
ホームページ >データベース >mysql チュートリアル >MySQL のマスター/スタンバイ、マスター/スレーブ、読み取り/書き込みの分離について詳しく学ぶ
MySQL のマスター/スタンバイ、マスター/スレーブ、読み取り/書き込みの分離について詳しく学ぶ

- 青灯夜游オリジナル
- 2021-09-01 18:46:572823ブラウズ
この記事では、MySQL におけるマスター/スレーブ、マスター/スレーブ、読み書きの分離について説明します。お役に立てば幸いです。
1. MySQL のプライマリとバックアップの基本原則
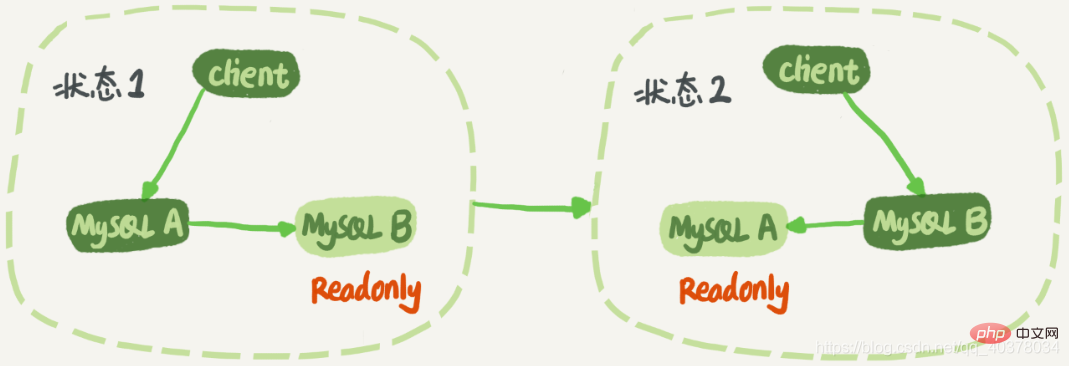
状態 1 では、クライアントは読み取りと書き込みのためにノード A に直接アクセスしますが、ノード A はノード A に直接アクセスします。 B これは A のスタンバイ データベースです。A のすべての更新を同期し、ローカルで実行します。これにより、ノード B と A のデータは同じ状態に保たれます。切り替えが必要な場合は状態2に切り替わります。このとき、クライアントはノード B に対して読み取りと書き込みを行い、ノード A は B のスタンバイ データベースになります。 [関連する推奨事項: mysql ビデオ チュートリアル ]
状態 1 では、ノード B は直接アクセスされませんが、スタンバイ ノード B を読み取り専用モードに設定することをお勧めします。理由はいくつかあります:
1. 一部の操作クエリ ステートメントがクエリのためにスタンバイ データベースに置かれることがあります。読み取り専用に設定すると誤操作を防ぐことができます。
2. ロジックの切り替えを防止します。バグ
3. 読み取り専用ステータスを使用してノードの役割を決定できます
スタンバイ データベースを読み取り専用に設定した場合、メイン データベースの最新の状態を維持するにはどうすればよいですかデータベース?
読み取り専用設定はスーパー特権ユーザーには無効であり、同期更新に使用されるスレッドにはスーパー特権があります。
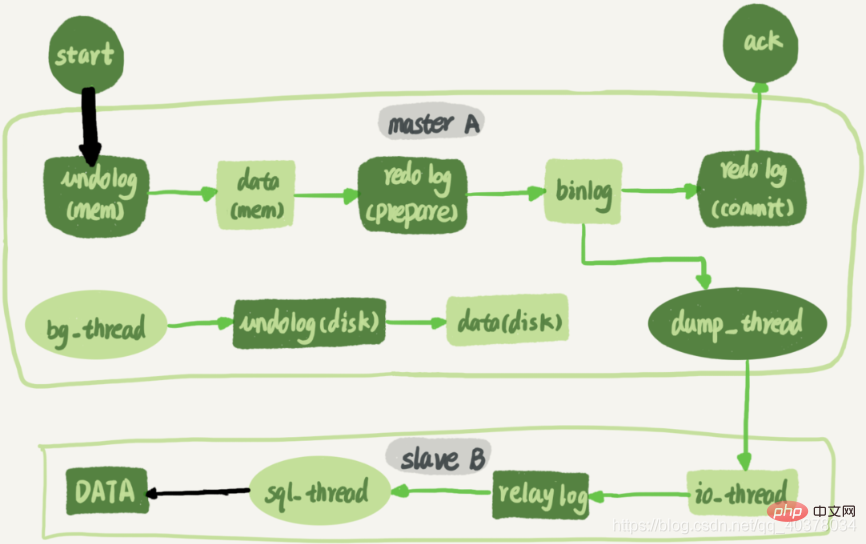
次の図は、ノード A で実行され、ノード A に同期される更新ステートメントを示しています。ノード B 完全なフローチャート: 
スタンバイ データベース B とプライマリ データベース A の間で長い接続が維持されます。メイン ライブラリ A 内には、スタンバイ ライブラリ B の長時間接続を処理する専用のスレッドがあります。トランザクション ログ同期の完全なプロセスは次のとおりです:
1. スタンバイ データベース B でchange master コマンドを使用して、プライマリ データベース A の IP、ポート、ユーザー名、パスワード、および開始場所を設定します。 binlog を要求しています。この場所には、ファイル名とログ オフセット
2 が含まれています。スタンバイ データベース B でスレーブ開始コマンドを実行します。このとき、スタンバイ データベースは、図の io_thread と sql_thread という 2 つのスレッドを開始します。このうち、io_thread はメイン ライブラリ
#3 との接続を確立する役割を果たします。メイン ライブラリ A がユーザー名とパスワードを検証した後、バイナリ ライブラリによって渡された場所に従って、ローカルからバイナリ ログの読み取りを開始します。スタンバイ ライブラリ B を作成し、それを B
4 に送信します。スタンバイ データベース B はバイナリ ログを取得した後、それをトランジット ログと呼ばれるローカル ファイルに書き込みます。
5.sql_thread はトランジット ログを読み取ります。ログを取得し、ログ内のコマンドを解析して実行します
マルチスレッド レプリケーション スキームの導入により、sql_thread は複数のスレッドに進化しました
2. ループ レプリケーションの問題
Double M 構造:
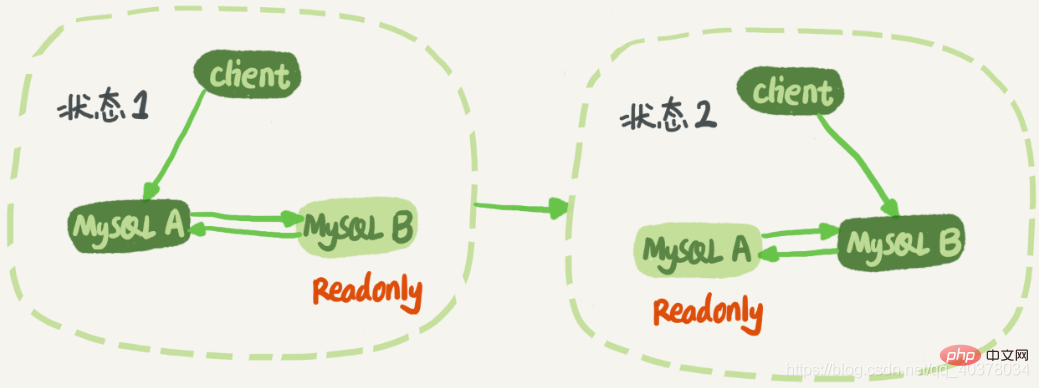
ノード A とノード B は相互にマスター/スタンバイ関係を持ちます。この方法では、切り替え中にアクティブ/スタンバイ関係を変更する必要はありません。
ダブル M 構造には解決すべき問題があります。ビジネス ロジックはノード A 上のステートメントを更新し、次に、生成されたバイナリログをノード B に送信します。 ノード B B がこの更新ステートメントを実行すると、バイナリログも生成されます。次に、ノード A がノード B のスタンバイ データベースでもある場合、ノード B の新しく生成されたバイナリ ログを取得して 1 回実行することと同じになり、ノード A とノード B の間のループで更新ステートメントが継続的に実行されます。つまり、ループ レプリケーション
MySQL は、このコマンドが初めて実行されたインスタンスのサーバー ID をバイナリログに記録します。したがって、次のロジックを使用して 2 つのノード間の循環レプリケーションの問題を解決できます:
1. 2 つのライブラリのサーバー ID は異なっていなければならないと規定されています。それらが同じである場合、それらはできません。関係
2. スタンバイ データベースはバイナリ ログを受信し、再生プロセス中に、元のバイナリ ログのサーバー ID と同じ新しいバイナリ ログを生成します。 ##3. 各データベースは、自分のメイン ライブラリからログが送信されたら、まずサーバー ID を決定します。それが自分のものと同じであれば、そのログは自分で生成されたものであることを意味し、直接
##1. ノード A から更新されたトランザクションの場合、A のサーバー ID が binlog に記録されます。##2. ノード B に送信されて一度実行された後、ノード B によって生成されたバイナリログのサーバー ID も A になります。サーバー ID
##3. その後、ノード A に送り返されます。 . A は、サーバー ID が自分のものと同じであると判断し、それ以上ログを処理しません。したがって、無限ループはここで解消されます。3. 一次遅延と二次遅延
1. 一次遅延とは何ですか遅延の準備をしていますか?
