
ホームページ >テクノロジー周辺機器 >AI >コンシューマグレードの GPU は 1,760 億個のパラメータを持つ大規模モデルの実行に成功
コンシューマグレードの GPU は 1,760 億個のパラメータを持つ大規模モデルの実行に成功

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-04-28 12:19:061303ブラウズ
コンシューマ GPU で大規模モデルを実行することは、機械学習コミュニティにとって継続的な課題です。
言語モデルのサイズはますます大きくなっています。PaLM には 540B のパラメータがあり、OPT、GPT-3、BLOOM には約 176B のパラメータがあります。モデルはまだ大きなサイズで移行中です。方向性を開発します。

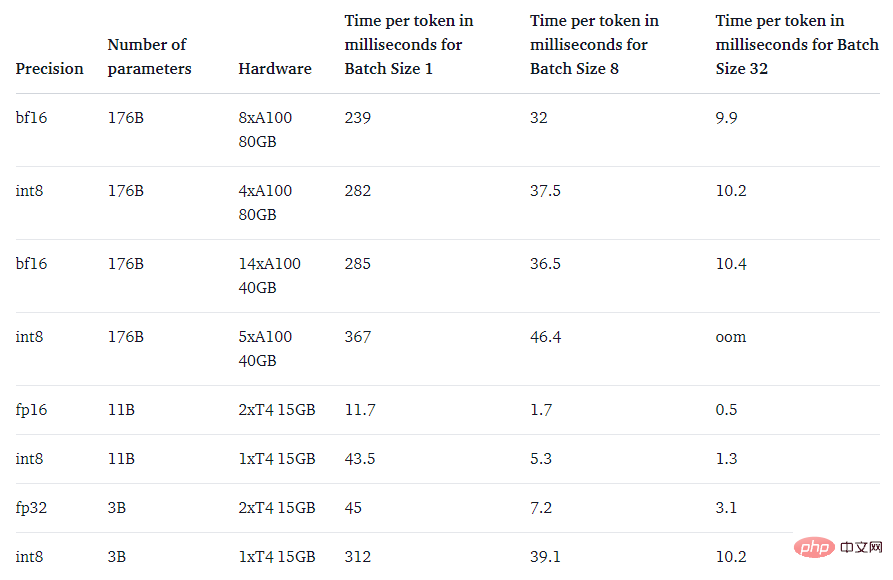
# これらのモデルは、簡単にアクセスできるデバイスで実行するのが困難です。たとえば、BLOOM-176B は推論タスクを完了するために 8 つの 80GB A100 GPU (それぞれ約 15,000 ドル) で実行する必要がありますが、BLOOM-176B を微調整するには 72 個のそのような GPU が必要です。 PaLM などの大きなモデルには、より多くのリソースが必要になります。
モデルのパフォーマンスを維持しながら、これらのモデルのリソース要件を削減する方法を見つける必要があります。この分野では、量子化や蒸留など、モデルのサイズを削減しようとするさまざまな技術が開発されています。
BLOOM は、人工知能スタートアップの Hugging Face がフランス政府の資金で運営する「BigScience」というプロジェクトで、1,000 人以上のボランティア研究者によって昨年作成されました。今年 7 月 12 日に BLOOM モデルはが正式にリリースされました。
Int8 推論を使用すると、モデルのメモリ フットプリントが大幅に削減されますが、モデルの予測パフォーマンスは低下しません。これに基づいて、ワシントン大学、メタ AI 研究所 (旧 Facebook AI 研究所) およびその他の機関の研究者が HuggingFace と共同で研究を実施し、訓練された BLOOM-176B をより少ない GPU で実行できるようにすることを試み、提案された手法が完全に統合されました。ハギングフェイストランスフォーマーに。

