
Redis を使用するときに遭遇する可能性のある 15 の落とし穴。雷を避けるために、ぜひそれらを集めてください。 !

- 青灯夜游転載
- 2021-04-21 10:46:233329ブラウズ
この記事では、Redis を使用するときに遭遇する可能性のある 15 の落とし穴を紹介します。一定の参考値があるので、困っている友達が参考になれば幸いです。

皆さんこんにちは、Kaitoです。
この記事では、Redis を使用するときに遭遇する可能性のある「落とし穴」についてお話したいと思います。
Redis の使用中に次のような「奇妙な」シナリオに遭遇した場合は、「落とし穴」に足を踏み入れている可能性が高くなります。キーには有効期限が設定されていますが、なぜ有効期限が切れないのでしょうか?
O(1) 複雑さの SETBIT コマンドを使用すると、Redis が OOM されましたか?
RANDOMKEY を実行してキーをランダムに選択すると、Redis がブロックされますか?
同じコマンドを使用しても、マスター データベースではデータが見つからないのに、スレーブ データベースではデータが見つかるのはなぜですか?
スレーブ ライブラリがメイン ライブラリよりも多くのメモリを使用するのはなぜですか?
Redis に書き込まれたデータが原因不明で失われるのはなぜですか?
...
-
[関連する推奨事項:
Redis ビデオ チュートリアル ]
とは正確には何ですか?これらの問題の原因は何でしょうか? この記事では、Redis を使用するときに遭遇する可能性のある落とし穴とその回避方法を一緒に確認します。
これらの質問を 3 つの部分に分けました:
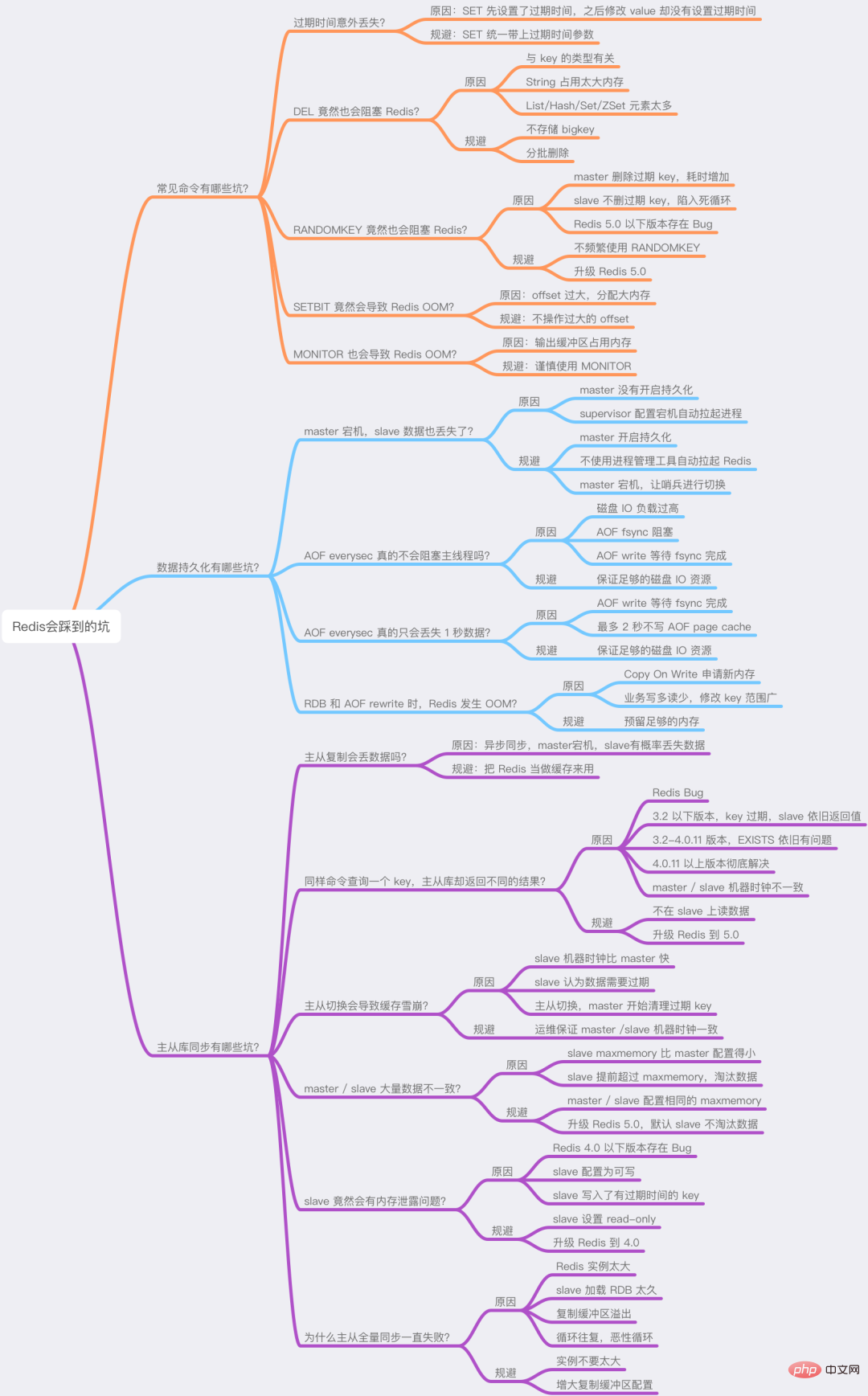
一般的なコマンドの落とし穴は何ですか?
データ永続化の落とし穴は何ですか?
マスター/スレーブデータベース同期の落とし穴は何ですか?
