
ホームページ >テクノロジー周辺機器 >AI >Baichuan Intelligent は Baichuan2 大型モデルをリリースしました。これは Llama2 よりも完全に先を行っており、トレーニング スライスもオープンソースです
Baichuan Intelligent は Baichuan2 大型モデルをリリースしました。これは Llama2 よりも完全に先を行っており、トレーニング スライスもオープンソースです

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-09-07 15:13:051325ブラウズ
Baichuan Intelligent が大型モデルを平均 28 日でリリースしたことに業界が驚いても、同社は立ち止まりませんでした。
9 月 6 日午後の記者会見で、Baichuan Intelligent は、微調整された Baichuan-2 大型モデルの公式オープンソースを発表しました。
 中国科学院の学者で清華大学人工知能研究所の名誉院長である張波氏が記者会見に出席した。
中国科学院の学者で清華大学人工知能研究所の名誉院長である張波氏が記者会見に出席した。
これは、8 月の Baichuan-53B 大型モデルのリリース以来、Baichuan によるもう 1 つの新しいリリースです。オープンソース モデルには、Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat およびそれらの 4 ビット量子化バージョンが含まれており、すべて無料で商用利用可能です。
モデルの完全な公開に加えて、Baichuan Intelligence はモデル トレーニング用の Check Point をオープンソース化し、新しいモデルのトレーニングの詳細を詳述する Baichuan 2 技術レポートを公開しました。 Baichuan Intelligence の創設者兼 CEO の Wang Xiaochuan 氏は、この動きにより、大規模モデルの学術機関、開発者、企業ユーザーが大規模モデルのトレーニング プロセスを深く理解し、大規模モデルの技術開発をより促進できるようになることへの期待を表明しました。学術研究とコミュニティ。
Baichuan 2 大型モデルのオリジナルリンク: https://github.com/baichuan-inc/Baichuan2
技術レポート: https://cdn.baichuan-ai.com/paper/ Baichuan2 -technical-report.pdf
今日のオープン ソース モデルは、大規模なモデルに比べてサイズが「小さい」です。その中でも、Baichuan2-7B-Base と Baichuan2-13B-Base は両方とも 2.6 兆の高品質のデータに基づいています。多次元言語データはトレーニングに使用され、前世代のオープンソース モデルの良好な生成および作成機能、スムーズなマルチラウンド対話機能、および低い導入しきい値を維持することに基づいて、2 つのモデルは数学において優れたパフォーマンスを備えています。コード、セキュリティ、論理的推論、意味理解などの能力が大幅に向上しました。
