



人工知能分野の最新の傾向では、人工的に生成されたプロンプトの品質が大規模言語モデル (LLM) の応答精度に決定的な影響を与えます。 OpenAI は、これらの大規模な言語モデルのパフォーマンスには、正確で詳細かつ具体的な質問が重要であると提案しています。しかし、一般ユーザーは自分の質問が LLM にとって十分に明確であることを保証できるでしょうか?
書き直す必要がある内容は次のとおりです。特定の状況における人間の自然な理解と機械の解釈との間には大きな違いがあることは注目に値します。たとえば、「偶数月」という概念は人間にとって明らかに 2 月や 4 月などの月を指しますが、GPT-4 はそれを偶数日の月と誤解する可能性があります。これは、日常のコンテキストを理解する際の人工知能の限界を明らかにするだけでなく、これらの大規模な言語モデルとより効果的にコミュニケーションする方法について熟考するよう促します。人工知能技術の継続的な進歩に伴い、人間と機械の間の言語理解のギャップをどのように埋めるかは、今後の研究の重要なテーマです。
# この件について、カリフォルニア大学ロサンゼルス校は次のように述べています。アンヘレス (UCLA) の一般人工知能研究所 (Gu Quanquan 教授率いる) は、大規模な言語モデル (GPT-4 など) の問題理解における曖昧さの問題に対する革新的な解決策を提案する研究レポートを発表しました。この研究は、博士課程の学生であるDeng Yihe、Zhang Weitong、Chen Zixiangによって完了しました
- ##論文アドレス: https://arxiv.org/pdf/2311.04205.pdf
- プロジェクトアドレス: https://uclaml.github.io/Rephrase-and -応答
書き直された中国語のコンテンツは次のとおりです。 このソリューションの核心は、大規模な言語モデルに質問を繰り返し拡張させて、回答の精度を向上させることです。研究の結果、GPT-4 によって再定式化された質問はより詳細になり、質問形式がより明確になったことがわかりました。この再表現と拡張の方法により、モデルの応答精度が大幅に向上します。実験によれば、十分にリハーサルを行った質問は、回答の精度が 50% から 100% 近くまで向上します。このパフォーマンスの向上は、大規模な言語モデル自体が改善される可能性を実証するだけでなく、人工知能が人間の言語をより効果的に処理し理解する方法についての新しい視点も提供します。
方法
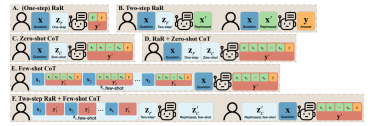
上記の調査結果に基づいて、研究者らは、「質問を言い換えて展開し、応答する」(略して RaR) というシンプルだが効果的なプロンプトを提案しました。このプロンプトワードは、質問に対する LLM の回答の質を直接的に向上させ、問題処理における重要な改善を示しています。

研究チームは、GPT-4 などを最大限に活用するために、「Two-step RaR」と呼ばれる RaR の亜種も提案しました。大きなモデルを使って問題を再現します。このアプローチは 2 つのステップに従います: 第 1 に、特定の質問に対して、特殊な言い換え LLM を使用して言い換え質問を生成します。第 2 に、元の質問と言い換え質問を組み合わせて、応答 LLM に回答を求めるために使用します。

結果
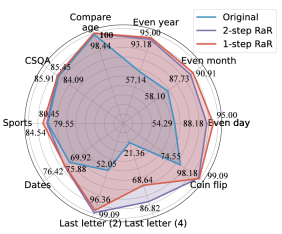
研究者らはさまざまなタスクを実施しました。結果は、シングルステップ RaR または 2 ステップ RaR のいずれかが GPT4 の解答精度を効果的に向上できることを示しています。特に、RaR は、GPT-4 では困難だったタスクで大幅な改善を示し、場合によっては 100% の精度に近づくことさえあります。研究チームは、次の 2 つの重要な結論を要約しました:
1. Restate and Extend (RaR) は、プラグアンドプレイのブラックボックス プロンプト手法を提供し、システム上の LLM パフォーマンスを効果的に向上させることができます。さまざまなタスク。
2. 質問応答 (QA) タスクで LLM のパフォーマンスを評価する場合、質問の品質をチェックすることが重要です。

