
ホームページ >データベース >mysql チュートリアル >MySQL の主キーの自動インクリメントの詳細については、こちらをご覧ください。
MySQL の主キーの自動インクリメントの詳細については、こちらをご覧ください。

- 青灯夜游転載
- 2021-08-26 19:29:201981ブラウズ
この記事では、MySQL の自動インクリメント主キーについて理解し、自動インクリメント値の変更メカニズム、自動インクリメント値の変更タイミング、自動インクリメント ロックの最適化方法などを紹介します。必要な友人は、について学ぶことができます。 it~

1. 自己増加値はどこに保存されますか?
#異なるエンジンには、自動インクリメント値を保存するための異なる戦略があります
#1. MyISAM エンジンの自動インクリメント値は、データ ファイルに保存されます
2.InnoDB エンジン MySQL 5.7 以前のバージョンでは、自己インクリメントされた値はメモリに保存され、永続化されません。各再起動後、初めてテーブルを開いたときに、自動インクリメント max(id) の最大値が見つかり、テーブルの現在の自動インクリメント値として max(id) ステップ サイズが使用されます。
select max(ai_col) from table_name for update;
MySQL8 .0 バージョンでは、自己増加する値の変更が REDO ログに記録されます。再起動時には、REDO ログを利用して再起動前の値を復元します
2 . 自己増加値変更メカニズムフィールド ID が AUTO_INCREMENT として定義されている場合、データ行を挿入するときの自動インクリメントの動作は次のとおりです:
1。データの挿入時に ID フィールドが 0、NULL、または未指定の値として指定された場合、テーブルの現在の AUTO_INCREMENT 値が自動インクリメント フィールド
2 に入力されます。ID フィールドが特定の値を指定している場合データを挿入するときは、ステートメントで指定された値を直接使用します
特定の値が挿入されると仮定します 値は X、現在の自動インクリメント値は Y
1 です。自己インクリメント値は新しい自己インクリメント値に変更されます。
新しい自己インクリメント値生成アルゴリズムは次のとおりです: auto_increment_offset (初期値) から開始し、auto_increment_increment (ステップ サイズ) をステップとします。サイズを指定し、最初の値が見つかるまで重ね合わせを続けます。フィールドより大きい値、c が唯一のインデックスです。テーブル作成ステートメントは次のとおりです。CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`)) ENGINE=InnoDB;すでにレコード (1, 1,1) をテーブル t に追加し、別のデータ挿入コマンドを実行します:
insert into t values(null, 1, 1);実行プロセスは次のとおりです: 1. エグゼキューターは InnoDB エンジン インターフェイスを呼び出して行を書き込みます。渡された行の値は (0,1,1)
2 です。 InnoDB 自動インクリメント ID が指定されていない値を検索し、テーブル t 2# の現在の自動インクリメント値を取得します##3. 受信行の値を (2,1,1)
4 に変更します。テーブルの自動インクリメント値を 3
5 に変更します。続行します。 c=1 のレコードがすでに存在するため、重複キー エラー (一意のキーの競合) が報告され、ステートメントは
対応する実行フローチャートは次のとおりです:
その後、新しいデータ行を挿入すると、取得される自動インクリメントされる ID は 3 になります。自動インクリメントされる主キーが連続的でない状況があります#一意キーの競合とトランザクションのロールバックにより、自動インクリメントされる主キー ID が連続的でない状況が発生します 4. ロック増加の最適化自己インクリメント ID ロックはトランザクション ロックではありませんが、各アプリケーションが完了するとすぐに解放され、他のトランザクションが再度適用できるようになります。 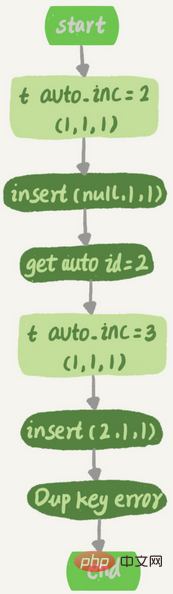 ただし、MySQL5 では、バージョン 0 では、自己増加ロックの範囲はステートメント レベルです。つまり、ステートメントがテーブルの自動インクリメント ロックに適用される場合、ステートメントが実行されるまでロックは解放されません。
ただし、MySQL5 では、バージョン 0 では、自己増加ロックの範囲はステートメント レベルです。つまり、ステートメントがテーブルの自動インクリメント ロックに適用される場合、ステートメントが実行されるまでロックは解放されません。
1。このパラメータは 0 に設定されます。これは、以前の MySQL5.0 バージョンの戦略が採用されること、つまり、ステートメントが実行された後にのみロックが解放されることを意味します。 2. このパラメータは 1 に設定されます