これらの問題を引き起こす理由は、あなたの理解を「覆す」可能性があります。準備ができたら、私の考えに従って始めてください。
一般的なコマンドの落とし穴は何ですか? 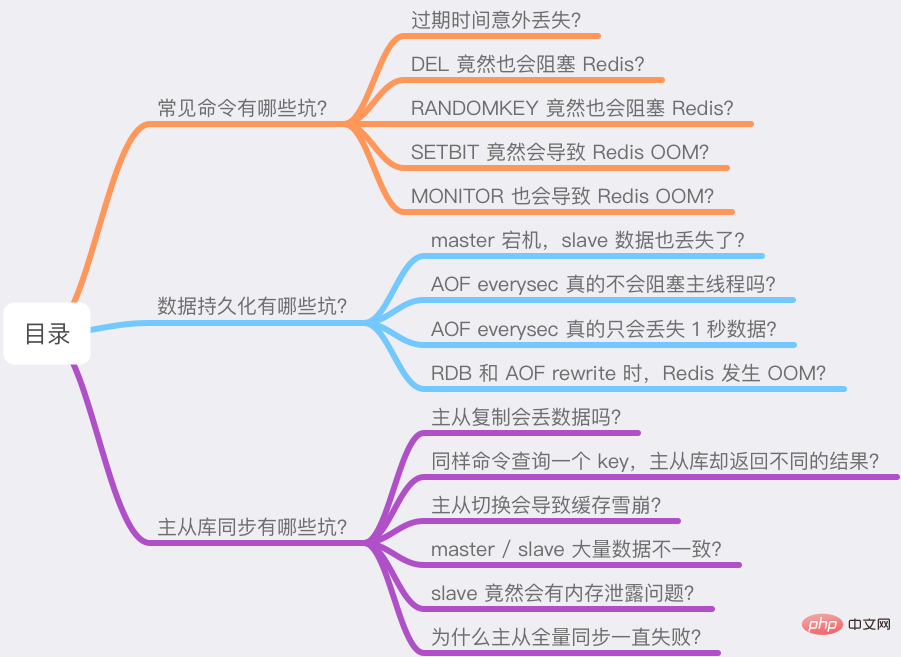
まず、Redis の使用時に「予期しない」結果が発生する一般的なコマンドをいくつか見てみましょう。
1) 有効期限を誤って紛失してしまいましたか?Redis を使用する場合、SET コマンドを使用することがよくありますが、これは非常に簡単です。 キーと値の設定に加えて、SET は次のようにキーの有効期限を設定することもできます。
127.0.0.1:6379> SET testkey val1 EX 60 OK 127.0.0.1:6379> TTL testkey (integer) 59
この時点で、キーの値を変更したい場合は、ただし、単に「有効期限」パラメータを追加せずに SET コマンドを使用すると、このキーの有効期限は「消去」されます。
rreeee見ましたか?テストキーは期限切れになりません!
#Redis を使い始めたばかりの方は、きっとこの落とし穴を踏んだことがあると思います。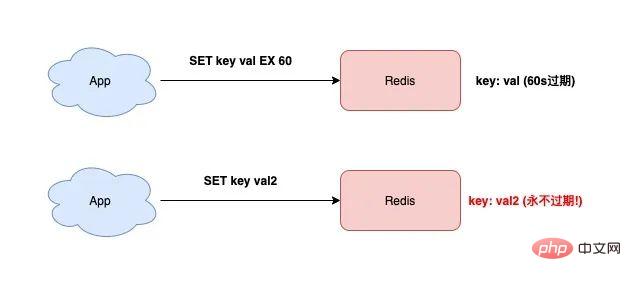 この問題の理由は次のとおりです。
この問題の理由は次のとおりです。
Redis のメモリが増加し続け、多くのキーに元々有効期限が設定されていたのに、後で有効期限が失われていることが判明した場合は、おそらくこの理由が原因です。 現時点では、Redis 内に期限切れになっていないキーが大量に存在し、メモリ リソースを過剰に消費します。
したがって、SET コマンドを使用するときに、最初に有効期限を設定すると、後でキーを変更するときに、有効期限が失われる問題を避けるために有効期限パラメータも追加する必要があります。 。
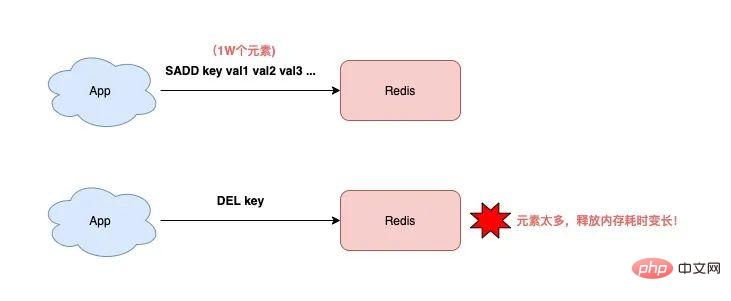
2) DEL は Redis をブロックすることもできますか?キーを削除するには、必ず DEL コマンドを使用しますが、その時間の複雑さについて考えたことはないのでしょうか? O(1)?必ずしも。
Redis の公式ドキュメントを注意深く読むと、次のことがわかります。
キーの削除にかかる時間は、キーのタイプに関係します。Redis 公式ドキュメントでは、DEL コマンドについて次のように説明されています。
key は String 型で、DEL の時間計算量は O(1)
- #key は List/Hash/Set/ZSet タイプ、DEL の時間計算量は O(M)、M は要素の数
- #Inつまり、文字列型以外のキーを削除する場合、キーの要素が多いほど、DEL の実行に時間がかかります。 #########どうしてこれなの?
理由は、この種のキーを削除する場合、Redis は各要素のメモリを順番に解放する必要があり、要素の数が増えるほど、このプロセスに時間がかかります。
このように長い操作を行うと、必然的に Redis インスタンス全体がブロックされ、Redis のパフォーマンスに影響を与えます。

したがって、List/Hash/Set/ZSet タイプのキーを削除する場合は、特に注意する必要があり、何も考えずに DEL を実行することはできません。以下のメソッドで削除します。
要素数を問い合わせます。 LLEN/HLEN/SCARD/ZCARD コマンドを実行します。
#要素数を判断します。要素数が少ない場合は、直接 DEL 削除を実行できます。要素数が少ない場合は、一括で削除します。
一括で削除: LRANGE/HSCAN/SSCAN/ZSCAN LPOP/RPOP/HDEL/SREM を実行します。 /ZREM 削除
Redis 4.0 ではレイジーフリー メカニズムが導入されていませんでしたか?この機構をオンにすると、メモリ解放の操作がバックグラウンドスレッドで実行されることになりますが、メインスレッドをブロックすることはありませんか?
