
ホームページ >データベース >mysql チュートリアル >MySQL のロック (グローバル ロック、テーブル レベルのロック、行ロック) についての深い理解
MySQL のロック (グローバル ロック、テーブル レベルのロック、行ロック) についての深い理解

- 青灯夜游転載
- 2021-08-31 10:43:552155ブラウズ
この記事では、MySQL のロックを理解し、MySQL のグローバル ロック、テーブル レベルのロック、行ロックについて紹介します。お役に立てば幸いです。

MySQL のロックは、ロックの範囲に応じて、グローバル ロック、テーブル レベル ロック、行ロックの 3 つのカテゴリに大別できます。
1. グローバル ロック
グローバル ロックは、データベース インスタンス全体をロックすることです。 MySQL にはグローバル読み取りロックを追加するメソッドが用意されており、そのコマンドは Flush tables with read lock です。ライブラリ全体を読み取り専用状態にする必要がある場合にこのコマンドを使用すると、他のスレッドのデータ更新ステートメント (データの追加、削除、変更)、データ定義ステートメントがブロックされます。 (テーブルの作成、テーブル構造の変更などを含む) およびトランザクションのコミット ステートメントを更新します。 [関連する推奨事項: mysql チュートリアル (ビデオ)]
グローバル ロックの一般的な使用シナリオは、データベース全体の論理バックアップを作成することです。つまり、データベース全体のすべてのテーブルを選択し、テキストとして保存します。
しかし、データベース全体を読み取り専用にすると、次の問題が発生する可能性があります。
- Ifメイン データベースでバックアップを実行すると、バックアップ期間中は更新を実行できなくなり、基本的にビジネスを停止する必要があります。
- バックアップがスレーブ データベースで実行される場合、スレーブ データベースはバイナリ ログを実行できません。バックアップ期間中にマスター データベースから同期されるため、マスターとスレーブの遅延が発生します。
反復読み取り分離レベルでトランザクションを開くと、一貫性ビューを取得できます
公式論理バックアップツールはmysqldumpです。 mysqldump がパラメータ --single-transaction を使用する場合、一貫したビューが確実に取得されるように、データをインポートする前にトランザクションが開始されます。 MVCC のサポートにより、このプロセス中にデータは正常に更新されます。単一トランザクションは、トランザクション エンジン ライブラリを使用するすべてのテーブルにのみ適用されます
1。ライブラリ全体が読み取り専用であるため、set global readonly=true を使用しないのはなぜですか?
- 一部のシステムでは、readonly の値は、ライブラリがメイン ライブラリであるかスタンバイ ライブラリであるかを決定するなど、他のロジックに使用されます。したがって、グローバル変数の変更方法の影響が大きくなります。
- 例外処理メカニズムに違いがあります。 Flush tables with read lock コマンドの実行後にクライアントが異常に切断した場合、MySQL は自動的にグローバル ロックを解放し、ライブラリ全体が通常に更新できる状態に戻ります。ライブラリ全体を読み取り専用に設定した後、クライアントで例外が発生すると、データベースは読み取り専用状態のままになり、ライブラリ全体が長期間書き込みできなくなり、リスクが高くなります
# 2. テーブル レベルのロック
MySQL には 2 種類のテーブル レベルのロックがあります。1 つはテーブル ロック、もう 1 つはメタ データ ロック (MDL)
テーブル ロックの構文は、ロック テーブル...読み取り/書き込みです。ロック解除テーブルを使用してアクティブにロックを解放することも、クライアントの切断時に自動的にロックを解放することもできます。ロック テーブル構文は、他のスレッドの読み取りと書き込みを制限するだけでなく、このスレッドの次の操作オブジェクトも制限します。 特定のスレッドで実行される場合 Alock tables t1 read,t2 wirte;このステートメントを使用すると、t1 の書き込みと t2 の読み書きを行う他のスレッドのステートメントがブロックされます。同時に、スレッド A は、ロック解除テーブルを実行する前に、t1 の読み取りと t2 の読み取りと書き込みの操作のみを実行できます。 t1 への書き込みさえ許可されません