通常の挿入ステートメントでは、自己増加ロックはアプリケーションの直後に解放されます。
挿入などのステートメントの場合..データをバッチで挿入する .select の場合、自己増加ロックはステートメントが完了するまで解放されるまで待機する必要があります。
3. このパラメーターは 2 に設定されます。自動ロックを適用するためのすべてのアクション-incremented 主キーは、適用後にロックを解放します。
データの一貫性を保つため、デフォルト設定は 1
セッション B が適用直後に自動インクリメント ロックを解放する場合自動インクリメント値の場合、次の状況が発生する可能性があります:- sessionB は最初に 2 行のデータ (1,1,1)、(2,2,2)
- ## を挿入します。 #sessionA は自動インクリメント ID を適用し、id=3 を取得しました。(3,5,5)
- を挿入した後、セッション B は実行を継続し、2 つのレコード (4,3,3)、(5, 4,4)
binlog_format=statement の場合、2 つのセッションがデータ挿入コマンドを同時に実行するため、binlog はテーブル t2 の更新ログに面します。状況は 2 つだけです。どちらかがセッション A を記録するまたはセッション B を最初に記録します。どちらの場合でも、このバイナリログはスレーブデータベースから実行されるか、一時インスタンスのリストアに使用され、スタンバイデータベースと一時インスタンスでは sessionB ステートメントが実行され、生成される結果の ID は連続します。この時点で、このライブラリではデータの不整合が発生しました。
この問題を解決するためのアイデア:  1) 元のライブラリにデータ ステートメントをバッチで挿入して、連続 ID 値を生成させます。したがって、自己増加ロックは、この目的を達成するためだけに、ステートメントが実行されるまで解放されません。
1) 元のライブラリにデータ ステートメントをバッチで挿入して、連続 ID 値を生成させます。したがって、自己増加ロックは、この目的を達成するためだけに、ステートメントが実行されるまで解放されません。
2)在binlog里面把插入数据的操作都如实记录进来,到备库执行的时候,不再依赖于自增主键去生成。也就是把innodb_autoinc_lock_mode设置为2,同时binlog_format设置为row
如果有批量插入数据(insert … select、replace … select和load data)的场景时,从并发插入数据性能的角度考虑,建议把innodb_autoinc_lock_mode设置为2,同时binlog_format设置为row,这样做既能并发性,又不会出现数据一致性的问题
对于批量插入数据的语句,MySQL有一个批量申请自增id的策略:
1.语句执行过程中,第一次申请自增id,会分配1个
2.1个用完以后,这个语句第二次申请自增id,会分配2个
3.2个用完以后,还是这个语句,第三次申请自增id,会分配4个
4.依次类推,同一个语句去申请自增id,每次申请到的自增id个数都是上一次的两倍
insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t; insert into t2(c,d) select c,d from t; insert into t2 values(null, 5,5);
insert … select,实际上往表t2中插入了4行数据。但是,这四行数据是分三次申请的自增id,第一次申请到了id=1,第二次被分配了id=2和id=3,第三次被分配到id=4到id=7
由于这条语句实际上只用上了4个id,所以id=5到id=7就被浪费掉了。之后,再执行insert into t2 values(null, 5,5),实际上插入了的数据就是(8,5,5)
这是主键id出现自增id不连续的第三种原因
五、自增主键用完了
自增主键字段在达到定义类型上限后,再插入一行记录,则会报主键冲突的错误
以无符号整型(4个字节,上限就是 2 32 − 1 2^{32}-1 232−1)为例,通过下面这个语句序列验证一下:
CREATE TABLE t ( id INT UNSIGNED auto_increment PRIMARY KEY ) auto_increment = 4294967295; INSERT INTO t VALUES(NULL); INSERT INTO t VALUES(NULL);
第一个insert语句插入数据成功后,这个表的AUTO_INCREMENT没有改变(还是4294967295),就导致了第二个insert语句又拿到相同的自增id值,再试图执行插入语句,报主键冲突错误
相关学习推荐:mysql教程(视频)
以上がMySQL の主キーの自動インクリメントの詳細については、こちらをご覧ください。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。