これはとても良い質問です。 これは本当にそうなのでしょうか? ここで結論を先に言います:Redis がレイジーフリーを有効にしても、String 型の bigkey を削除すると、バックグラウンド スレッドで実行されるのではなく、メイン スレッドで処理されます。 . .したがって、Redis をブロックするリスクが依然として存在します。 #########何故ですか? ここにヒントがあります。興味のある学生は、まずレイジーフリー関連情報を確認して答えを見つけてください。 :)
実は、レイジーフリーに関するナレッジポイントはたくさんあります。スペースの都合上、後で特別な記事を書く予定です。引き続き注目してください~3) RANDOMKEY は Redis をブロックすることもできますか?
Redis でキーをランダムに表示する場合は、通常、RANDOMKEY コマンドを使用します。 このコマンドは、Redis からキーを「ランダムに」抽出します。
ランダムなので実行速度はかなり速いはずですよね?
実際にはそうではありません。
この問題を明確に説明するには、この問題を Redis の有効期限戦略と組み合わせる必要があります。
Redis の有効期限戦略について何か知っている場合は、Redis がスケジュールされたクリーニングと遅延クリーニングの組み合わせを使用して期限切れのキーをクリーンアップすることを知っているはずです。
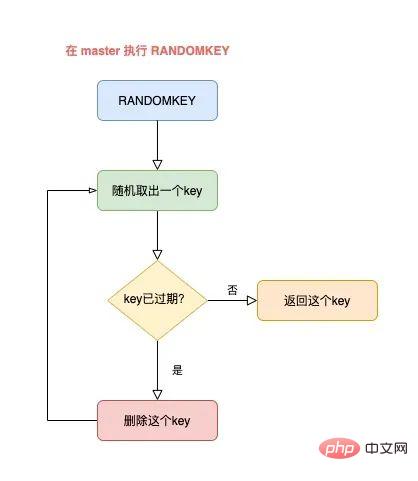
RANDOMKEY はランダムにキーを取り出した後、まずキーの有効期限が切れているかどうかを確認します。
キーの有効期限が切れている場合、Redis はキーを削除します。このプロセスは
lazy cleanupです。
しかしクリーンアップはまだ終わっていないため、Redis は「期限切れでない」キーを見つけてクライアントに返す必要があります。 現時点では、Redis はキーをランダムに取り出し、有効期限が切れていないキーが見つかってクライアントに返されるまで、キーの有効期限が切れているかどうかを判断し続けます。
全体のプロセスは次のようになります:
マスターはランダムにキーを取り出し、それが期限切れかどうかを判断します
Ifキーの有効期限が切れている場合は、キーを削除し、引き続きキー
- # をランダムに選択し、有効期限が切れていないキーが見つかるまでこのサイクルを繰り返し、## を返します。 #しかし、ここに質問があります:
- 現時点で Redis で多数のキーが期限切れになっているが、まだクリーンアップされていない場合、このサイクルは終了するまで長期間続くことになります。期限切れのキーをクリーンアップして検索するのに時間がかかりますが、キーの有効期限は切れていません。
导致的结果就是,RANDOMKEY 执行耗时变长,影响 Redis 性能。
以上流程,其实是在 master 上执行的。
如果在 slave 上执行 RANDOMEKY,那么问题会更严重!
为什么?
主要原因就在于,slave 自己是不会清理过期 key。
那 slave 什么时候删除过期 key 呢?
其实,当一个 key 要过期时,master 会先清理删除它,之后 master 向 slave 发送一个 DEL 命令,告知 slave 也删除这个 key,以此达到主从库的数据一致性。
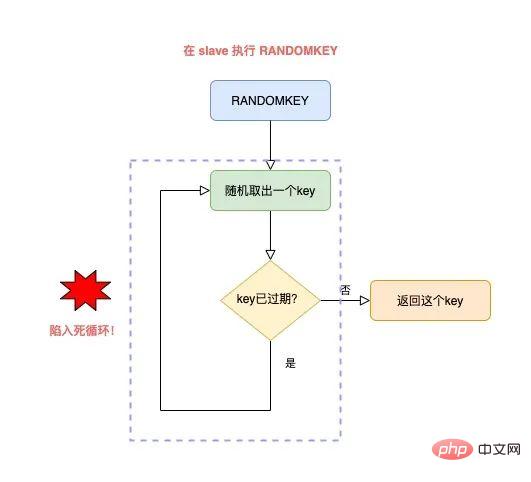
还是同样的场景:Redis 中存在大量已过期,但还未被清理的 key,那在 slave 上执行 RANDOMKEY 时,就会发生以下问题:
slave 随机取出一个 key,判断是否已过期
key 已过期,但 slave 不会删除它,而是继续随机寻找不过期的 key
由于大量 key 都已过期,那 slave 就会寻找不到符合条件的 key,此时就会陷入「死循环」!
也就是说,在 slave 上执行 RANDOMKEY,有可能会造成整个 Redis 实例卡死!
是不是没想到?在 slave 上随机拿一个 key,竟然有可能造成这么严重的后果?
这其实是 Redis 的一个 Bug,这个 Bug 一直持续到 5.0 才被修复。
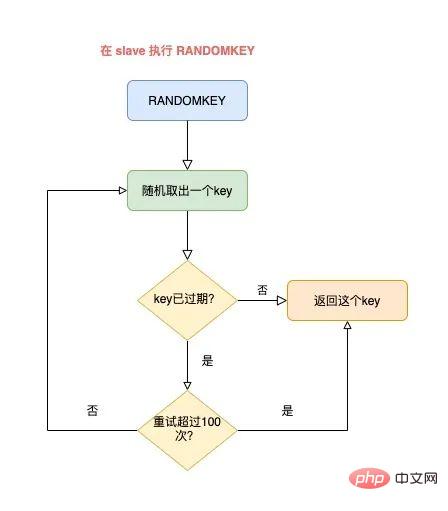
修复的解决方案是,在 slave 上执行 RANDOMKEY 时,会先判断整个实例所有 key 是否都设置了过期时间,如果是,为了避免长时间找不到符合条件的 key,slave 最多只会在哈希表中寻找 100 次,无论是否能找到,都会退出循环。
这个方案就是增加上了一个最大重试次数,这样一来,就避免了陷入死循环。
虽然这个方案可以避免了 slave 陷入死循环、卡死整个实例的问题,但是,在 master 上执行这个命令时,依旧有概率导致耗时变长。
所以,你在使用 RANDOMKEY 时,如果发现 Redis 发生了「抖动」,很有可能是因为这个原因导致的!
