



今月初め、Meta は「Split Everything」モデルを発表し、CV サークル全体に衝撃を与えました。
# ここ数日で、「Relate-Anything-Model (RAM)」と呼ばれる機械学習モデルが登場しました。これにより、Segment Anything Model (SAM) は、異なる視覚概念間のさまざまな視覚的関係を識別できるようになります。
このモデルは、南洋理工大学の MMLab チームと、キングス カレッジ ロンドンの VisCom 研究室と同済大学の学生によって開発されたものであると理解されています。時間。

デモ アドレス: https://huggingface.co/spaces/mmlab-ntu/関連する-anything-model
コードアドレス: https://github.com/Luodian/RelateAnything
##データセットのアドレス: https://github.com/Jingkang50/OpenPSG
効果のデモンストレーション
まずは、見てみましょう「Relate-Anything-Model(RAM)」の応用例を見てみましょう!
たとえば、サッカーをしたり、ダンスをしたり、友達を作ったりする RAM モデルの実装に関する次の画像分析結果は、非常に印象的で、よく表示されています。さまざまなアプリケーションのパフォーマンスと可能性。



RAM モデルは、ECCV'22 SenseHuman Workshop & International Algorithm Example Competition「Panoptic Scene Graph Generation」トラックに基づいています。チャンピオンプログラム。

PSG チャレンジには 100 万ドルの賞金があり、高度な画像セグメンテーション手法の使用やロングテール問題の解決など、世界中の 100 チームから提出されたさまざまなソリューションを受け取りました。さらに、コンペティションでは、シーン グラフ固有のデータ拡張技術など、いくつかの革新的な手法も採用されました。
パフォーマンス指標、新規性、ソリューションの重要性などの考慮事項に基づいて評価した結果、Xiaohongshu チームの GRNet が優れた手法として際立っていました。

