



この記事の対象読者:
- 大規模なデータ セットに対して Pandas/NumPy 操作を実行したい人。
- Python を使用してビッグ データに対して機械学習タスクを実行したい人。

この記事では、.csv 形式のファイルを使用して、Python のさまざまな操作だけでなく、配列、テキスト ファイルなどの他の形式も示します。
大規模な機械学習データセットにパンダを使用できないのはなぜですか?
Pandas が機械学習データセットを読み込むためにコンピューター メモリ (RAM) を使用することはわかっていますが、コンピューターに 8 GB のメモリ (RAM) がある場合、なぜパンダは依然として 2 GB のデータセット毛織物を読み込むことができないのでしょうか?その理由は、Pandas を使用して 2 GB のファイルを読み込むには、2 GB の RAM だけでなく、より多くのメモリが必要になるためです。合計メモリ要件はデータセットのサイズとそのデータセットに対して実行する操作によって異なるためです。
これは、コンピューター メモリにロードされたさまざまなサイズのデータセットの簡単な比較です:

さらに、Pandas はオペレーティング システムのコアを 1 つだけ使用するため、処理が非常に困難になります。遅い。言い換えれば、pandas は並列処理 (問題を小さなタスクに分割すること) をサポートしていないと言えます。
コンピューターに 4 つのコアがあると仮定して、次の図は CSV ファイルをロードするときに pandas によって使用されるコアの数を示しています。

Pandas は通常、大規模な機械学習を処理するために使用されるデータセットの主な理由は次の 2 点です。1 つはコンピューターのメモリ使用量、もう 1 つは並列処理の欠如です。 NumPy と Scikit-learn では、大規模なデータセットに対して同じ問題に直面します。
これら 2 つの問題を解決するには、Dask と呼ばれる Python ライブラリを使用できます。これにより、大規模なデータ セットに対してパンダ、NumPy、ML などのさまざまな操作を実行できるようになります。
Dask はどのように機能しますか?
Dask はデータセットをパーティションにロードしますが、pandas は通常、機械学習データセット全体をデータフレームとして使用します。 Dask では、データセットの各パーティションは pandas データフレームとみなされます。
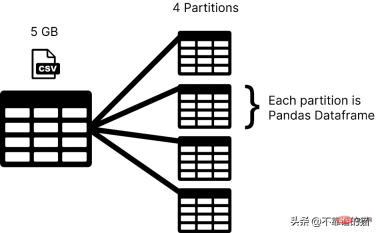
#Dask は一度に 1 つのパーティションをロードするため、メモリ割り当てエラーを心配する必要はありません。
以下は、dask を使用してさまざまなサイズの機械学習データセットをコンピューター メモリに読み込む場合の比較です。
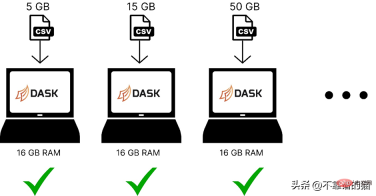
Dask は、並列処理の問題を解決します。データは複数のパーティションに分割され、それぞれが個別のコアを使用するため、データセットの計算が高速化されます。
コンピューターに 4 つのコアがあると仮定して、dask が 5 GB の csv ファイルをロードする方法を次に示します。

dask ライブラリを使用するには、次のコマンドを使用できます。インストールするには:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>
Dask には、dask.array、dask.dataframe、dask.distributed などのいくつかのモジュールがあり、それぞれ NumPy、pandas、Tornado などの対応するライブラリをインストールしている場合にのみ機能します。
dask を使用して大きな CSV ファイルを処理するにはどうすればよいですか?
dask.dataframe は大きな CSV ファイルを処理するために使用されます。最初に、pandas を使用してサイズ 8 GB のデータセットをインポートしようとしました。
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)
私の 16 GB RAM ラップトップでメモリ割り当てエラーが発生しました。
ここで、dask.dataframe を使用して同じ 8 GB データをインポートしてみます。
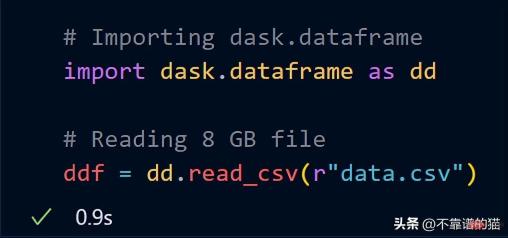
dask は、8 GB ファイル全体を ddf にロードするのにわずか 1 秒かかりました。変数。
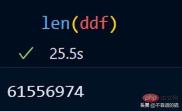
ddf 変数の出力を見てみましょう。

ご覧のとおり、実行時間は 0.5 秒で、119 個のパーティションに分割されていることがわかります。
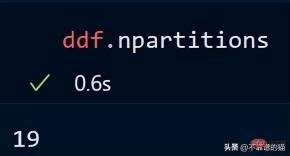
次のコマンドを使用して、データフレームのパーティション数を確認することもできます。
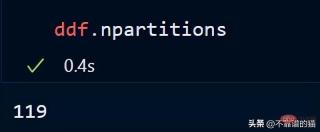
デフォルトでは、dask は 8 GB CSV ファイルを 119 のパーティション (各パーティション) にロードします。サイズは 64MB です)、これは利用可能な物理メモリとコンピューターのコア数に基づいて行われます。
CSV ファイルをロードするときに、blocksize パラメーターを使用して独自のパーティション数を指定することもできます。
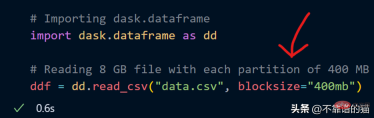