4) O(1) 复杂度的 SETBIT,竟然会导致 Redis OOM?
在使用 Redis 的 String 类型时,除了直接写入一个字符串之外,还可以把它当做 bitmap 来用。
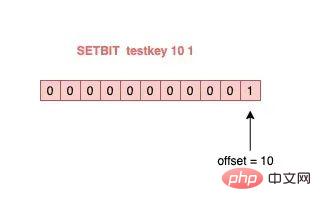
具体来讲就是,我们可以把一个 String 类型的 key,拆分成一个个 bit 来操作,就像下面这样:
127.0.0.1:6379> SETBIT testkey 10 1 (integer) 1 127.0.0.1:6379> GETBIT testkey 10 (integer) 1
其中,操作的每一个 bit 位叫做 offset。
但是,这里有一个坑,你需要注意起来。
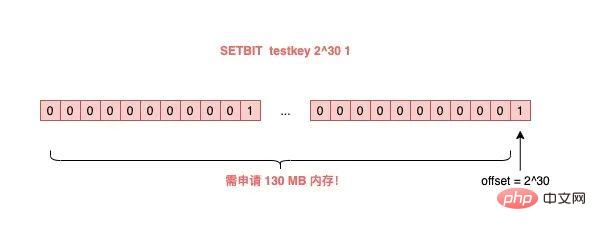
如果这个 key 不存在,或者 key 的内存使用很小,此时你要操作的 offset 非常大,那么 Redis 就需要分配「更大的内存空间」,这个操作耗时就会变长,影响性能。
所以,当你在使用 SETBIT 时,也一定要注意 offset 的大小,操作过大的 offset 也会引发 Redis 卡顿。
这种类型的 key,也是典型的 bigkey,除了分配内存影响性能之外,在删除它时,耗时同样也会变长。
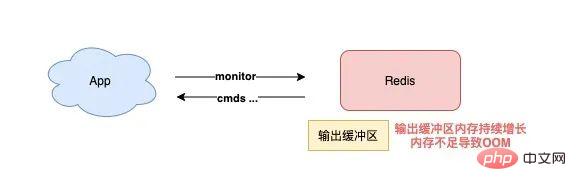
5) 执行 MONITOR 也会导致 Redis OOM?
这个坑你肯定听说过很多次了。
当你在执行 MONITOR 命令时,Redis 会把每一条命令写到客户端的「输出缓冲区」中,然后客户端从这个缓冲区读取服务端返回的结果。
但是,如果你的 Redis QPS 很高,这将会导致这个输出缓冲区内存持续增长,占用 Redis 大量的内存资源,如果恰好你的机器的内存资源不足,那 Redis 实例就会面临被 OOM 的风险。
したがって、特に QPS が高い場合には、MONITOR を慎重に使用する必要があります。
上記の問題シナリオはすべて、一般的なコマンドを使用するときに発生し、「意図せずに」引き起こされる可能性があります。
Redis の「データ永続性」の落とし穴を見てみましょう。
データ永続化の落とし穴は何ですか?
Redis データの永続化は、RDB と AOF の 2 つの方法に分かれています。
その中で、RDB はデータのスナップショットであり、AOF はすべての書き込みコマンドをログ ファイルに記録します。
データの永続化に関する問題は主にこれら 2 つのブロックに集中しています。順番に見ていきましょう。
1) マスターがダウンし、スレーブのデータも失われますか?
Redis が次のモードでデプロイされている場合、データ損失が発生します:
マスター/スレーブ センチネル デプロイメント インスタンス
マスターはデータ永続化機能を有効にしていません
- #Redis プロセスはスーパーバイザーによって管理され、「プロセスがクラッシュして自動的に再起動する」ように構成されています
- マスターがダウンしており、センチネルは切り替えを開始していません。マスター プロセスは、スーパーバイザによってすぐに自動的にプルアップされます。
- ただし、マスターではデータの永続性が有効にされず、起動後は「空の」インスタンスになります。
この時点で、スレーブとマスターの一貫性を保つために、インスタンス内のすべてのデータが自動的に「クリア」され、スレーブも「空の」インスタンスになります
######あなたはそれを見ましたか?このシナリオでは、すべてのマスター/スレーブ データが失われます。
現時点で、ビジネス アプリケーションが Redis にアクセスし、キャッシュにデータがないことが判明すると、すべてのリクエストがバックエンド データベースに送信されます。これにより、さらに「キャッシュなだれ」が引き起こされ、ビジネスに大きな影響を与えます。
したがって、このような状況が起こらないようにする必要があります。私からのアドバイスは次のとおりです:
- Redis インスタンスはプロセス管理ツールを使用せずに自動的にプルアップされます
- マスターがダウンしたら、センチネルに切り替えを開始させ、スレーブをマスターに昇格させます
- 切り替えが完了したら、マスターを再起動してスレーブをマスターに昇格させますスレーブに劣化
- データの永続性を構成する場合は、この問題を回避する必要があります。
Redis が AOF を有効にする場合は、AOF フラッシュ戦略を構成する必要があります。
パフォーマンスとデータ セキュリティのバランスに基づいて、appendfsync Everysec ソリューションを使用することになります。
このソリューションの動作モードは、Redis のバックグラウンド スレッドが AOF ページ キャッシュのデータを 1 秒ごとにディスク (fsync) にフラッシュすることです。
このソリューションの利点は、AOF ディスク ブラッシングの時間のかかる操作がバックグラウンド スレッドで実行され、メイン スレッドへの影響が回避されることです。
しかし、本当にメインスレッドには影響しないのでしょうか?
答えは否定的です。
実際には、次のようなシナリオがあります。
Redis バックグラウンド スレッドが AOF ページ キャッシュ フラッシュ (fysnc) を実行するとき、この時点でディスク IO 負荷が高すぎる場合、fsync への呼び出しが行われます。ブロックされました。現時点では、メイン スレッドはまだ書き込みリクエストを受信しているため、この時点のメイン スレッドは、最初に最後のバックグラウンド スレッドがディスクを正常にフラッシュしたかどうかを判断します。
どうやって判断するの?
