
ホームページ >テクノロジー周辺機器 >AI >効率的かつリアルな超大規模都市レンダリングの実現:NeRFとフィーチャグリッド技術の組み合わせ
効率的かつリアルな超大規模都市レンダリングの実現:NeRFとフィーチャグリッド技術の組み合わせ

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-06 17:04:171231ブラウズ
純粋に MLP に基づいた Neural Radiation Field (NeRF) は、モデルの容量が限られているため、大規模なシーンのブラー レンダリングでアンダーフィッティングが発生することがよくあります。最近、シーンを地理的に分割し、複数のサブ NeRF を使用して各エリアを個別にモデル化することを提案する研究者もいますが、これによって生じる問題は、シーンが徐々に拡大するにつれて、トレーニング コストがサブ NeRF の数に比例することです。 。 拡大する。
もう 1 つの解決策は、ボクセル フィーチャ グリッド表現を使用することです。これは計算効率が高く、グリッド解像度を高めると大規模なシーンに自然に拡張できます。ただし、フィーチャ メッシュでは制約が少ないために次善の解決策しか得られないことが多く、特に複雑なジオメトリやテクスチャのある領域では、レンダリング時にノイズ アーティファクトが生成されます。
この記事では、香港中文大学、上海人工知能研究所、その他の機関の研究者が、都市 (Ubran) シーンの高忠実度レンダリングを実現するための新しいフレームワークを提案しています。同時に計算効率も考慮され、CVPR 2023 に選ばれました。この調査では、コンパクトな多重解像度の地上フィーチャ平面表現を使用してシーンを大まかにキャプチャし、共同学習された方法でレンダリングするために NeRF ブランチ ネットワークを介して位置エンコードされた入力でそれを補足します。このアプローチは 2 つのアプローチの利点を統合しています: フィーチャ グリッド表現の指導の下、軽量の重み付けされた NeRF は詳細を含む現実的な新しい視点を提示するのに十分です; 共同で最適化された地表フィーチャ平面をさらに洗練して、より正確でより詳細な形状を形成できます。詳細な特徴空間をコンパクトにし、より自然なレンダリング結果を出力します。

- 論文アドレス: https://arxiv.org/pdf /2303.14001.pdf
- プロジェクトのホームページ: https://city-super.github.io/gridnerf/
 方法の紹介
方法の紹介
ターゲット シーンは、まずトレーニング前の段階でフィーチャ メッシュを使用してモデル化され、シーンのジオメトリと外観を大まかにキャプチャします。次に、粗い特徴グリッドを使用して、1) NeRF ポイント サンプリングがシーン表面の周囲に集中するようにガイドし、2) シーンのジオメトリとサンプリングされた位置の外観に関する追加の特徴を NeRF の位置エンコーディングに提供します。このようなガイダンスにより、NeRF は大幅に圧縮されたサンプリング空間でより詳細な情報を効率的に取得できます。さらに、粗いレベルのジオメトリおよび外観情報が NeRF に明示的に提供されるため、グローバル座標からボリューム密度およびカラー値へのマッピングを学習するには軽量の MLP で十分です。 2 番目の共同学習ステージでは、粗い特徴メッシュが NeRF ブランチからの勾配を介してさらに最適化され、正規化されるため、単独で適用した場合により正確で自然なレンダリング結果が得られます。
この研究の核心は、新しいデュアルブランチ構造、つまり Grid ブランチと NeRF ブランチです。 1) 研究者らはまず、事前トレーニング段階で特徴面のピラミッド シーンをキャプチャし、浅い MLP レンダラー (グリッド ブランチ) を通じて光線ポイントを大まかにサンプリングし、ピクセル カラーのボリューム積分 MSE によってそれらの放射輝度値を予測しました。損失の監督。このステップでは、情報が豊富な多重解像度の密度/外観特徴面のセットが生成されます。 2) 次に、研究者は共同学習段階に入り、より洗練されたサンプリングを実行します。研究者らは、学習された特徴グリッドを使用して、シーンの表面に焦点を当てるように NeRF ブランチ サンプリングをガイドしました。サンプリング ポイントのグリッド特性は、特徴平面上の双一次補間によって導出されます。これらの特徴は位置エンコーディングと連結され、NeRF ブランチに供給されて体積密度と色が予測されます。共同トレーニング中、グリッド ブランチの出力は、グラウンド トゥルース イメージと NeRF ブランチからの精細なレンダリング結果を使用して引き続き監視されることに注意してください。
対象シナリオ: この研究では、新しいグリッド誘導神経放射線場を使用して大規模な都市シーンを実行します。レンダリング。下の画像の左側は、5,000 を超えるドローン画像によってキャプチャされた、2.7km^2 の地上エリアにわたる大規模な都市風景の例を示しています。研究によると、NeRF ベースの方法では、ぼやけて平滑化しすぎた結果が得られ、モデルの容量が制限される一方、固有グリッド ベースの方法では、高解像度の固有グリッドを使用した大規模なシーンに適応するとノイズの多いアーティファクトが表示される傾向があることが示されています。本研究で提案したデュアルブランチモデルは、両方の手法の利点を組み合わせ、既存の手法を大幅に改善することで、現実的な斬新なビューレンダリングを実現します。どちらのブランチも、それぞれのベースラインよりも大幅に強化されています。 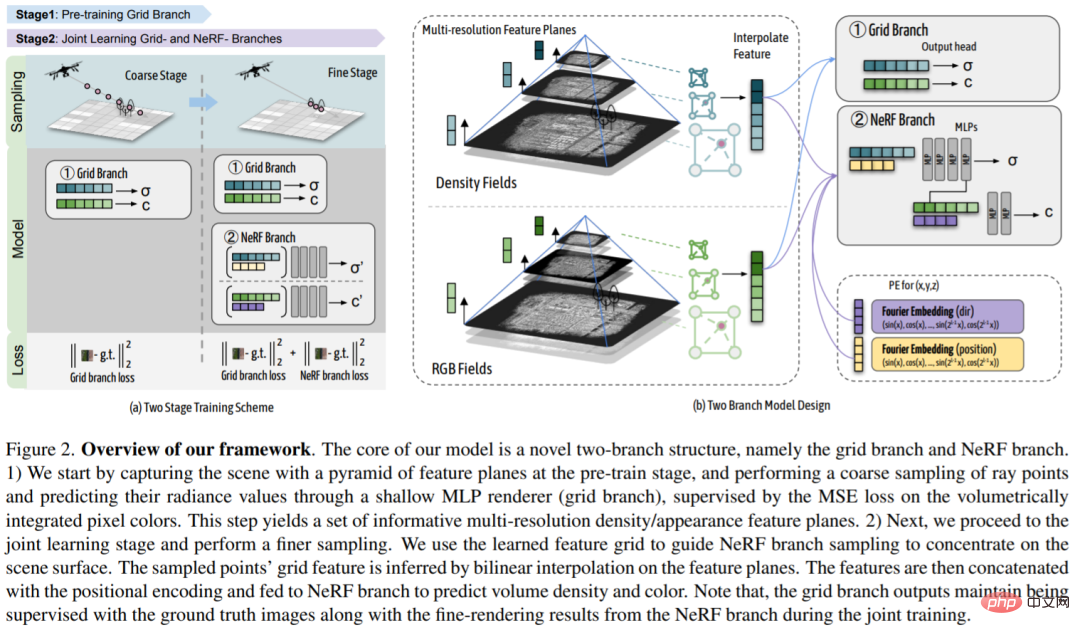