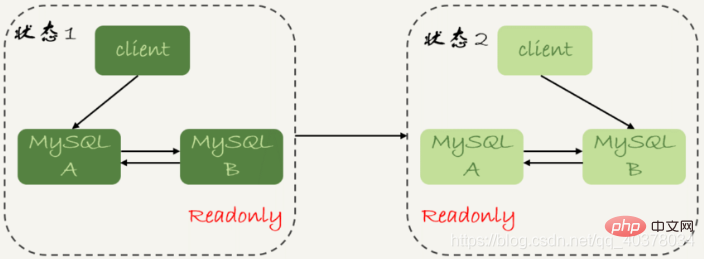 データ同期に関連する時点には主に次の 3 つが含まれます:
データ同期に関連する時点には主に次の 3 つが含まれます:
1. メイン ライブラリ A がトランザクションを完了し、それを binlog に書き込みます。この瞬間は T1## として記録されます。 #2. 次に、それをスタンバイ データベース B に渡します。スタンバイ データベース B がバイナリ ログを受信した時刻は T2
3 として記録されます。スタンバイ データベース B がトランザクションを完了した後、時刻は T3# として記録されます##いわゆるマスター/スレーブ遅延は、同じトランザクションに対してスレーブ データベースが実行される時間とマスター データベースが完了する時間の差、つまり T3-T1
スレーブ データベースのスレーブ ステータス コマンドで show を実行できます。その戻り結果には、現在のスタンバイ データベースが何秒遅れているかを示すために使用される秒数ビハインドマスターが表示されます。
秒数ビハインドマスターの計算方法は次のとおりです。 :
1. 各トランザクションのバイナリログには時間フィールドがあり、メイン データベースに書き込まれた時間を記録するために使用されます。
2. スタンバイ データベースは、トランザクションの時間フィールドの値を取り出します。現在実行中のトランザクションを計算し、それと現在のシステム時刻の差は秒_behind_masterです。
メイン データベース マシンとスタンバイ データベース マシンのシステム時刻設定が一致していない場合でも、メイン データベース マシンの値が不正確になることはありません。そしてスタンバイ遅延。スタンバイ データベースがプライマリ データベースに接続されると、SELECTUNIX_TIMESTAMP() 関数を通じて現在のプライマリ データベースのシステム時刻が取得されます。メイン データベースのシステム時刻がそれ自身のシステム時刻と一致していないことが判明した場合、スタンバイ データベースは、秒のビハインド マスターの計算を実行するときにその差を自動的に差し引きます。
通常のネットワーク条件では、プライマリ データベースとプライマリ データベース間の遅延の主な原因は、スタンバイ データベースが受信したことは、バイナリ ログとこのトランザクションの実行との時間差です。
マスター バックアップの遅延の最も直接的な現れは、バックアップ データベースが転送ログを消費する速度が遅いことです。メイン データベースが binlog を生成する速度よりも高速です
2. アクティブ データベースとバックアップ データベース間の遅延の原因
##1. 一部の展開条件下では、パフォーマンスが低下します。バックアップ データベースが配置されているマシンのパフォーマンスは、プライマリ データベースが配置されているマシンのパフォーマンスより劣ります2. 高圧。メイン データベースは書き込み機能を提供し、スタンバイ データベースは一部の読み取り機能を提供します。スタンバイ データベースの圧力制御を無視すると、スタンバイ データベース上のクエリは大量の CPU リソースを消費し、同期速度に影響を与え、プライマリ データベースとセカンダリ データベースの遅延を引き起こします。次の処理を実行できます。- 1 人のマスターと多数のスレーブ。スタンバイ データベースに加えて、さらにいくつかのスレーブ ライブラリを接続して、読み取り圧力を共有できます。
- Hadoop などのバイナリ ログを介して外部システムに出力し、外部システムが統計クエリ機能を提供できるようにします。
4. アクティブ/スタンバイ切り替え戦略
1. 信頼性優先戦略
ダブル M 構造の下で、スレーブは状態 1 から状態 2 に切り替える詳細なプロセスは次のとおりです: 1. スタンバイ データベース B の現在の秒数ビハインドマスターを確認します。それが特定の値未満の場合は続行します。次のステップに進むか、このステップの再試行を続行します。2. メイン ライブラリ A を読み取り専用状態に変更します。つまり、readonly を true に設定します。3. の値を決定します。スタンバイ ライブラリ B の Seconds_behind_master を値が 04 になるまで変更します。ライブラリ B を読み取り/書き込み状態に変更します。つまり、readonly を false5 に設定します。ビジネス リクエストをスタンバイに切り替えます。 library B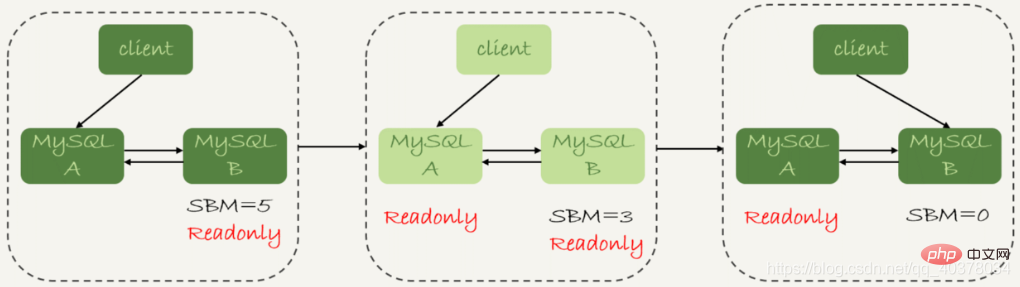 この切り替えプロセスに問題はありますか? 使用時間。ステップ 2 の後、メイン データベース A とスタンバイ データベース B は両方とも読み取り専用状態になります。これは、システムが書き込み不可能な状態になり、ステップ 5 が完了するまで復元できないことを意味します。この利用できない状態では、より時間のかかるステップはステップ 3 であり、数秒かかる場合があります。これは、最初のステップ 1 で、秒数ビハインドマスターの値が十分に小さいことを確認するための判断を行う必要がある理由でもあります。