バックグラウンド スレッドは、ディスク ブラッシングが成功した後、ディスク ブラッシングの時間を記録します。
メインスレッドはこの時間を使用して、最後のディスクブラシからの経過時間を判断します。全体のプロセスは次のようになります。
- メインスレッドが AOF ページ キャッシュを書き込む (書き込みシステム コール) 前に、まずバックグラウンドの fsync が完了したかどうかを確認します。
- fsync が完了し、メイン スレッドが AOF ページ キャッシュに直接書き込みます
- fsync が完了していない場合、その後の経過時間を確認します。最後のfsync?
- 最後の fysnc が成功してから 2 秒以内の場合、メインスレッドは AOF ページ キャッシュに書き込まずに直接戻ります
- 2 秒以内の場合 fysnc が 2 秒以上成功した場合、メインスレッドは AOF ページ キャッシュの書き込みを強制します (書き込みシステム コール)
- ディスク IO 負荷が高いため、このとき、バックグラウンド スレッド fynsc がブロックし、メイン スレッドもブロックして、AOF ページ キャッシュの書き込みを待機します (同じ fd の操作、fsync と書き込みは相互に排他的です。一方が他方の成功を待つ必要があります)。実行を続行できますが、それ以外の場合はブロックされて待機します)
分析の結果、構成した AOF フラッシュ戦略が 1 秒ごとに appendfsync である場合でも、メイン スレッドをブロックするリスクが依然として存在することがわかりました。
実際、この問題の重要な点は、ディスク IO 負荷が高すぎるために fynsc がブロックされ、その結果、AOF ページ キャッシュへの書き込み時にメイン スレッドがブロックされることです。
したがって、この問題を回避するには、ディスクに十分な IO リソースがあることを確認する必要があります。
3) AOF Everysec では本当に 1 秒間のデータしか失われませんか?
上記の質問を分析し続けます。
上で述べたように、ここでは上記のステップ 4 に焦点を当てる必要があります。
つまり: メイン スレッドが AOF ページ キャッシュに書き込むとき、最初に最後の fysnc が成功した時間を決定します。最後の fysnc 成功から 2 秒以内であれば、メイン スレッドは直接戻ります。 AOF ページ キャッシュに書き込まなくなります。
これは、バックグラウンド スレッドが fsync フラッシュを実行するとき、メイン スレッドは最大 2 秒間待機し、AOF ページ キャッシュに書き込まないことを意味します。
この時点で Redis がクラッシュすると、AOF ファイル内のデータは 1 秒ではなく 2 秒失われます。
分析を続けていますが、Redis メインスレッドが AOF ページ キャッシュに書き込まずに 2 秒待機するのはなぜですか?
実際、Redis AOF が appendfsync eachsec に設定されている場合、通常、バックグラウンド スレッドは 1 秒ごとに fsync ディスク フラッシュを実行しますが、ディスク リソースが十分であればブロックされることはありません。
言い換えれば、AOF ページ キャッシュが何も考えずに書き込まれている限り、Redis メイン スレッドはバックグラウンド スレッドがディスクを正常にフラッシュしたかどうかをまったく気にする必要はありません。
ただし、Redis 作成者は、現時点でディスク IO リソースが比較的逼迫している場合、バックグラウンド スレッド fsync がブロックされる可能性があると考えています。
したがって、Redis 作成者はメイン スレッドで AOF ページ キャッシュを書き込む前に、最後に成功した fsync からの時間を最初にチェックします。それが 1 秒を超えて失敗した場合、メイン スレッドはこの時点で認識します。 fsync がブロックされる可能性がある時間。
したがって、メイン スレッドは AOF ページ キャッシュを書き込まずに 2 秒待機します。目的は:
メイン スレッドがブロックされるリスクを軽減することです (何も考えずに AOF ページ キャッシュを書き込むと、メイン スレッドがすぐにブロックされます)
- #fsync がブロックされた場合、メイン スレッドはバックグラウンド スレッドが fsync が成功するまで待機するために 1 秒の時間を残します
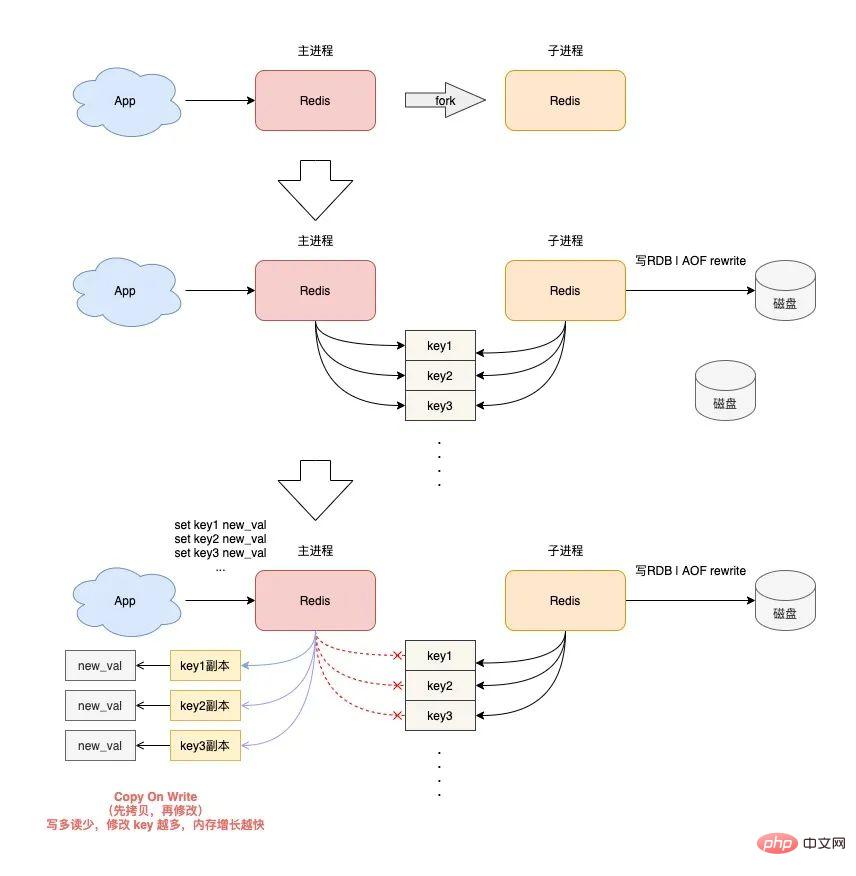
4) RDB と AOF を書き換えると Redis で OOM が発生しますか?
