


メモリが 3% ~ 7% 削減されました。 Google、コンパイラ最適化のための機械学習フレームワークMLGOを提案

現代のコンピューターの誕生に伴い、より速く、より小さなコードをコンパイルする方法という問題が浮上しました。
コンパイルの最適化は、費用対効果が最も高い最適化方法です。コードの最適化を改善すると、大規模なデータセンター アプリケーションの運用コストを大幅に削減できます。コンパイルされたバイナリは厳密なコード サイズの予算を満たす必要があるため、コンパイルされたコード サイズは、セキュア ブート パーティションに展開されるモバイルおよび組み込みシステムまたはソフトウェアにとって重要です。分野が進歩するにつれて、ヒューリスティックがますます複雑になり、限られたシステムスペースが大幅に圧迫され、メンテナンスやさらなる改善が妨げられています。
最近の研究では、機械学習が複雑なヒューリスティックを機械学習戦略に置き換えることにより、コンパイラの最適化においてより多くの機会を切り開くことができることを示しています。ただし、汎用の業界グレードのコンパイラに機械学習戦略を採用することは依然として課題です。
この問題を解決するために、Google の 2 人の上級エンジニア、Qian Yundi と Mircea Trofin は、業界初の「機械学習ガイド付きコンパイラ最適化フレームワーク MLGO」を提案しました。機械学習技術を LLVM に体系的に統合するためのユニバーサル フレームワーク。LLVM は、ミッションクリティカルな高性能ソフトウェアの構築に広く普及しているオープンソースの産業用コンパイラ インフラストラクチャです。