この切り替えプロセスに問題はありますか? 使用時間。ステップ 2 の後、メイン データベース A とスタンバイ データベース B は両方とも読み取り専用状態になります。これは、システムが書き込み不可能な状態になり、ステップ 5 が完了するまで復元できないことを意味します。この利用できない状態では、より時間のかかるステップはステップ 3 であり、数秒かかる場合があります。これは、最初のステップ 1 で、秒数ビハインドマスターの値が十分に小さいことを確認するための判断を行う必要がある理由でもあります。
2. 可用性優先戦略
可用性優先戦略: 信頼性優先戦略のステップ 4 と 5 が最初に実行されるように強制的に調整された場合、つまり、接続はメイン データとスタンバイ データが同期されるのを待たずにスタンバイ データベース B に直接切り替え、スタンバイ データベース B の読み取りと書き込みを許可すると、システムに使用できない時間がほとんどなくなります。この切り替えプロセスのコストは、データの不整合の可能性ですmysql> CREATE TABLE `t` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `c` int(11) unsigned DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(c) values(1),(2),(3);表 t は、自動インクリメントされる主キー ID を定義します。データが初期化されると、メイン データベースとスタンバイ データベースに 3 行のデータが存在します。 。テーブル t に対して 2 つの insert ステートメント コマンドを次の順序で実行し続けます。
insert into t(c) values(4);insert into t(c) values(5);メイン データベース上の他のデータ テーブルに対する多数の更新があり、メインとスタンバイ間の遅延が 5 秒に達すると仮定します。 。 c=4 のステートメントを挿入すると、アクティブ/スタンバイの切り替えが開始されます。次の図は、可用性優先戦略が使用可能で、binlog_format=mixed
# の場合の切り替えプロセスとデータの結果を示しています。 ## 1. ステップ 2 で、メイン データベース A は挿入ステートメントの実行を終了し、データ行 (4,4) を挿入し、アクティブ/スタンバイ スイッチ 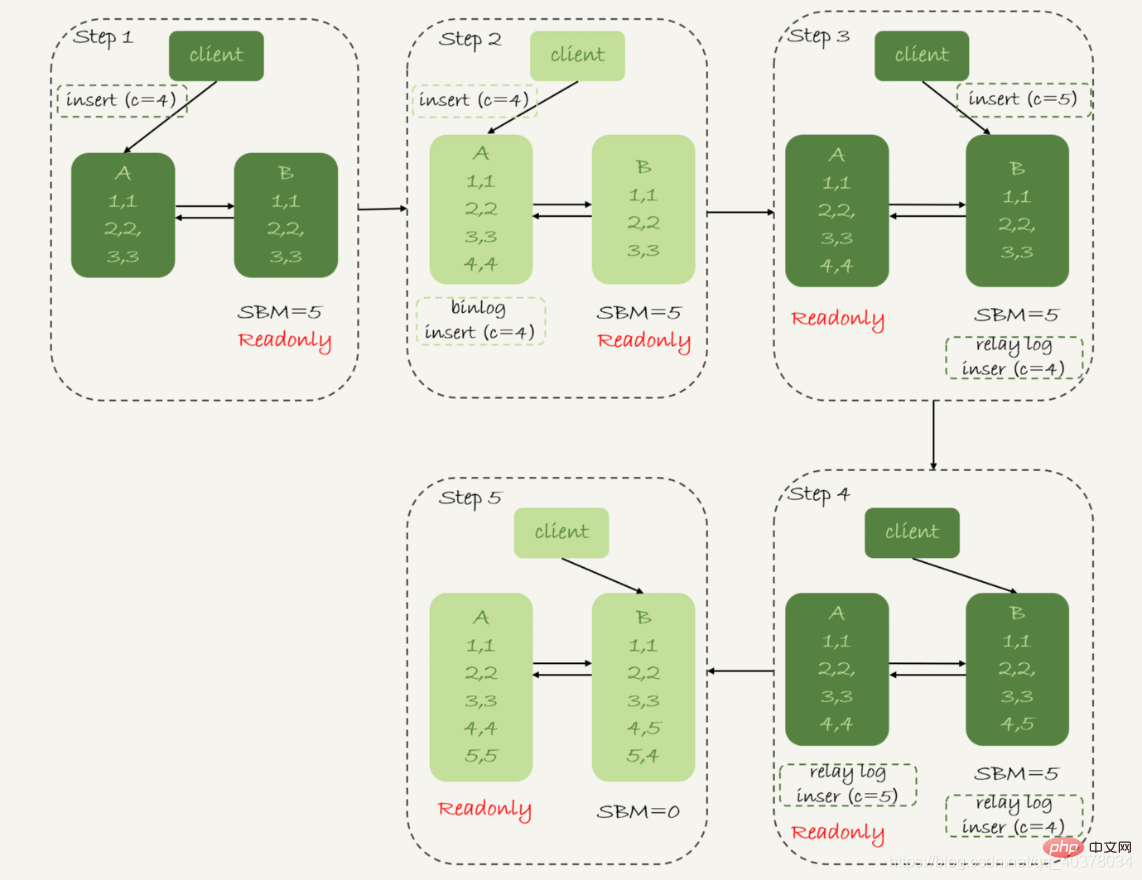
2 を開始します。ステップ 3 では、アクティブとスタンバイ間の遅延は 5 秒であるため、スタンバイ データベース B が c=4 を挿入する転送ログを適用する前に、c=5
3 を挿入するクライアントのコマンドの受信を開始します。ステップ 4 で、スタンバイ データベース B はデータ行 (4, 5) を挿入し、このバイナリ ログをメイン データベース A
4 に送信します。ステップ 5 で、スタンバイ データベース B は転送ログ c=4 を挿入し、データ行 (5,4) を挿入します。スタンバイ データベース B で直接実行される insert c=5 ステートメントは、メイン データベース A に渡され、新しいデータ行 (5,5) が挿入されます。データベース A とスタンバイ データベース B 2 行の不整合なデータが表示される
可用性優先戦略、binlog_format=row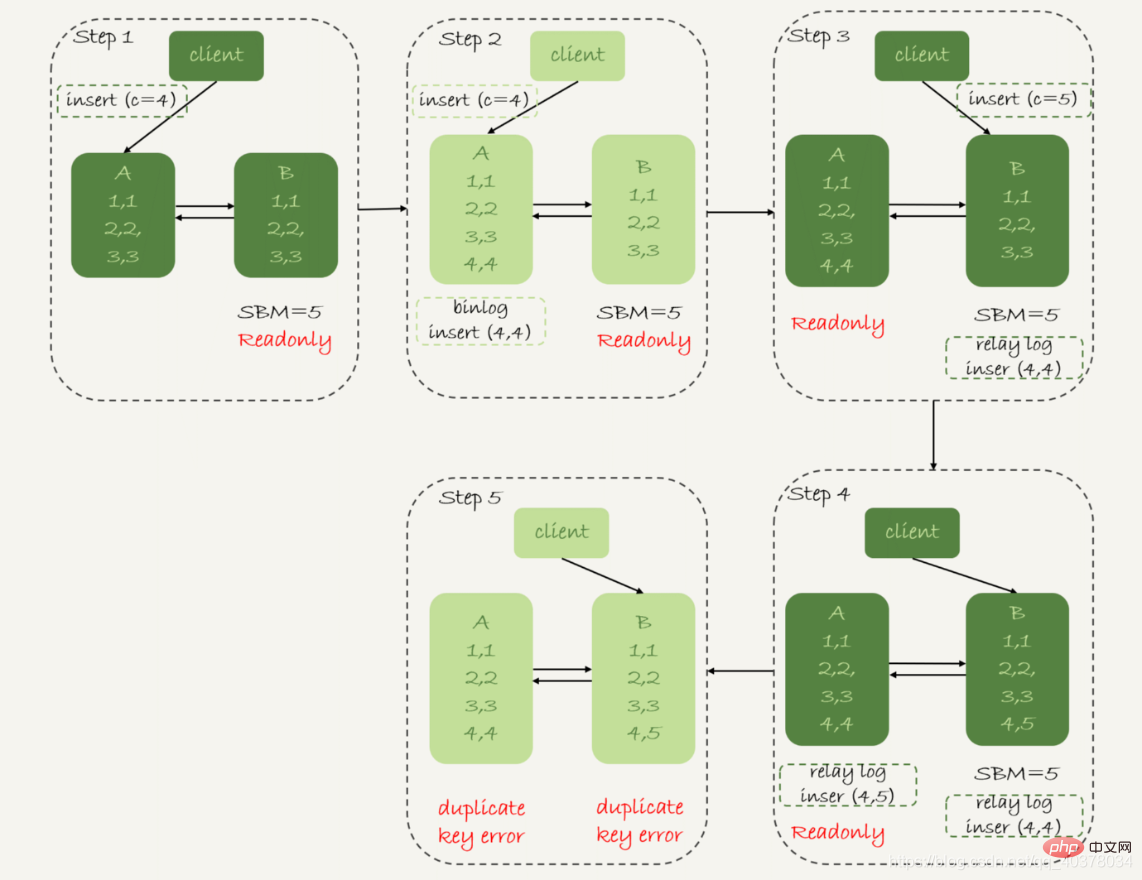
したがって、行形式で binlog を記録すると、新しく挿入された行のすべてのフィールド値が記録されるため、最終的には一貫性のない行が 1 つあります。さらに、両側のアクティブおよびスタンバイ同期のアプリケーション スレッドが重複キー エラーを報告して停止します。つまり、この場合、スタンバイデータベースBの(5,4)とプライマリデータベースAの(5,5)の2行のデータは相手には実行されません
3 . 概要
1. binlog を行形式で使用すると、データの不整合の問題が見つけやすくなります。混合またはステートメント形式のバイナリ ログを使用する場合、データの不整合の問題を発見するまでに長い時間がかかる場合があります。