「簡単に言えば、Baichuan7B の 70 億パラメータ モデルは、英語のベンチマークですでに LLaMA2 の 130 億パラメータ モデルと同等です。したがって、小さなモデルで大きな違いを生み出すことができ、小さなモデルは大型モデルの性能と同等であり、同じサイズのモデルでも総合的に LLaMA2 の性能を上回る、より高い性能を達成できます」と王暁川氏は述べています。
前世代の 13B モデルと比較して、Baichuan2-13B-Base は数学的機能が 49%、コーディング機能が 46%、セキュリティ機能が 37%、論理機能が 25% 向上しています。推論能力が向上し、意味理解能力が 15% 向上しました。
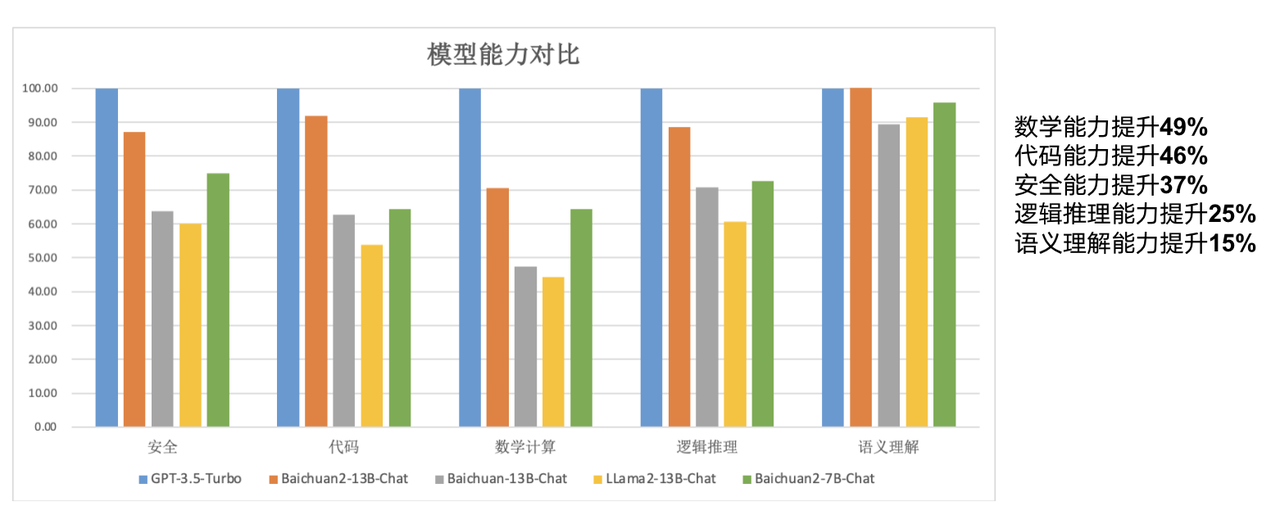
レポートによると、この新しいモデルに関して、Baichuan Intelligence の研究者はデータ収集から微調整に至るまで多くの最適化を行ったとのことです。
「以前の検索での経験をさらに活用し、大量のモデル トレーニング データに対して多粒度のコンテンツ品質スコアリングを実施し、2 億 6,000 万 T のコーパス レベルを使用して 7B および 13B モデルをトレーニングし、マルチ言語サポート」と王暁春氏は語った。 「Qianka A800 クラスターでは 180TFLOPS のトレーニング パフォーマンスを達成でき、マシン使用率は 50% を超えています。さらに、多くのセキュリティ調整作業も完了しました。」
2 つのオープンソース プロジェクトこのモデルは、主要な評価リストで良好なパフォーマンスを示しています。MMLU、CMMLU、GSM8K などのいくつかの権威ある評価ベンチマークでは、LLaMA2 を大きくリードしています。同じパラメータ数を持つ他のモデルと比較しても、パフォーマンスは非常に優れています。捕まり性能が高く、同サイズのLLaMA2競合モデルよりも振幅が優れています。
さらに注目に値するのは、MMLU などの複数の権威ある英語評価ベンチマークによると、Baichuan2-7B には、主流の英語タスクで 130 億個のパラメータを持つ LLaMA2 と同じレベルの 70 億個のパラメータがあるということです。
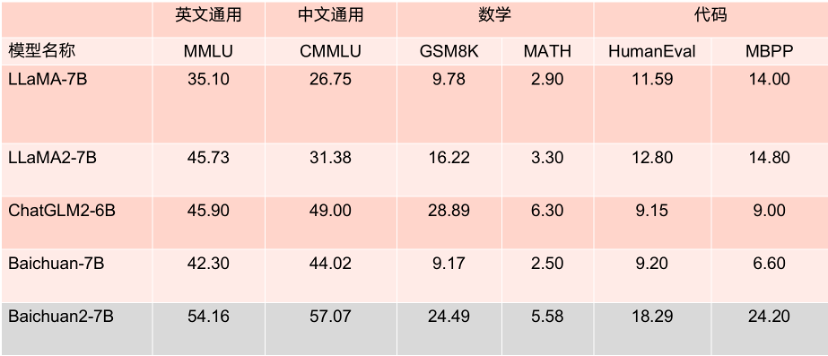
7B パラメータ モデルのベンチマーク結果。
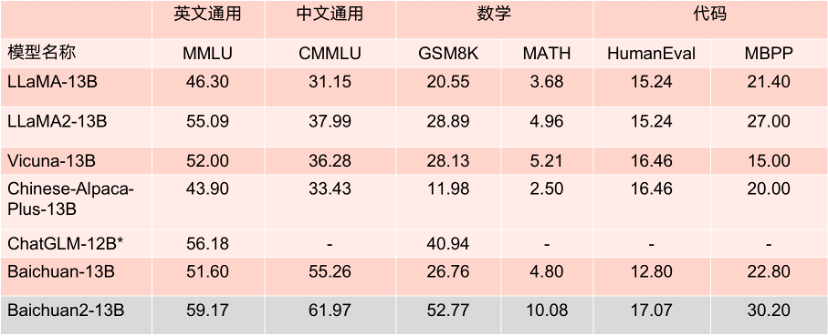
13B パラメトリック モデルのベンチマーク結果。
Baichuan2-7B および Baichuan2-13B は学術研究に完全にオープンであるだけでなく、開発者は電子メールで申請して正式な商用ライセンスを取得した後、無料で商業的に使用することもできます。
「モデルのリリースに加えて、学術分野へのさらなるサポートも提供したいと考えています」と王暁川氏は語った。 「技術レポートに加えて、Baichuan2 大型モデル トレーニング プロセスの重みパラメーター モデルも公開しました。これにより、誰もが事前トレーニングを理解したり、微調整や強化を実行したりするのに役立ちます。これも中国で初めてです。」
