


AI絵画の分野では、アリババが提案したComposerとスタンフォードが提案した安定拡散に基づくControlNetが、制御可能な画像生成の理論開発を主導してきました。ただし、制御可能なビデオ生成に関する業界の探求はまだ比較的空白です。
画像生成と比較して、制御可能なビデオは、ビデオコンテンツの空間の制御性に加えて、時間次元の制御性も満たす必要があるため、より複雑です。これに基づいて、アリババとアントグループの研究チームが率先して試みを行い、複合生成パラダイムによって時間と空間の両方の次元でのビデオ制御性を同時に実現するVideoComposerを提案しました。

- 論文アドレス: https://arxiv.org/abs/2306.02018
- プロジェクトのホームページ: https://videocomposer.github.io
少し前に、Alibaba Wensheng ビデオ モデルは控えめで、Moda コミュニティと Hugging Face でオープンソース化されていました。予想外に国内外の開発者から幅広い注目を集めました。モデルによって生成されたビデオには、マスク氏自身からも返答がありました。このモデルは注文を受けましたModa コミュニティでは何日も続けてアクセスされ、1 日に数万人の海外からのアクセスがありました。

##Text-to-Video on Twitter
VideoComposer 研究チームの最新の成果として、再び国際的な注目を集めています。コミュニティに焦点を当てます。

 #Twitter の VideoComposer
#Twitter の VideoComposer
実際、制御性はビジュアル コンテンツ作成のより高い基準となり、カスタマイズされた画像生成においては大きな進歩を遂げていますが、ビデオ生成の分野にはまだ 3 つの問題があります。大きな課題: 実験結果によると、VideoComposer は、単一の写真や手描きの絵などから特定のビデオを生成するなど、ビデオの時間と空間のパターンを柔軟に制御でき、さらには簡単に使用することもできます。シンプルな手書きの指示で、ターゲットの移動スタイルを制御します。この調査では、9 つの異なる古典的なタスクで VideoComposer のパフォーマンスを直接テストし、すべて満足のいく結果を達成し、VideoComposer の多用途性を証明しました。
ビデオ LDM ## 隠れた空間。 ビデオ LDM は、まず、入力ビデオ を潜在空間式にマッピングするための事前トレーニングされたエンコーダーを導入します。ここで、 にマッピングします。 VideoComposer では、パラメータは に設定されます。 #拡散モデル。 実際のビデオ コンテンツの配信について学ぶには , 拡散モデルは、正規分布ノイズから徐々にノイズを除去して実際の視覚コンテンツを復元することを学習します。このプロセスは、実際には、長さ T=1000 の可逆マルコフ連鎖をシミュレートしています。潜在空間で可逆プロセスを実行するために、Video LDM は
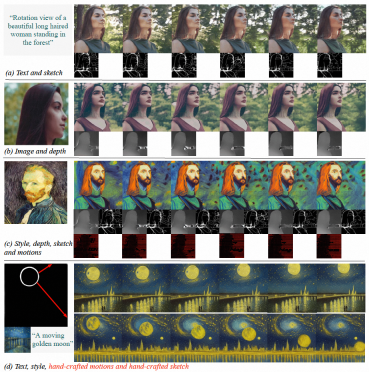 #図 (a ~ c) VideoComposer は、テキスト、空間的および時間的条件、またはそのサブセットを満たすビデオを生成できます。 (d) VideoComposer は、期待される動きモード (赤いストローク) と形状モード (白いストローク) を満たしながら、ゴッホのスタイルを満たすビデオを生成するために 2 つのストロークのみを使用できます。 #メソッドの紹介
#図 (a ~ c) VideoComposer は、テキスト、空間的および時間的条件、またはそのサブセットを満たすビデオを生成できます。 (d) VideoComposer は、期待される動きモード (赤いストローク) と形状モード (白いストローク) を満たしながら、ゴッホのスタイルを満たすビデオを生成するために 2 つのストロークのみを使用できます。 #メソッドの紹介
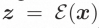
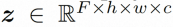




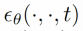
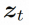

空間ローカル誘導バイアスの使用とノイズ除去のためのシーケンス時間誘導バイアスの使用を完全に調査するために、VideoComposer は 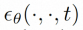