2. アクティブ/スタンバイ スイッチオーバーの可用性優先戦略により、データの不整合が発生します。したがって、ほとんどの場合、信頼性優先戦略を採用することをお勧めします
5. MySQL の並列レプリケーション戦略
プライマリおよび並列レプリケーション機能に関して注目していただきたいのは、上の図の 2 つの黒い矢印です。 1 つはメイン データベースに書き込むクライアントを表し、もう 1 つはスタンバイ データベース上の sql_thread 実行転送ログを表します。
MySQL バージョン 5.6 より前では、MySQL はシングル スレッド レプリケーションのみをサポートしていました。同時実行性が高く、TPS が高かったため、マスター バックアップの遅延に関する重大な問題が発生します。
マルチスレッド レプリケーション メカニズムは、スレッドが 1 つだけの sql_thread を複数のスレッドに分割します。これは、次のモデルと一致します。
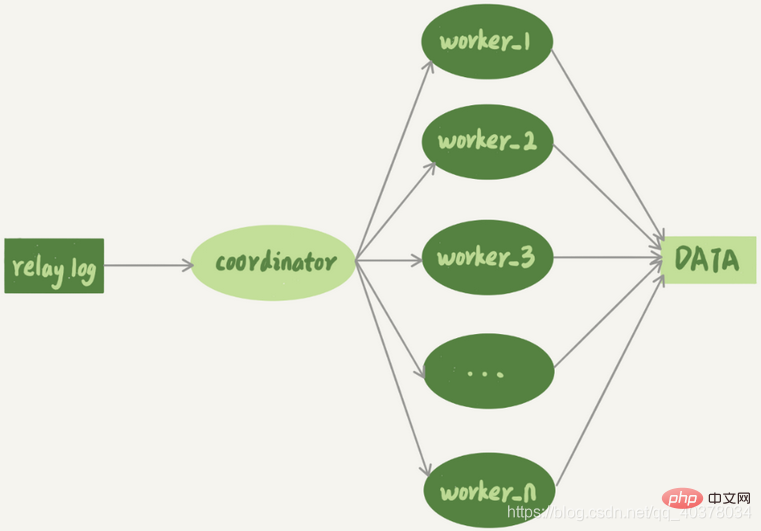 # コーディネーターは元の sql_thread ですが、現在はデータを直接更新することはなく、転送ログの読み取りとトランザクションの分散のみを担当します。実際にログを更新するのはワーカー スレッドになります。ワーカー スレッドの数は、パラメータ SLAVE_Parallel_workers によって決まります。配布する場合、コーディネーターは次の 2 つの基本要件を満たす必要があります:
# コーディネーターは元の sql_thread ですが、現在はデータを直接更新することはなく、転送ログの読み取りとトランザクションの分散のみを担当します。実際にログを更新するのはワーカー スレッドになります。ワーカー スレッドの数は、パラメータ SLAVE_Parallel_workers によって決まります。配布する場合、コーディネーターは次の 2 つの基本要件を満たす必要があります:
更新カバレッジを引き起こすことはできません。これには、同じ行を更新する 2 つのトランザクションを同じワーカーに分散する必要があります。
##同じトランザクションは分割できず、同じワーカーに配置する必要があります- 1 . MySQL5.6 バージョンの並列レプリケーション戦略
- MySQL5.6 バージョンは並列レプリケーションをサポートしていますが、サポートされる粒度はデータベースごとに並列です。分散戦略を決定するために使用されるハッシュ テーブルでは、キーはデータベース名
です。この戦略の並列効果は圧力モデルによって異なります。メイン データベースに複数の DB があり、各 DB の負荷がバランスされている場合、この戦略を使用する効果は非常に優れています。この戦略の 2 つの利点:
ハッシュ値を構築します。非常に高速です。ライブラリ名 のみが必要です。ステートメント形式の binlog はライブラリ名 も簡単に取得できるため、binlog 形式も必要ありません。- 異なる DB を作成します。同じ人気を持つテーブルはこれらの異なる DB に均等に分割され、この戦略が強制的に使用されます
- 2. MariaDB の並列レプリケーション戦略
redo ログ グループ送信の最適化、MariaDB の並列レプリケーション戦略はこの機能を利用します:
同じグループ内で送信できるトランザクションは同じ行を変更しません
メイン データベースで並行して実行できるトランザクション、スタンバイ データベースも並行して実行できる必要があります- 実装に関しては、MariaDB はこれを行います:
- 1グループ内で一緒に送信されたトランザクションは同じ commit_id を持ち、次のグループは commit_id 1
- 2 です。Commit_id は binlog
3 に直接書き込まれます。スタンバイ データベース アプリケーションに送信されるとき、トランザクションは同じ commit_id を持つものは、実行のために複数のワーカーに分散されます
4. このグループの実行がすべて完了した後、コーディネーターは次のバッチを削除します
以下の図では、メイン ライブラリで 3 つのグループのトランザクションが実行され、trx1、trx2、および trx3 が送信されると、trx4、trx5、および trx6 が実行されると仮定します。このようにして、最初のトランザクション グループが送信されると、次のトランザクション グループがすぐにコミット状態に入ります。
MariaDB の並列レプリケーション戦略によると、スタンバイ データベースに対する実行の影響は次のとおりです。
