
ホームページ >テクノロジー周辺機器 >AI >MiniGPT-4 は、写真を見たり、チャットしたり、Web サイトをスケッチしたり構築したりすることもできます。Stable Diffusion のビデオ バージョンはこちらです。
MiniGPT-4 は、写真を見たり、チャットしたり、Web サイトをスケッチしたり構築したりすることもできます。Stable Diffusion のビデオ バージョンはこちらです。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-28 12:10:181358ブラウズ
#目次
- #潜在力を調整する: 潜在拡散モデルを使用した高解像度ビデオ合成 #MiniGPT-4: 高度な大規模言語モデルによる視覚言語の理解を強化する
- OpenAssistant 会話 - 大規模言語モデルの調整の民主化
- 何でも修復: あらゆるものをセグメント化して画像の修復を実現
- マスクに適応した CLIP を使用したオープンボキャブラリーのセマンティック セグメンテーション
- Plan4MC: オープンワールド Minecraft タスクのスキル強化学習と計画
- T2Ranking: パッセージ ランキングのための大規模な中国ベンチマーク
- ArXiv Weeklyラジオ局: NLP、CV、ML その他の厳選された論文 (音声付き)
論文 1: 潜在力の調整: 潜在拡散モデルによる高解像度ビデオ合成
- 著者: Andreas Blattmann、Robin Rombach 他
- 論文アドレス: https://arxiv.org/pdf/2304.08818.pdf
要約:最近、ミュンヘン大学の研究者、NVIDIA、他の機関が使用している潜在拡散モデル (LDM) により、高解像度の長時間ビデオ合成が可能になります。
論文では、研究者らはビデオ モデルを現実世界の問題に適用し、高解像度の長いビデオを生成しました。彼らは、関連する 2 つのビデオ生成問題に焦点を当てています。1 つは、自動運転環境におけるシミュレーション エンジンとして大きな可能性を秘めた高解像度の実世界の運転データのビデオ合成であり、もう 1 つは、クリエイティブなコンテンツ生成のためのテキストガイド付きビデオ生成です。この目的を達成するために、研究者らはビデオ潜在拡散モデル (ビデオ LDM) を提案し、LDM を計算集約型タスクである高解像度ビデオ生成に拡張しました。以前のビデオ生成 DM 作業とは対照的に、画像に対してのみビデオ LDM を事前トレーニングしました (または、利用可能な事前トレーニング済み画像 LDM を使用しました)。これにより、大規模な画像データセットの利用が可能になりました。
次に、時間次元が潜在空間 DM に導入され、事前にトレーニングされた空間層が固定され、これらの時間層は符号化された画像シーケンス (つまり、ビデオ) 上でのみトレーニングされます。これにより、変換が行われます。 LDM 画像ジェネレーター ビデオジェネレーターに変換します (左下の図)。最後に、LDM のデコーダーが同様の方法で微調整され、ピクセル空間での時間的一貫性が達成されます (下の右の画像)。
推奨事項: ビデオ バージョンの安定した拡散: NVIDIA は最高 1280×2048、最長 4.7 秒を達成します。
論文 2: MiniGPT-4: 高度な大規模言語モデルによる視覚言語理解を強化する
- 著者: Zhu Deyao、Chen Jun、Shen Xiaoqian、Li Xiang、Mohamed H. Elhoseiny
- 論文アドレス: https://minigpt-4。 github .io/
キング・アブドラ科学技術大学 (KAUST) のチームが GPT-4 類似製品を開発しました -ミニGPT-4。 MiniGPT-4 は、詳細な画像説明の生成や手書きの下書きから Web サイトを作成するなど、GPT-4 と同様の多くの機能を示します。さらに、著者らは、与えられた画像に基づいて物語や詩を作成すること、画像に示されている問題に対する解決策を提供すること、食べ物の写真に基づいて料理方法をユーザーに教えることなど、MiniGPT-4 の他の新しい機能を観察しました。 MiniGPT-4 は、投影レイヤーを使用して、フリーズされたビジュアル エンコーダーとフリーズされた LLM (Vicuna) を位置合わせします。 MiniGPT-4 は、事前トレーニング済みの ViT および Q-Former ビジュアル エンコーダー、別個の線形投影レイヤー、および高度な Vicuna 大規模言語モデルで構成されています。 MiniGPT-4 では、視覚的特徴を Vicuna と一致させるために線形レイヤーをトレーニングするだけで済みます。
