
ホームページ >テクノロジー周辺機器 >AI >強力な基本エンジン CoDi-2 によるあらゆるテキスト、ビジュアル、オーディオ混合生成、マルチモーダル
強力な基本エンジン CoDi-2 によるあらゆるテキスト、ビジュアル、オーディオ混合生成、マルチモーダル

- PHPz転載
- 2023-12-04 12:39:58975ブラウズ
研究者らは、CoDi-2 は包括的なマルチモーダル基本モデルの開発分野における大きな進歩であると指摘しました
今年 5 月、Northカロライナ州チャペルヒル大学とマイクロソフトは、1 つのモデルで複数のモダリティを統合できるようにするコンポーザブル拡散 (CoDi) モデルを提案しました。 CoDi は、単一モーダル間の生成をサポートするだけでなく、複数の条件付き入力およびマルチモーダル結合生成を受け取ることもできます。
最近、カリフォルニア大学バークレー校、Microsoft Azure AI、Zoom、ノースカロライナ大学チャペルヒル校の多くの研究者が CoDi システムを CoDi-2 バージョンにアップグレードしました

論文アドレス: https://arxiv.org/pdf/2311.18775.pdf
プロジェクト アドレス: https://codi-2. github.io/

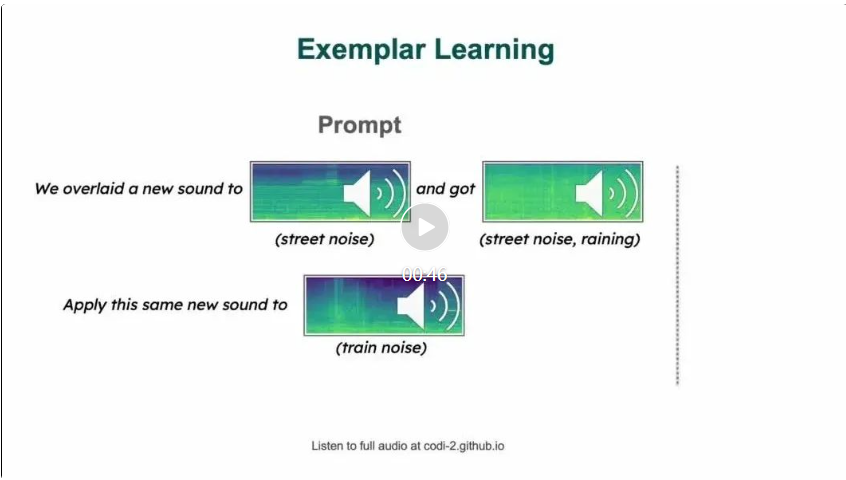
元の意味を変えずに内容を書き直します。中国語に書き直す必要があります。
Zineng Tang の論文によると、CoDi-2 は複雑なマルチモーダルにインターリーブされたコンテキスト命令に従い、あらゆるモダリティ (テキスト、ビジュアル、オーディオ) をゼロで生成します。 - または数ショットのインタラクション)