大規模モデルのトレーニングには、大量の高品質データの取得、大規模トレーニング クラスターの安定したトレーニング、モデル アルゴリズムのチューニングなどの複数のステップが含まれます。各リンクには多量の人材、計算能力、その他のリソースの投資が必要ですが、モデルをゼロからトレーニングするコストが高いため、学術コミュニティは大規模なモデルのトレーニングに関する詳細な研究を行うことができません。
Baichuan Intelligence は、220B から 2640B までのモデル トレーニングのプロセス全体に対して Check Ponit をオープンソース化しました。これは、科学研究機関が大型モデルのトレーニングプロセス、継続的なモデルトレーニング、モデル値の調整などを研究するのに非常に価値があり、国内の大型モデルの科学研究の進歩を促進できます。
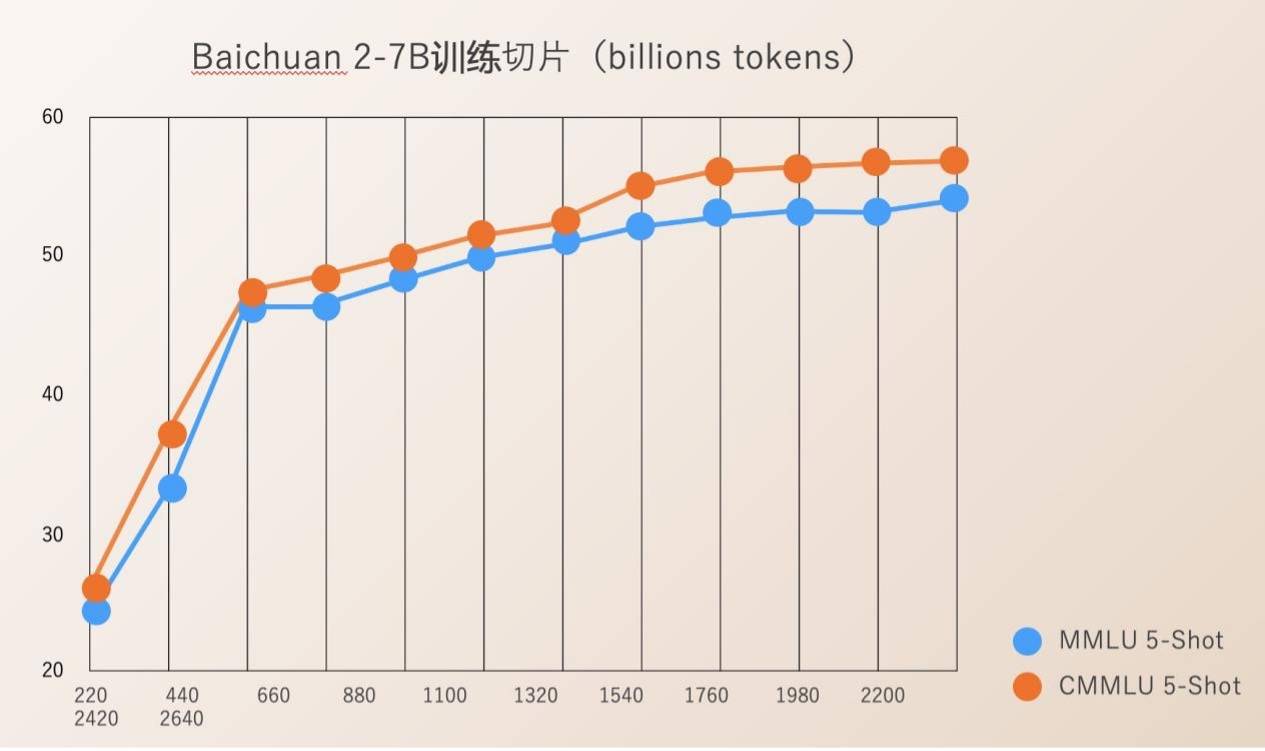
以前は、ほとんどのオープンソース モデルは、モデルの重みを外部に公開するだけで、トレーニングの詳細についてはほとんど言及されていませんでした。徹底的な調査を実施します。
Baichuan Intelligence が発行した Baichuan 2 技術レポートには、データ処理、モデル構造の最適化、スケーリング則、プロセス指標などを含む、Baichuan 2 トレーニングのプロセス全体が詳しく記載されています。
Baichuan Intelligence は設立以来、オープンソースを通じて中国の大型モデル生態系の繁栄を促進することを会社の重要な発展方向とみなしてきました。設立から 4 か月も経たないうちに、同社は 2 つのオープンソースの無料商用中国大型モデル Baichuan-7B と Baichuan-13B、および検索機能を強化した大型モデル Baichuan-53B をリリースしました。多くの信頼できるレビューでリストの上位にランクされ、500 万回以上ダウンロードされています。
先週、大規模モデルの公共サービス写真撮影の最初のバッチが開始されたことは、科学技術の分野における重要なニュースでした。今年設立された大手モデル企業の中で、百川智能は「生成型人工知能サービス管理暫定措置」に登録され、正式に一般向けにサービスを提供できる唯一の企業である。
基本的な大型モデルに業界をリードする研究開発とイノベーション機能を備えた 2 つのオープンソース Baichuan 2 モデルは、Tencent Cloud、Alibaba Cloud、Volcano Ark、Huawei、MediaTek を含む上流および下流の企業から肯定的な反応を得ています。多くの有名企業がこの会議に参加し、百川智能との協力に達しました。報告によると、Hugging Face における Baichuan Intelligence の大型モデルのダウンロード数は、過去 1 か月間で 337 万件に達しました。
Baichuan Intelligence の以前の計画によれば、今年は 1,000 億個のパラメータを備えた大規模モデルをリリースし、来年の第 1 四半期に「スーパー アプリケーション」をリリースする予定です。
以上がBaichuan Intelligent は Baichuan2 大型モデルをリリースしました。これは Llama2 よりも完全に先を行っており、トレーニング スライスもオープンソースですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。