実験
研究者は、ベースラインのパフォーマンスと研究者の比較方法を報告します。質的にも量的にも。ビジュアル品質とすべての指標の点で大幅な改善が見られます。研究者のアプローチにより、純粋に MLP ベースの方法 (NeRF および Mega-NeRF) よりも鮮明な幾何学形状と微細な詳細が明らかになりました。特に、NeRF の能力とスペクトル バイアスが限られているため、遊び場の植生や縞模様などの幾何学形状や色の急速な変化を常にシミュレートすることができません。 Mega-NeRF ベースラインに示されているように、シーンを地理的に小さな領域に分割することはわずかに役立ちますが、表示された結果は依然として滑らかすぎるように見えます。それどころか、学習された特徴グリッドによって導かれ、NeRF のサンプリング空間はシーン表面近くで効果的かつ大幅に圧縮されます。図 3 に示すように、地表フィーチャ平面からサンプリングされた密度フィーチャと外観フィーチャは、シーンのコンテンツを明示的に表します。精度はそれほど高くありませんが、すでに有益なローカル ジオメトリとテクスチャが提供されており、NeRF の位置エンコーディングが不足しているシーンの詳細を収集することを促進します。

以下の表 1 は、定量的な結果を示しています。
図 6 レンダリングの忠実度が急速に向上していることがわかります。 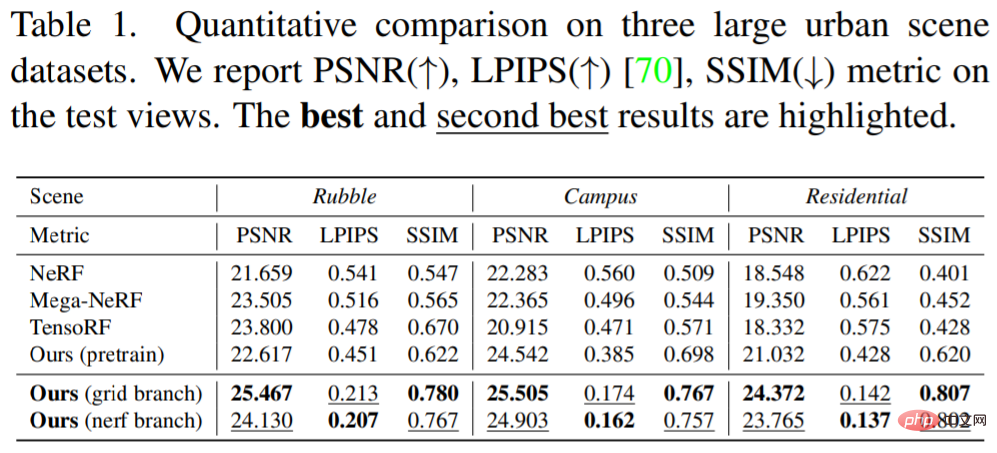
詳細については、元の論文を参照してください。

以上が効率的かつリアルな超大規模都市レンダリングの実現:NeRFとフィーチャグリッド技術の組み合わせの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。