論文アドレス: https://arxiv.org/pdf/2101.04808.pdf ##MLGO は強化学習を使用してニューラル ネットワークをトレーニングして意思決定を行い、LLVM のヒューリスティック アルゴリズムを置き換えます。著者の説明によると、LLVM には 2 つの MLGO 最適化があります:
1) インライン化によるコード量の削減;
2)レジスタ割り当てを通じてコードのパフォーマンスを向上させます。
両方の最適化は LLVM リポジトリで利用でき、実稼働環境にデプロイされています。
1 MLGO はどのように機能しますか?
インライン化は、冗長なコードを削除する決定を行うことで、コード サイズを削減するのに役立ちます。次の例では、呼び出し元関数
<span style="font-size: 15px;">foo()</span> <span style="font-size: 15px;"> が呼び出し先関数 </span> bar( ) <span style="font-size: 15px;">、および </span> <span style="font-size: 15px;">bar()</span> <span style="font-size: 15px;"> 自体は </span> # を呼び出します##バズ() 。これら 2 つの呼び出しサイトをインライン化すると、単純な <span style="font-size: 15px;"> </span> foo() 関数が返され、コード サイズが削減されます。 <span style="font-size: 15px;"></span>
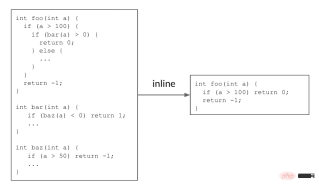 キャプション: インライン化により、冗長なコードが削除され、コード サイズが削減されます。
キャプション: インライン化により、冗長なコードが削除され、コード サイズが削減されます。
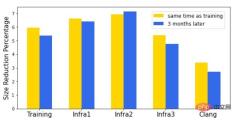
実際のコードでは、何千もの関数が相互に呼び出しているため、コール グラフが形成されます。インライン化フェーズ中に、コンパイラーはすべての呼び出し元と呼び出し先のペアのコール グラフを走査し、呼び出し元と呼び出し先のペアをインライン化するかどうかを決定します。以前のインライン化の決定によってコール グラフが変更され、その後の決定と最終結果に影響を与えるため、これは継続的な意思決定プロセスです。上記の例では、コール グラフ MLGO が登場する前は、インライン/非インラインの決定はヒューリスティックによって行われていましたが、時間の経過とともに改善することがますます困難になってきました。 MLGO はヒューリスティックを機械学習モデルに置き換えます。コール グラフのトラバース中に、コンパイラは、入力グラフ内の関連する機能 (つまり、入力) を介して特定の呼び出し元と呼び出し先のペアをインライン化するかどうかについてニューラル ネットワークの推奨事項を求め、コール グラフ全体が完了するまで決定を順番に実行します。が達成された。 凡例: インライン化プロセス中の MLGO の図、「# bbs」、「# users」、「callsite height」は呼び出し元と呼び出し先のペア機能のインスタンス MLGO は、ポリシー勾配アルゴリズムと進化的ポリシー アルゴリズムを使用してデシジョン ネットワークの RL トレーニングを実行します。最適な決定に関する根拠となる真実はありませんが、オンライン RL は、トレーニングとアセンブリの実行を繰り返すトレーニング済みのポリシーを使用して、データを収集し、ポリシーを改善します。特に、現在トレーニング中のモデルを考慮すると、コンパイラーはインライン化フェーズ中にモデルを参照して、インラインか非インラインかを決定します。コンパイル後、一連の決定プロセス (ステータス、アクション、報酬) のログが生成されます。このログは、モデルを更新するためにトレーナーに渡されます。満足のいくモデルが得られるまで、このプロセスが繰り返されます。 #注: トレーニング中のコンパイラの動作——コンパイラは、ソース コード foo.cpp をオブジェクト ファイルにコンパイルします。 foo.o を作成し、一連の最適化を実行しました。そのうちの 1 つはインライン チャネルでした。 トレーニングされたポリシーはコンパイラに組み込まれており、コンパイル プロセス中にインライン/非インラインの決定を提供します。トレーニング シナリオとは異なり、この戦略ではログは生成されません。 TensorFlow モデルは XLA AOT に埋め込まれており、モデルを実行可能コードに変換します。これにより、TensorFlow の実行時の依存関係とオーバーヘッドが回避され、コンパイル時の ML モデル推論によって生じる追加の時間とメモリのコストが最小限に抑えられます。 #キャプション: 本番環境でのコンパイラの動作 により時間とメモリのオーバーヘッドが 3% ~ 7% 削減されます。 ソフトウェア全体の汎用性に加えて、時間全体の汎用性も重要です。ソフトウェアとコンパイラーの両方が積極的に開発されているため、適切な期間内に良好なパフォーマンスを維持するには、よく訓練された戦略が必要です。 3 か月後に同じソフトウェア セットでモデルのパフォーマンスを評価したところ、わずかな低下しか見つかりませんでした。 凡例: インライン サイズポリシーのサイズ削減率。X 軸はさまざまなソフトウェアを表し、Y 軸は削減率を表します。 「トレーニング」はモデルをトレーニングするソフトウェアであり、「InfraX」は別の内部ソフトウェア パッケージです。 MLGO のインライン サイズ変更トレーニングは、バイナリ サイズが重要な、多様なハードウェアおよびソフトウェア エコシステムを強化するように設計された汎用オープンソース オペレーティング システムである Fuchsia 上にデプロイされています。ここで、MLGO は C 翻訳単位サイズの 6.3% 削減を示しています。 一般的なフレームワークとして、MLGO を使用してレジスタ割り当て (レジスタ割り当て) チャネルを改善し、LLVM でのコードのパフォーマンスを向上させます。レジスタ割り当ては、物理レジスタをアクティブなスコープ (つまり、変数) に割り当てる問題を解決します。 コードが実行されると、さまざまなライブ範囲がさまざまな時点で完了し、後続の処理ステージで使用するためにレジスタが解放されます。次の例では、各「加算」命令と「乗算」命令では、すべてのオペランドと結果が物理レジスタ内にあることが必要です。リアルタイム範囲 x は緑色のレジスタに割り当てられ、青色または黄色のレジスタのリアルタイム範囲より前に完了します。 x が完了すると、緑色のレジスタが使用可能になり、生存範囲 t に割り当てられます。 コードの実行中、さまざまなライブ範囲がさまざまなタイミングで完了し、解放されたレジスタは後続の処理ステージで使用されます。以下の例では、各「加算」および「乗算」命令では、すべてのオペランドと結果が物理レジスタ内に存在する必要があります。アクティブ範囲 x は緑のレジスタに割り当てられ、青または黄色のレジスタのライブ範囲の前に完了します。 x が完了すると、緑色のレジスタが使用可能になり、有効範囲 t に割り当てられます。 # 凡例: レジスタ割り当ての例 アクティブ レンジを割り当てる場合 q いつ、使用可能なレジスタがないため、レジスタ割り当てチャネルは、q のためのスペースを空けるためにどのアクティブ範囲をレジスタから「追い出す」ことができるかを決定する必要があります。これは「フィールドエビクション」問題と呼ばれ、元のヒューリスティックの決定を置き換えるためにモデルをトレーニングする場所です。この例では、黄色のレジスタから z を削除し、それを q と z の前半に割り当てます。 次に、実際の範囲 z の未割り当ての下半分を検討します。別の競合が発生します。今回は、アクティブな範囲 t が削除されて分割され、t の前半と z の最後の部分が緑色のレジスタを使用することになります。 Z の中間部分は命令 q = t * y に対応します。ここで z は使用されないため、どのレジスタにも割り当てられず、その値は黄色のレジスタからスタックに格納され、後で緑色のレジスタに再ロードされます。 。 tでも同じことが起こります。これにより、コードに余分なロード/ストア命令が追加され、パフォーマンスが低下します。レジスタ割り当てアルゴリズムの目標は、この非効率を最小限に抑えることです。これは、RL ポリシー トレーニングをガイドするための報酬として使用されます。 インライン サイズ戦略と同様に、レジスタ割り当て (regalloc-for-Performance) 戦略は Google 内の大規模なソフトウェア パッケージでトレーニングされており、さまざまなソフトウェア間で普遍的に使用できます。 2 番目 (QPS) は、一連の内部大規模データセンター アプリケーションで 0.3% ~ 1.5% 増加しました。 QPS の改善は展開後数か月間持続し、モデルの一般化可能性を実証しました。 MLGO は、強化学習を使用して、意思決定を行うニューラル ネットワークをトレーニングします。これは、複雑なヒューリスティック手法に代わる機械学習戦略です。一般的な産業グレードのフレームワークとして、インライン化やレジスタ割り当てだけでなく、より多くの環境でより深く、より広く使用されるようになるでしょう。 MLGO は次のように開発できます: 1) 機能の追加やより優れた RL アルゴリズムの適用など、より深く; 2) より広範に、インライン化と再配布に適用可能 さらなる最適化ヒューリスティックを超えて。 著者らは、MLGO がコンパイラ最適化の分野にもたらす可能性に熱意を持っており、研究コミュニティからのさらなる採用と将来の貢献を楽しみにしています。 <span style="font-size: 15px;">foo()</span> → <span style="font-size: 15px;">bar()</span> → <span style="font-size: 15px;">baz()</span> コードサイズを削減するには、両側で「はい」の決定を下す必要があります。 



2 レジスタ割り当て

以上がメモリが 3% ~ 7% 削減されました。 Google、コンパイラ最適化のための機械学習フレームワークMLGOを提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 10生成AIコーディング拡張機能とコードのコードを探る必要がありますApr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要がありますApr 13, 2025 am 01:14 AMねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 中国語版
中国語版、とても使いやすい

Dreamweaver Mac版
ビジュアル Web 開発ツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