MySQL バージョン 5.5 では、MDL が導入されました。テーブルの追加、削除、変更、クエリを実行する場合は、MDL 読み取りロックを追加します。テーブルの構造を変更する場合は、MDL 書き込みロックを追加します
- 読み取りロックは相互に排他的ではないため、複数のスレッドが同時にテーブルの追加、削除、変更、クエリを行うことができます
- 読み取りと書き込みロック、書き込みロックは相互に排他的であり、テーブル構造を変更する操作の安全性を確保するために使用されます。したがって、同時にテーブルにフィールドを追加する 2 つのスレッドがある場合、一方は実行を開始する前に、もう一方の実行が完了するまで待機する必要があります。
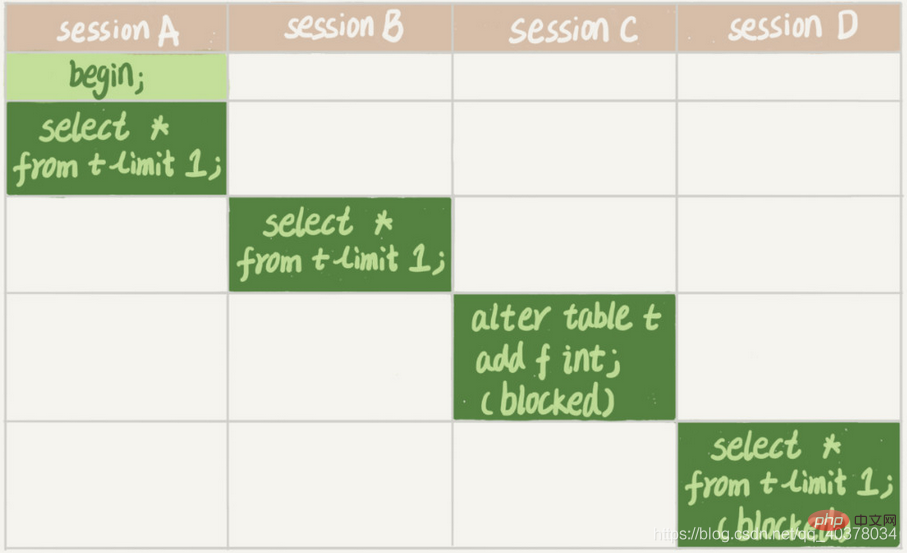 セッション A が最初に開始され、この時点で MDL 読み取りロックがテーブル t に追加されます。セッション B も MDL 読み取りロックを必要とするため、正常に実行できます。その後、セッション A の MDL 読み取りロックが解放されておらず、セッション C は MDL 書き込みロックが必要であるため、セッション C はブロックされます。そのため、ブロックすることしかできません。セッション C 自体のみがブロックされる場合は問題ありませんが、テーブル t に対する MDL 読み取りロックを適用する今後のすべてのリクエストもセッション C によってブロックされます。テーブルに対するすべての追加、削除、変更、およびクエリ操作は、まず MDL 読み取りロックを適用する必要があります。その後、すべてロックされます。つまり、テーブルは完全に読み取りおよび書き込み可能になります。
セッション A が最初に開始され、この時点で MDL 読み取りロックがテーブル t に追加されます。セッション B も MDL 読み取りロックを必要とするため、正常に実行できます。その後、セッション A の MDL 読み取りロックが解放されておらず、セッション C は MDL 書き込みロックが必要であるため、セッション C はブロックされます。そのため、ブロックすることしかできません。セッション C 自体のみがブロックされる場合は問題ありませんが、テーブル t に対する MDL 読み取りロックを適用する今後のすべてのリクエストもセッション C によってブロックされます。テーブルに対するすべての追加、削除、変更、およびクエリ操作は、まず MDL 読み取りロックを適用する必要があります。その後、すべてロックされます。つまり、テーブルは完全に読み取りおよび書き込み可能になります。
#トランザクション内の MDL ロックはステートメントの実行の開始時に適用されますが、ステートメントの終了直後には解放されず、トランザクション全体がコミットされた後に解放されます
1. 小さなテーブルにフィールドを安全に追加するには? まず、長いトランザクションを解決する必要があります。トランザクションが送信されないと、DML ロックは常に占有されてしまいます。 MySQL の information_schema ライブラリの innodb_trx テーブルで、現在実行されているトランザクションを見つけることができます。 DDL によって変更されるテーブルに長いトランザクションが実行されている場合は、最初に DDL を一時停止するか、長いトランザクションを強制終了することを検討してください。2. 変更されるテーブルがホットスポット テーブルの場合、データは大きくありませんが、上記のリクエストが非常に頻繁に発生するため、フィールドを追加する必要があります。 alter table ステートメントで待機時間を設定します。指定された待機時間内に MDL 書き込みロックを取得できれば最善です。取得できない場合は、後続のビジネス ステートメントをブロックせずに、最初に上がってください。次に、コマンドを再試行してプロセスを繰り返します#3. 行ロックMySQL の行ロックは、エンジン層の各エンジンによって実装されます。ただし、すべてのエンジンが行ロックをサポートしているわけではありません。たとえば、MyISAM エンジンは行ロックをサポートしていません。
