



検索システムの基礎となる検索想起は、効果向上の上限を決定します。既存の大規模リコール結果に差別化された増分価値をもたらし続ける方法は、私たちが直面している主な課題です。マルチモーダルな事前トレーニングとリコールの組み合わせは、私たちに新たな地平を切り開き、オンライン効果に大幅な改善をもたらします。
まえがき
マルチモーダル事前トレーニングは、学界と産業界での研究の焦点です。異なるモダリティ間の意味論的な対応により、視覚的な質問応答、視覚的な推論、画像とテキストの検索など、さまざまな下流タスクのパフォーマンスを向上させることができます。 グループ内では、マルチモーダル事前トレーニングの研究と応用も行っています。 淘宝網のメイン検索シナリオでは、ユーザーが入力したクエリとリコール対象の商品との間に自然なクロスモーダル検索要件がありますが、以前はさらに多くのタイトルが存在していました。商品には統計的特徴が使用され、画像などのより直感的な情報は無視されました。 しかし、視覚的要素を含む一部のクエリ (白いドレス、花柄のドレスなど) では、誰もが検索結果ページの最初の画像に魅了されると思います。


▐ 技術的な問題と解決策
概要検索およびリコールのシナリオにマルチモーダル テクノロジを適用する場合、解決する必要がある主な問題が 2 つあります:- マルチモーダル グラフィックおよびテキストの事前トレーニング モデルは、通常、画像とテキストのモダリティを統合します。メイン検索にはクエリの存在があり、製品画像とタイトルの元の画像とテキスト モダリティに基づいて、追加のテキスト モダリティを考慮する必要があります。同時に、クエリと製品タイトルの間には意味上のギャップがあり、クエリは比較的短く幅広いものですが、製品タイトルは販売者が SEO を行うため、長くキーワードが詰め込まれていることがよくあります。
- 通常、事前トレーニング タスクとダウンストリーム タスクの関係は、事前トレーニングでは大規模なラベルなしデータが使用され、ダウンストリームでは少量のラベル付きデータが使用されます。しかし、メインの検索とリコールでは、下流のベクトル リコール タスクの規模は膨大で、データは数十億に達しますが、GPU リソースが限られているため、事前トレーニングで使用できるデータは比較的少量のみです。この場合、事前トレーニングが下流のタスクにもメリットをもたらすかどうか。
私たちの解決策は次のとおりです:
- Text-Graphic Pre-training : クエリと製品アイテムをそれぞれエンコーダに渡し、それらをツインタワーステートエンコーダーとしてのクロスモデル。クエリ タワーとアイテム タワーを見ると、2 ストリーム モデルと同様に、後の段階で相互作用しますが、特にアイテム タワーを見ると、画像とタイトルの 2 つのモードが初期段階で相互作用します。シングルストリームモデル。したがって、私たちのモデル構造は、一般的なシングルストリーム構造やデュアルストリーム構造とは異なります。この設計の開始点は、クエリ ベクトルとアイテム ベクトルをより効果的に抽出し、下流のツインタワー ベクトル再現モデルに入力を提供し、事前トレーニング段階でツインタワー内積モデリング手法を導入することです。クエリとタイトルの間のセマンティックな接続とギャップをモデル化するために、クエリとアイテムのツインタワーのエンコーダーを共有し、言語モデルを個別に学習します。
- 事前トレーニングとリコールタスク間のリンク : サンプル構築方法と下流の損失を考慮して設計ベクトルリコールタスク 事前学習段階のタスクとモデリング方法について説明します。一般的な画像とテキストのマッチング タスクとは異なり、クエリとアイテムのマッチング タスクとクエリと画像のマッチング タスクを使用し、クエリで最もクリック数の多かったアイテムをポジティブ サンプルとして使用し、バッチ内の他のサンプルをネガティブ サンプルとして使用します。クエリとアイテムのツインタワー、内積の方法でモデル化された複数分類タスク。この設計の出発点は、事前トレーニングをベクトル呼び出しタスクに近づけ、限られたリソースの下で可能な限り下流のタスクに効果的な入力を提供することです。さらに、ベクトルリコールタスクでは、トレーニングプロセス中にトレーニング前の入力ベクトルが固定されている場合、大規模なデータに対して効果的に調整することができないため、ベクトル内のトレーニング前の入力ベクトルもモデル化しました。タスクのリコール、トレーニング ベクトルの更新。
#事前トレーニング済みモデル
▐ モデリング方法