研究者らは、2 ステップ RaR 法を使用して、GPT-4、GPT-3.5、Vicuna-13b-v.15 などのさまざまなモデルのパフォーマンスを調査する研究を実施しました。実験結果は、GPT-4 など、より複雑なアーキテクチャと強力な処理能力を備えたモデルの場合、RaR 手法により処理問題の精度と効率が大幅に向上できることを示しています。 Vicuna などのより単純なモデルの場合、改善は小さくなりますが、それでも RaR 戦略の有効性が示されています。これに基づいて、研究者たちは、さまざまなモデルを再話した後、質問の質をさらに調査しました。小規模なモデルに対する言い換え質問は、質問の意図を混乱させる可能性があります。また、GPT-4 のような高度なモデルは、人間の意図に一致する言い換え質問を提供し、他のモデルの回答を強化することができます

この調査結果により、重要な現象が明らかになります。言語モデルの異なるレベルによって練習される質問の質と有効性には違いがあります。特に GPT-4 のような高度なモデルの場合、再説明された問題は、問題をより明確に理解できるだけでなく、他の小規模なモデルのパフォーマンスを向上させるための効果的なインプットとしても機能します。
思考連鎖 (CoT) との違い
RaR と思考連鎖 (CoT) の違いを理解するために、研究者たちは数学的手法を提案しました。 RaR が CoT と数学的にどのように異なるのか、またそれらをどのように簡単に組み合わせることができるのかを説明します。
モデルの推論機能を強化する方法を詳しく検討する前に、この研究では、モデルの推論を確実に行うために質問の質を向上させる必要があることを指摘しています。能力を適切に評価できます。例えば、「コイン投げ」問題では、GPT-4は「投げる」を人間の意図とは異なるランダムな投げ動作として理解していることが判明した。 「ステップごとに考えてみましょう」という言葉でモデルを推論したとしても、この誤解は推論の過程で残ります。質問を明確にして初めて、大規模な言語モデルが意図した質問に答えました

さらに、研究者たちは、質問のテキストに加えて、Q&A が含まれていることにも気づきました。少数ショット CoT のサンプルも人間によって作成されます。このため、人工的に構築されたサンプルに欠陥がある場合、大規模言語モデル (LLM) はどのように反応するのかという疑問が生じます。この研究は興味深い例を提供し、貧弱な数ショットの CoT 例が LLM に悪影響を与える可能性があることを発見しました。 「最終文字結合」タスクを例にとると、以前に使用した問題例は、モデルのパフォーマンスの向上にプラスの効果を示しました。ただし、最後の文字の検索から最初の文字の検索など、プロンプト ロジックが変更されると、GPT-4 は間違った答えを返しました。この現象は、人為的な例に対するモデルの敏感さを浮き彫りにします。

研究者らは、RaR を使用すると、GPT-4 が特定の例の論理的欠陥を修正できるため、少数ショット CoT の品質とパフォーマンスが向上することを発見しました。堅牢性
結論
人間と大規模言語モデル (LLM) との間のコミュニケーションは誤解される可能性があります: 人間にとっては明らかな問題でも、他の問題は誤解される可能性があります大規模な言語モデルで理解できるようになります。 UCLA の研究チームは、LLM に質問に答える前に質問を言い換えて明確にする新しい方法である RaR を提案することでこの問題を解決しました。
RaR の有効性は、実行された多くの実験評価で実証されています。いくつかのベンチマーク データセットでの効果が確認されています。さらに分析した結果、問題を再記述することで問題の品質を向上させることができ、この改善効果は異なるモデル間で移行できることがわかりました。
将来の展望としては、RaR と同様のことが期待されます。手法は今後も改善され、CoT などの他の手法との統合により、人間と大規模な言語モデルの間の対話により正確かつ効率的な方法が提供され、最終的には AI の説明と推論能力の境界が拡大されます。
以上が大規模な AI モデルに自律的に質問させる: GPT-4 は人間と会話する際の障壁を打ち破り、より高いレベルのパフォーマンスを実証しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム
 AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM
AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM主要なエンタープライズ分析プラットフォームAlteryxのCEOであるAndy Macmillanとの私の最近の会話は、AI革命におけるこの重要でありながら過小評価されている役割を強調しました。 MacMillanが説明するように、生のビジネスデータとAI-Ready情報のギャップ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

WebStorm Mac版
便利なJavaScript開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

メモ帳++7.3.1
使いやすく無料のコードエディター