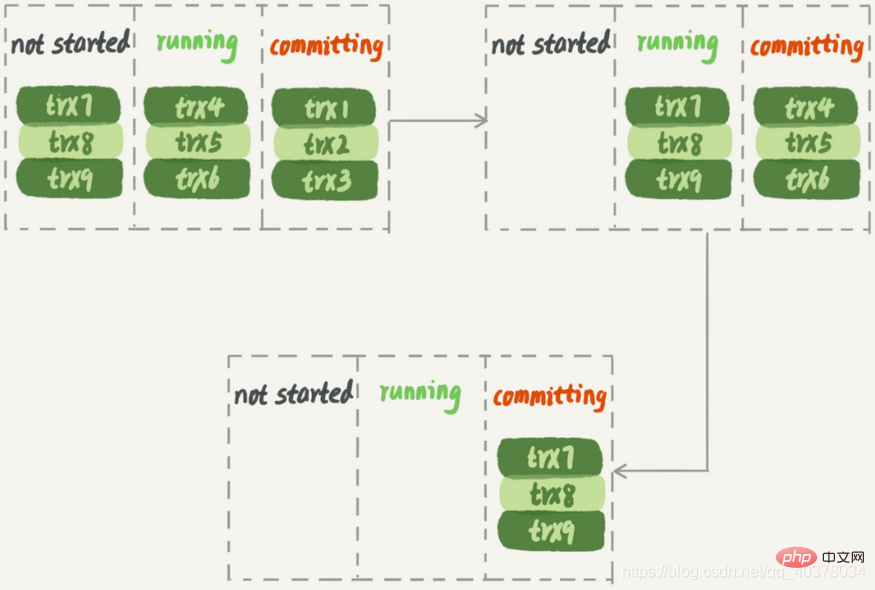 スタンバイ データベースで実行する場合、トランザクションの 2 番目のグループは、トランザクションの 2 番目のグループが開始できる前に、トランザクションの最初のグループが完全に実行されるまで待機する必要があります。
スタンバイ データベースで実行する場合、トランザクションの 2 番目のグループは、トランザクションの 2 番目のグループが開始できる前に、トランザクションの最初のグループが完全に実行されるまで待機する必要があります。
さらに、この計画は大きなイベントによって簡単に妨げられます。 trx2 が非常に大規模なトランザクションであると仮定すると、スタンバイ データベースが適用されると、trx1 と trx3 の実行が完了した後、次のグループが実行を開始できます。ワーカー スレッドが 1 つだけ動作しているため、リソースが無駄になります
 3. MySQL5.7 バージョンの並列レプリケーション戦略
3. MySQL5.7 バージョンの並列レプリケーション戦略
MySQL5.7 のバージョンはパラメータによって決まります。並列レプリケーション戦略を制御するための SLAVE-Parallel- タイプ:
は DATABASE として構成されます。これは、MySQL5.6 バージョン
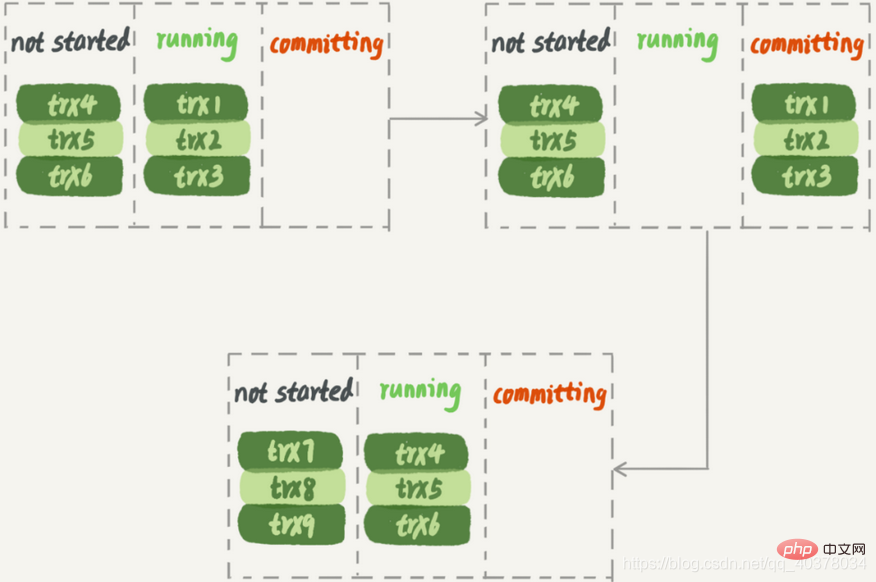
のデータベースごとの並列戦略を使用することを意味します。 LOGICAL_CLOCK として、MariaDB と同様の戦略を意味します。 MySQL はこれに基づいて最適化を行っていますが、同時に実行状態にあるすべてのトランザクションを並列化できますか?不可以,因为这里面可能有由于锁冲突而处于锁等待状态的事务。如果这些事务在备库上被分配到不同的worker,就会出现备库跟主库不一致的情况
而MariaDB这个策略的核心是所有处于commit状态的事务可以并行。事务处于commit状态表示已经通过了锁冲突的检验了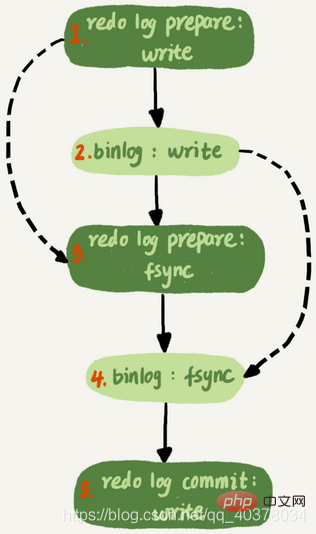
其实只要能够达到redo log prepare阶段就表示事务已经通过锁冲突的检验了
因此,MySQL5.7并行复制策略的思想是:
1.同时处于prepare状态的事务,在备库执行时是可以并行的
2.处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的
binlog组提交的时候有两个参数:
- binlog_group_commit_sync_delay参数表示延迟多少微妙后才调用fsync
- binlog_group_commit_sync_no_delay_count参数表示基类多少次以后才调用fsync
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL5.7的并行复制策略里,它们可以用来制造更多的同时处于prepare阶段的事务。这样就增加了备库复制的并行度。也就是说,这两个参数既可以故意让主库提交得慢些,又可以让备库执行得快些
4、MySQL5.7.22的并行复制策略
MySQL5.7.22增加了一个新的并行复制策略,基于WRITESET的并行复制,新增了一个参数binlog-transaction-dependency-tracking用来控制是否启用这个新策略。这个参数的可选值有以下三种:
- COMMIT_ORDER,根据同时进入prepare和commit来判断是否可以并行的策略
- WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的hash值,组成集合writeset。如果两个事务没有操作相同的行,也就是说它们的writeset没有交集,就可以并行
- WRITESET_SESSION,是在WRITESET的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序
为了唯一标识,hash值是通过库名+表名+索引名+值计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值
1.writeset是在主库生成后直接写入到binlog里面的,这样在备库执行的时候不需要解析binlog内容
2.不需要把整个事务的binlog都扫一遍才能决定分发到哪个worker,更省内存
3.由于备库的分发策略不依赖于binlog内容,索引binlog是statement格式也是可以的
对于表上没主键和外键约束的场景,WRITESET策略也是没法并行的,会暂时退化为单线程模型
六、主库出问题了,从库怎么办?