行ロックは、データ テーブル内の行レコードに対するロックです。たとえば、トランザクション A が行を更新し、同時にトランザクション B も同じ行を更新したい場合、更新はトランザクション A の操作が完了するまで待つ必要があります。
1. 2-フェーズ ロック プロトコル トランザクション A が保持する 2 つのレコードの行ロックはコミットまで解放されません。トランザクション B の更新ステートメントは、トランザクション A がコミットを実行するまでブロックされます。実行を継続する
#トランザクション内で複数の行をロックする必要がある場合は、ロックの競合を引き起こす可能性が最も高く、同時実行性に影響を与える可能性が最も高いロックを配置する必要があります。できるだけ遡って
映画チケットのオンライン取引を実装したいと考えており、顧客 A が劇場 B で映画チケットを購入したいと考えているとします。ビジネスには次の操作が必要です:
1. 映画チケットの価格を顧客 A の口座残高から差し引く 2. 映画のチケット価格を劇場 B の口座残高に追加します 3. トランザクション ログを記録するトランザクションのアトミック性を確保するには、これら 3 つの操作を 1 つのトランザクションに含める必要があります。トランザクション内でこれら 3 つのステートメントの順序を調整するにはどうすればよいでしょうか? 劇場 B で同時にチケットを購入したい別の顧客 C がいる場合、2 つのトランザクション間の矛盾はステートメント 2 になります。同じ劇場アカウントの残高を更新したいため、同じデータ行を変更する必要があります。 2 フェーズ ロック プロトコルによれば、トランザクションがコミットされると、操作に必要なすべての行ロックが解放されます。したがって、ステートメント 2 を、たとえば 3、1、2 の順に最後に配置すると、劇場アカウント残高行のロック時間が最も短くなります。これにより、トランザクション間のロック待機が最小限に抑えられ、同時実行性が向上します。2. デッドロックとデッドロックの検出
同時システムでは、異なるスレッドでリソースの循環依存関係が発生します。関連するスレッドが他のスレッドがリソースを解放するのを待っている場合、これらのスレッドはデッドロックと呼ばれる無限待機状態になります
トランザクション A はトランザクション B が行ロックを解放するのを待っていますトランザクション B は、トランザクション A が id=1 の行ロックを解放するのを待っています。トランザクション A とトランザクション B は、互いのリソースが解放されるのを待っています。これは、トランザクション A とトランザクション B がデッドロック状態に入ったことを意味します。デッドロックが発生した場合、2 つの戦略があります。
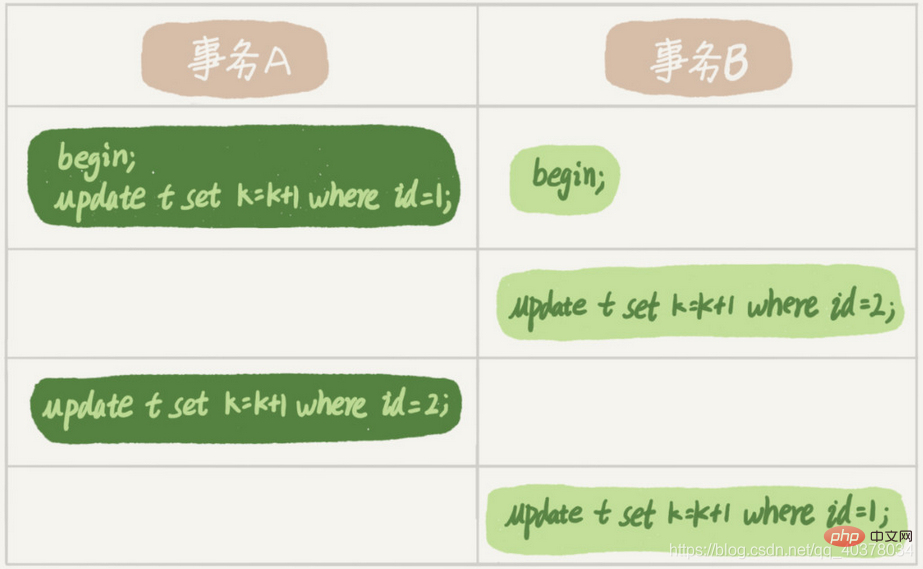
1 つの戦略は、タイムアウトになるまで直接待つことです。このタイムアウトは、パラメータ innodb_lock_wait_timeout で設定できます
- 別の戦略は、デッドロック検出を開始することです。デッドロックが見つかったら、他のトランザクションが実行を継続できるように、デッドロック チェーン内のトランザクションを積極的にロールバックします。パラメータ innodb_deadlock_detect を on に設定します。これは、このロジックをオンにすることを意味します。
- InnoDB では、innodb_lock_wait_timeout のデフォルト値は 50 秒です。つまり、最初の戦略が採用された場合、デッドロックが発生すると、最初の戦略が採用されます。 1 つは、ロックされたスレッドがタイムアウトして 50 秒後に終了し、その後、他のスレッドが実行を継続できることです。オンライン サービスの場合、この待機時間は許容できないことがよくあります。
3. ロックの競合を減らすために、1 行を複数の論理行に変更します。劇場アカウントを例にとると、10 レコードなどの複数のレコードに配置することを検討できます。劇場アカウントの合計金額は、これら 10 レコードの値の合計に等しくなります。このようにして、劇場アカウントにお金を追加するたびに、追加するレコードの 1 つをランダムに選択できます。このようにして、各競合の確率が元のメンバーの 1/10 になり、ロック待機の数が減り、デッドロック検出の CPU 消費量が削減されます。ステートメントを 1 行チェックしてください? 実行がとても遅いですか?