マルチモーダル事前トレーニング モデルでは、画像から特徴を抽出し、テキスト特徴と融合する必要があります。画像から特徴を抽出するには主に 3 つの方法があります。CV フィールドでトレーニングされたモデルを使用して、画像の RoI 特徴、グリッド特徴、およびパッチ特徴を抽出します。モデル構造の観点から見ると、画像特徴とテキスト特徴の異なる融合方法に応じて、シングルストリーム モデルとデュアルストリーム モデルの 2 つの主なタイプがあります。シングルストリーム モデルでは、画像特徴とテキスト特徴が初期段階で結合されて Encoder に入力されますが、デュアル ストリーム モデルでは、画像特徴とテキスト特徴がそれぞれ 2 つの独立した Encoder に入力され、その後、処理のためにクロスモーダル エンコーダーに入力します。▐ 最初の調査
画像の特徴を抽出する方法は次のとおりです: 画像を分割します。パッチ シーケンスについては、ResNet を使用して各パッチの画像特徴を抽出します。モデル構造としては、Query、title、imageをつなぎ合わせてEncoderに入力するというシングルストリーム構造を試してみました。複数セットの実験の後、この構造の下では、下流のツインタワー ベクトル呼び出しタスクの入力として純粋な Query ベクトルとアイテム ベクトルを抽出するのが難しいことがわかりました。特定のベクトルを抽出するときに不要なモードをマスクすると、予測がトレーニングと矛盾します。この問題は、対話型モデルからツインタワー モデルを直接抽出することに似ていますが、私たちの経験によれば、このモデルは学習済みのツインタワー モデルほど効果的ではありません。これに基づいて、新しいモデル構造を提案します。#▐ モデル構造
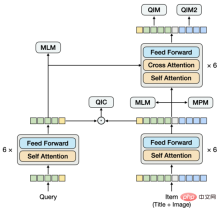 ##デュアルフロー構造と同様に、モデルの下部はツインタワーで構成され、上部はクロスモーダルエンコーダを介してツインタワーと統合されています。デュアルストリーム構造とは異なり、ツインタワーは単一のモードで構成されていません。アイテムタワーにはタイトルと画像のデュアルモードが含まれています。タイトルと画像は結合されてエンコーダに入力されます。この部分は、シングルストリームモデル。クエリとタイトルの間の意味関係とギャップをモデル化するために、クエリとアイテムのツインタワーのエンコーダーを共有し、言語モデルを個別に学習します。
##デュアルフロー構造と同様に、モデルの下部はツインタワーで構成され、上部はクロスモーダルエンコーダを介してツインタワーと統合されています。デュアルストリーム構造とは異なり、ツインタワーは単一のモードで構成されていません。アイテムタワーにはタイトルと画像のデュアルモードが含まれています。タイトルと画像は結合されてエンコーダに入力されます。この部分は、シングルストリームモデル。クエリとタイトルの間の意味関係とギャップをモデル化するために、クエリとアイテムのツインタワーのエンコーダーを共有し、言語モデルを個別に学習します。
▐ 事前トレーニング タスク
- マスク言語モデリング (MLM): テキスト内Token 、15% をランダムにマスクし、残りのテキストと画像を使用してマスクされたテキスト トークンを予測します。クエリとタイトルには、それぞれ MLM タスクがあります。 MLM はクロスエントロピー損失を最小限に抑えます:
 ここで # は残りのテキスト トークンを表します
ここで # は残りのテキスト トークンを表します
- マスクされたパッチ モデリング (MPM): 画像内パッチ トークンの 25% はランダムにマスクされ、残りの画像とテキストはマスクされた画像トークンを予測するために使用されます。 MPM は KL 発散損失を最小限に抑えます: ここで # は残りのイメージ トークンを表します
-
クエリ項目分類 (QIC): クエリの下で最もクリック数が多かったアイテムが正のサンプルとして使用され、バッチ内の他のサンプルが負のサンプルとして使用されます。 QIC は、線形レイヤーを通じてクエリ タワーとアイテム タワー [CLS] トークンの次元を 256 次元に削減し、類似度計算を実行して予測確率を取得し、クロス エントロピー ロスを最小限に抑えます。 はさまざまな方法で計算できます:
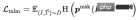
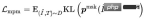
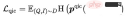
