
ホームページ >テクノロジー周辺機器 >AI >大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ
大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ

- 王林転載
- 2023-10-07 12:13:011762ブラウズ
2018 年、Google は BERT をリリースしました。リリースされると、11 個の NLP タスクの最先端 (Sota) の結果を一気に打ち破り、NLP の世界における新たなマイルストーンとなりました; BERT の構造は次の図に示されています。左側は BERT モデルの事前トレーニング プロセス、右側は特定のタスクの微調整プロセスです。このうち、微調整段階は、テキスト分類、品詞タグ付け、質疑応答システムなどの下流タスクで使用される際に微調整するためのものです。BERT は以下の点で微調整できます。構造を調整せずにさまざまなタスクを実行できます。 「言語モデルの事前トレーニングと下流タスクの微調整」というタスク設計を通じて、強力なモデル効果をもたらしました。それ以来、「事前トレーニング言語モデルと下流タスクの微調整」が、NLP の分野における主流のトレーニング パラダイムになりました。
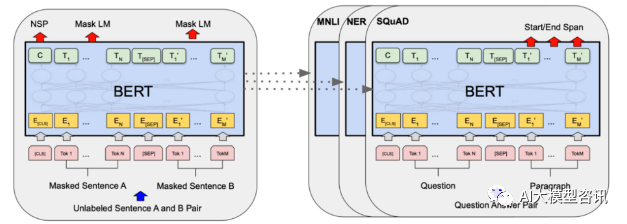 BERT 構造図、左側は事前トレーニング プロセス、右側は特定のタスクの微調整プロセス
BERT 構造図、左側は事前トレーニング プロセス、右側は特定のタスクの微調整プロセス
しかし、GPT3 に代表される大規模アーキテクチャの登場により、大規模言語モデル (LLM) のパラメータ サイズが増大するにつれて、コンシューマ グレードのハードウェア上での完全な微調整は不可能になってきました。次の表は、A100 GPU (80G ビデオ メモリ) および 64GB 以上の CPU メモリを備えたハードウェアでのフルモデルの微調整とパラメータ効率の良い微調整の CPU/GPU メモリ消費量を示しています。
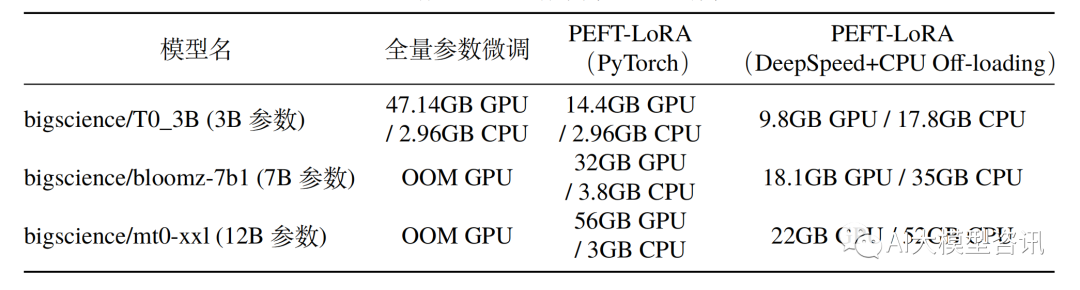 パラメータ微調整とパラメータ効率的な微調整の間のメモリ使用量の完全な比較
パラメータ微調整とパラメータ効率的な微調整の間のメモリ使用量の完全な比較
さらに、モデルの包括的な微調整は、多様性の喪失と深刻な忘却の問題にもつながります。 。したがって、モデルの微調整を効率的に実行する方法が業界研究の焦点となっており、効率的なパラメータ微調整技術を迅速に開発するための研究スペースも提供されています。
効率的なパラメータ微調整とは、微調整を指します。少量または追加のモデル パラメーターと、固定された大規模な部分事前トレーニング モデル (LLM) パラメーターを使用することで、コンピューティングとストレージのコストを大幅に削減しながら、パラメーターの完全な微調整に匹敵するパフォーマンスを実現します。パラメーターの効率的な微調整方法は、場合によっては完全な微調整よりも優れており、ドメイン外のシナリオによく一般化できます。
効率的な微調整技術は、下図に示すように、パラメータの追加 (A)、更新するパラメータの一部を選択する (S)、高度なパラメータ化の導入の 3 つのカテゴリに大別できます。 (R)。パラメータを追加する方法のうち、それらは主に、アダプタのような方法とソフト プロンプトの 2 つのサブカテゴリに分類されます。