最後に、Redis が RDB スナップショットと AOF 書き換えを実行するときに発生する問題を見てみましょう。 Redis が RDB スナップショットと AOF 書き換えを実行すると、インスタンス内のデータをディスクに永続化するための子プロセスが作成されます。 子プロセスを作成すると、オペレーティング システムの fork 関数が呼び出されます。 フォークの実行が完了すると、親プロセスと子プロセスは同時に同じメモリ データを共有します。 ただし、この時点でもメインプロセスは書き込みリクエストを受け取ることができ、受信した書き込みリクエストは Copy On Write (コピーオンライト) メソッドを使用してメモリデータを操作します。 言い換えると、メイン プロセスに変更が必要なデータがあると、Redis は既存のメモリ内のデータを直接変更するのではなく、まずメモリ データをコピーしてから、メモリ内のデータを変更します。新しいメモリ。これは「コピーオンライト」と呼ばれます。 コピー オン ライトは、書き込む必要がある人が最初にコピーしてから変更するという意味でも理解できます。 親プロセスがキーを変更したい場合は、元のメモリ データを新しいメモリにコピーする必要があることがわかったはずです。このプロセスには、「新しいメモリ」のアプリケーションが含まれます。 ビジネス特性が「書き込みが多く読み取りが少ない」場合で、OPS が非常に高い場合、RDB および AOF の書き換え中に大量のメモリ コピー作業が生成されます。 これの何が問題なのでしょうか?書き込みリクエストが多いため、Redis 親プロセスが大量のメモリを適用することになります。この期間中、キー変更の範囲が広くなるほど、より多くの新しいメモリ アプリケーションが必要になります。
マシンのメモリ リソースが不十分な場合、Redis が OOM の危険にさらされることになります。这就是你会从 DBA 同学那里听到的,要给 Redis 机器预留内存的原因。
其目的就是避免在 RDB 和 AOF rewrite 期间,防止 Redis OOM。
以上这些,就是「数据持久化」会遇到的坑,你踩到过几个?
下面我们再来看「主从复制」会存在哪些问题。
主从复制有哪些坑?
Redis 为了保证高可用,提供了主从复制的方式,这样就可以保证 Redis 有多个「副本」,当主库宕机后,我们依旧有从库可以使用。
在主从同步期间,依旧存在很多坑,我们依次来看。
1) 主从复制会丢数据吗?
首先,你需要知道,Redis 的主从复制是采用「异步」的方式进行的。
这就意味着,如果 master 突然宕机,可能存在有部分数据还未同步到 slave 的情况发生。
这会导致什么问题呢?
如果你把 Redis 当做纯缓存来使用,那对业务来说没有什么影响。
master 未同步到 slave 的数据,业务应用可以从后端数据库中重新查询到。
但是,对于把 Redis 当做数据库,或是当做分布式锁来使用的业务,有可能因为异步复制的问题,导致数据丢失 / 锁丢失。
关于 Redis 分布式锁可靠性的更多细节,这里先不展开,后面会单独写一篇文章详细剖析这个知识点。这里你只需要先知道,Redis 主从复制是有概率发生数据丢失的。
2) 同样命令查询一个 key,主从库却返回不同的结果?
不知道你是否思考过这样一个问题:如果一个 key 已过期,但这个 key 还未被 master 清理,此时在 slave 上查询这个 key,会返回什么结果呢?
slave 正常返回 key 的值
slave 返回 NULL
你认为是哪一种?可以思考一下。
答案是:不一定。
嗯?为什么会不一定?
这个问题非常有意思,请跟紧我的思路,我会带你一步步分析其中的原因。
其实,返回什么结果,这要取决于以下 3 个因素:
Redis 的版本
具体执行的命令
机器时钟
先来看 Redis 版本。
如果你使用的是 Redis 3.2 以下版本,只要这个 key 还未被 master 清理,那么,在 slave 上查询这个 key,它会永远返回 value 给你。
也就是说,即使这个 key 已过期,在 slave 上依旧可以查询到这个 key。
// Redis 2.8 版本 在 slave 上执行 127.0.0.1:6479> TTL testkey (integer) -2 // 已过期 127.0.0.1:6479> GET testkey "testval" // 还能查询到!
但如果此时在 master 上查询这个 key,发现已经过期,就会把它清理掉,然后返回 NULL。
// Redis 2.8 版本 在 master 上执行 127.0.0.1:6379> TTL testkey (integer) -2 127.0.0.1:6379> GET testkey (nil)
发现了吗?在 master 和 slave 上查询同一个 key,结果竟然不一样?
其实,slave 应该要与 master 保持一致,key 已过期,就应该给客户端返回 NULL,而不是还正常返回 key 的值。
为什么会发生这种情况?
其实这是 Redis 的一个 Bug:3.2 以下版本的 Redis,在 slave 上查询一个 key 时,并不会判断这个 key 是否已过期,而是直接无脑返回给客户端结果。
这个 Bug 在 3.2 版本进行了修复,但是,它修复得「不够彻底」。
什么叫修复得「不够彻底」?
这就要结合前面提到的,第 2 个影响因素「具体执行的命令」来解释了。
Redis 3.2 虽然修复了这个 Bug,但却遗漏了一个命令:EXISTS。
也就是说,一个 key 已过期,在 slave 直接查询它的数据,例如执行 GET/LRANGE/HGETALL/SMEMBERS/ZRANGE 这类命令时,slave 会返回 NULL。
但如果执行的是 EXISTS,slave 依旧会返回:key 还存在。
// Redis 3.2 版本 在 slave 上执行 127.0.0.1:6479> GET testkey (nil) // key 已逻辑过期 127.0.0.1:6479> EXISTS testkey (integer) 1 // 还存在!