 はさまざまな方法で計算できます:
はさまざまな方法で計算できます:
 このうち、
このうち、
は類似度計算を表し、 は温度ハイパーパラメータを表し、 と mそれぞれ、スケーリング係数と緩和係数を表しますクエリ アイテム マッチング (QIM): クエリの下で最もクリック数が多かったアイテムがポジティブ サンプルとして使用され、バッチ内のその他のアイテムはポジティブ サンプルとして使用されます。現在のクエリに最も類似したものがネガティブ サンプルとして使用されます。 QIM はクロスモーダル エンコーダーの [CLS] トークンを使用して予測確率を計算し、クロス エントロピー損失を最小限に抑えます:
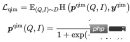
クエリ画像マッチング (QIM2): QIM サンプルでは、マスクはタイトルを削除して、クエリと画像の間のマッチングを強化します。 QIM2 はクロスエントロピー損失を最小限に抑えます:
モデルのトレーニング目標は、全体的な損失を最小限に抑えることです: 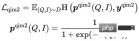
これらの 5 つのプレでは、 -条件 トレーニング タスクでは、MLM タスクと MPM タスクがアイテム タワーの上に配置され、タイトルまたは画像のトークンの一部がマスクされた後にクロスモーダル情報を使用して相互に回復する機能をモデル化します。クエリタワーの上には独立したMLMタスクがあり、クエリタワーとアイテムタワーのエンコーダを共有することで、クエリとタイトルの意味関係やギャップがモデル化されます。 QIC タスクは、2 つのタワーの内積を使用して、事前トレーニング タスクと下流ベクトル呼び出しタスクをある程度調整し、AM-Softmax を使用して、クエリの表現とクエリで最もクリックされたアイテムの表現との間の距離を縮めます。 、クエリと最もクリックされたアイテムの間の距離、その他のアイテムの距離を押しのけます。 QIM タスクはクロスモーダル エンコーダーの上に位置し、クロスモーダル情報を使用してクエリとアイテムの一致をモデル化します。計算量の都合上、通常のNSPタスクの陽性サンプルと陰性サンプルの比率は1:1ですが、さらに陽性サンプルと陰性サンプルの距離を広げるために、QICの類似度計算結果をもとに困難な陰性サンプルを構築します。タスク。 QIM2 タスクは QIM タスクと同じ位置にあり、テキストに関連して画像によってもたらされる増分情報を明示的にモデル化します。
#ベクトル再現モデル
▐
モデリング手法大規模な情報検索システムでは、想起モデルが最下位にあり、大量の候補セットでスコアを付ける必要があります。パフォーマンス上の理由から、ユーザーとアイテムのツイン タワーの構造は、ベクトルの内積を計算するためによく使用されます。ベクトル再現モデルの中心的な問題は、正および負のサンプルをどのように構築するか、および負のサンプルのサンプリングの規模です。私たちの解決策は、ページ上のアイテムに対するユーザーのクリックを肯定的なサンプルとして使用し、製品プール全体のクリック分布に基づいて数万の否定的なサンプルをサンプリングし、サンプリングされたソフトマックス損失を使用してサンプリング サンプルから次のことを推定することです。アイテムは完全な製品プールにあります。クリック確率は です。

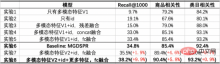
は類似度の計算を表し、 は温度を表しますハイパーパラメータ 一般的な FineTune パラダイムに従って、事前トレーニングされたデータを変換しようとしました。ベクトルをツイン タワー MLP に直接入力し、大規模なネガティブ サンプリングとサンプル ソフトマックスと組み合わせて、マルチモーダル ベクトル再現モデルをトレーニングします。ただし、通常の小規模な下流タスクとは対照的に、ベクトル再現タスクのトレーニング サンプル サイズは数十億のオーダーと巨大です。 MLP のパラメーター量ではモデルのトレーニングをサポートできず、すぐに独自の収束状態に達しますが、その効果は良好ではないことが観察されました。同時に、事前トレーニングされたベクトルはベクトル再現モデルのパラメーターではなく入力として使用され、トレーニングの進行につれて更新することはできません。その結果、比較的小規模なデータに関する事前トレーニングは、大規模なデータに関する下流のタスクと競合します。 