 ##Dask にはサンプル データセットがすでに含まれています。時系列データを使用して、dask がデータセットに対してどのように数学的演算を実行するかを示します。
##Dask にはサンプル データセットがすでに含まれています。時系列データを使用して、dask がデータセットに対してどのように数学的演算を実行するかを示します。
 dask.datasets をインポートした後、ddf_20y は 2000 年 1 月 1 日から 2021 年 12 月 31 日までの時系列データをロードしました。
dask.datasets をインポートした後、ddf_20y は 2000 年 1 月 1 日から 2021 年 12 月 31 日までの時系列データをロードしました。
時系列データのパーティション数を見てみましょう。
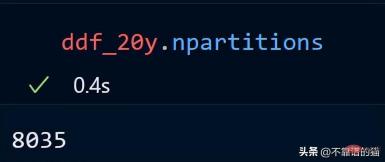 #20 年間の時系列データは 8035 のパーティションに分散されています。
#20 年間の時系列データは 8035 のパーティションに分散されています。
pandas では、head を使用してデータセットの最初の数行を出力します。これは dask にも当てはまります。
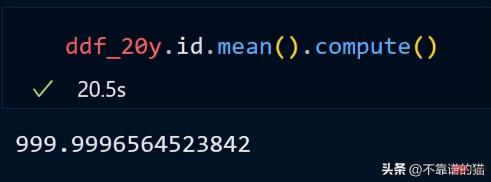
 id 列の平均を計算してみましょう。
id 列の平均を計算してみましょう。
 dask は遅延計算を使用するため、データフレームの合計行数を出力しません (出力は必要になるまで表示されません)。出力を表示するには、compute メソッドを使用します。
dask は遅延計算を使用するため、データフレームの合計行数を出力しません (出力は必要になるまで表示されません)。出力を表示するには、compute メソッドを使用します。
 データセットの各列を正規化する (値を 0 から 1 の間に変換する) と仮定すると、Python コードは次のとおりです。
データセットの各列を正規化する (値を 0 から 1 の間に変換する) と仮定すると、Python コードは次のとおりです。
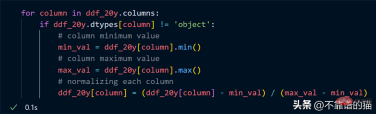 列をループし、各列の最小値と最大値を見つけ、単純な数式を使用して列を正規化します。
列をループし、各列の最小値と最大値を見つけ、単純な数式を使用して列を正規化します。
キーポイント: 正規化の例では、実際の数値計算が行われるとは考えないでください。これは単なる遅延評価です (必要になるまで出力は表示されません)。
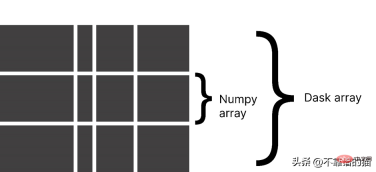
Dask 配列を使用する理由
Dask は配列を小さなチャンクに分割します。各チャンクは NumPy 配列です。
 dask.arrays は、大きな配列を処理するために使用されます。次の Python コードでは、dask を使用して 10000 x 10000 の配列を作成し、それを x 変数に格納します。
dask.arrays は、大きな配列を処理するために使用されます。次の Python コードでは、dask を使用して 10000 x 10000 の配列を作成し、それを x 変数に格納します。
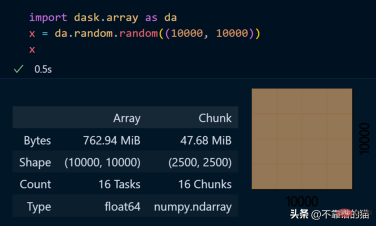 x 変数を呼び出すと、配列に関するさまざまな情報が生成されます。
x 変数を呼び出すと、配列に関するさまざまな情報が生成されます。
配列の特定の要素を表示する
 dask 配列に対して数学演算を実行する Python の例:
dask 配列に対して数学演算を実行する Python の例:
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
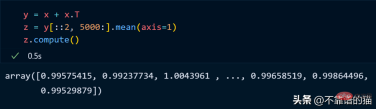
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据

让我们取数据集的一个子集并计算该子集的总行数。
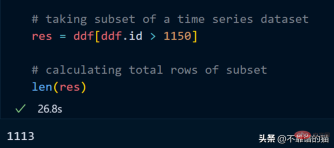
计算总行数需要 27 秒。
我们现在使用 persist 方法:

持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
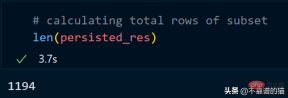
同样,我们可以对持久化数据集执行其他操作以减少计算时间。

persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。

正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
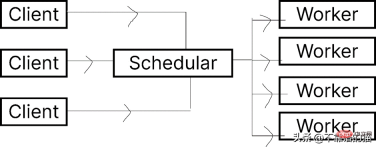
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群

如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
Grid_Search メソッドを使用すると仮定すると、通常は次の Python コードを使用します。
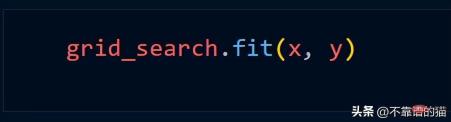
dask.distributed を使用してクラスターを作成します。

クラスターを使用して scikit-learn モデルを適合させるには、joblib を使用するだけで済みます。

以上がPython で大規模な機械学習データセットを処理する簡単な方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 10生成AIコーディング拡張機能とコードのコードを探る必要がありますApr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要がありますApr 13, 2025 am 01:14 AMねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

Dreamweaver Mac版
ビジュアル Web 開発ツール

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