共通パラメータの効率的な微調整テクノロジーには、BitFit、プレフィックス チューニング、プロンプト チューニング、P-チューニング、アダプター チューニング、LoRA などが含まれます。次の章では、主流の効率的なパラメータ微調整方法について詳しく説明します
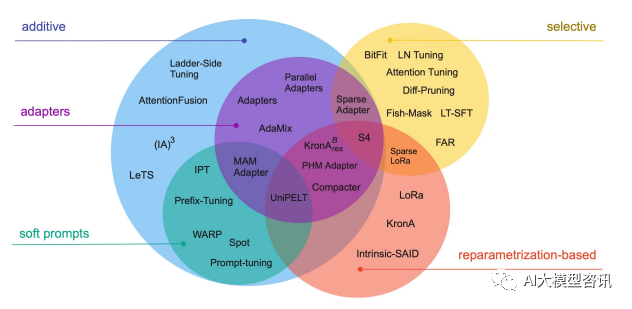 #一般的なパラメータの効率的な微調整テクノロジと方法
#一般的なパラメータの効率的な微調整テクノロジと方法
BitFit
各タスクの完全な微調整は非常に効果的ですが、独自に大規模なモデルも生成されます。そのため、微調整中にどのような変更が発生したかを推測することが難しく、展開も難しく、特にタスクの数が増えると維持するのが難しくなります。
理想的には、次の条件を満たす効率的な微調整方法があればよいと考えています。
上記の問題は、微調整プロセスが新しい学習をどの程度導くことができるかによって異なります。能力と事前訓練LM中等学校の能力への露出。ただし、以前の効率的な微調整方法であるアダプター チューニングと差分プルーニングでも、上記のニーズを部分的に満たすことができます。 BitFit は、より小さいパラメーターを使用したスパースな微調整メソッドであり、上記のニーズをすべて満たすことができます。
BitFit は、トレーニング中にバイアス パラメーターまたはバイアス パラメーターの一部のみを更新するスパース微調整メソッドです。 Transformer モデルの場合、ほとんどのトランスフォーマー エンコーダー パラメーターが固定され、特定のタスクのバイアス パラメーターと分類層パラメーターのみが更新されます。関連するバイアス パラメーターには、クエリ、キー、値の計算、およびアテンション モジュールでの複数のアテンション結果のマージに関連するバイアス、MLP レイヤーのバイアス、レイヤー正規化レイヤーのバイアス パラメーター、および事前トレーニング モデルのバイアス パラメーターが含まれます。下図に示すように。
図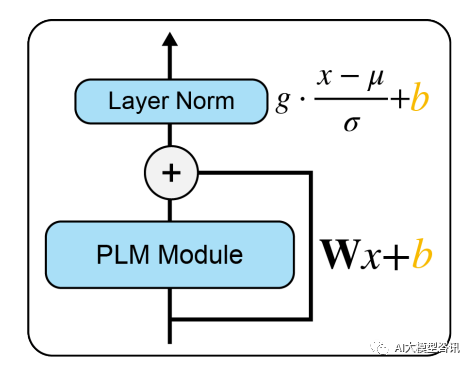
Bert-Base/Bert-Large などのモデルでは、バイアス パラメーターはモデルの全パラメーターの 0.08% ~ 0.09% しか占めません。しかし、GLUE データセットに基づく Bert-Large モデルに対する BitFit、アダプター、および Diff-Pruning の効果を比較すると、パラメーターの数がはるかに少ない場合、BitFit はアダプターおよび Diff-Pruning と同じ効果があることがわかりました。アダプターと差分プルーニングよりも、タスクによってはアダプターと差分プルーニングよりわずかに優れています。 実験結果からわかるように、すべてのパラメーターの微調整と比較して、BitFit の微調整結果では非常に少数のパラメーターのみが更新され、複数のデータ セットで良好な結果が得られました。すべてのパラメーターを微調整するほどではありませんが、すべてのモデル パラメーターを固定する Frozen 方法よりははるかに優れています。同時に、BitFit トレーニングの前後でパラメーターを比較すると、キーの計算に関連するバイアス パラメーターなど、多くのバイアス パラメーターがあまり変化していないことがわかりました。クエリを計算し、特徴次元を N から 4N に拡大する FFN 層のバイアス パラメーターが最も顕著な変化を示していることがわかり、これら 2 種類のバイアス パラメーターを更新するだけでも良好な結果が得られます。