解決策はいくつかありますが、事前学習モデルをベクトル再現モデルに統合する方法がありますが、事前学習モデルのパラメータ数が多すぎるため、サンプルサイズが大きくなり、ベクトル再現モデルでは、ベクトル再現モデルでは使用できませんが、限られたリソースの制約の下では、合理的な時間内で定期的なトレーニングを実行する必要があります。もう 1 つの方法は、ベクトル再現モデルでパラメータ行列を構築し、事前トレーニングされたベクトルを行列にロードし、トレーニングの進行に応じて行列のパラメータを更新することです。調査した結果、この方法は工学的な実装の観点から比較的高価であることがわかりました。これに基づいて、事前トレーニングベクトルの更新を簡単かつ実現可能にモデル化するモデル構造を提案します。 始めましょうFC を使用して事前トレーニング ベクトルの次元数を削減します。事前トレーニングではなくここで次元数を削減する理由は、現在の高次元ベクトルが依然として負のサンプル サンプリングの許容可能なパフォーマンス範囲内にあるためです。この場合, ベクトル想起タスクの次元削減は、トレーニング目標とより一致します。同時に、クエリとアイテムの ID 埋め込み行列を導入し、埋め込み次元は縮小された事前トレーニング ベクトルの次元と一致し、ID と事前トレーニング ベクトルがマージされます。この設計の開始点は、大規模なトレーニング データをサポートするのに十分な量のパラメーターを導入すると同時に、トレーニングの進行に応じて事前トレーニング ベクトルを適応的に更新できるようにすることです。 ID ベクトルと事前トレーニング ベクターのみを使用して融合すると、モデルの効果は事前トレーニング ベクターのみを使用したツインタワー MLP の効果を超えるだけでなく、ベースライン モデル MGDSPR も超えます。より多くの機能が含まれています。さらに、これに基づいてさらに多くの機能を導入すると、効果がさらに向上します。 Recall@K : 評価データ セットは、トレーニング セットの翌日のデータで構成されています。まず、さまざまなクリックとトランザクションの結果です。同じクエリ内のユーザーを ベクトル再現モデルの場合、Recall@K が一定レベルまで増加した後は、Query とItem の間の相関にも注意する必要があります。関連性の低いモデルは、たとえ検索効率を向上させることができたとしても、ユーザー エクスペリエンスの低下や、悪いケースの増加による苦情や世論の増加にも直面することになります。 オンライン相関モデルと一致するオフライン モデルを使用して、クエリと項目の間、およびクエリと項目カテゴリの間の相関を評価します。 いくつかのカテゴリから 1 つを選択します10億レベルの製品プールが構築され、事前トレーニングデータセットが構築されます。 私たちのベースライン モデルは、QIM および QIM2 タスクを追加して最適化された FashionBert です。クエリ ベクトルとアイテム ベクトルを抽出するときは、非パディング トークンに対してのみ平均プーリングを使用します。次の実験では、単一のタワーと比較して 2 つのタワーを使用したモデリングによってもたらされる利点を調査し、アブレーション実験を通じて主要な部品の役割を示します。 これらの実験から、次の結論を導き出すことができます: 10 億レベルのクリックされたページを選択しますベクトルリコールデータセットを構築します。各ページにはポジティブ サンプルとして 3 つのクリック項目が含まれており、クリック分布に基づいて製品プールから 10,000 のネガティブ サンプルがサンプリングされます。これに基づいて、トレーニング データの量をさらに拡大したり、ネガティブ サンプルのサンプリングを行ったりしても、効果の顕著な改善は観察されませんでした。 私たちのベースライン モデルは、メイン検索の MGDSPR モデルです。以下の実験では、ベースラインに対するベクトル再現とマルチモーダル事前トレーニングを組み合わせることによってもたらされる利益を調査し、アブレーション実験を通じて主要な部分の役割を示します。 これらの実験から、次の結論を導き出すことができます: ベクトル再現モデルの上位 1000 件の結果のうち、オンライン システムが再現できた項目をフィルタリングして除外したところ、残りの増分結果の相関関係は基本的に次のとおりであることがわかりました。変更なし。多数のクエリの下では、これらの増分結果が製品のタイトルを超えた画像情報をキャプチャし、クエリとタイトルの間の意味上のギャップにおいて一定の役割を果たしていることがわかります。 #クエリ: ハンサムなスーツ メインの検索シナリオのアプリケーション要件に応えて、クエリとアイテムのツインタワー入力を使用したテキスト画像の事前トレーニング モデルを提案しました。クロスモーダル エンコーダ: アイテム タワーがマルチモーダル グラフィックスとテキストを含む単一フロー モデルである構造。 Query-Item と Query-Image のマッチング タスク、および Query と Items のツインタワーの内積によってモデル化された Query-Item 多分類タスクにより、事前トレーニングが下流のベクトル想起タスクに近づくようになります。同時に、事前トレーニングされたベクトルの更新はベクトルリコールでモデル化されます。リソースが限られている場合でも、比較的少量のデータを使用した事前トレーニングでも、大量のデータを使用する下流タスクのパフォーマンスを向上させることができます。 製品の理解、関連性、並べ替えなどの主要な検索の他のシナリオでも、マルチモーダル テクノロジを適用する必要があります。私たちはこれらのシナリオの調査にも参加しており、マルチモーダルテクノロジーが将来的にはますます多くのシナリオにメリットをもたらすと信じています。 淘宝網メイン検索リコール チーム: このチームは、メイン検索リンク内のリンクのリコールと大まかな並べ替えを担当しており、現在の主な技術的方向性は次のとおりです。全空間サンプルの多目的パーソナライズされたベクトル想起、大規模な事前トレーニングに基づくマルチモーダル想起、対照学習に基づく同様のクエリ意味書き換え、および粗いランキングモデルなど。 ▐ 最初の調査
▐ モデル構造

実験分析
##▐ 評価指標
事前トレーニング済みモデルの効果は通常、下流タスクの指標を使用して評価され、別個の評価指標が使用されることはほとんどありません。ただし、この方法では、モデルのバージョンの各反復で、対応するベクトル想起タスクをトレーニングし、次にベクトル想起タスクの指標を評価する必要があるため、事前トレーニングされたモデルの反復コストは比較的高くなります。プロセス全体が非常に長くなります。事前トレーニングされたモデルのみを評価するための効果的な指標はありますか?最初にいくつかの論文で Rank@K を試しました. この指標は主に画像とテキストのマッチング タスクを評価するために使用されます: 最初に事前トレーニングされたモデルを使用して人工的に構築された候補セットをスコア付けし、次に に従ってソートされた上位 K の結果を計算します。画像とテキストにヒットするスコア。一致する陽性サンプルの割合。 Rank@K をクエリ項目マッチング タスクに直接適用したところ、結果が期待と一致しないことがわかりました。Rank@K を使用したより優れた事前トレーニング モデルは、下流のベクトル再現モデルでより悪い結果を達成する可能性があり、事前にガイドすることができません。トレーニング: モデルのトレーニングの反復。これに基づいて、事前トレーニング モデルの評価とベクトル再現モデルの評価を統合し、同じ評価指標とプロセスを使用することで、事前トレーニング モデルの反復を比較的効果的に導くことができます。
 に集約し、モデルによって予測される上位 K の結果の割合を計算します。hit:
に集約し、モデルによって予測される上位 K の結果の割合を計算します。hit:
▐ 事前トレーニング実験

▐ ベクトルリコール実験

概要と展望
チーム紹介
以上が淘宝網の主な検索リコールシナリオにおけるマルチモーダルテクノロジーの探求の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIセラピストがここにいます:あなたが知る必要がある14の画期的なメンタルヘルスツールApr 30, 2025 am 11:17 AM
AIセラピストがここにいます:あなたが知る必要がある14の画期的なメンタルヘルスツールApr 30, 2025 am 11:17 AM訓練を受けたセラピストの人間のつながりと直観を提供することはできませんが、多くの人々は、比較的顔のない匿名のAIボットと心配や懸念を共有することを快適に共有していることが研究で示されています。 これが常に良いかどうか
 食料品の通路にAIを呼びますApr 30, 2025 am 11:16 AM
食料品の通路にAIを呼びますApr 30, 2025 am 11:16 AM数十年の技術である人工知能(AI)は、食品小売業界に革命をもたらしています。 大規模な効率性の向上とコスト削減から、さまざまなビジネス機能にわたる合理化されたプロセスまで、AIの影響はUndeniablです