2 つのフィールド id と c を持つテーブルを構築し、そこに 100,000 行のレコードを挿入しますCREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=100000) do
insert into t values(i,i);
set i=i+1;
end while;
END
1. カテゴリ 1: 長いクエリ時間は返されません
select * from t3 where id=1;
クエリ結果が長時間返されません。show processlist コマンドを使用して現在のステートメントのステータスを確認してください
1)、MDL ロックを待ちます
下の図に示すように、show processlist;
コマンドを使用して、テーブル メタデータ ロックの待機の図を表示します。このステータスは、スレッドがテーブル t で MDL 書き込みロックを要求または保持しており、選択ステートメントをブロックしていることを示します。
シナリオの再発:
sessionA は、lock table コマンドを使用してテーブル t に対する MDL 書き込みロックを保持しており、sessionB のクエリは MDL 読み取りロックを取得する必要があります。したがって、セッション B は待機状態になります。
 この種の問題に対処する方法は、誰が MDL 書き込みロックを保持しているかを調べて、それを強制終了することです。ただし、show processlist の結果では、sessionA の Command 列が Sleep になっており、検索が不便ですが、sys.schema_table_lock_waits テーブルをクエリすることで、ブロッキングの原因となっているプロセス ID を直接知ることができ、kill で接続を切断することができます。コマンド (MySQL を起動するときに、performance_schema=on を設定する必要があります。off に設定する場合と比較して、約 10% のパフォーマンスが低下します)
この種の問題に対処する方法は、誰が MDL 書き込みロックを保持しているかを調べて、それを強制終了することです。ただし、show processlist の結果では、sessionA の Command 列が Sleep になっており、検索が不便ですが、sys.schema_table_lock_waits テーブルをクエリすることで、ブロッキングの原因となっているプロセス ID を直接知ることができ、kill で接続を切断することができます。コマンド (MySQL を起動するときに、performance_schema=on を設定する必要があります。off に設定する場合と比較して、約 10% のパフォーマンスが低下します)
select blocking_pid from sys.schema_table_lock_waits;
2)、flush を待ちます
##テーブル内の# t で次の SQL ステートメントを実行します。 select * from information_schema.processlist where id=1;
特定のスレッドのステータスがテーブルのフラッシュを待機していることがわかります。
flush tables t with read lock;flush tables with read lock;
これら 2 つのフラッシュ ステートメントは、テーブル t が指定されている場合、テーブル t のみが閉じられることを意味し、特定のテーブル名が指定されていない場合、 は、を意味します。 MySQL で開いているすべてのテーブルを閉じる

しかし、通常の状況では、他のスレッドによってブロックされない限り、これら 2 つのステートメントは非常に高速に実行されます
したがって、「待機中」が表示されます。テーブル フラッシュ ステータスの考えられる状況は次のとおりです。 : テーブルのフラッシュ コマンドが他のステートメントによってブロックされ、その後 select ステートメントがブロックされます。