デモンストレーションの例: スケッチから Web サイトを作成します。

推奨事項: 3 日間でほぼ 10,000 個のスター、違いのない GPT-4 画像認識能力を体験してください。MiniGPT を参照してください。 4 写真でチャットし、スケッチで Web サイトを構築します。
#論文 3: OpenAssistant の会話 - 大規模言語モデルの調整の民主化
- 著者: Andreas Köpf 、ヤニック・キルチャーなど
- 論文アドレス: https://drive.google.com/file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
##要約: 大規模なアライメント研究を民主化するために、LAION AI (Stable diffusion で使用されるオープンソース データを提供する) などの機関の研究者が、大規模な大量のテキストベースの入力とフィードバックが収集されて、言語モデルやその他の AI アプリケーションをトレーニングするために特別に設計された多様でユニークなデータセットである OpenAssistant Conversations が作成されます。
このデータセットは、人間が生成し、人間が注釈を付けたアシスタント スタイルの会話コーパスであり、幅広いトピックと文体をカバーしており、35 の 66,497 会話ツリーに分散された 161,443 のメッセージで構成されています。さまざまな言語。このコーパスは、13,500 人を超えるボランティアが参加する世界的なクラウドソーシングの取り組みの成果です。これは、SOTA 命令モデルを作成しようとしている開発者にとって非常に貴重なツールです。そして、データセット全体には誰でも自由にアクセスできます。さらに、OpenAssistant Conversations データセットの有効性を証明するために、この研究では、タスクを理解し、サードパーティ システムと対話し、情報を動的に取得します。これはおそらく、人間のデータでトレーニングされた初の完全にオープンソースの大規模な命令微調整モデルです。
結果は、OpenAssistant の応答が GPT-3.5-turbo (ChatGPT) よりも人気があることを示しています。
OpenAssistant Conversations データは、Web アプリ インターフェイスを使用して収集されます。これには、プロンプト、プロンプトのマーク、応答メッセージの追加の 5 つのステップが含まれます。プロンプターの場合またはアシスタント、応答をマークし、アシスタントの応答をランク付けします。
推奨: ChatGPT 世界最大のオープンソースの代替品。
論文 4: 何でも修復: セグメントと画像修復の融合
- # 著者: Tao Yu、 Runseng Feng 他
- ## 論文アドレス: http://arxiv.org/abs/2304.06790
- 要約:
IA には 3 つの主な機能があります: (i) 何でも削除: ユーザーは削除したいオブジェクトをクリックするだけで、IA は痕跡を残さずにオブジェクトを削除し、効率的な「魔法の」削除を実現します。 (ii) 何でも入力: 同時に、ユーザーはテキスト プロンプト (テキスト プロンプト) を通じてオブジェクトに何を入力したいかを IA にさらに伝えることができ、IA は埋め込み AIGC (AI 生成コンテンツ) モデル (AI 生成コンテンツなど) を駆動します。安定拡散 [2] として) 対応するコンテンツが埋め込まれたオブジェクトを生成して、自由に「コンテンツ作成」を実現します; (iii) 何でも置換: ユーザーは、保持する必要があるオブジェクトをクリックして選択し、テキスト プロンプトを使用して IA に通知することもできます。オブジェクトの背景を何かに置き換えたい場合は、オブジェクトの背景を指定したコンテンツに置き換えて、鮮やかな「環境変換」を実現できます。 IA の全体的なフレームワークを次の図に示します。 推奨事項: 細かいマークを付ける必要はありません。オブジェクトを削除して、コンテンツの充填とシーンの置換を行います。 