ソリューションを紹介する前に、まず 2 つの古典的な PSG ベースライン手法を紹介します。1 つは 2 段階手法で、もう 1 つは 1 段階手法です。
2 段階のベースライン手法の場合、図 a に示すように、最初の段階では、事前トレーニングされたパノラマ セグメンテーション モデル Panoptic FPN を使用して、画像から特徴、セグメンテーション、および分類予測を抽出します。 。次に、個々のオブジェクトの特徴が IMP などの古典的なシーン グラフ ジェネレーターに供給され、第 2 段階で PSG タスクに適合するシーン グラフ生成が行われます。この 2 段階のアプローチにより、古典的な SGG メソッドを最小限の変更で PSG タスクに適合させることができます。 図 b に示すように、単一ステージのベースライン メソッド PSGTR は、まず CNN を使用して画像特徴を抽出し、次に DETR と同様のトランスフォーマー エンコーダー/デコーダーを使用します。トリプル表現を直接学ぶことができます。ハンガリアン マッチャーは、予測されたトリプルとグランド トゥルース トリプルを比較するために使用されます。次に、最適化の目的はマッチャーの計算コストを最大化することであり、ラベル付けとセグメンテーションのクロスエントロピー DICE/F-1 損失を使用して総損失が計算されます。 
##RAM モデルの設計プロセスでは、著者は、PSG チャンピオン スキーム GRNet の 2 段階構造パラダイムについて言及しています。元の PSG 記事の調査では、現時点では 1 段階モデルのパフォーマンスが 2 段階モデルよりも優れていることが示されていますが、多くの場合、1 段階モデルは 2 段階モデルほど優れたセグメンテーション パフォーマンスを達成できないことがわかります。
さまざまなモデル構造を観察した結果、リレーショナル トリプルの予測における単一段階モデルの優れたパフォーマンスは、画像からの直接監視によるものである可能性があると推測されます。機能マップ シグナルは関係を把握するのに適しています。
この観察に基づいて、GRNet のような RAM の設計は、2 つのステージに焦点を当てて 2 つのモード間のトレードオフを見つけることを目的としています。これは、単一段階のパラダイムでグローバル コンテキストを取得する機能によって実現されます。
具体的には、まず、SAM (Segment Anything Model) を特徴抽出器として使用して、画像内のオブジェクトを識別してセグメント化します。また、SAM セグメンターから特定のオブジェクトを抽出します。オブジェクトの中間特徴マップは、対応するセグメンテーションと融合されて、オブジェクト レベルの特徴が取得されます。
#続いて、Transformer がグローバル コンテキスト モジュールとして使用され、取得されたオブジェクト レベルの特徴が線形マッピング後に入力されます。 Transformer エンコーダのクロスアテンション メカニズムを通じて、出力オブジェクト機能は他のオブジェクトからよりグローバルな情報を収集します。#最後に、Transformer によって出力される各オブジェクト レベルの特徴について、セルフ アテンション メカニズムを使用してコンテキスト情報がさらに強化され、相互作用が完了します。それぞれのオブジェクト。
ここでは、オブジェクトのカテゴリを示すカテゴリ埋め込みも追加されており、そこからオブジェクトのペアとそれらの関係の予測が得られることに注意してください。 。
RAM 関係分類
トレーニング プロセス中に、関係カテゴリごとに、オブジェクトを決定するために関係バイナリ分類タスクを実行する必要があります。ペア間に関係があるかどうか。#GRNet と同様に、リレーショナル バイナリ分類タスクには特別な考慮事項がいくつかあります。たとえば、PSG データセットには通常、「人々がゾウを見る」と「人々がゾウに餌をやる」といった複数の関係を持つ 2 つのオブジェクトが同時に存在します。マルチラベル問題を解決するために、著者らは関係予測を単一ラベル分類問題からマルチラベル分類問題に変換しました。
#さらに、PSG データセット以来、精度と相関の追求は、境界関係 (「in」や「stop at」など) の学習には適していない可能性があります。実際には同時に存在します)。この問題を解決するために、RAM は、関係分類に自己蒸留ラベルを使用し、指数移動平均を使用してラベルを動的に更新する自己トレーニング戦略を採用しています。
リレーショナル バイナリ分類損失を計算する場合、予測された各オブジェクトは、対応する基礎となるグラウンド トゥルース オブジェクトとペアになる必要があります。この目的には、ハンガリーのマッチング アルゴリズムが使用されます。 # ただし、このアルゴリズムは、特にネットワークの精度が低いトレーニングの初期段階では不安定になる傾向があります。これにより、同じ入力に対して異なるマッチング結果が得られ、ネットワーク最適化の方向が一貫性を持たなくなり、トレーニングがより困難になる可能性があります。 RAM では、以前のソリューションとは異なり、強力な SAM モデルを利用して、ほぼすべての画像の完全かつ詳細なセグメンテーションを実行できます。予測と GT をマッチングするプロセスにおいて、RAM は当然のことながら、PSG データ セットを使用してモデルをトレーニングするという新しい GT マッチング方法を設計しました。 #各トレーニング イメージについて、SAM は複数のオブジェクトをセグメント化しますが、PSG のグラウンド トゥルース (GT) マスクに一致するオブジェクトはほんのわずかです。著者らは、交差結合 (IOU) スコアに基づいて単純なマッチングを実行し、(ほぼ) すべての GT マスクが SAM マスクに割り当てられるようにします。その後、著者は SAM マスクに基づいて関係図を再生成しました。これはモデルの予測と自然に一致しました。 RAM モデルでは、作成者はセグメント何でもモデル (SAM) を使用して、画像内のオブジェクトを識別してセグメント化します。 、およびセグメント化された各オブジェクトの特徴を抽出します。次に、Transformer モジュールを使用してセグメント化されたオブジェクト間で対話し、新しい機能を取得します。最後に、これらの特徴がカテゴリに埋め込まれた後、セルフ アテンション メカニズムを通じて予測結果が出力されます。 学習プロセスでは、特に、著者は新しい GT マッチング手法を提案し、この手法に基づいて予測と GT のペア関係を計算し、分類しました。彼らの相互関係。関係分類の教師あり学習プロセスでは、著者はそれをマルチラベル分類問題とみなして、ラベルの境界関係を学習する自己学習戦略を採用しています。 最後に、RAM モデルがさらなるインスピレーションと革新をもたらすことを願っています。関係性を見つけることができる機械学習モデルをトレーニングしたい場合は、このチームの作業をフォローし、いつでもフィードバックや提案を与えることができます。 RAM のその他の設計
RAM モデルの概要

プロジェクトアドレス: https://github.com/Jingkang50/OpenPSG
以上がNTUは新しいRAMモデルを提案し、メタを使用してすべてを分割して関係を取得し、歌と踊りの急所攻撃効果は優れています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

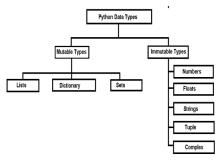 Pythonの可変vs不変のオブジェクト-AnalyticsVidhyaApr 13, 2025 am 09:15 AM
Pythonの可変vs不変のオブジェクト-AnalyticsVidhyaApr 13, 2025 am 09:15 AM導入 Pythonはオブジェクト指向のプログラミング言語(またはoop)です。前の記事では、その多目的な性質を調査しました。このため、Pythonはさまざまなデータ型を提供します。これはMに広く分類できます
 無料でTableauを学ぶ11のYouTubeチャネル-AnalyticsVidhyaApr 13, 2025 am 09:14 AM
無料でTableauを学ぶ11のYouTubeチャネル-AnalyticsVidhyaApr 13, 2025 am 09:14 AM導入 Tableauは、効率的なデータ分析とプレゼンテーションのために、世界中で企業や個人が現在使用している最も堅牢なデータ視覚化ツールの1つと考えられています。ユーザーフレンドリーなインターフェイスとextenを使用しています
 10生成AIコーディング拡張機能とコードのコードを探る必要がありますApr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要がありますApr 13, 2025 am 01:14 AMねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