シナリオの繰り返し:セッション A では、sleep( 1) は行ごとに 1 回呼び出されるため、このステートメントはデフォルトで 100,000 秒間実行されます。この期間中、テーブル t はセッション A によって開かれています。次に、セッション B がテーブル t をフラッシュしてからテーブル t を閉じるとき、セッション A のクエリが終了するまで待つ必要があります。このようにして、sessionC が再度クエリを実行したい場合、フラッシュ コマンド

3) によってブロックされ、行ロックを待機します
select * from t where id=1 lock in share mode;
アクセス ID= 1 であるため、このレコードに読み取りロックを追加する必要があります。この時点で、このレコードに対する書き込みロックを保持しているトランザクションがすでに存在する場合、select ステートメントはブロックされます
シナリオ繰り返し:
セッション A がトランザクションを開始し、書き込みロックを占有し、送信しませんでした。これがセッション B がブロックされた理由です。

 2. カテゴリ 2 : クエリが遅い
2. カテゴリ 2 : クエリが遅い
sessionA はまず、一貫性のあるスナップショット コマンドを使用してトランザクション開始を使用してトランザクションを開き、トランザクションの一貫性のある読み取りを確立します (また、スナップショット読み取りと呼ばれます。MVCC メカニズムは、アンドゥ ログ内の送信されたデータを取得するために使用されます。したがって、その読み取りはノンブロッキングです)、その後セッション B が更新ステートメントを実行します
セッション B が 100 万回の更新ステートメントを実行した後、 100 万件のロールバック ログが生成されます
带lock in share mode的语句是当前读,因此会直接读到1000001这个结果,速度很快;而select * from t where id=1这个语句是一致性读,因此需要从1000001开始,依次执行undo log,执行了100万次以后,才将1这个结果返回
五、间隙锁
建表和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
这个表除了主键id外,还有一个索引c
为了解决幻读问题,InnoDB引入了间隙锁,锁的就是两个值之间的空隙
当执行select * from t where d=5 for update的时候,就不止是给数据库中已有的6个记录加上了行锁,还同时加了7个间隙锁。这样就确保了无法再插入新的记录
行锁分成读锁和写锁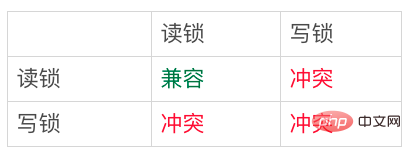
跟间隙锁存在冲突关系的是往这个间隙中插入一个记录这个操作。间隙锁之间不存在冲突关系
这里sessionB并不会被堵住。因为表t里面并没有c=7会这个记录,因此sessionA加的是间隙锁(5,10)。而sessionB也是在这个间隙加的间隙锁。它们用共同的目标,保护这个间隙,不允许插入值。但它们之间是不冲突的
间隙锁和行锁合称next-key lock,每个next-key lock是前开后闭区间。表t初始化以后,如果用select * from t for update要把整个表所有记录锁起来,就形成了7个next-key lock,分别是(-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。因为+∞是开区间,在实现上,InnoDB给每个索引加了一个不存在的最大值supremum,这样才符合都是前开后闭区间
间隙锁和next-key lock的引入,解决了幻读的问题,但同时也带来了一些困扰
间隙锁导致的死锁:
1.sessionA执行select … for update语句,由于id=9这一行并不存在,因此会加上间隙锁(5,10)
2.sessionB执行select … for update语句,同样会加上间隙锁(5,10),间隙锁之间不会冲突
3.sessionB试图插入一行(9,9,9),被sessionA的间隙锁挡住了,只好进入等待
4.sessionA试图插入一行(9,9,9),被sessionB的间隙锁挡住了
两个session进入互相等待状态,形成了死锁
间隙锁的引入可能会导致同样的语句锁住更大的范围,这其实是影响并发度的
在读提交隔离级别下,不存在间隙锁
六、next-key lock
表t的建表语句和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