下图是一个基本的一主多从结构
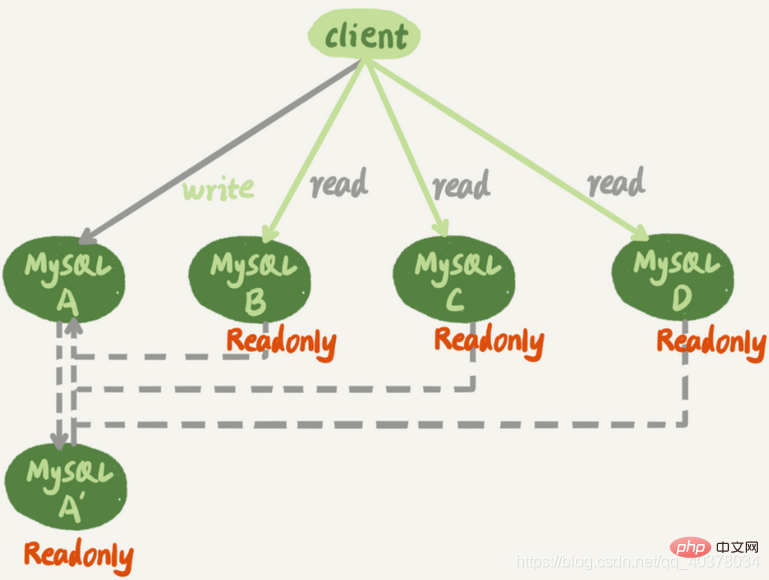
图中,虚线箭头表示的是主备关系,也就是A和A’互为主备,从库B、C、D指向的是主库A。一主多从的设置,一般用于读写分离,主库负责所有的写入和一部分读,其他的读请求则由从库分担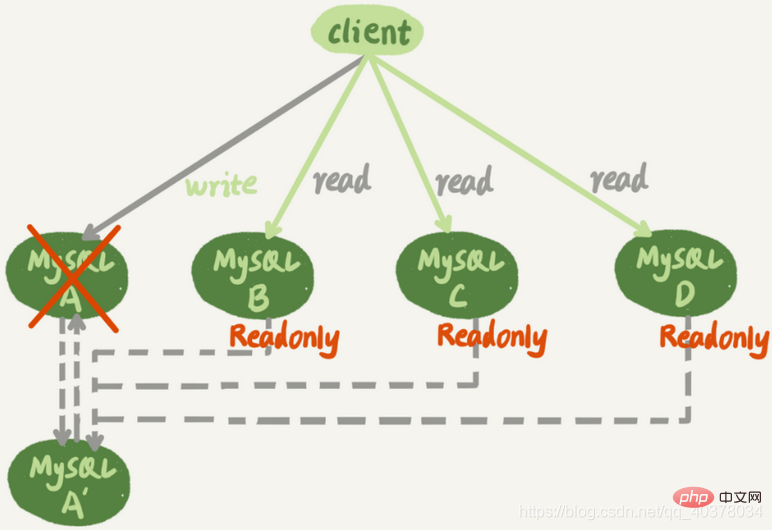
一主多从结构在切换完成后,A’会成为新的主库,从库B、C、D也要改接到A’
1、基于位点的主备切换
当我们把节点B设置成节点A’的从库的时候,需要执行一条change master命令:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_name MASTER_LOG_POS=$master_log_pos
- MASTER_HOST、MASTER_PORT、MASTER_USER和MASTER_PASSWORD四个参数,分别代表了主库A’的IP、端口、用户名和密码
- 最后两个参数MASTER_LOG_FILE和MASTER_LOG_POS表示,要从主库的master_log_name文件的master_log_pos这个位置的日志继续同步。而这个位置就是所说的同步位点,也就是主库对应的文件名和日志偏移量
找同步位点很难精确取到,只能取一个大概位置。一种去同步位点的方法是这样的:
1.等待新主库A’把中转日志全部同步完成
2.在A’上执行show master status命令,得到当前A’上最新的File和Position
3.取原主库A故障的时刻T
4.用mysqlbinlog工具解析A’的File,得到T时刻的位点,这个值就可以作为$master_log_pos
这个值并不精确,有这么一种情况,假设在T这个时刻,主库A已经执行完成了一个insert语句插入了一行数据R,并且已经将binlog传给了A’和B,然后在传完的瞬间主库A的主机就掉电了。那么,这时候系统的状态是这样的:
1.在从库B上,由于同步了binlog,R这一行已经存在
2.在新主库A’上,R这一行也已经存在,日志是写在master_log_pos这个位置之后的
3.在从库B上执行change master命令,指向A’的File文件的master_log_pos位置,就会把插入R这一行数据的binlog又同步到从库B去执行,造成主键冲突,然后停止tongue
通常情况下,切换任务的时候,要先主动跳过这些错误,有两种常用的方法
一种是,主动跳过一个事务
set global sql_slave_skip_counter=1;start slave;
另一种方式是,通过设置slave_skip_errors参数,直接设置跳过指定的错误。这个背景是,我们很清楚在主备切换过程中,直接跳过这些错误是无损的,所以才可以设置slave_skip_errors参数。等到主备间的同步关系建立完成,并稳定执行一段时间之后,还需要把这个参数设置为空,以免之后真的出现了主从数据不一致,也跳过了
2、GTID
MySQL5.6引入了GTID,是一个全局事务ID,是一个事务提交的时候生成的,是这个事务的唯一标识。它的格式是:
GTID=source_id:transaction_id
- source_id是一个实例第一次启动时自动生成的,是一个全局唯一的值
- transaction_id是一个整数,初始值是1,每次提交事务的时候分配给这个事务,并加1
GTID模式的启动只需要在启动一个MySQL实例的时候,加上参数gtid_mode=on和enforce_gtid_consistency=on就可以了
在GTID模式下,每个事务都会跟一个GTID一一对应。这个GTID有两种生成方式,而使用哪种方式取决于session变量gtid_next的值
1.如果gtid_next=automatic,代表使用默认值。这时,MySQL就把GTID分配给这个事务。记录binlog的时候,先记录一行SET@@SESSION.GTID_NEXT=‘GTID’。把这个GTID加入本实例的GTID集合
2.如果gtid_next是一个指定的GTID的值,比如通过set gtid_next=‘current_gtid’,那么就有两种可能:
- 如果current_gtid已经存在于实例的GTID集合中,接下里执行的这个事务会直接被系统忽略
- 如果current_gtid没有存在于实例的GTID集合中,就将这个current_gtid分配给接下来要执行的事务,也就是说系统不需要给这个事务生成新的GTID,因此transaction_id也不需要加1
一个current_gtid只能给一个事务使用。这个事务提交后,如果要执行下一个事务,就要执行set命令,把gtid_next设置成另外一个gtid或者automatic
这样每个MySQL实例都维护了一个GTID集合,用来对应这个实例执行过的所有事务
3、基于GTID的主备切换
在GTID模式下,备库B要设置为新主库A’的从库的语法如下:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1
其中master_auto_position=1就表示这个主备关系使用的是GTID协议
实例A’的GTID集合记为set_a,实例B的GTID集合记为set_b。我们在实例B上执行start slave命令,取binlog的逻辑是这样的:
1.实例B指定主库A’,基于主备协议建立连接