##VideoComposer
組み合わせ条件。 VideoComposer は、ビデオを 3 つの異なるタイプの条件 (テキスト条件、空間条件、クリティカル タイミング条件) に分解します。これらの条件が組み合わさって、ビデオ内の空間的および時間的パターンを決定します。 VideoComposer は、一般的な構成可能なビデオ生成フレームワークであるため、以下にリストされているものに限定されず、ダウンストリーム アプリケーションに基づいて、よりカスタマイズされた条件を VideoComposer に組み込むことができます。
- #テキスト条件: テキストdescription は、大まかなビジュアル コンテンツとモーションの側面を含む、ビデオの視覚的な指示を提供します。これは、T2V でよく使用される条件でもあります。
- 空間条件:
- 単一画像。指定されたビデオの最初のフレームを空間条件として選択し、画像からビデオを生成し、ビデオのコンテンツと構造を表現します。
- 単一スケッチ。PiDiNet を使用して、最初のビデオ フレームのスケッチを 2 番目の空間条件として抽出します。
- Style (スタイル)。単一画像のスタイルを合成ビデオにさらに転送し、スタイル ガイドとして画像の埋め込みを選択します;
- タイミング条件:
- 映像特有の要素である動きベクトル(Motion Vector)は、2次元のベクトルとして表現されます。 、水平方向と垂直方向。 2 つの隣接するフレーム間のピクセルごとの動きを明示的にエンコードします。動きベクトルの自然な特性により、この状態は時間的に滑らかに合成された動き制御信号として扱われ、圧縮ビデオから標準 MPEG-4 形式で動きベクトルを抽出します;
- 深度シーケンス(深度シーケンス)、ビデオレベルの深度情報を導入するには、PiDiNet の事前トレーニング済みモデルを使用してビデオ フレームの深度マップを抽出します。
- マスク シーケンス (マスク シーケンス) )、管状マスクを導入してローカルの時空間コンテンツをマスクし、観察可能な情報に基づいてマスクされた領域をモデルに強制的に予測させます。
- スケッチ シーケンス。単一のスケッチと比較して、スケッチ シーケンスは次のことができます。細部をより細かく制御して、正確なカスタム構成を実現します。
# 時空間条件付きエンコーダー。 シーケンス条件には豊富で複雑な時空間依存関係が含まれており、制御可能な命令に大きな課題をもたらします。入力条件の時間的認識を強化するために、この研究では、時空間関係を組み込む時空間条件エンコーダー (STC エンコーダー) を設計しました。具体的には、2 つの 2D 畳み込みと avgPooling を含む軽量の空間構造が最初に適用されてローカル空間情報が抽出され、その結果の条件シーケンスが時間モデリングのために時間 Transformer レイヤーに入力されます。このようにして、STC エンコーダは時間的キューの明示的な埋め込みを容易にし、多様な入力に対する条件付き埋め込みのための統合されたエントリを提供することで、フレーム間の一貫性を強化できます。さらに、この研究では、単一の画像と単一のスケッチの空間条件を時間次元で繰り返して、時間条件との一貫性を確保し、条件埋め込みプロセスを容易にしました。
条件が STC エンコーダーを通じて処理された後、最終的な条件シーケンスは STC エンコーダーと同じ空間形状を持ち、要素ごとの加算によって融合されます。最後に、マージされた条件付きシーケンスは、制御信号としてチャネル次元に沿って連結されます。テキストとスタイルの条件については、クロスアテンション メカニズムを利用してテキストとスタイルのガイダンスを挿入します。
#トレーニングと推論
2 段階のトレーニング戦略。 VideoComposer は画像 LDM の事前トレーニングを通じて初期化でき、トレーニングの難易度をある程度軽減できますが、モデルが時間的なダイナミクスを認識する能力を持つことは困難です。複数の条件を同時に生成できるため、組み合わせたビデオ生成のトレーニングの難易度が高くなります。したがって、この研究では 2 段階の最適化戦略を採用しました。第 1 段階では、最初に T2V トレーニングを通じてモデルにタイミング モデリング機能が装備され、第 2 段階では、組み合わせトレーニングを通じて VideoComposer が最適化され、パフォーマンスが向上しました。
推論。 推論プロセス中、推論効率を向上させるために DDIM が使用されます。また、分類子を使用しないガイダンスを採用して、生成された結果が指定された条件を確実に満たすようにします。生成プロセスは次のように形式化できます:
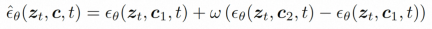
ここで、ω は誘導率、c1 と c2 は 2 つの条件セットです。この誘導メカニズムは 2 つの条件のセットによって判断され、強度制御を通じてモデルをより柔軟に制御できます。
実験結果実験的調査では、研究では、VideoComposer がユニバーサル生成フレームワークを備えた統合モデルとして機能することを実証し、9 つの古典的なタスクに対する VideoComposer の機能を検証しました。 。
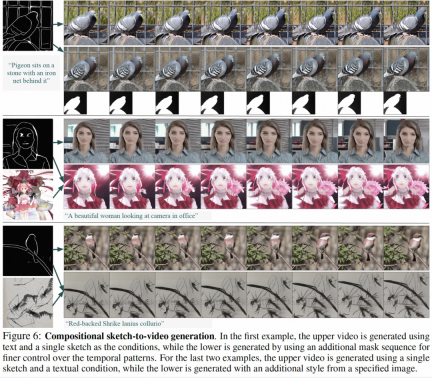
この研究結果の一部は、静止画像からビデオの生成 (図 4)、ビデオの修復 (図 5)、静的なスケッチのビデオから生成 (図 6) です。 、手描きのモーション コントロール ビデオ (図 8) とモーション転送 (図 A12) は両方とも、制御可能なビデオ生成の利点を反映できます。



以上が時間と空間を制御可能なビデオ生成が現実となり、アリババの新しい大規模モデルVideoComposerが人気にの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム
 AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM
AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM主要なエンタープライズ分析プラットフォームAlteryxのCEOであるAndy Macmillanとの私の最近の会話は、AI革命におけるこの重要でありながら過小評価されている役割を強調しました。 MacMillanが説明するように、生のビジネスデータとAI-Ready情報のギャップ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

WebStorm Mac版
便利なJavaScript開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