1、next-key lock加锁规则
- 原则1:加锁的基本单位是next-key lock,next-key lock是前开后闭区间
- 原则2:查找过程中访问到的对象才会加锁
- 优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁
- 优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁
- 一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止
这个规则只限于MySQL5.x系列
2、案例一:等值查询间隙锁

1.由于表t中没有id=7的记录,根据原则1,加锁单位是next-key lock,sessionA加锁范围就是(5,10]
2.根据优化2,这是一个等值查询(id=7),而id=10不满足查询条件,next-key lock退化成间隙锁,因此最终加锁的范围是(5,10)
所以,sessionB要往这个间隙里面插入id=8的记录会被锁住,但是sessionC修改id=10这行是可以的
3、案例二:非唯一索引等值锁
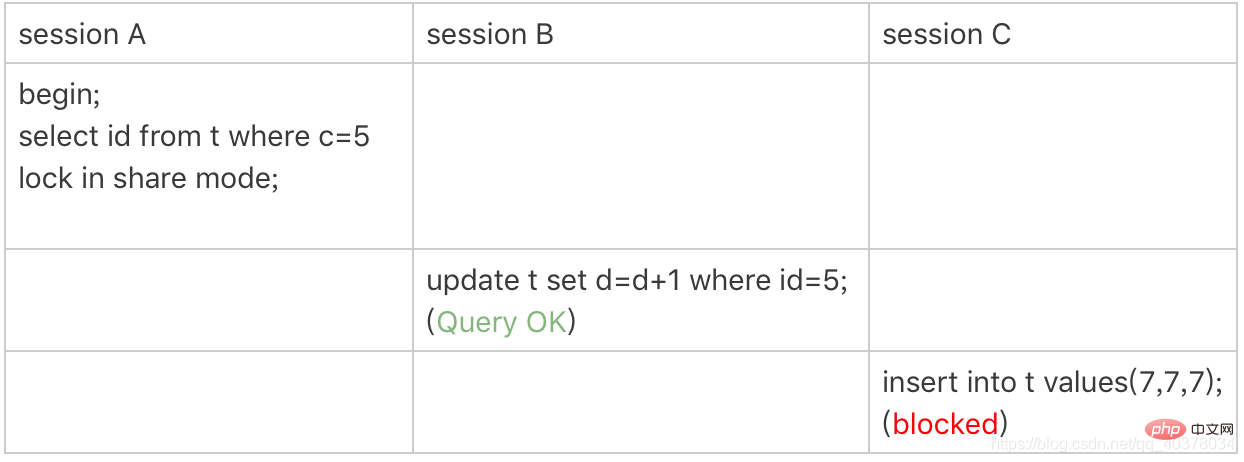
1.根据原则1,加锁单位是next-key lock,因此会给(0,5]加上next-key lock
2.c是普通索引,因此访问c=5这一条记录是不能马上停下来的,需要向右遍历,查到c=10才放弃。根据原则2,访问到的都要加锁,因此要给(5,10]加next-key lock
3.根据优化2,等值判断,向右遍历,最后一个值不满足c=5这个等值条件,因此退化成间隙锁(5,10)
4.根据原则2,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有任何锁,这就是为什么sessionB的update语句可以执行完成
锁是加在索引上的,在这个例子中,lock in share mode只锁覆盖索引,但是如果是for update,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁,这样的话sessionB的update语句会被阻塞住。如果你要用 lock in share mode 来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段
4、案例三:主键索引范围锁

1.开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10]。根据优化1,主键id上的等值条件,退化成行锁,只加了id=10这一行的行锁
2.范围查询就往后继续找,找到id=15这一行停下来,因此需要加next-key lock(10,15]
所以,sessionA这时候锁的范围就是主键索引上,行锁id=10和next-key lock(10,15]
5、案例四:非唯一索引范围锁
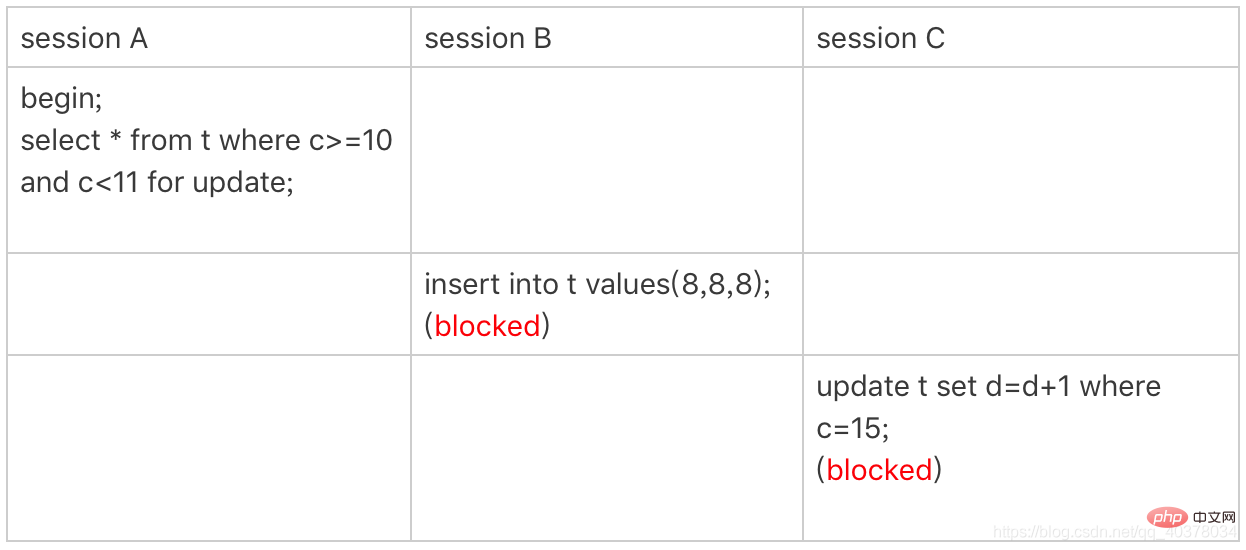
这次sessionA用字段c来判断,加锁规则跟案例三唯一的不同是:在第一次用c=10定位记录的时候,索引c上加上(5,10]这个next-key lock后,由于索引c是非唯一索引,没有优化规则,因此最终sessionA加的锁是索引c上的(5,10]和(10,15]这两个next-key lock
6、案例五:唯一索引范围锁bug
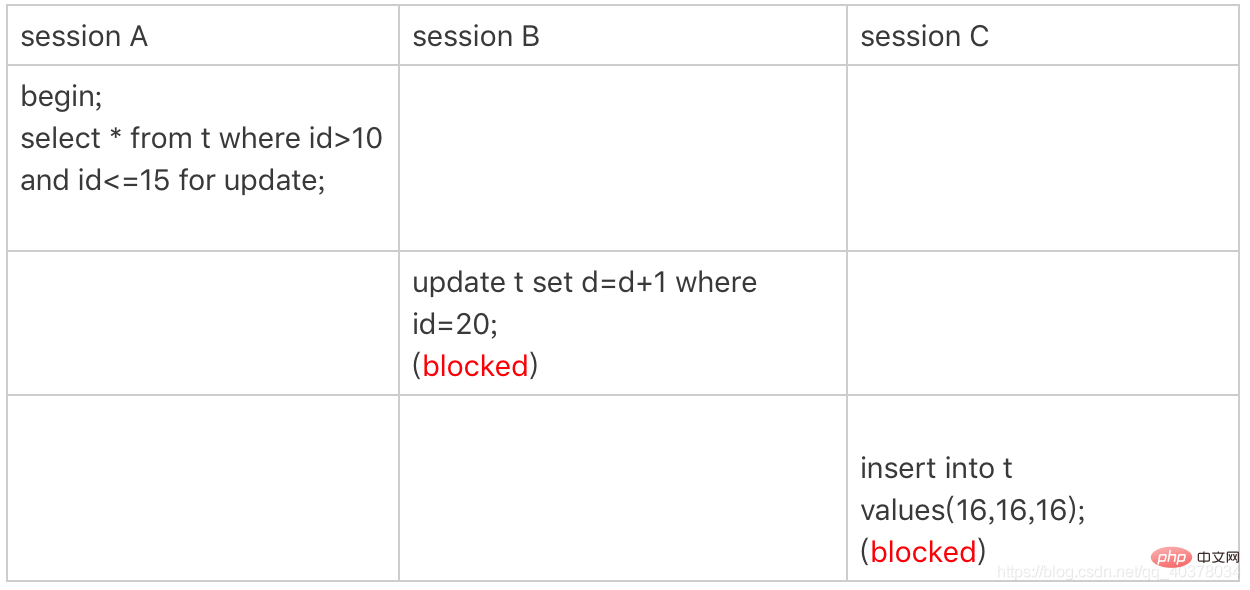
sessionA是一个范围查询,按照原则1的话,应该是索引id上只加(10,15]这个next-key lock,并且因为id是唯一键,所以循环判断到id=15这一行就应该停止了
但是实现上,InnoDB会扫描到第一个不满足条件的行为止,也就是id=20。而且由于这是个范围扫描,因此索引id上的(15,20]这个next-key lock也会被锁上
所以,sessionB要更新id=20这一行是会被锁住的。同样地,sessionC要插入id=16的一行,也会被锁住
7、案例六:非唯一索引上存在等值的例子
insert into t values(30,10,30);
新插入的这一行c=10,现在表里有两个c=10的行。虽然有两个c=10,但是它们的主键值id是不同的,因此这两个c=10的记录之间也是有间隙的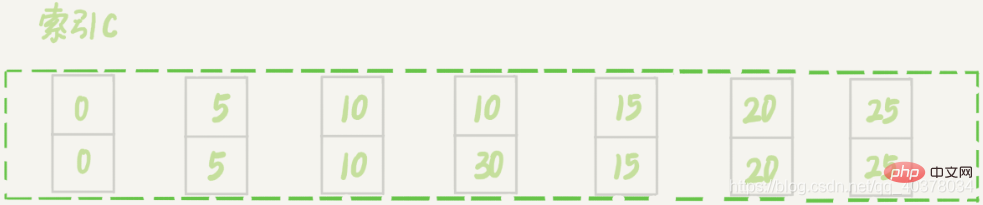