原因在于,EXISTS 与查询数据的命令,使用的不是同一个方法。
Redis 作者只在查询数据时增加了过期时间的校验,但 EXISTS 命令依旧没有这么做。
直到 Redis 4.0.11 这个版本,Redis 才真正把这个遗漏的 Bug 完全修复。
如果你使用的是这个之上的版本,那在 slave 上执行数据查询或 EXISTS,对于已过期的 key,就都会返回「不存在」了。
这里我们先小结一下,slave 查询过期 key,经历了 3 个阶段:
3.2 以下版本,key 过期未被清理,无论哪个命令,查询 slave,均正常返回 value
3.2 - 4.0.11 版本,查询数据返回 NULL,但 EXISTS 依旧返回 true
4.0.11 以上版本,所有命令均已修复,过期 key 在 slave 上查询,均返回「不存在」
这里要特别鸣谢《Redis开发与运维》的作者,付磊。
这个问题我是在他的文章中看到的,感觉非常有趣,原来 Redis 之前还存在这样的 Bug 。随后我又查阅了相关源码,并对逻辑进行了梳理,在这里才写成文章分享给大家。
虽然已在微信中亲自答谢,但在这里再次表达对他的谢意~
最后,我们来看影响查询结果的第 3 个因素:「机器时钟」。
假设我们已规避了上面提到的版本 Bug,例如,我们使用 Redis 5.0 版本,在 slave 查询一个 key,还会和 master 结果不同吗?
答案是,还是有可能会的。
这就与 master / slave 的机器时钟有关了。
无论是 master 还是 slave,在判断一个 key 是否过期时,都是基于「本机时钟」来判断的。
如果 slave 的机器时钟比 master 走得「快」,那就会导致,即使这个 key 还未过期,但以 slave 上视角来看,这个 key 其实已经过期了,那客户端在 slave 上查询时,就会返回 NULL。
是不是很有意思?一个小小的过期 key,竟然藏匿这么多猫腻。
如果你也遇到了类似的情况,就可以通过上述步骤进行排查,确认是否踩到了这个坑。
3) 主从切换会导致缓存雪崩?
这个问题是上一个问题的延伸。
我们假设,slave 的机器时钟比 master 走得「快」,而且是「快很多」。
此时,从 slave 角度来看,Redis 中的数据存在「大量过期」。
如果此时操作「主从切换」,把 slave 提升为新的 master。
它成为 master 后,就会开始大量清理过期 key,此时就会导致以下结果:
master 大量清理过期 key,主线程发生阻塞,无法及时处理客户端请求
Redis 中数据大量过期,引发缓存雪崩
你看,当 master / slave 机器时钟严重不一致时,对业务的影响非常大!
所以,如果你是 DBA 运维,一定要保证主从库的机器时钟一致性,避免发生这些问题。
4) master / slave 大量数据不一致?
还有一种场景,会导致 master / slave 的数据存在大量不一致。
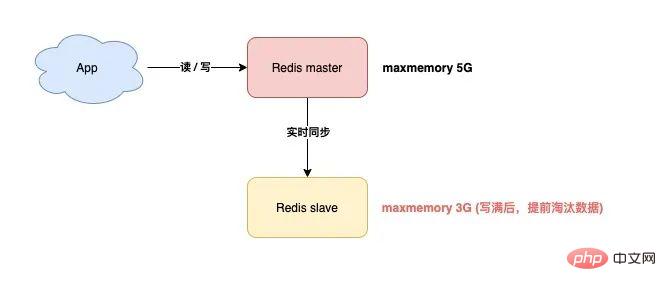
这就涉及到 Redis 的 maxmemory 配置了。
Redis 的 maxmemory 可以控制整个实例的内存使用上限,超过这个上限,并且配置了淘汰策略,那么实例就开始淘汰数据。
但这里有个问题:假设 master / slave 配置的 maxmemory 不一样,那此时就会发生数据不一致。
例如,master 配置的 maxmemory 为 5G,而 slave 的 maxmemory 为 3G,当 Redis 中的数据超过 3G 时,slave 就会「提前」开始淘汰数据,此时主从库数据发生不一致。
さらに、マスター/スレーブの maxmemory 設定は同じですが、その上限を調整する場合は特に注意する必要があります。そうしないと、スレーブによってもデータが削除されます。
maxmemory を増やします。スレーブを調整するときは、最初にスレーブを調整してからマスターを調整します。
maxmemory をより小さい値に調整する場合は、最初にマスターを調整します。
slave が maxmemory を超えると、データ が「自動的に」削除されるためです。
スレーブがそれ自体でデータを削除することが許可されていない場合、これらすべての問題を回避できるでしょうか? ######それは正しい。 この問題に関しては、Redis関係者も多くのユーザーからフィードバックを受けているはずです。 Redis 5.0 バージョンでは、公式がついにこの問題を完全に解決しました。 Redis 5.0 では、replica-ignore-maxmemory という構成項目が追加されています。デフォルトは [yes] です。 このパラメータは、スレーブ メモリが maxmemory を超えた場合でも、データを自動的に削除しないことを示します。このように、スレーブは常にマスターと同等であり、マスターから送信されたデータを忠実にコピーするだけであり、それ自体で「ちょっとしたトリック」を行うことはありません。
この時点で、マスター/スレーブのデータは完全に一貫していることが保証されます。
バージョン 5.0 を使用している場合は、この問題を心配する必要はありません。
5) スレーブには実際にメモリ リークの問題があるのでしょうか?
