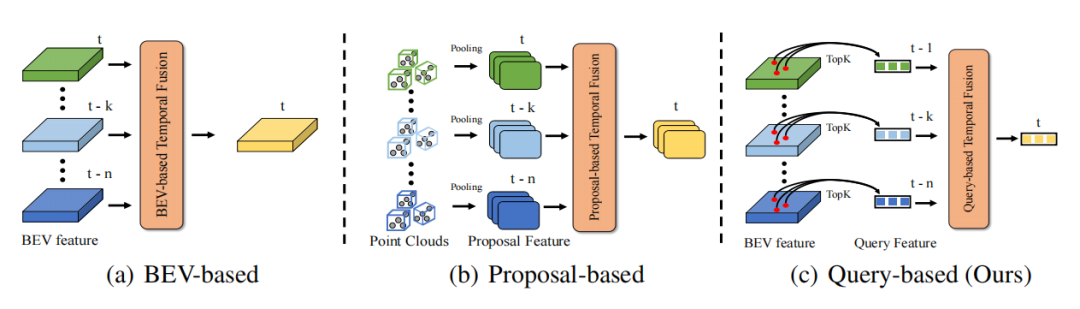
DETR は非常に優れたターゲット検出パラダイムであり、そのクエリ設計とセット予測のアイデアにより、後処理なしでエレガントな検出パラダイムを効果的に実現します。 DETR では、各クエリはオブジェクトを表し、クエリは密な特徴に比べて非常に疎です (通常、クエリの数は比較的小さい固定数に設定されます)。 Quey をタイミング融合の対象として使用すれば、計算オーバーヘッドの問題は当然低いレベルに下がります。したがって、DETR のクエリ パラダイムは、当然ながらタイミング融合に適したパラダイムです。時間的融合では、時間的コンテキスト情報の合成を達成するために、複数のフレーム間のオブジェクトの関連付けを構築する必要があります。したがって、主な問題は、クエリベースのタイミング フュージョン パイプラインを構築し、2 つのフレーム間のクエリ間の相関関係を確立する方法です。
- 実際のシーンでの自車の動きにより、2 つのフレームの点群/画像は座標系でずれていることが多く、実際のアプリケーションでは過去のすべてのフレームを比較することは不可能です現在のフレーム内でネットワークを再転送して、位置合わせされた点群/画像の特徴を抽出します。したがって、この記事では、計算の繰り返しを避けるために、メモリ バンクを使用して履歴フレームから取得したクエリ特徴とそれに対応する検出結果のみを保存します。
- 点群と画像はターゲット フィーチャの記述において大きく異なるため、フィーチャ レベルを通じて統一された時間融合手法を構築することは現実的ではありません。ただし、3 次元空間では、点群と画像モダリティの両方が、ターゲットの幾何学的位置と動き情報の関係を通じて、隣接するフレーム間の相関関係を表現できます。したがって、この論文では、オブジェクトの幾何学的位置と対応する動き情報を使用して、2 つのフレーム間のオブジェクトの注目行列をガイドします。
メソッドの紹介
QTNet の中心的なアイデアは、メモリ バンクを使用して、履歴フレームで取得されたクエリ特徴とそれに対応する検出結果を保存することです。重複を避ける 過去のフレームのコストを計算します。クエリの 2 つのフレーム間で、リレーションシップ モデリングにモーション ガイド付きアテンション マトリックスを使用します
#全体的なフレームワーク
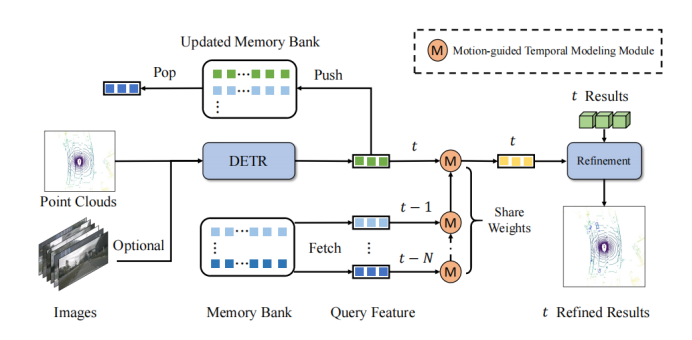