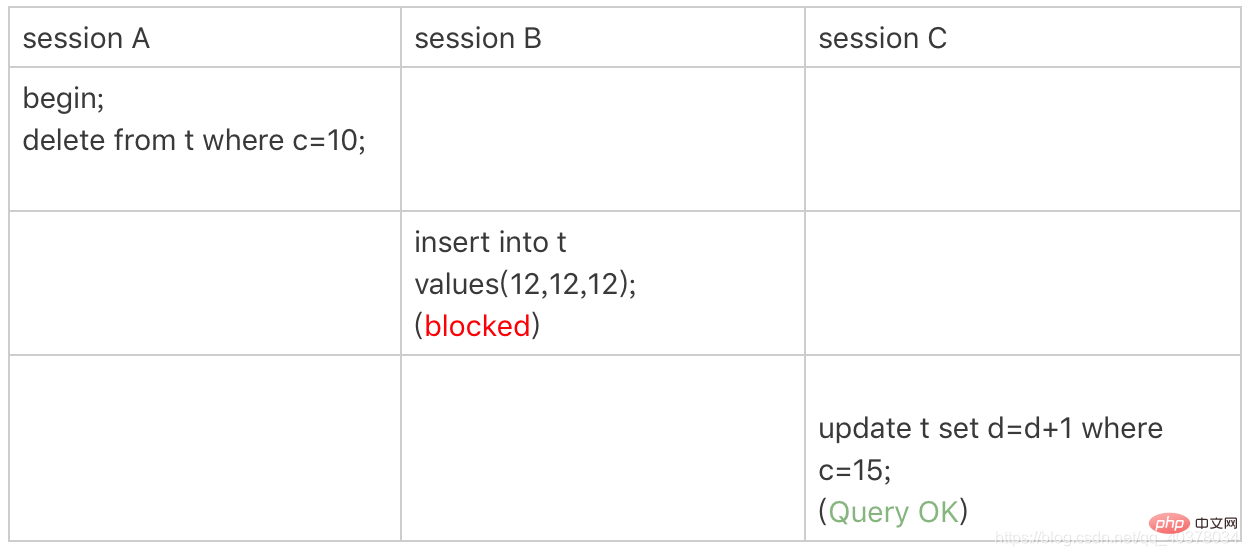
sessionA在遍历的时候,先访问第一个c=10的记录。根据原则1,这里加的是(c=5,id=5)到(c=10,id=10)这个next-key lock。然后sessionA向右查找,直到碰到(c=15,id=15)这一行,循环才结束。根据优化2,这是一个等值查询,向右查找到了不满足条件的行,所以会退化成(c=10,id=10)到(c=15,id=15)的间隙锁
也就是说,这个delete语句在索引c上的加锁范围,就是下图中蓝色区域覆盖的部分,这个蓝色区域左右两边都是虚线,表示开区间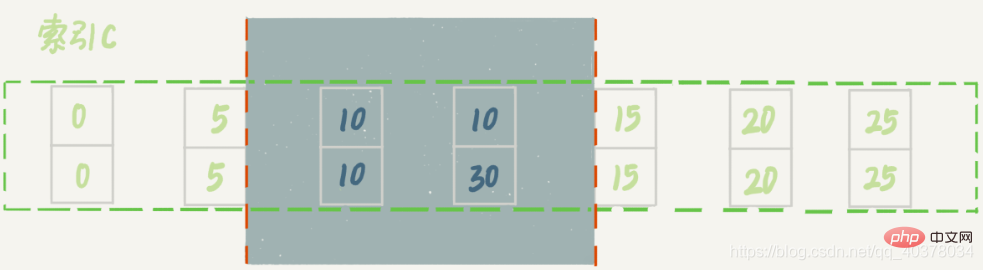
8、案例七:limit语句加锁

加了limit 2的限制,因此在遍历到(c=10,id=30)这一行之后,满足条件的语句已经有两条,循环就结束了。因此,索引c上的加锁范围就变成了从(c=5,id=5)到(c=10,id=30)这个前开后闭区间,如下图所示:
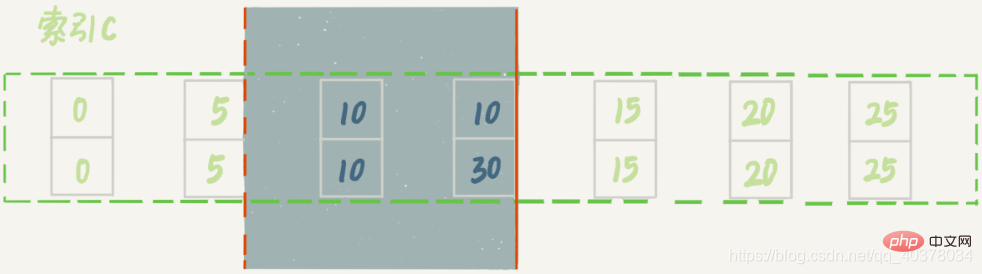
再删除数据的时候尽量加limit,这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围
9、案例八:一个死锁的例子

1.sessionA启动事务后执行查询语句加lock in share mode,在索引c上加了next-key lock(5,10]和间隙锁(10,15)
2.sessionB的update语句也要在索引c上加next-key lock(5,10],进入锁等待
3.然后sessionA要再插入(8,8,8)这一行,被sessionB的间隙锁锁住。由于出现了死锁,InnoDB让sessionB回滚
sessionB的加next-key lock(5,10]操作,实际上分成了两步,先是加(5,10)间隙锁,加锁成功;然后加c=10的行锁,这时候才被锁住的
七、用动态的观点看加锁
表t的建表语句和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
1、不等号条件里的等值查询
begin; select * from t where id>9 and id<12 order by id desc for update;
利用上面的加锁规则,这个语句的加锁范围是主键索引上的(0,5]、(5,10]和(10,15)。加锁单位是next-key lock,这里用到了优化2,即索引上的等值查询,向右遍历的时候id=15不满足条件,所以next-key lock退化为了间隙锁(10,15)

1.首先这个查询语句的语义是order by id desc,要拿到满足条件的所有行,优化器必须先找到第一个id
2.这个过程是通过索引树的搜索过程得到的,在引擎内部,其实是要找到id=12的这个值,只是最终没找到,但找到了(10,15)这个间隙
3.然后根据order by id desc,再向左遍历,在遍历过程中,就不是等值查询了,会扫描到id=5这一行,所以会加一个next-key lock (0,5]
在执行过程中,通过树搜索的方式定位记录的时候,用的是等值查询的方法
2、等值查询的过程
begin; select id from t where c in(5,20,10) lock in share mode;

这条in语句使用了索引c并且rows=3,说明这三个值都是通过B+树搜索定位的
在查找c=5的时候,先锁住了(0,5]。但是因为c不是唯一索引,为了确认还有没有别的记录c=5,就要向右遍历,找到c=10确认没有了,这个过程满足优化2,所以加了间隙锁(5,10)。执行c=10会这个逻辑的时候,加锁的范围是(5,10]和(10,15),执行c=20这个逻辑的时候,加锁的范围是(15,20]和(20,25)
这条语句在索引c上加的三个记录锁的顺序是:先加c=5的记录锁,再加c=10的记录锁,最后加c=20的记录锁
select id from t where c in(5,20,10) order by c desc for update;
由于语句里面是order by c desc,这三个记录锁的加锁顺序是先锁c=20,然后c=10,最后是c=5。这两条语句要加锁相同的资源,但是加锁顺序相反。当这两条语句并发执行的时候,就可能出现死锁
八、insert语句的锁为什么这么多?
