
ホームページ >バックエンド開発 >Python チュートリアル >Python を使用して KNN 分類アルゴリズムを処理する
Python を使用して KNN 分類アルゴリズムを処理する

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2022-09-07 14:09:551871ブラウズ

【相关推荐:Python3视频教程 】
KNN分类算法的介绍
KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法。
他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本“距离”最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类。简单的说就是让最相似的K个样本来投票决定。
这里所说的距离,一般最常用的就是多维空间的欧式距离。这里的维度指特征维度,即样本有几个特征就属于几维。
KNN示意图如下所示。(图片来源:百度百科)
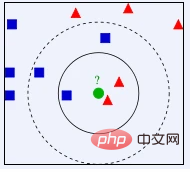
上图中要确定测试样本绿色属于蓝色还是红色。
显然,当K=3时,将以1:2的投票结果分类于红色;而K=5时,将以3:2的投票结果分类于蓝色。
KNN算法简单有效,但没有优化的暴力法效率容易达到瓶颈。如样本个数为N,特征维度为D的时候,该算法时间复杂度呈O(DN)增长。
所以通常KNN的实现会把训练数据构建成K-D Tree(K-dimensional tree),构建过程很快,甚至不用计算D维欧氏距离,而搜索速度高达O(D*log(N))。
不过当D维度过高,会产生所谓的”维度灾难“,最终效率会降低到与暴力法一样。
因此通常D>20以后,最好使用更高效率的Ball-Tree,其时间复杂度为O(D*log(N))。
人们经过长期的实践发现KNN算法虽然简单,但能处理大规模的数据分类,尤其适用于样本分类边界不规则的情况。最重要的是该算法是很多高级机器学习算法的基础。
当然,KNN算法也存在一切问题。比如如果训练数据大部分都属于某一类,投票算法就有很大问题了。这时候就需要考虑设计每个投票者票的权重了。
测试数据
测试数据的格式仍然和前面使用的身高体重数据一致。不过数据稍微增加了一些
1.5 40 thin 1.5 50 fat 1.5 60 fat 1.6 40 thin 1.6 50 thin 1.6 60 fat 1.6 70 fat 1.7 50 thin 1.7 60 thin 1.7 70 fat 1.7 80 fat 1.8 60 thin 1.8 70 thin 1.8 80 fat 1.8 90 fat 1.9 80 thin 1.9 90 fat
Python代码实现
scikit-learn提供了优秀的KNN算法支持。
import numpy as np
from sklearn import neighbors
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
import matplotlib.pyplot as plt
''' 数据读入 '''
data = []
labels = []
with open("data\\1.txt") as ifile:
for line in ifile:
tokens = line.strip().split(' ')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
x = np.array(data)
labels = np.array(labels)
y = np.zeros(labels.shape)
''' 标签转换为0/1 '''
y[labels=='fat']=1
''' 拆分训练数据与测试数据 '''
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
''' 创建网格以方便绘制 '''
h = .01
x_min, x_max = x[:, 0].min() - 0.1, x[:, 0].max() + 0.1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
''' 训练KNN分类器 '''
clf = neighbors.KNeighborsClassifier(algorithm='kd_tree')
clf.fit(x_train, y_train)
'''测试结果的打印'''
answer = clf.predict(x)
print(x)
print(answer)
print(y)
print(np.mean( answer == y))
'''准确率与召回率'''
precision, recall, thresholds = precision_recall_curve(y_train, clf.predict(x_train))
answer = clf.predict_proba(x)[:,1]
print(classification_report(y, answer, target_names = ['thin', 'fat']))
''' 将整个测试空间的分类结果用不同颜色区分开'''
answer = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:,1]
z = answer.reshape(xx.shape)
plt.contourf(xx, yy, z, cmap=plt.cm.Paired, alpha=0.8)
''' 绘制训练样本 '''
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train, cmap=plt.cm.Paired)
plt.xlabel(u'身高')
plt.ylabel(u'体重')
plt.show()结果分析
输出结果:
[ 0. 0. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 1.]
[ 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 1.]
准确率=0.94, score=0.94
precision recall f1-score support
thin 0.89 1.00 0.94 8
fat 1.00 0.89 0.94 9
avg / total 0.95 0.94 0.94 17
KNN分类器在众多分类算法中属于最简单的之一,需要注意的地方不多。有这几点要说明:
1、KNeighborsClassifier可以设置3种算法:‘brute',‘kd_tree',‘ball_tree'。如果不知道用哪个好,设置‘auto'让KNeighborsClassifier自己根据输入去决定。
2、注意统计准确率时,分类器的score返回的是计算正确的比例,而不是R2。R2一般应用于回归问题。
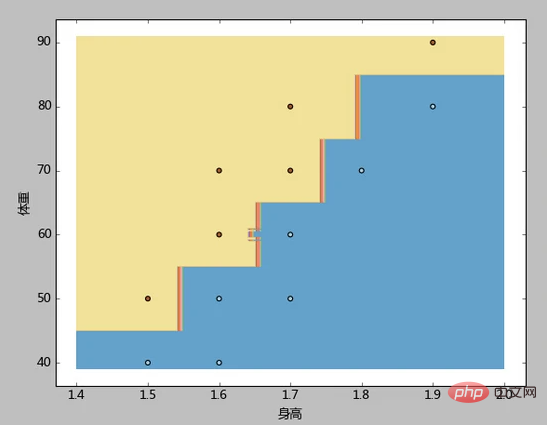
3、本例先根据样本中身高体重的最大最小值,生成了一个密集网格(步长h=0.01),然后将网格中的每一个点都当成测试样本去测试,最后使用contourf函数,使用不同的颜色标注出了胖、廋两类。
容易看到,本例的分类边界,属于相对复杂,但却又与距离呈现明显规则的锯齿形。
この種の境界線形関数は扱いが困難です。 KNN アルゴリズムには、このような境界問題の処理において固有の利点があります。後続のシリーズでは、このデータセットの正解率 = 0.94 が優れた結果であるとみなされることがわかります。
【関連する推奨事項: Python3 ビデオ チュートリアル ]
以上がPython を使用して KNN 分類アルゴリズムを処理するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。