フレームワーク図に示されているように、QTNet には、3D DETR 構造を備えた 3D ターゲット検出器 (LiDAR、カメラ、マルチモーダルが利用可能)、メモリ バンク、およびタイミング融合のためのモーション ガイド付き時間モデリング モジュール (MTM) が含まれています。 。 QTNet は、DETR 構造の 3D ターゲット検出器を通じて、対応するフレームのクエリ特徴と検出結果を取得し、取得したクエリ特徴と検出結果を先入れ先出しキュー (FIFO) 方式でメモリ バンクに送信します。メモリ バンクの数は、タイミング フュージョンに必要なフレーム数に設定されます。タイミング融合の場合、QTNet は最も遠い時間から始めてメモリ バンクからデータを読み取り、MTM モジュールを使用してメモリ バンク内のすべての機能を フレームから フレームまで繰り返し融合します。現在のフレームのクエリ機能を強化し、強化されたクエリ機能に基づいて現在のフレームの対応する検出結果を調整します。
具体的には、QTNet は フレーム と フレームの フレームと フレームのクエリ機能を融合します。 フレームの拡張クエリ機能 を取得します。次に、QTNet は フレームと フレームのクエリ機能を融合します。このようにして、繰り返しを通じて フレームに継続的に統合されます。ここで使用される MTM は、 フレームから フレームまですべてパラメーターを共有していることに注意してください。
モーション ガイド付きアテンション モジュール
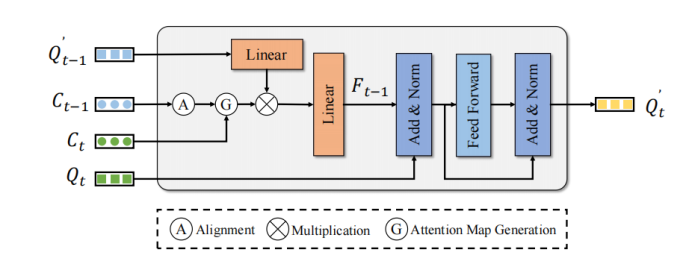
MTM は、オブジェクトの中心点の位置を使用して、明示的に フレームを生成しますクエリと フレーム クエリのアテンション マトリックス。エゴポーズ行列 と 、オブジェクトの中心点、および速度が与えられるとします。まず、MTM はエゴ ポーズとオブジェクト予測の速度情報を使用して、前のフレームのオブジェクトを次のフレームに移動し、2 つのフレームの座標系を揃えます。
次に、 # を渡します。 ##フレーム オブジェクトの中心点と フレームの修正された中心点は、ユークリッド コスト行列 を構築します。さらに、誤った一致の可能性を避けるために、この記事ではカテゴリ と距離しきい値 を使用してアテンション マスク :
Convert を構築します。コスト マトリックス 最終的な目標は、アテンション マトリックスを形成することです。アテンション マトリックスを フレーム の強化されたクエリ機能に適用して、集計します。強化する時間的特徴 フレームのクエリ特徴:
最終的に強化されたフレームのクエリ特徴 単純な FFN を通じて、対応する検出結果を洗練します検出性能の向上を実現します。
分離された時間融合構造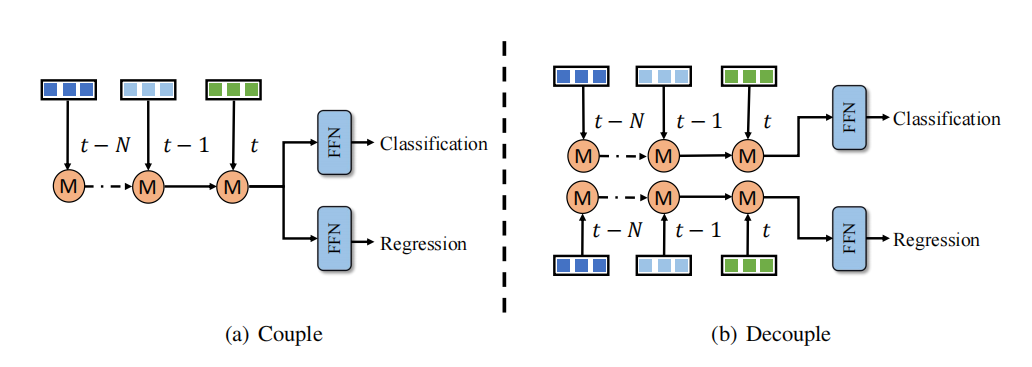 時間融合の分類と回帰学習に不均衡の問題があることが観察されています。ソリューション 時系列融合ブランチは、それぞれ分類と回帰のために設計されています。ただし、この分離アプローチでは、計算コストと待ち時間がさらに増加するため、ほとんどの方法では受け入れられません。対照的に、QTNet は効率的なタイミング フュージョン設計を利用しており、その計算コストと遅延は無視でき、3D 検出ネットワーク全体よりも優れたパフォーマンスを発揮します。したがって、この記事では、図
時間融合の分類と回帰学習に不均衡の問題があることが観察されています。ソリューション 時系列融合ブランチは、それぞれ分類と回帰のために設計されています。ただし、この分離アプローチでは、計算コストと待ち時間がさらに増加するため、ほとんどの方法では受け入れられません。対照的に、QTNet は効率的なタイミング フュージョン設計を利用しており、その計算コストと遅延は無視でき、3D 検出ネットワーク全体よりも優れたパフォーマンスを発揮します。したがって、この記事では、図
## に示すように、無視できるコストでより優れた検出パフォーマンスを達成するために、時系列融合における分類と回帰ブランチの分離方法を採用しています。 #QTNet は、点群/画像/マルチモダリティで一貫したポイント増加を実現します
nuScenes データセットの検証後、QTNet は将来の When 情報、TTA、およびモデルが統合され、68.4 の mAP と 72.2 の NDS が達成され、SOTA パフォーマンスが達成されます。未来情報を使用する MGTANet と比較すると、3 フレーム タイミング フュージョンの場合、QTNet は MGTANet よりも優れたパフォーマンスを示し、それぞれ mAP が 3.0、NDS が 1.0 増加します
さらに、この記事は、マルチモーダルおよびリング ビューベースの方法でも検証されており、nuScenes 検証セットの実験結果は、さまざまなモダリティにおける QTNet の有効性を証明しています。 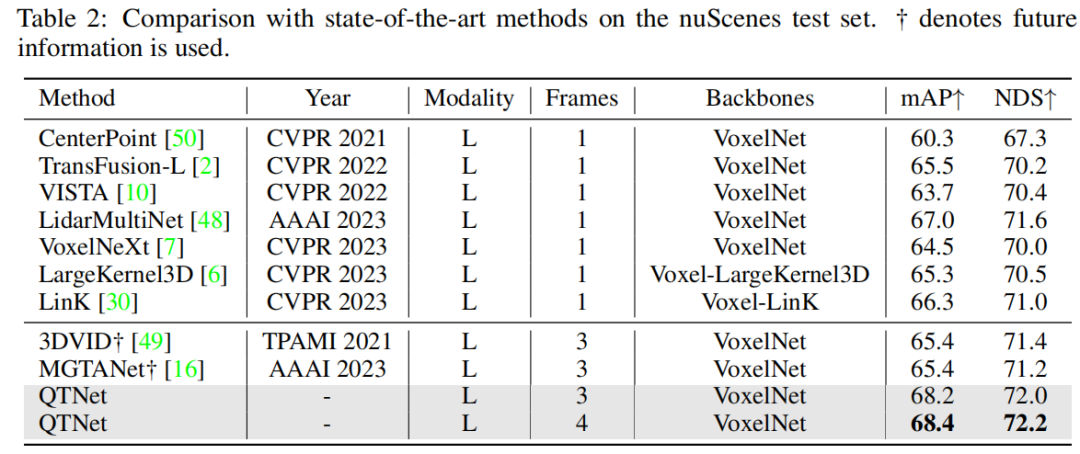