1、insert … select语句
表t和t2的表结构、初始化数据语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t;
在可重复读隔离级别下,binlog_format=statement时执行下面这个语句时,需要对表t的所有行和间隙加锁
insert into t2(c,d) select c,d from t;
2、insert循环写入
要往表t2中插入一行数据,这一行的c值是表t中c值的最大值加1,SQL语句如下:
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
这个语句的加锁范围,就是表t索引c上的(3,4]和(4,supermum]这两个next-key lock,以及主键索引上id=4这一行
执行流程是从表t中按照索引c倒序吗,扫描第一行,拿到结果写入到表t2中,因此整条语句的扫描行数是1
但如果要把这一行的数据插入到表t中的话:
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);

explain结果中的Extra字段中Using temporary字段,表示这个语句用到了临时表
执行流程如下:
1.创建临时表,表里有两个字段c和d
2.按照索引c扫描表t,依次取c=4、3、2、1,然后回表,读到c和d的值写入临时表
3.由于语义里面有limit 1,所以只取了临时表的第一行,再插入到表t中
这个语句会导致在表t上做全表扫描,并且会给索引c上的所有间隙都加上共享的next-key lock。所以,这个语句执行期间,其他事务不能在这个表上插入数据
需要临时表是因为这类一边遍历数据,一边更新数据的情况,如果读出来的数据直接写回原表,就可能在遍历过程中,读到刚刚插入的记录,新插入的记录如果参与计算逻辑,就跟语义不符
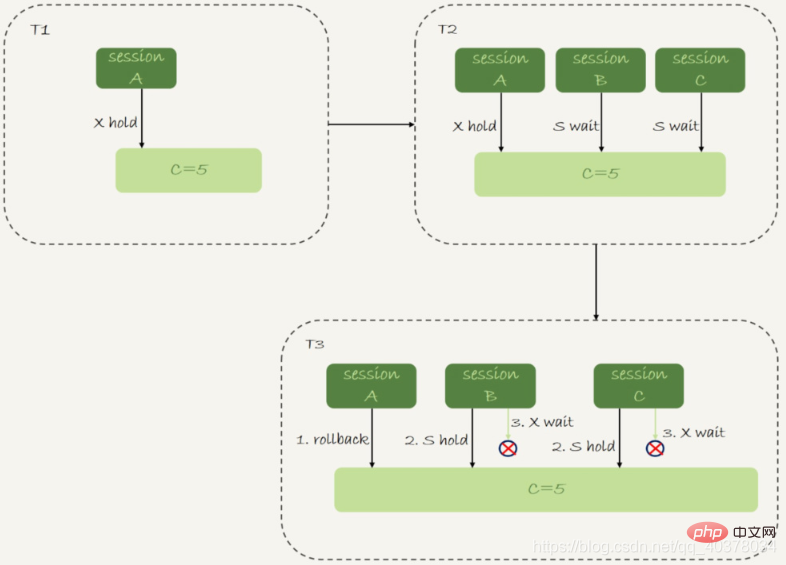
3、insert唯一键冲突

sessionA执行的insert语句,发生唯一键冲突的时候,并不只是简单地报错返回,还在冲突的索引上加了锁,sessionA持有索引c上的(5,10]共享next-key lock(读锁)

在sessionA执行rollback语句回滚的时候,sessionC几乎同时发现死锁并返回
1.在T1时刻,启动sessionA,并执行insert语句,此时在索引c的c=5上加了记录锁。这个索引是唯一索引,因此退化为记录锁
2.在T2时刻,sessionA回滚。这时候,sessionB和sessionC都试图继续执行插入操作,都要加上写锁。两个session都要等待对方的行锁,所以就出现了死锁
4、insert into … on duplicate key update
上面这个例子是主键冲突后直接报错,如果改写成
insert into t values(11,10,10) on duplicate key update d=100;
就会给索引c上(5,10]加一个排他的next-key lock(写锁)
insert into … on duplicate key update的语义逻辑是,插入一行数据,如果碰到唯一键约束,就继续执行后面的更新语句。如果有多个列违反了唯一性索引,就会按照索引的顺序,修改跟第一个索引冲突的行
表t里面已经有了(1,1,1)和(2,2,2)这两行,执行这个语句效果如下:
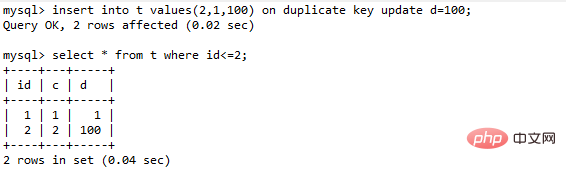
主键id是先判断的,MySQL认为这个语句跟id=2这一行冲突,所以修改的是id=2的行
思考题:
1、如果要删除一个表里面的前10000行数据,有以下三种方法可以做到:
- 第一种,直接执行
delete from T limit 10000; - 第二种,在一个连接中循环执行20次
delete from T limit 500; - 第三种,在20个连接中同时执行
delete from T limit 500;
选择哪一种方式比较好?
参考答案:
第一种方式,单个语句占用时间长,锁的时间也比较长,而且大事务还会导致主从延迟
第三种方式,会人为造成锁冲突
第二种方式相对较好
更多编程相关知识,请访问:编程入门!!
以上がMySQL のロック (グローバル ロック、テーブル レベルのロック、行ロック) についての深い理解の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。