
Redis の面接で見逃せない 40 の質問 (回答とマインド マップを含む)

- 青灯夜游転載
- 2021-04-02 10:34:258602ブラウズ
この記事では、回答分析や Redis ナレッジ ポイント マインド マップなど、Redis 面接の質問 40 件を紹介します。一定の参考値があるので、困っている友達が参考になれば幸いです。

Redis の面接の質問
#1. Redis とは何ですか?
Redis完全にオープンソースで無料、BSD プロトコルに準拠した、高性能のキー/値データベースです。
Redis およびその他のキー値キャッシュ製品には、次の 3 つの特徴があります。
(1) Redis はデータの永続化をサポートし、再起動時にメモリ内のデータをディスクに保存できます。 再ロードできます。使用するために。
(2) Redis は、単純なキーと値の型のデータをサポートするだけでなく、リスト、セット、zset、ハッシュなどのデータ構造のストレージも提供します。
(3) Redis はデータ バックアップ、つまりマスター/スレーブ モードでのデータ バックアップをサポートしています。
[関連する推奨事項: Redis ビデオ チュートリアル ]
Redis の利点
(1) 非常に高いパフォーマンス – Redis は 110,000 回/秒の読み取りが可能です。書き込み速度は81000回/秒。
(2) 豊富なデータ型 – Redis は、バイナリの場合の文字列、リスト、ハッシュ、セット、および順序付きセットのデータ型操作をサポートします。
(3) アトミック - Redis のすべての操作はアトミックです。つまり、操作は正常に実行されるか、失敗した場合はまったく実行されません。個々の操作はアトミックです。複数の操作は、MULTI 命令と EXEC 命令によってラップされたトランザクション、つまりアトミック性もサポートします。
(4) 豊富な機能 – Redis は、パブリッシュ/サブスクライブ、通知、キーの有効期限などの機能もサポートしています。
Redis は他の Key-Value ストアとどう違うのですか?
(1) Redis はより複雑なデータ構造を持ち、それらに対するアトミックな操作を提供します。これは他のデータベースとは異なる進化の過程です。 Redis のデータ型は基本的なデータ構造に基づいており、追加の抽象化を必要とせずにプログラマにとって透過的です。
(2) Redis はメモリ内で実行されますが、ディスクに永続化できるため、データ量がハードウェアを超えることはできないため、さまざまなデータセットの高速読み取りおよび書き込みを実行するときはメモリを考慮する必要があります。メモリ。インメモリ データベースのもう 1 つの利点は、ディスク上の同じ複雑なデータ構造と比較して、メモリ内での操作が非常にシンプルであるため、Redis は内部の複雑性が高くても多くのことを実行できることです。また、ディスク形式に関しては、ランダム アクセスを必要としないため、コンパクトな追加生成となります。
2. Redis データ型?
回答: Redis は、文字列 (文字列)、ハッシュ (ハッシュ)、リスト (リスト)、セット (セット)、および zsetsorted セット: 順序付きセット) の 5 つのデータ型をサポートします。
実際のプロジェクトで最も一般的に使用されるものは文字列とハッシュです。上級 Redis ユーザーの場合は、HyperLogLog、Geo、Pub/Sub のデータ構造も追加する必要があります。
BloomFilter、RedisSearch、Redis-ML などの Redis モジュールを触ったことがあると言うと、面接官の目が輝き始めます。
3. Redis を使用する利点は何ですか?
# (1) HashMap と同様にメモリ上にデータを格納するため高速です。HashMap の利点は、検索と操作の計算量が両方とも O1)# # (2) 豊富なデータ型のサポート、文字列、リスト、セット、Zset、ハッシュなどのサポート (3) トランザクションのサポート、操作はアトミックです。いわゆるアトミック性とは、データに対するすべての変更が行われることを意味します。 (4) 豊富な機能: キャッシュやメッセージに使用でき、キーごとに有効期限を設定でき、有効期限が切れると自動的に削除されます4. Memcached と比較した Redis の利点は何ですか?