実際のアプリケーションでは、タイミング融合のコストのオーバーヘッドが非常に重要です。この記事では、QTNet について、計算量、遅延、パラメータ量の 3 つの側面から解析と実験を行います。結果は、ネットワーク全体と比較して、異なるベースラインによって引き起こされる QTNet の計算オーバーヘッド、時間遅延、パラメータ量が無視できるほど小さいことを示しています。特に計算量は 0.1G FLOP (LiDAR ベースライン) のみを使用します
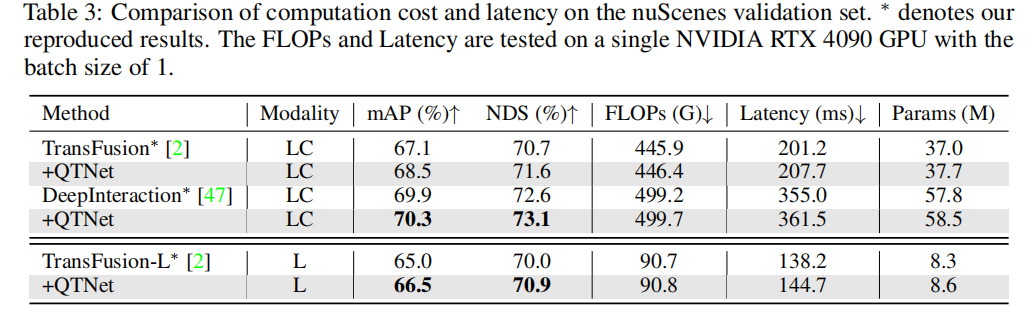
さまざまなタイミング融合パラダイムの比較
クエリベースのタイミング融合パラダイムの優位性を検証するために、さまざまな代表的なフロンティア タイミングを選択し、融合手法を比較しました。実験結果を通じて、クエリパラダイムに基づくタイミング融合アルゴリズムは、BEVおよび提案パラダイムに基づくものよりも効率的であることが判明した。 0.1G FLOP と 4.5ms オーバーヘッドのみを使用すると、QTNet はより優れたパフォーマンスを示しますが、パラメーター全体の量はわずか 0.3M
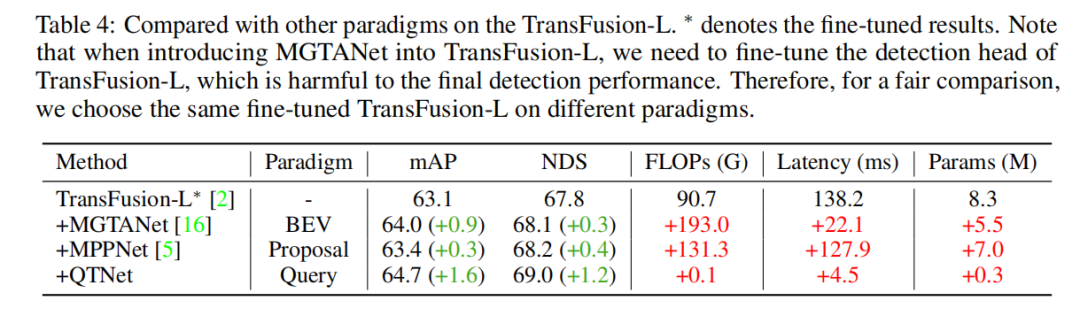
アブレーション実験
この研究では、nuScenes 検証セット上の LiDAR ベースラインに基づいて、3 フレームの時間融合によるアブレーション実験を実施しました。実験結果は、単にクロスアテンションを使用して時間的関係をモデル化しても明らかな効果がないことを示しています。ただし、MTM を使用すると、検出パフォーマンスが大幅に向上します。これは、大規模な点群における明示的なモーション ガイダンスの重要性を示しています。さらに、アブレーション実験を通じて、QTNet の全体的な設計が非常に軽量で効率的であることもわかりました。 4 フレームのデータをタイミング フュージョンに使用する場合、QTNet の計算量はわずか 0.24G FLOP、遅延はわずか 6.5 ミリ秒です。
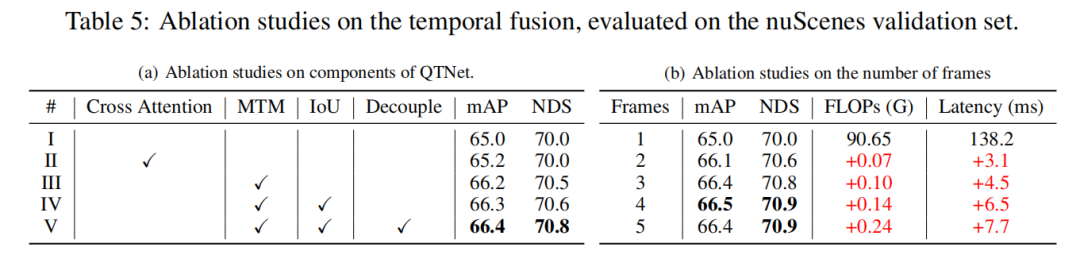
MTM の可視化