- 論文アドレス: https://arxiv.org/pdf/2208.07339.pdf
- Github アドレス: https://github.com/timdettmers/bitsandbytes
この研究では、モデルの推論パフォーマンスに影響を与えない、トランスフォーマーのための最初の 10 億スケールの Int8 量子化プロセスを提案します。 16 ビットまたは 32 ビットの重みを備えた 175B パラメーター トランスフォーマーをロードし、フィードフォワード レイヤーとアテンション プロジェクション レイヤーを 8 ビットに変換できます。完全な精度のパフォーマンスを維持しながら、推論に必要なメモリを半分に削減します。
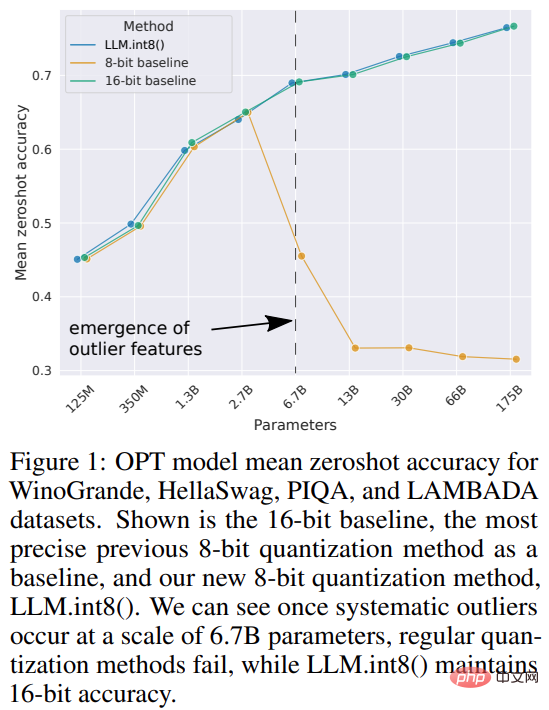
この研究では、ベクトル量子化と混合精度分解の組み合わせを LLM.int8() と名付けました。実験の結果、LLM.int8() を使用することで、パフォーマンスを低下させることなく、コンシューマ GPU 上で最大 175B パラメータの LLM による推論を実行できることがわかりました。このアプローチは、異常値がモデルのパフォーマンスに及ぼす影響に新たな光を当てるだけでなく、OPT-175B/BLOOM などの非常に大規模なモデルを、コンシューマ グレードの GPU を備えた単一サーバー上で使用することを初めて可能にします。
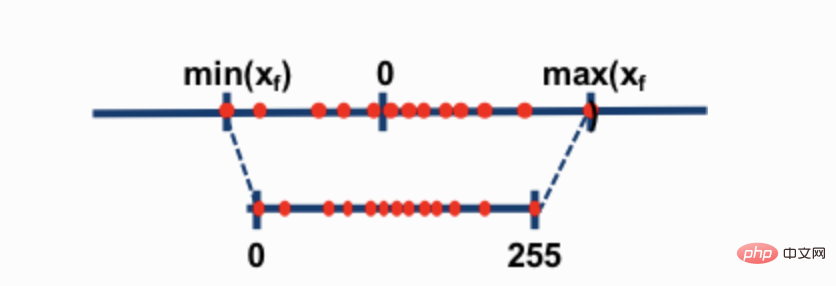
最も一般的な 2 つの 8 ビット量子化手法は、ゼロ点量子化と absmax (絶対最大値) 量子化です。どちらのメソッドも浮動小数点値をよりコンパクトな int8 (1 バイト) 値にマップします。
たとえば、ゼロ点量子化では、データ範囲が -1.0 ~ 1.0 で、-127 ~ 127 に量子化される場合、拡張係数は 127 になります。この拡張係数では、たとえば値 0.3 は 0.3*127 = 38.1 に拡張されます。通常、量子化には丸めが含まれるため、38 になります。これを逆にすると、38/127=0.2992 となり、この例では量子化誤差は 0.008 になります。これらの一見小さなエラーは、モデル層を通じて伝播するにつれて蓄積および増大する傾向があり、パフォーマンスの低下を引き起こします。
これらの手法は深層学習モデルを定量化できますが、多くの場合、モデルの精度が低下します。しかし、Hugging Face Transformers および Accelerate ライブラリに統合されている LLM.int8() は、176B パラメータを持つ大規模なモデル (BLOOM など) であってもパフォーマンスを低下させない最初のテクニックです。
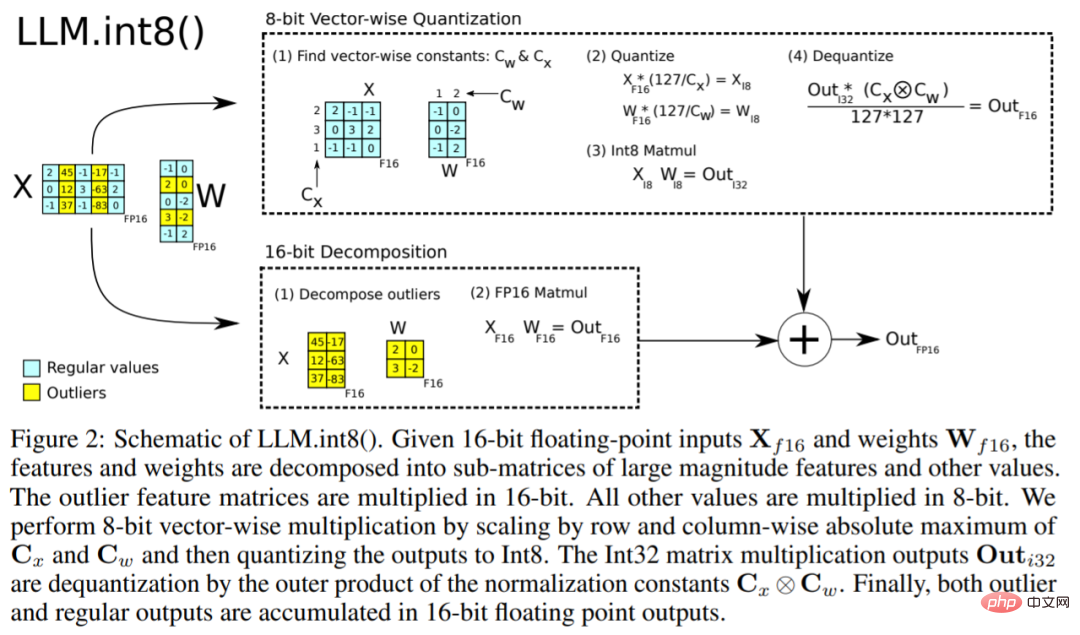
LLM.int8() アルゴリズムは次のように説明できます。本質的に、LLM.int8() は 3 つのステップで行列乗算の計算を完了しようとします。状態、列ごとに外れ値 (つまり、特定のしきい値を超える値) を抽出します。
- FP16 の外れ値と int8 の非外れ値の行列乗算を実行します。
- FP16 で非外れ値を逆量子化し、外れ値と非外れ値を加算して完全な結果を取得します。

 # #####################################
# #####################################
以上がコンシューマグレードの GPU は 1,760 億個のパラメータを持つ大規模モデルの実行に成功の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。