(1) Memcached の値はすべて単純な文字列であり、redis はその代替として、より豊富なデータ型をサポートします (2) Redis は Memcached よりも高速です 非常に迅速です(3) Redis はデータを永続化できます##5. Memcache と Redis の違いは何ですか?(1) 保存方法 Memecache はすべてのデータをメモリ上に保存しますが、停電後はハングアップしますので、メモリサイズを超えるデータは保存できません。 Redis は部分的にハードディスクに保存されるため、データの永続性が保証されます。
(2) データ サポートの種類 Memcache は、比較的単純なデータ型をサポートしています。 Redis には複雑なデータ型があります。
(3) 使用される基礎モデルが異なります。基礎となる実装メソッドとクライアントとの通信用のアプリケーション プロトコルが異なります。一般的なシステムがシステム関数を呼び出すと、移動とリクエストに一定の時間が無駄になるため、Redis は独自の VM メカニズムを直接構築します。
6. Redis はシングルプロセスおよびシングルスレッドですか?回答: Redis は単一プロセスおよび単一スレッドです。Redis はキュー テクノロジを使用して同時アクセスをシリアル アクセスに変換し、従来のデータベース シリアル制御のオーバーヘッドを排除します。
7. 文字列型の値が格納できる最大容量はどれくらいですか?答え: 512M
8. Redis の永続化メカニズムとは何ですか?それぞれの長所と短所は何ですか?
Redis は、RDB メカニズムと AOF メカニズムという 2 つの永続化メカニズムを提供します:
1. RDBRedis DataBase) 永続化メソッド:
は、データ セット スナップショットを使用するメソッドを指します。 -persistent モード) は、redis データベースのすべてのキーと値のペアを記録し、特定の時点でデータを一時ファイルに書き込みます。永続化が完了した後、この一時ファイルは、データ回復を実現するために最後に永続化されたファイルを置き換えるために使用されます。
利点:
(1) ファイル dump.rdb が 1 つだけあるため、永続化に便利です。
(2) 耐災害性が高く、ファイルを安全なディスクに保存できます。
(3) パフォーマンスを最大化するには、子プロセスをフォークして書き込み操作を完了し、メインプロセスがコマンドの処理を継続できるようにして、IO を最大化します。永続化のために別のサブプロセスを使用し、メインプロセスは IO 操作を実行しないため、redis の高いパフォーマンスが保証されます)
(4) データセットが大きい場合、起動効率は AOF よりも高くなります。
欠点:
データのセキュリティが低い。 RDB は一定の間隔で永続化されますが、永続化の間に redis に障害が発生するとデータ損失が発生します。
2. AOFAppend 専用ファイル) 永続化メソッド:
は、すべてのコマンド ライン レコードが完全に次の形式であることを意味します。 redis コマンド要求プロトコル。永続ストレージ)は、aof ファイルとして保存されます。
利点:
(1) データ セキュリティ、aof 永続性は、appendfsync 属性を使用して構成でき、常に各コマンド操作が aof ファイルに記録されます。
(2) 追加モードでファイルを書き込む サーバーが途中でダウンした場合でも、redis-check-aof ツールを使用してデータの整合性の問題を解決できます。
(3) AOF メカニズムの書き換えモード。 AOF ファイルが書き換えられる前に (ファイルが大きすぎる場合、コマンドはマージされて書き換えられます)、一部のコマンド (誤ってフラッシュオールなど) を削除する可能性があります)
欠点:
( 1) AOF ファイルは RDB ファイルに比べてサイズが大きく、回復速度が遅くなります。
(2) データセットが大きい場合、rdbよりも起動効率が悪くなります。
9. Redis の一般的なパフォーマンスの問題と解決策:
(1) マスターはメモリ スナップショットを書き込まないことが最善です。マスターがメモリ スナップショットを書き込む場合、save コマンドはrdbSave 関数は、メインスレッドの作業をブロックします。スナップショットが比較的大きい場合、パフォーマンスへの影響が非常に大きく、サービスが断続的に停止されます。
(2) データが重要な場合、スレーブは AOF バックアップ データ、ポリシー設定を有効にします。 1 秒あたり 1 つの
を同期します (3) マスターとスレーブのレプリケーションの速度と接続の安定性を考慮すると、マスターとスレーブをオンにするのが最適です。同じ LAN
(4) 大きな負荷がかからないようにする スレーブ
をマスター ライブラリに追加する (5) マスター/スレーブ レプリケーションにはグラフ構造を使用しないでください。一方向のリンク リスト構造を使用します。つまり、マスター <- スレーブ 1<- スレーブ 2 <- スレーブ 3... のようになります。この構造により、単一障害点の問題が解決され、マスターのスレーブによる置き換えが容易になります。 。マスターがハングアップした場合は、他のすべてを変更せずに、すぐに Slave1 をマスターとして有効にすることができます。