MTM がクロス アテンションよりも優れている理由を探るため、この記事では 2 つのフレーム間のオブジェクトのアテンション マトリックスを視覚化します。ここでは、2 つのフレーム間で同じ ID が同じオブジェクトを表します。 MTM によって生成された注意行列 (b) は、Cross Attend によって生成された注意行列 (a) よりも識別力が高いことがわかります。特に小さなオブジェクト間の注意行列がそうです。これは、明示的な動きによって誘導されるアテンション マトリックスにより、モデルが物理モデリングを通じて 2 つのフレーム間のオブジェクトの関連付けを確立しやすくなることを示しています。この記事では、タイミング フュージョンにおけるタイミング相関を物理的に確立する問題について簡単に説明するだけですが、タイミング相関をより適切に構築する方法を検討する価値は依然としてあります。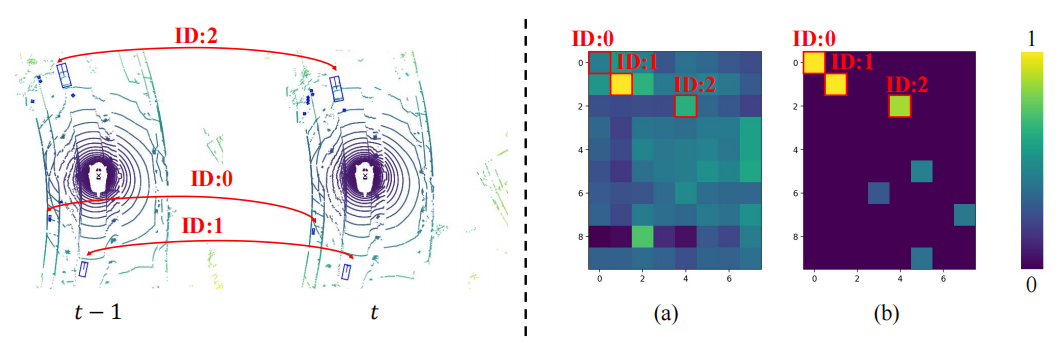
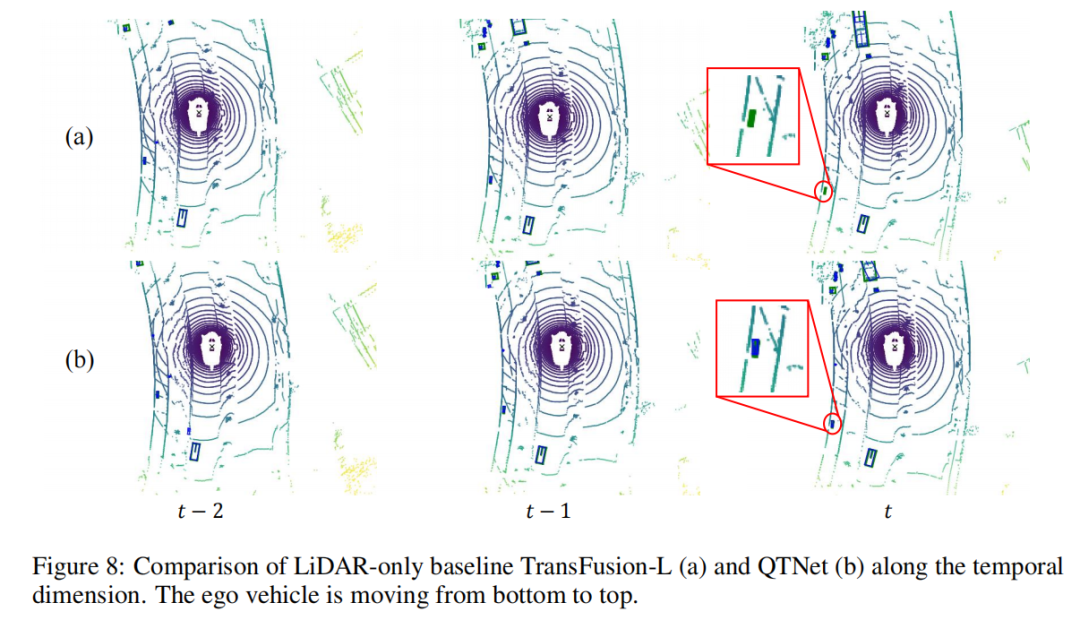
この記事では、シーンシーケンスを対象として、検出結果を視覚的に分析します。左下隅の小さなオブジェクトが、フレーム
から開始して車両から急速に遠ざかり、ベースラインがフレーム のオブジェクトを見逃していることがわかります。まだフレーム内で検出されます オブジェクトが検出されました。これは、時間融合における QTNet の有効性を証明しています。
 #この記事の概要
#この記事の概要
この記事では、現在の 3D ターゲット検出のための、より効率的なクエリベースの時間融合手法 QTNet を提案します。タスク。その主なコアには 2 つのポイントがあります: 1 つは時間融合のオブジェクトとしてスパース クエリを使用し、繰り返しの計算を避けるためにメモリ バンクを介して履歴情報を保存すること、もう 1 つは明示的なモーション モデリングを使用して時間クエリ間のアテンション マトリックスの生成をガイドすることです。 、時間関係モデリングを実現します。これら 2 つの重要なアイデアを通じて、QTNet は、LiDAR、カメラ、マルチモダリティに適用できるタイミング フュージョンを効率的に実装し、無視できるコストのオーバーヘッドで 3D ターゲット検出のパフォーマンスを一貫して向上させることができます。
書き直す必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/s9tkF_rAP2yUEkn6tp9eUQ
以上がQTNet: 点群、画像、マルチモーダル検出器用の新しい時間融合ソリューション (NeurIPS 2023)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。