論文 5: マスク適応 CLIP を使用したオープンボキャブラリーのセマンティック セグメンテーション 要約: Meta と UTAustin は共同で、新しいオープン言語スタイル モデル (オープン語彙セグメンテーション、OVSeg) を提案しました。これにより、Segment Anything モデルがカテゴリを認識できるようになります。別れる。 効果の観点から見ると、OVSeg を Segment Anything と組み合わせて、きめ細かいオープン言語セグメンテーションを完了できます。たとえば、以下の図 1 では、ひまわり、白いバラ、菊、カーネーション、緑のナデシコなどの花の種類を識別します。 推奨事項: Meta/UTAustin は、新しいオープン クラス セグメンテーション モデルを提案しています。 #論文 6: Plan4MC: オープンワールド Minecraft タスクのスキル強化学習と計画 要約: 北京大学と北京知源人工知能研究所のチームは、専門家データなしで Minecraft のマルチタスクを効率的に解決する方法である Plan4MC を提案しました。著者は強化学習と計画手法を組み合わせて、複雑なタスクの解決を基本スキルの学習とスキル計画の 2 つの部分に分解します。著者らは、内在的報酬強化学習法を使用して、3 種類のきめ細かい基本スキルを訓練します。エージェントは大規模な言語モデルを使用してスキル関係グラフを構築し、グラフ上の検索を通じてタスク計画を取得します。実験部分では、Plan4MC は現在 24 の複雑で多様なタスクを完了でき、すべてのベースライン手法と比較して成功率が大幅に向上しています。 推奨事項: ChatGPT と強化学習を使用して「Minecraft」をプレイすると、Plan4MC は 24 の複雑なタスクを克服します。 論文 7: T2Ranking: パッセージ ランキングのための大規模な中国ベンチマーク 段落の並べ替えは、情報検索の分野において非常に重要かつ困難なトピックであり、多くの注目を集めています。学界と産業界から幅広い注目を集めています。段落ランキング モデルの有効性により、検索エンジンのユーザー満足度が向上し、質疑応答システムや読解などの情報検索関連アプリケーションに役立ちます。これに関連して、MS-MARCO、DuReader_retrieval などのいくつかのベンチマーク データセットは、段落並べ替えに関する関連研究作業をサポートするために構築されました。ただし、一般的に使用されるデータ セットのほとんどは英語のシーンに焦点を当てており、中国語のシーンについては、既存のデータ セットではデータ規模、きめ細かいユーザー アノテーション、および偽陰性例の問題の解決策に制限があります。このような背景を背景に、この研究では実際の検索ログに基づいた新しい中国語段落ランキング ベンチマーク データ セット、T2Ranking を構築しました。 T2Ranking は、300,000 を超える実際のクエリと 200 万のインターネット段落で構成され、プロのアノテーターによって提供される 4 レベルのきめ細かい関連性アノテーションが含まれています。現在のデータといくつかのベースライン モデルは Github で公開されており、関連する研究成果は SIGIR 2023 のリソース ペーパーとして承認されました。 推奨事項: 300,000 の実際のクエリ、200 万のインターネット段落、中国語段落ランキングのベンチマーク データ セットがリリースされました。 ArXiv Weekly Radiostation
1. DSTC9 および DSTC10 用の HLTPR@RWTH によるタスク指向のドキュメントベースのダイアログ システム (Hermann より) Ney)2. トレードオフの探求: 高特異性放射線学の NLI タスクにおける統合大規模言語モデルとローカル微調整モデルの比較 (Wei Liu、Dingang Shen より) 3. アスペクトベースの感情分析の堅牢性について: モデル、データ、トレーニングの再考 (Tat-Seng Chua より) 4 . Stochastic Parrots Looking for Stochastic Parrots : LLMs are Easy to Fine-Tune and Hard to Detect with other LLMs. (Rachid Guerraoui より) 5. Chameleon: プラグアンドプレイ構成大規模言語モデルによる推論 (Kai-Wei Chang、Song-Chun Zhu、Jianfeng Gao より) 6. MER 2023: マルチラベル学習、モダリティの堅牢性、および半教師あり学習. (Meng Wang、Erik Cambria、Guoying Zhao より) 7. GeneGPT: NCBI Web API を使用するための大規模言語モデルの教育. (Zhiyong Lu より) 8 . 