10. Redis の期限切れキーの削除戦略は何ですか?
(1) スケジュール削除: キーの有効期限を設定しながら、タイマー(タイマー)を作成し、キーの有効期限が来たら即座にキーの削除を実行させます。
(2) 遅延削除: キーの有効期限が切れたままにしますが、キー空間からキーを取得するたびに、取得したキーの有効期限が切れているかどうかを確認し、期限切れの場合はキーを削除し、期限切れになっていない場合はキーを削除します。期限切れです。削除してください。このキーを返してください。
(3) 定期的な削除: プログラムは時々データベースをチェックし、期限切れのキーを削除します。削除する期限切れのキーの数とチェックするデータベースの数はアルゴリズムによって決まります。
11. Redis リサイクル戦略 (排除戦略)?
volatile-lru: 有効期限が設定されたデータセットから (server.db[i].expires )削除対象として最も最近使用されていないデータを選択するには
#volatile-ttl: 削除対象に有効期限が設定されたデータ セット (server.db[i].expires) から期限切れになるデータを選択します volatile-random: 有効期限が設定されたデータ セット (server.db[i].expires) から削除するデータをランダムに選択します allkeys-lru: データ セット (server.db[i) から].dict) 削除対象として最も最近使用されていないデータを選択しますallkeys-random: 削除対象としてデータ セット (server.db[i].dict) から任意のデータを選択しますno-enviction (eviction): Forbidden Evicting dataここでは 6 つのメカニズムに注意してください。Volatile キーと allkeys は、有効期限を指定してデータ セットからデータを削除するか、すべてのデータ セットからデータを削除するかを指定します。次の lru、ttl、randomこれは、3 つの異なる排除戦略に加えて、決してリサイクルしないという非羨望の戦略です。 使用ポリシー ルール: (1) データがべき乗則分布を示している場合、つまり、アクセス頻度が高いデータとアクセス頻度が低いデータがある場合は、allkeys-lru# を使用します。# #(2) データが均等に分散されている場合、つまりすべてのデータ アクセス頻度が同じ場合は、allkeys-random
を使用します。12. edis はなぜすべてのデータをメモリに置く必要があるのですか?
回答: 最速の読み取りおよび書き込み速度を実現するために、Redis はすべてのデータをメモリに読み取り、そのデータを非同期でディスクに書き込みます。つまり、redis は高速でデータの永続性が高いという特徴を持っています。データがメモリに配置されていない場合、ディスク I/O 速度は Redis のパフォーマンスに重大な影響を与えます。メモリがどんどん安くなっている現在、redis の人気はますます高まるでしょう。使用される最大メモリが設定されている場合、既存のデータ レコードの数がメモリ制限に達すると、新しい値を挿入できなくなります。
13. Redis の同期メカニズムを理解していますか?
回答: Redis はマスター/スレーブ同期とスレーブ/スレーブ同期を使用できます。最初の同期中に、プライマリ ノードは bgsave を実行し、後続の変更操作をメモリ バッファに記録します。完了後、rdb ファイル全体がレプリカ ノードに同期されます。レプリカ ノードがデータを受け入れた後、rdb イメージがロードされます。記憶の中に。ロードが完了すると、その期間中に変更された操作記録を再生のためにレプリカ ノードに同期するようにマスター ノードに通知され、同期プロセスが完了します。
14. パイプラインの利点は何ですか? パイプラインを使用する理由は何ですか?