 あなたの精神を持ち上げるために生成的なAIからPEPの話をするApr 30, 2025 am 11:15 AM
あなたの精神を持ち上げるために生成的なAIからPEPの話をするApr 30, 2025 am 11:15 AMそれについて話しましょう。 革新的なAIブレークスルーのこの分析は、さまざまなインパクトのあるAIの複雑さを特定して説明するなど、最新のAIで進行中のForbes列のカバレッジの一部です(こちらのリンクを参照)。さらに、私のコンプのために
 AI駆動のハイパーパーソナリゼーションがすべてのビジネスにとって必須である理由Apr 30, 2025 am 11:14 AM
AI駆動のハイパーパーソナリゼーションがすべてのビジネスにとって必須である理由Apr 30, 2025 am 11:14 AMプロの画像を維持するには、時折ワードローブの更新が必要です。 オンラインショッピングは便利ですが、対面の試練の確実性がありません。 私の解決策? AI駆動のパーソナライズ。 衣類の選択をキュレーションするAIアシスタントが想像しています
 Duolingoを忘れてください:Google Translateの新しいAI機能は言語を教えていますApr 30, 2025 am 11:13 AM
Duolingoを忘れてください:Google Translateの新しいAI機能は言語を教えていますApr 30, 2025 am 11:13 AMGoogle Translateは言語学習機能を追加します Android Authorityによると、App Expert AssemberBugは、Google Translateアプリの最新バージョンには、パーソナライズされたアクティビティを通じてユーザーが言語スキルを向上させるように設計された新しい「実践」モードのテストコードが含まれていることを発見しました。この機能は現在、ユーザーには見えませんが、AssembleDebugはそれを部分的にアクティブにして、新しいユーザーインターフェイス要素の一部を表示できます。 アクティブ化すると、この機能は、「ベータ」バッジでマークされた画面の下部に新しい卒業キャップアイコンを追加し、「実践」機能が最初に実験形式でリリースされることを示します。 関連するポップアッププロンプトは、「あなたのために調整されたアクティビティを練習してください!」を示しています。つまり、Googleがカスタマイズされたことを意味します
 彼らはAIのためにTCP/IPを作成しており、Nandaと呼ばれていますApr 30, 2025 am 11:12 AM
彼らはAIのためにTCP/IPを作成しており、Nandaと呼ばれていますApr 30, 2025 am 11:12 AMMITの研究者は、AIエージェント向けに設計された画期的なWebプロトコルであるNandaを開発しています。 ネットワークエージェントと分散型AIの略であるNandaは、インターネット機能を追加することにより、人類のモデルコンテキストプロトコル(MCP)に基づいて構築され、AI Agenを可能にします
 プロンプト:Deepfake Detectionは活況を呈しているビジネスですApr 30, 2025 am 11:11 AM
プロンプト:Deepfake Detectionは活況を呈しているビジネスですApr 30, 2025 am 11:11 AMメタの最新のベンチャー:chatgptに匹敵するAIアプリ Facebook、Instagram、WhatsApp、およびThreadsの親会社であるMetaは、新しいAIを搭載したアプリケーションを立ち上げています。 このスタンドアロンアプリであるMeta AIは、OpenaiのChatGptと直接競争することを目指しています。 レバー
 ビジネスリーダーのためのAIサイバーセキュリティでの次の2年間Apr 30, 2025 am 11:10 AM
ビジネスリーダーのためのAIサイバーセキュリティでの次の2年間Apr 30, 2025 am 11:10 AMAIサイバー攻撃の上昇する潮をナビゲートします 最近、人類のためのCISOであるジェイソン・クリントンは、機械間通信が増殖すると、これらの「アイデンティティ」を保護するために、非人間のアイデンティティに結びついた新たなリスクを強調しました。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。
ホットトピック
 7870
7870 15164914140752130125124429
15164914140752130125124429