2.实例B把set_b发给主库A’
3.实例A’算出set_a与set_b的差集,也就是所有存在于set_a,但是不存在于set_b的GTID的集合,判断A’本地是否包含了这个差集需要的所有binlog事务
- 如果不包含,表示A’已经把实例B需要的binlog给删掉了,直接返回错误
- 如果确认全部包含,A’从自己的binlog文件里面,找出第一个不在set_b的事务,发给B
4.之后从这个事务开始,往后读文件,按顺序取binlog发给B去执行
4、GTID和在线DDL
如果是由于索引缺失引起的性能问题,可以在线加索引来解决。但是,考虑到要避免新增索引对主库性能造成的影响,可以先在备库加索引,然后再切换,在双M结构下,备库执行的DDL语句也会传给主库,为了避免传回后对主库造成影响,要通过set sql_log_bin=off关掉binlog,但是操作可能会导致数据和日志不一致
两个互为主备关系的库实例X和实例Y,且当前主库是X,并且都打开了GTID模式。这时的主备切换流程可以变成下面这样:
- 在实例X上执行stop slave
- 在实例Y上执行DDL语句。这里不需要关闭binlog
- 执行完成后,查出这个DDL语句对应的GTID,记为source_id_of_Y:transaction_id
- 到实例X上执行一下语句序列:
set GTID_NEXT="source_id_of_Y:transaction_id";begin;commit;set gtid_next=automatic;start slave;
这样做的目的在于,既可以让实例Y的更新有binlog记录,同时也可以确保不会在实例X上执行这条更新
七、MySQL读写分离
读写分离的基本结构如下图:
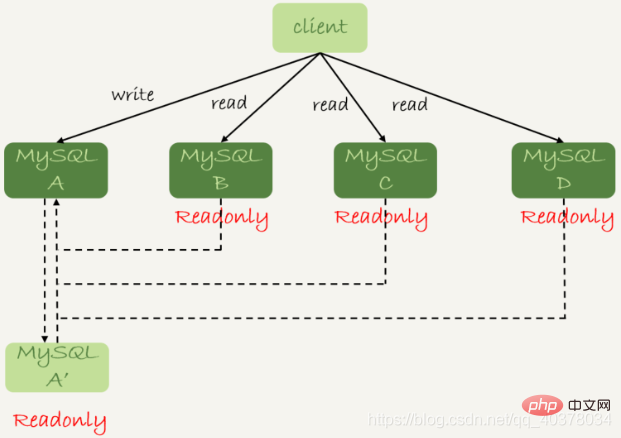
读写分离的主要目的就是分摊主库的压力。上图中的结构是客户端主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。由客户端来选择后端数据库进行查询
还有一种架构就是在MySQL和客户端之间有一个中间代理层proxy,客户端只连接proxy,由proxy根据请求类型和上下文决定请求的分发路由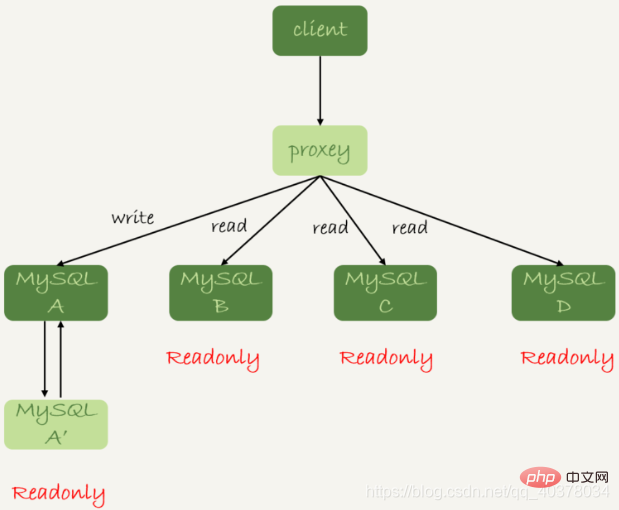
1.客户端直连方案,因此少了一层proxy转发,所以查询性能稍微好一点,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如Zookeeper,尽量让业务端只专注于业务逻辑开发
2.带proxy的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高,而且proxy也需要有高可用架构
在从库上会读到系统的一个过期状态的现象称为过期读
1、强制走主库方案
强制走主库方案其实就是将查询请求做分类。通常情况下,可以分为这么两类:
1.对于必须要拿到最新结果的请求,强制将其发到主库上
2.对于可以读到旧数据的请求,才将其发到从库上
这个方案最大的问题在于,有时候可能会遇到所有查询都不能是过期读的需求,比如一些金融类的业务。这样的话,就需要放弃读写分离,所有读写压力都在主库,等同于放弃了扩展性
2、Sleep方案
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。这个方案的假设是,大多数情况下主备延迟在1秒之内,做一个sleep可以很大概率拿到最新的数据
以买家发布商品为例,商品发布后,用Ajax直接把客户端输入的内容作为最新商品显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这个显示,来确认产品已经发布成功了。等到卖家再刷新页面,去查看商品的时候,其实已经过了一段时间,也就达到了sleep的目的,进而也就解决了过期读的问题
但这个方案并不精确:
1.如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒
2.如果延迟超过1秒,还是会出现过期读
3、判断主备无延迟方案
show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短
1.第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0。如果还不等于0,那就必须等到这个参数变为0才能执行查询请求
show slave status结果的部分截图如下:
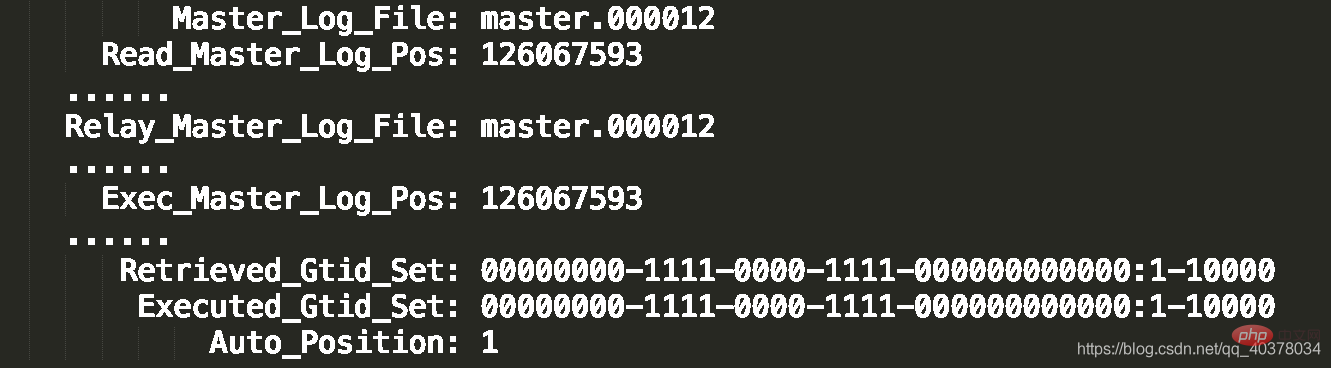
2.第二种方法,对比位点确保主备无延迟:
- Master_Log_File和Read_Master_Log_Pos表示的是读到的主库的最新位点
- Relay_Master_Log_File和Exec_Master_Log_Pos表示的是备库执行的最新位点
如果Master_Log_File和Read_Master_Log_Pos和Relay_Master_Log_File和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成
3.第三种方法,对比GTID集合确保主备无延迟:
- Auto_Position=1表示这堆主备关系使用了GTID协议
- Retrieved_Gitid_Set是备库收到的所有日志的GTID集合