逆に、これらのいずれかが修正されると、モデルの効果は大きく失われます。 プレフィックス チューニング以前の作業は、主に個別のテンプレートを手動で設計するか、自動的に設計することでした。個別のテンプレートを検索します。手動でデザインされたテンプレートの場合、テンプレートの変更はモデルの最終的なパフォーマンスに特に影響を及ぼします。単語の追加、単語の欠落、または位置の変更は、比較的大きな変更を引き起こします。自動検索テンプレートの場合、コストが比較的高くなりますが、同時に、以前の個別トークン検索の結果が最適ではない可能性があります。さらに、従来の微調整パラダイムでは、事前トレーニングされたモデルを使用してさまざまな下流タスクを微調整するため、微調整されたモデルの重みをタスクごとに保存する必要があります。時間はかかりますが、その一方で、多くの保管スペースも必要になります。上記の 2 つの点に基づいて、Prefix Tuning は固定の事前トレーニング LM を提案します。LM にトレーニング可能なタスク固有のプレフィックスを追加することで、タスクごとに異なるプレフィックスを保存でき、微調整コストも小さくなります。 ; 同時に、この種のプレフィックスは実際には連続微分可能な仮想トークン (ソフト プロンプト/連続プロンプト) が最適化されており、離散トークンよりも優れた効果を発揮します。 つまり、書き直す必要があるのは、「プレフィックスの意味は何ですか?」ということです。プレフィックスの役割は、y をより適切に生成できるように、x に関連する情報を抽出するようにモデルをガイドすることです。たとえば、要約タスクを実行したい場合、微調整後、prefix は現在実行していることが「要約フォーム」タスクであることを理解し、x から重要な情報を抽出するようにモデルを誘導できます。感情分類タスクを実行するには、プレフィックスを使用して、x 内の感情に関連する意味情報を抽出するようにモデルをガイドできます。あまり厳密な説明ではないかもしれませんが、プレフィックスの役割は大体理解できると思います。 プレフィックスチューニングとは、トークンを入力する前にタスクに関連する仮想トークンをプレフィックスとして構築し、そのプレフィックスのパラメータのみを更新することです。トレーニング中の部分ですが、PLM の他のパラメーターは固定されています。モデル構造が異なる場合は、異なるプレフィックスを構築する必要があります: 元の意味を変えずにコンテンツを書き直し、中国語で書き直します。
前の部分の微調整では、すべての Transformer パラメーター (赤いボックス) を更新し、タスクごとにモデルの完全なコピーを保存する必要があります。下部のプレフィックス調整は、Transformer パラメータをフリーズし、プレフィックス (赤いボックス) のみを最適化します。 このメソッドは、プロンプトが人為的に構築された「明示的な」プロンプトであることを除いて、プロンプトの構築と実際には似ています。また、パラメータは更新できませんが、プレフィックス は学習可能な「暗黙の」ヒントです。同時に、Prefix のパラメータを直接更新することによるトレーニングの不安定化やパフォーマンスの低下を防ぐために、Prefix 層の前に MLP 構造を追加し、トレーニング完了後は Prefix のパラメータのみを保持します。