##このリンクは画像のソースです: https://twitter.com/ZinengTang/status/1730658941414371820
CoDi-2 は、多機能でインタラクティブなマルチモーダル大規模言語モデル (MLLM) として、状況に応じた学習、推論、チャット、および編集を実行できます。 to-any 入出力モーダル パラダイム。タスクを待ちます。 CoDi-2 は、エンコードと生成中にモダリティと言語を調整することにより、LLM が複雑なモーダル インターリーブ命令とコンテキスト例を理解できるだけでなく、連続特徴空間内で合理的で一貫したマルチモーダル出力を自己回帰的に生成できるようにします。 CoDi-2 をトレーニングするために、研究者らはテキスト、ビジュアル、オーディオにわたるコンテキストに応じたマルチモーダルな命令を含む大規模な生成データセットを構築しました。 CoDi-2 は、複数ラウンドのインタラクティブな対話を通じた、コンテキスト学習、推論、任意対任意のモーダル生成の組み合わせなど、マルチモーダル生成のための一連のゼロショット機能を実証します。中でも、トピック主導の画像生成、ビジュアル変換、オーディオ編集などのタスクにおいて、以前のドメイン固有モデルを上回っています。
人間と CoDi-2 の間の複数ラウンドの対話により、画像編集のための状況に応じたマルチモーダルな指示が提供されます。
書き直す必要があるのは次のとおりです: モデル アーキテクチャ
CoDi-2 は、コンテキスト内のテキスト、画像、音声やその他のマルチを処理するように設計されています。 - モーダル入力。特定の命令を使用して状況に応じた学習を促進し、対応するテキスト、画像、音声出力を生成します。 CoDi-2 用に書き直す必要があるのは次のとおりです。 モデルのアーキテクチャ図は次のとおりです。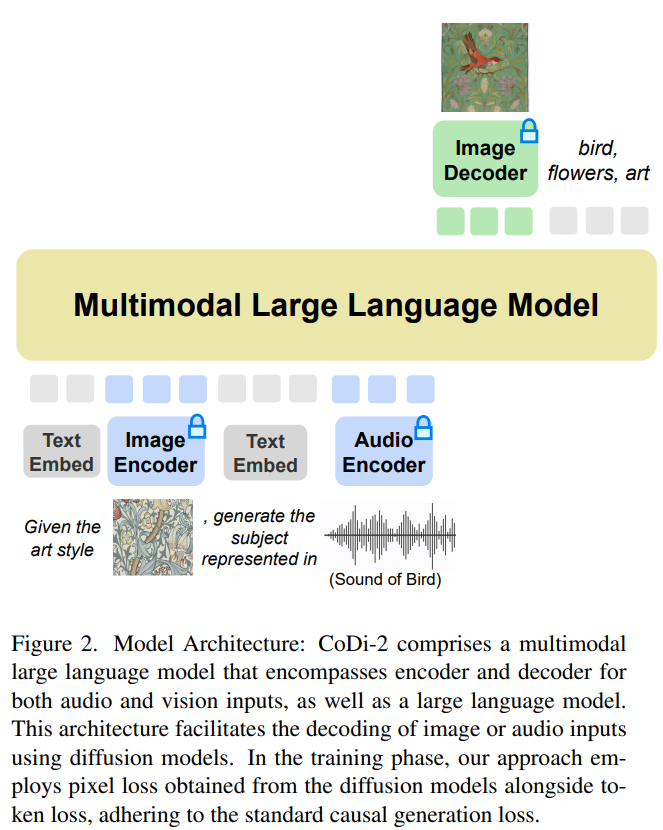
マルチモーダル大規模言語モデルを基本エンジンとして使用する
この任意対任意の基本モデルは、インターリーブされたモーダルを消化できます入力、複雑な指示 (マルチターン会話、コンテキスト例など) についての理解と推論、およびマルチモーダル ディフューザーとの対話には、強力な基本エンジンが必要です。研究者らは、テキストのみの LLM にマルチモーダルな認識を提供するために構築された MLLM をこのエンジンとして提案しました。 調整されたマルチモーダル エンコーダ マッピングを使用することで、研究者はモーダルにインターリーブされた入力シーケンスを LLM にシームレスに認識させることができます。具体的には、マルチモーダル入力シーケンスを処理する場合、まずマルチモーダル エンコーダーを使用してマルチモーダル データを特徴シーケンスにマッピングし、次に「以上が強力な基本エンジン CoDi-2 によるあらゆるテキスト、ビジュアル、オーディオ混合生成、マルチモーダルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連記事
続きを見る- テクノロジーでファッション業界に力を与え、福田区の「ベイエリア ファッション ヘッドクォーター センター」の建設を支援する
- Luxshare Precision: 人型ロボットなどの新興産業に参入するための成熟した能力とビジネス基盤を備えています
- 工業情報化部は「ブレイン・コンピューター・インターフェース産業の発展を加速する」と発表した。
- 我が国のコンピューティング産業の規模は2兆6000億元に達し、過去6年間に2091万台以上の汎用サーバーと82万台以上のAIサーバーが出荷された。
- 2023 年人工知能コンピューティング カンファレンス AICC が北京で開催され、大規模モデルとインテリジェント コンピューティング能力に関する業界の熱い議論に焦点が当てられました