回答: パイプラインによって実行される命令間に因果関係がない場合、複数の IO ラウンドトリップの時間を 1 回に短縮できます。ストレス テストに redis-benchmark を使用すると、redis の QPS ピーク値に影響を与える重要な要素がパイプライン バッチ命令の数であることがわかります。
15. Redis クラスターを使用したことがありますか? クラスター化の原理は何ですか?
(1) Redis Sentinal は高可用性を重視しており、マスターがダウンすると、自動的にスレーブをマスターに昇格させてサービスを提供し続けます。
(2) Redis Cluster は拡張性を重視しており、単一の Redis メモリが不足する場合、Cluster はシャード ストレージとして使用されます。
16. Redis クラスター ソリューションによってクラスター全体が使用できなくなるのは、どのような状況ですか?
回答: 3 つのノード A、B、C があり、レプリケーション モデルがないクラスターでは、ノード B に障害が発生すると、クラスター全体が 5501 ~ 11000 の範囲が欠落していると判断します。利用できません。
17. Redis でサポートされる Java クライアントは何ですか?公式で推奨されているのはどれですか?
回答: Redisson、Jedis、レタスなど。公式では Redisson を使用することが推奨されています。
18. ジェディスとレディソンの長所と短所は何ですか?
回答: Jedis は Redis の Java 実装のクライアントであり、その API は Redis コマンドに対して比較的包括的なサポートを提供します。Redisson は分散型でスケーラブルな Java データ構造を実装します。Jedis と比較すると、その機能は相対的に優れています。シンプルで、文字列操作をサポートせず、並べ替え、トランザクション、パイプライン、パーティションなどの Redis 機能をサポートしません。
Redisson の目的は、ユーザーの懸念事項を Redis から分離して、ユーザーがビジネス ロジックの処理に集中できるようにすることです。
19. Redis でパスワードを設定し、パスワードを確認するにはどうすればよいですか?
パスワードの設定: config set requirepass 123456
認可パスワード: auth 123456
20. Redis ハッシュ スロットの概念について話しますか?
回答: Redis クラスターは一貫したハッシュを使用しませんが、ハッシュ スロットの概念を導入しています。Redis クラスターには 16384 のハッシュ スロットがあります。各キーは CRC16 検証に合格した後、16384 を法としてチェックされます。スロットを配置する場合、クラスター内の各ノードはハッシュ スロットの一部を担当します。

#21. Redis クラスターのマスター/スレーブ レプリケーション モデルとは何ですか?
回答: 一部のノードに障害が発生した場合、またはほとんどのノードが通信できなくなった場合でもクラスターを引き続き使用できるようにするために、クラスターはマスター/スレーブ レプリケーション モデルを使用し、各ノードには N-1 個のレプリカが存在します。
22. Redis クラスターで書き込み操作は失われますか?なぜ?
回答: Redis はデータの強い一貫性を保証しません。つまり、実際には、特定の条件下ではクラスターが書き込み操作を失う可能性があります。
23. Redis クラスターはどのようにレプリケートされますか?
回答: 非同期レプリケーション
24. Redis クラスター内のノードの最大数はいくつですか?
答え: 16384。
25. Redis クラスターのデータベースを選択するにはどうすればよいですか?
回答: 現在、Redis クラスターはデータベースを選択できません。デフォルトはデータベース 0 です。
26. Redis の接続をテストするにはどうすればよいですか?
回答: ping コマンドを使用します。
27. Redis トランザクションを理解するにはどうすればよいですか?
回答:
(1) トランザクションは個別の分離操作です。トランザクション内のすべてのコマンドはシリアル化され、順番に実行されます。トランザクションの実行中、他のクライアントから送信されたコマンド要求によって中断されることはありません。