また、アブレーション実験により、埋め込み層のみの調整では十分な表現力が得られず、大幅なパフォーマンス低下につながることが判明しているため、各層にプロンプトパラメータを追加し、比較的大きな変更を加えています。 プレフィックス チューニングは便利に見えますが、次の 2 つの重大な欠点もあります。 大規模なモデルを完全に微調整するには、タスクごとにモデルをトレーニングする必要があり、オーバーヘッドと展開コストが比較的高くなります。同時に、個別プロンプト (手動でプロンプトを設計し、モデルにプロンプトを追加することを指します) 方法は比較的高価であり、効果はあまり良くありません。プロンプト チューニングは、プロンプトを手動で設計する代わりに、更新されたパラメーターを逆伝播することによってプロンプトを学習します。同時に、モデルの元の重みを固定し、プロンプト パラメーターのみをトレーニングします。トレーニング後は、同じモデルをマルチタスク推論に使用できます。 モデルのチューニングでは、各タスクの事前トレーニング済みモデル全体のタスク固有のコピーを作成する必要があります。下流のタスクと推論は、別々のバッチで。プロンプト チューニングでは、タスクごとに小さなタスク固有のプロンプトを保存するだけで済み、元の事前トレーニング済みモデルを使用した混合タスク推論が可能になります。 プロンプト チューニングは、プレフィックス チューニングの簡易バージョンと見なすことができます。タスクごとに独自のプロンプトを定義し、それを入力としてデータに結合しますが、入力層にプロンプト トークンを追加するだけです。困難なトレーニング問題を解決するために、調整のために MLP を追加する必要はありません。 実験を通じて、事前トレーニングされたモデルのパラメーターの数が増加するにつれて、プロンプト チューニング方法は完全なパラメーター微調整の結果に近づくことが判明しました。同時に、プロンプト チューニングは、同じタスクに対して異なるプロンプトをバッチで同時にトレーニングする (つまり、同じ質問を複数の異なる方法で行う) ことを意味するプロンプト アンサンブルも提案しました。これは、異なるモデルをトレーニングすることに相当します。たとえば、モデル統合のコストははるかに小さくなります。さらに、プロンプト チューニングのペーパーでは、初期化方法とプロンプト トークンの長さがモデルのパフォーマンスに与える影響についても説明しています。アブレーション実験の結果から、プロンプト チューニングはクラス ラベルを使用して、ランダム初期化やサンプル語彙を使用した初期化よりも適切にモデルを初期化することがわかりました。ただし、モデル パラメーターのスケールが増加すると、このギャップは最終的にはなくなります。プロンプト トークンの長さが 20 程度であれば、すでにパフォーマンスは良好です (20 を超えると、プロンプト トークンの長さを増やしてもモデルのパフォーマンスが大幅に向上することはありません)。同様に、モデル パラメーターのスケールが大きくなるにつれて、このギャップも減少します。 (つまり、非常に大規模なモデルの場合、プロンプト トークンの長さが非常に短くても、パフォーマンスに大きな影響はありません)。 プレフィックス チューニング
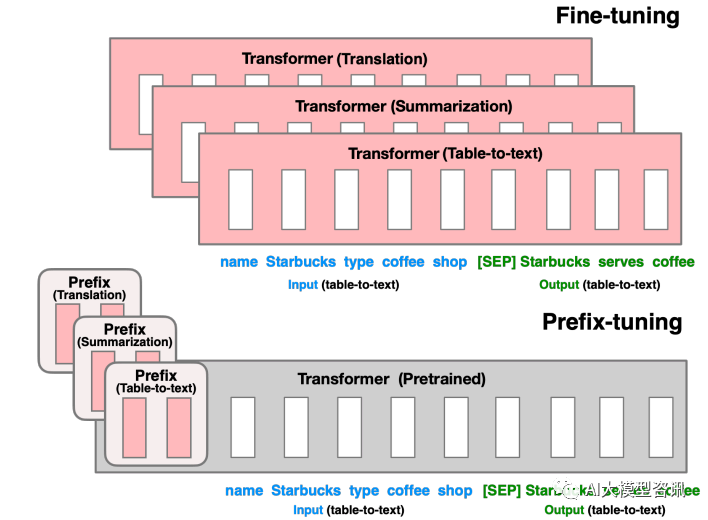 図
図プロンプトチューニング
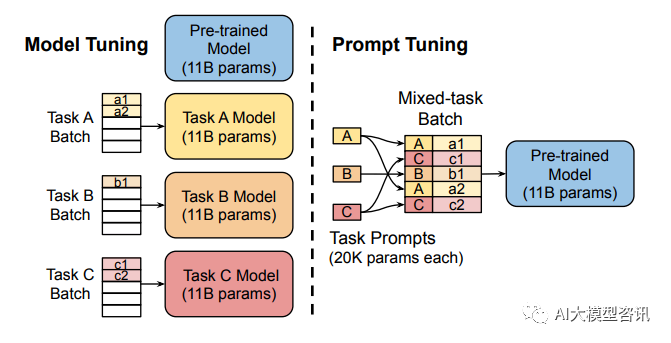 図
図
以上が大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。