はい、あなたは間違っていません。 ######どうしてそうなった?詳しく見てみましょう。
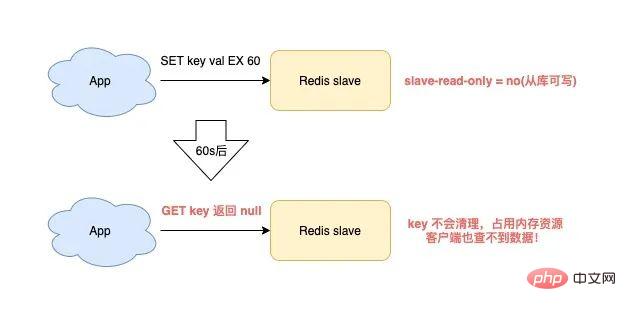
Redis を使用している場合、次のシナリオに該当するとスレーブ メモリ リークがトリガーされます: Redis が 4.0 より前のバージョンを使用している- スレーブ設定項目は読み取り専用 = いいえ (ライブラリから書き込み可能) ##有効期限付きのキーがスレーブに書き込まれます
- この時点で、スレーブではメモリ リークが発生します。
- スレーブ内のキーは、有効期限が切れても自動的にクリアされません。 積極的に削除しないと、これらのキーはスレーブ メモリに残り、スレーブ メモリを消費します。
最も問題なのは、コマンドを使用してこれらのキーをクエリしても、結果が見つからないことです。 これはスレーブの「メモリ リーク」問題です。
これは実際には Redis のバグであり、この問題は Redis 4.0 でのみ修正されました。 解決策は、書き込み可能なスレーブでは、有効期限付きのキーを書き込むときに、スレーブはこれらのキーを「記録」します。
その後、スレーブはこれらのキーを定期的にスキャンし、有効期限に達すると消去します。
ビジネスでデータをスレーブに一時的に保存する必要があり、これらのキーに有効期限が設定されている場合は、この問題に注意する必要があります。 Redis のバージョンを確認する必要があります。バージョンが 4.0 より前の場合は、この落とし穴を必ず回避してください。
実際、最善の解決策は、Redis の使用仕様を策定することです。スレーブは強制的に読み取り専用にし、書き込みは許可されないようにする必要があります。これにより、マスター/スレーブのデータの一貫性が保証されるだけでなく、ただし、スレーブメモリのリーク問題も避けてください。
6) マスターとスレーブの完全同期が失敗し続けるのはなぜですか?マスターとスレーブが完全に同期されている場合、同期失敗の問題が発生する可能性があります。具体的なシナリオは次のとおりです:
スレーブがマスターに対して完全な同期リクエストを開始します。 、マスターは RDB を生成してスレーブに送信し、スレーブは RDB をロードします。 RDB データが大きすぎるため、スレーブのロード時間も非常に長くなります。
この時点で、スレーブは RDB のロードを完了していませんが、マスターとスレーブ間の接続が切断され、データの同期が失敗していることがわかります。
その後、スレーブが再度完全同期を開始し、マスターが RDB を生成してスレーブに送信していることがわかります。
同様に、スレーブが RDB をロードすると、マスター/スレーブの同期が再び失敗し、以下同様になります。
これはどうなりましたか?
実は、これは Redis の「レプリケーション ストーム」問題です。
レプリケーション ストームとは何ですか?
先ほど説明した内容と同じです: マスターとスレーブの完全同期が失敗し、同期が再開され、その後再び同期が失敗するという悪循環が繰り返され、マシン リソースが浪費され続けます。
これによってこの問題が発生するのはなぜですか?
Redis に次の特性がある場合、この問題が発生する可能性があります:
マスターのインスタンス データが大きすぎるため、スレーブがインスタンス データをロードするのに時間がかかりすぎます。 RDB.
コピー バッファー (スレーブ クライアント出力バッファー制限) 構成が小さすぎます
マスターには多数の書き込みリクエスト
マスターとスレーブがデータを完全に同期している場合、マスターが受信した書き込みリクエストは、まずマスターとスレーブの「コピー バッファ」に書き込まれます。このバッファの量は構成によって決まります。
スレーブによる RDB のロードが遅すぎると、スレーブは「レプリケーション バッファ」内のデータを時間内に読み取ることができなくなり、レプリケーション バッファが「オーバーフロー」します。
メモリの継続的な増加を避けるために、マスターはこの時点でスレーブを「強制的に」切断し、完全な同期は失敗します。
その後、同期に失敗したスレーブが完全同期を「再」開始し、上記の問題に陥るという悪循環を繰り返す、いわゆる「レプリケーションストーム」です。 。
この問題を解決するにはどうすればよいですか?次の提案をします:
Redis インスタンスは大きすぎず、大きすぎる RDB は避けてください。
コピー バッファー構成をできるだけ大きくしてください。可能な限り、スレーブが RDB をロードするのに十分な時間を残し、完全な同期が失敗する可能性を減らしてください。
あなたもこの落とし穴を踏んだことがある場合は、これで解決できます。解決。
まとめ
要約すると、この記事では主に「コマンドの使用法」、「データの永続性」、「マスターとスレーブの同期」という点で Redis について説明します。考えられる落とし穴は 3 つあります。
どうですか?それはあなたの理解を覆しましたか?
この記事の情報量は非常に多いです。現在の考え方が少し「混乱している」場合でも、心配しないでください。理解と記憶を促進するためのマインド マップも用意しました。 。
Redis を使用する際には、これらの落とし穴を事前に回避し、Redis により良いサービスを提供できることを願っています。
追記
最後に、開発プロセス中に落とし穴に入ってしまった私の経験と考えについてお話したいと思います。
実際、新しい分野に触れるときは、不慣れ、慣れ、落とし穴を踏む、経験を吸収する、快適になるなど、いくつかの段階を経ます。
それでは、落とし穴を踏むこの段階で、落とし穴を踏まないようにするにはどうすればよいでしょうか?あるいは、罠に陥った後に問題を効率的にトラブルシューティングするにはどうすればよいでしょうか?
ここでは、役立つ 4 つの側面をまとめました:
1) 公式ドキュメントの設定ファイルに関するコメントをさらに読んでください
ぜひ、公式ドキュメントや設定ファイルに関するコメントをもっと読んでください。実際、優れたソフトウェアは文書やコメントに含まれる可能性のある多くのリスクを警告しており、それらを注意深く読めば、多くの基本的な問題を事前に回避できます。
2) 質問の詳細をそのままにせず、その理由をもっと考えてください。
常に好奇心を持ち続けてください。問題に遭遇したとき、繭を剥がして徐々に問題を見つけ出す能力を身につけ、問題の本質を探る精神を常に持ち続けてください。
3) あえて疑問を提起してください。ソース コードは嘘をつきません。
問題が奇妙であると思われる場合、それはバグである可能性があります。あえて疑問を提起してください。
ソース コードを通じて問題の真実を見つけることは、インターネット上でお互いから盗用された 100 個の記事を読むよりも優れています (記事を何度もコピーすると、間違いを犯す可能性が非常に高くなります)。
4) 完璧なソフトウェアはありません。優れたソフトウェアは段階的に反復されます。
優れたソフトウェアはすべて、段階的に反復されます。反復プロセス中にバグが存在するのは正常なことであり、正しい考え方でバグに対処する必要があります。
これらの経験と洞察はあらゆる研究分野に適用できるので、皆さんのお役に立てれば幸いです。
プログラミング関連の知識について詳しくは、プログラミング教育をご覧ください。 !
以上がRedis を使用するときに遭遇する可能性のある 15 の落とし穴。雷を避けるために、ぜひそれらを集めてください。 !の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。