


データはマシンの生命線です。それがなければ、AI に関連するものを構築することはできません。今週発表された Appen の AI および機械学習の現状レポートによると、多くの組織が AI および機械学習の取り組みを維持するための良質でクリーンなデータの取得に依然として苦労しています。
Appen の人工知能に関する調査によると、人工知能の 4 つの段階 (データ調達、データ準備、モデルのトレーニングと展開、人間によるモデルの評価) のうち、データ調達が最も多くのリソースとコストを消費します。 . 最も長く、最も挑戦的なもの。 504 人のビジネスリーダーとテクノロジー専門家。
Harris が実施した Appen の調査によると、組織の AI 予算の平均でデータ調達に 34% が消費され、データの準備とモデルのテストと展開がそれぞれ 24%、モデルの評価が 15% を占めています。この世論調査は、米国、英国、アイルランド、ドイツの IT 意思決定者、ビジネス リーダーやマネージャー、テクノロジー実践者を対象に実施されました。
時間の観点から見ると、データの調達には組織の時間の約 26% が費やされ、データの準備とモデルのテスト、導入、モデルの評価はそれぞれ 24% と 23% を占めます。最後に、技術者の 42% は、モデルの評価 (41%)、モデルのテストと展開 (38%)、データの準備 (34%) と比較して、データ調達が AI ライフサイクルの最も困難な段階であると考えています。
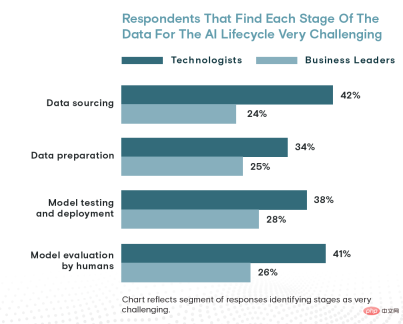
テクノロジーの専門家によると、データの調達は人工知能が直面する最大の課題です。しかし、ビジネス リーダーは物事の見方が異なります...
課題にもかかわらず、組織はそれをうまく機能させています。 Appen 氏によると、回答者の 5 分の 4 (81%) が、AI への取り組みをサポートするのに十分なデータを持っていると確信していると回答しました。おそらくこの成功の鍵は、大多数 (88%) が Appen などの外部 AI トレーニング データ プロバイダーを使用してデータを増強していることです。
ただし、データの正確性には疑問があります。 Appen 氏は、80% 以上のデータ精度を報告した回答者はわずか 20% であることを発見しました。データの精度が 90% 以上であると答えたのはわずか 6% (約 10 人に 1 人) でした。言い換えれば、80% 以上の組織では、5 件に 1 件のデータにエラーが含まれているということになります。
それを念頭に置くと、Appen の調査によると、回答者のほぼ半数 (46%) がデータの正確性は重要であるが、「しかしそれは修正できる」と同意していることは、おそらく驚くべきことではありません。データの精度はそれほど大きなニーズではないと答えた人はわずか 2% でしたが、51% がデータの精度が重要なニーズであることに同意しました。
Appen の CTO Wilson Pang のデータ品質の重要性に関する見解は、データ品質は重要ではないと考える顧客の 48% と一致しているようです。
「データの精度は、AI および ML モデルの成功にとって非常に重要です。質の高いデータにより、モデルの出力が向上し、一貫した処理と意思決定が可能になるからです」とパン氏はレポートで述べています。 「良い結果を達成するには、データセットが正確で、包括的で、スケーラブルでなければなりません。」
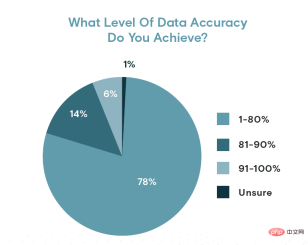
データの精度レベルは、一部の組織が望むほど高くない可能性があります
「回答者の大多数は外部データ プロバイダーを使用しており、データの調達と準備をアウトソーシングすることで、データ サイエンティストはコストを節約していると推測できます。適切な管理、データのクリーニングとラベル付けに必要な時間」とデータラベル付け会社は述べた。
ただし、データのエラー率が比較的高いことから判断すると、おそらく組織はデータの調達および準備プロセス (内部または外部を問わず) を縮小すべきではありません。 AI プロセスの構築と維持に関しては、競合する多くのニーズが存在します。Appen が特定したもう 1 つの上位のニーズは、資格のあるデータ専門家の雇用です。ただし、データ管理が大幅に進歩するまで、組織はデータ品質の重要性を推進し続けるようチームに圧力をかけ続ける必要があります。
この調査では、93% の組織が倫理的 AI が AI プロジェクトの「基盤」であるべきであることに強くまたはある程度同意していることも判明しました。 AppenのCEOマーク・ブレーヤン氏は、良いスタートだったが、やるべきことはまだあると語った。 「問題は、多くの人が貧弱なデータセットで優れたAIを構築しようとするという課題に直面しており、それが目標達成に大きな障害となっているということだ」とブレイアン氏はプレスリリースで述べた。
Appen のレポートによると、AI に使用される組織のデータセットの大部分は依然として社内でカスタム収集されたデータであり、データの 38% から 42% を占めています。合成データは驚くほど好調で、組織のデータの 24% ~ 38% を占めましたが、事前にラベル付けされたデータ (通常はデータ サービス プロバイダーから提供される) がデータの 23% ~ 31% を占めました。
合成データは特に機密性の高い AI プロジェクトにおけるバイアスの発生を減らす可能性があり、Appen の回答者の 97% が「包括的なトレーニング データセットを開発する際に」合成データを使用していると回答しています。
レポートのその他の興味深い調査結果は次のとおりです:
- 組織の 77% が毎月または四半期ごとにモデルを再トレーニングしています;
- 米国組織の 55% は自社が先を行っていると主張しています競合他社、ヨーロッパの 44% と比較;
- 42% の組織が AI の「広範な」展開を報告している (2021 年の人工知能の現状レポートの 51% と比較);
- 7% AI 予算が 500 万ドルを超えていると報告している組織は、昨年は 9% でした。
以上が調査によると、データソースは依然として AI の主なボトルネックとなっているの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