- Executed_Gitid_Set是备库所有已经执行完成的GTID集合
如果这两个集合相同,也表示备库接收到的日志都已经同步完成
4.一个事务的binlog在主备库之间的状态:
1)主库执行完成,写入binlog,并反馈给客户端
2)binlog被从主库发送给备库,备库收到
3)在备库执行binlog完成
上面判断主备无延迟的逻辑是备库收到的日志都执行完成了。但是,从binlog在主备之间状态的分析中,有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态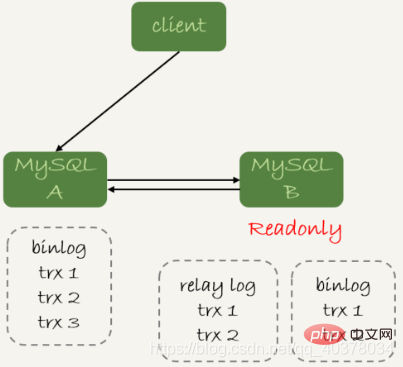
这时,主库上执行完成了三个事务trx1、trx2和trx3,其中:
- trx1和trx2已经传到从库,并且已经执行完成了
- trx3在主库执行完成,并且已经回复给客户端,但是还没有传到从库中
如果这时候在从库B上执行查询请求,按照上面的逻辑,从库认为已经没有同步延迟,但还是查不到trx3的
4、配合semi-sync
要解决上面的问题,就要引入半同步复制。semi-sync做了这样的设计:
1.事务提交的时候,主库把binlog发送给从库
2.从库收到binlog以后,发回给主库一个ack,表示收到了
3.主库收到这个ack以后,才能给客户端返回事务完成的确认
如果启用了semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志
semi-sync+位点判断的方案,只对一主一备的场景是成立的。在一主多从场景中,主库只要等到一个从库的ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
1.如果查询是落在这个响应了ack的从库上,是能够确保读到最新数据
2.但如果查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题
判断同步位点的方案还有另外一个潜在的问题,即:如果在业务更新的高峰期,主库的位点或者GTID集合更新很快,那么上面的两个位点等值判断就会一直不成立,很有可能出现从库上迟迟无法响应查询请求的情况
上图从状态1到状态4,一直处于延迟一个事务的状态。但是,其实客户端是在发完trx1更新后发起的select语句,我们只需要确保trx1已经执行完成就可以执行select语句了。也就是说,如果在状态3执行查询请求,得到的就是预期结果了
semi-sync配合主备无延迟的方案,存在两个问题:
1.一主多从的时候,在某些从库执行查询请求会存在过期读的现象
2.在持续延迟的情况下,可能出现过度等待的问题
5、等主库位点方案
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
1.它是在从库执行的
2.参数file和pos指的是主库上的文件名和位置
3.timeout可选,设置为正整数N表示这个函数最多等待N秒
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务
1.如果执行期间,备库同步线程发生异常,则返回NULL
2.如果等待超过N秒,就返回-1
3.如果刚开始执行的时候,就发现已经执行过这个位置了,则返回0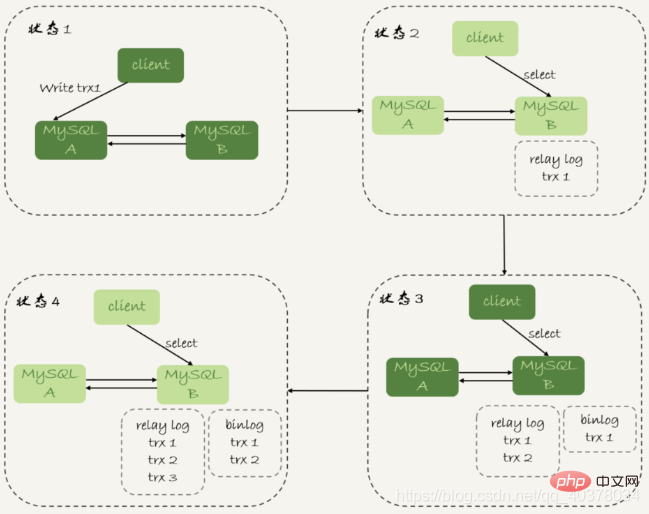
对于上图中先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,可以使用这个逻辑:
1.trx1事务更新完成后,马上执行show master status得到当前主库执行到的File和Position
2.选定一个从库执行查询语句
3.在从库上执行select master_pos_wait(file, pos, 1)
4.如果返回值是>=0的正整数,则在这个从库执行查询语句
5.否则,到主库执行查询语句
流程如下:
6、GTID方案
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑如下:
1.等待,直到这个库执行的事务中包含传入的gtid_set,返回0
2.超时返回1
等主库位点方案中,执行完事务后,还要主动去主库执行show master status。而MySQL5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案可以减少一次查询
等GTID的流程如下:
1.trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1
2.选定一个从库执行查询语句
3. select wait_for_executed_gtid_set(gtid1, 1);
4 を実行します。戻り値が 0 の場合は、このスレーブ ライブラリに対してクエリ ステートメントを実行します。
5. それ以外の場合は、クエリ ステートメントを実行するメイン データベース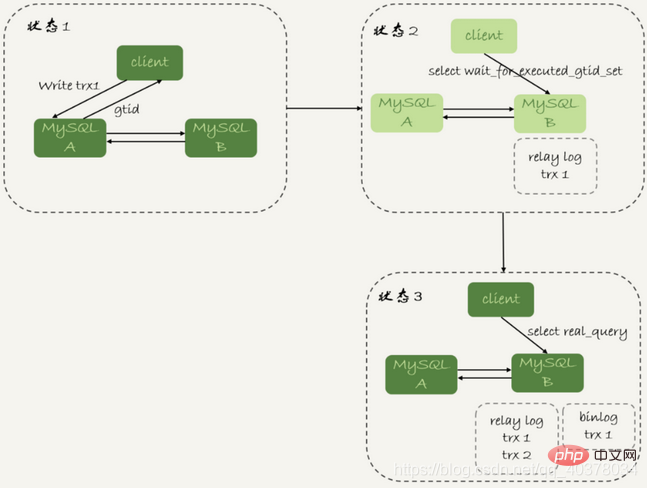
プログラミング関連の知識の詳細については、プログラミング入門をご覧ください。 !
以上がMySQL のマスター/スタンバイ、マスター/スレーブ、読み取り/書き込みの分離について詳しく学ぶの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。