事前トレーニング済み言語モデルを使用した生物医学文書の要約に関する調査 (Sophia Ananiadou より) 9. ソーシャル メディアからの精神疾患検出のための感情融合:調査 (Sophia Ananiadou より) #10. 言語モデルにより、異種データ レイクの構造化ビューを生成するためのシンプルなシステムが実現 (Christopher Ré より) this 今週の CV に選ばれた 10 件の論文は次のとおりです: 1. NeuralField-LDM: 階層的潜在拡散モデルによるシーン生成 (Antonio より) Torralba) 2. Align-DETR: Simple IoU-aware BCE loss による DETR の改善 (Xiangyu Zhang より) 3. 探索少数ショット画像生成における互換性のない知識伝達 (Shuicheng Yan より) 4.ビデオ質問応答のための学習状況ハイパーグラフ。 (ムバラク・シャーより) 5.単一クリップを超えたビデオ生成。 (ヤン・ミンシュアンより) 6. Vision Transformer による不均一かすみ除去のデータ中心のソリューション。 (Huan Liuより) 7.ニューロモーフィック オプティカル フローとイベント カメラを使用したリアルタイム実装。 (ルカ・ベニーニ、ダヴィデ・スカラムッツァより) 8.インタラクティブな画像検索のための言語ガイド付きローカル侵入。 (張雷より) 9. LipsFormer: ビジョン トランスフォーマーへの Lipschitz 連続性の導入。 (張雷より) 10. UVA: ビュー合成、ポーズ レンダリング、ジオメトリ、テクスチャ編集のための統合ボリューム アバターに向けて。 (Dacheng Tao より) 本周 10 篇 ML 精选论文是: 1. RL の理論と実践を効果的な視野で橋渡しします。 (スチュアート・ラッセルより) 2.透明性と堅牢性を備えたデータ駆動型の風力タービン出力曲線モデルを目指して。 (クラウス・ロバート・ミュラーより) 3.オープンワールドの継続的学習: 新規性の検出と継続的学習を統合します。 (Bing Liu より) 4.潜在空間での学習により、ディープ ニューラル オペレーターの予測精度が向上します。 (ジョージ・エム・カルニアダキスより) 5.グラフ ニューラル ネットワークの分離: 1 つではなく複数の単純な GNN を同時にトレーニングします。 (李雪龍より) 6.モデルベースのニューラル ネットワークの一般化と推定誤差限界。 (ヨニーナ・C・エルダールより) 7. RAFT: 生成基盤モデルの調整に対するランク付けされた FineTuning に報酬を与えます。 (Tong Zhang より) 8. GAN の適応型コンセンサス最適化手法。 (パワン・クマールより) 9.勾配降下法の角度ベースの動的学習率。 (パワン・クマールより) 10. AGNN: 過剰な平滑化を軽減するための交互グラフ正則化ニューラル ネットワーク。 (郭文忠より)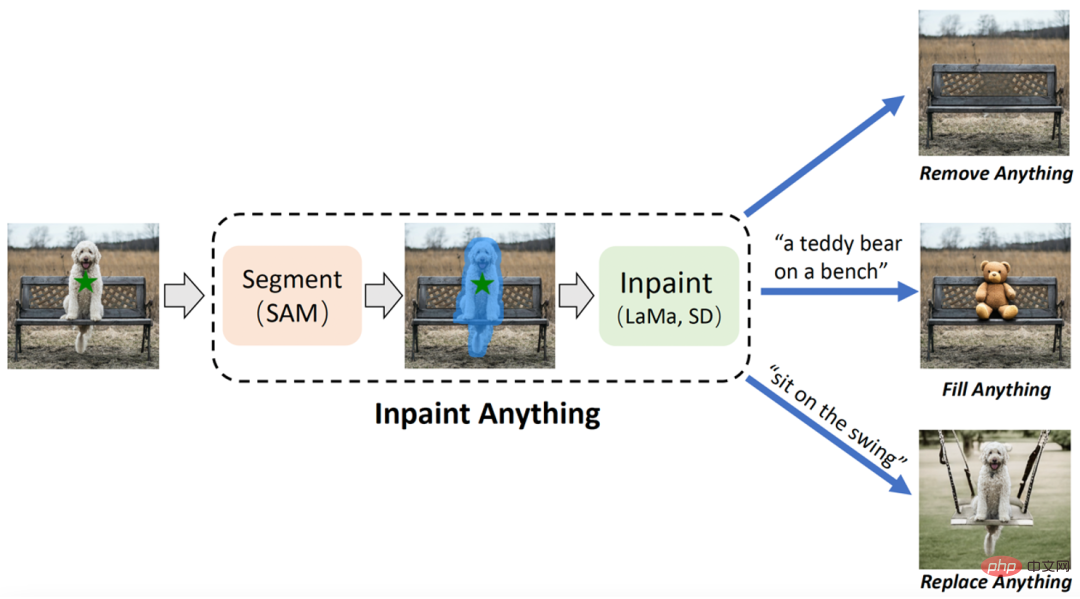


##要約:Heart of Machine は、Chu Hang、Luo Ruotian、Mei Honyuan によって開始された ArXiv Weekly Radiostation と協力しています。7 つの論文に基づいて、このセレクションは詳細です。 NLP、CV、ML の各分野から厳選した 10 件の今週の重要論文と、論文の要約紹介を音声で提供します。今週の
10 論文 選択された NLP 論文は次のとおりです:
以上がMiniGPT-4 は、写真を見たり、チャットしたり、Web サイトをスケッチしたり構築したりすることもできます。Stable Diffusion のビデオ バージョンはこちらです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。