(2) トランザクションはアトミックな操作です。トランザクション内のすべてのコマンドが実行されるか、まったく実行されません。
28. Redis トランザクションに関連するコマンドは何ですか?
回答: MULTI、EXEC、DISCARD、WATCH
29. Redis キーの有効期限と永続的な有効性をそれぞれ設定するにはどうすればよいですか?
回答: EXPIRE および PERSIST コマンド。
30. Redis はどのようにメモリを最適化しますか?
回答: できるだけハッシュ テーブル (ハッシュ) を使用してください。ハッシュ テーブル (ハッシュ テーブルに格納される数値が小さいことを意味します) は非常に少ないメモリを使用するため、変換に最善を尽くす必要があります。データモデルをハッシュテーブルに抽象化します。たとえば、Web システムにユーザー オブジェクトがある場合、ユーザーの名前、姓、電子メール、パスワードに個別のキーを設定せず、すべてのユーザー情報をハッシュ テーブルに保存します。
31. Redis のリサイクル プロセスはどのように機能しますか?
回答: クライアントが新しいコマンドを実行し、新しいデータを追加しました。 Redi はメモリ使用量をチェックし、maxmemory 制限を超えている場合は、設定されたポリシーに従ってリサイクルされます。新しいコマンドが実行されるなど。したがって、私たちは常に境界に到達し、その後常に境界の下に戻ってリサイクルすることにより、常にメモリ制限の境界を超えています。コマンドの結果として大量のメモリが使用される場合 (大規模なセットの共通部分を新しいキーに保存する場合など)、このメモリ使用量がメモリ制限を超えるまでにそれほど時間はかかりません。
32. Redis のメモリ使用量を削減するにはどのような方法がありますか?
回答: 32 ビット Redis インスタンスを使用している場合は、通常、小さなキーが多数存在するため、ハッシュ、リスト、ソート セット、セットなどのコレクション型データを有効に活用できます。・お値打ちに使えて、よりコンパクトにまとめて収納できます。
33. Redis のメモリが不足するとどうなりますか?
回答: 設定された上限に達すると、Redis 書き込みコマンドはエラー メッセージを返します (ただし、読み取りコマンドは正常に返されます)。または、Redis をキャッシュとして使用して、構成削除メカニズム Redis の場合、メモリ制限に達すると、古いコンテンツがフラッシュされます。
34. Redis インスタンスには最大でいくつのキーを保存できますか?リスト、セット、ソートされたセットは最大でいくつの要素を保存できますか?
回答: 理論上、Redis は最大 232 個のキーを処理でき、実際のテストでは、各インスタンスには少なくとも 2 億 5,000 万個のキーが保存されました。いくつかのより大きな値をテストしています。リスト、セット、ソートされたセットは 232 個の要素を保持できます。言い換えれば、Redis のストレージ制限は、システムで利用可能なメモリの量です。
35. MySQL には 2,000 万のデータがありますが、redis には 2,000 万のデータのみが保存されます。redis 内のデータがホット データであることを確認するにはどうすればよいですか?
回答: Redis メモリ データ セットのサイズが特定のサイズに増加すると、データ削除戦略が実装されます。
関連知識: Redis は 6 つのデータ削除戦略を提供します:
volatile-lru: 有効期限が設定された最も最近使用されていないデータ セット (server.db[i].expires) を選択します。 データ削除
volatile-ttl: 有効期限が設定されているデータセット (server.db[i].expires) から有効期限が切れるデータを選択します。
volatile-random: データセットから有効期限が設定されているデータ セット (server.db[i].expires) から有効期限を削除するデータを選択します。
allkeys-lru: データ セット (server.db[i].expires) から最も最近使用されていないデータを選択します。 db[i].dict) データ削除
allkeys-random: データ セットからデータ削除をランダムに選択します (server.db[i].dict)
no-enviction (エビクション):データのエビクションを禁止する
36. Redis に最も適したシナリオは何ですか?
1. セッション キャッシュ
Redis を使用するために最も一般的に使用されるシナリオの 1 つはセッション キャッシュです。 Memcached などの他のストアに比べて Redis でセッションをキャッシュする利点は、Redis が永続性を提供することです。一貫性を厳密に必要としないキャッシュを維持する場合、ユーザーのショッピング カート情報がすべて失われると、ほとんどの人は不満を抱くでしょう。幸いなことに、Redis は長年にわたって改良されてきたため、Redis を適切に使用してセッション ドキュメントをキャッシュする方法を見つけるのは簡単です。有名な商用プラットフォーム Magento でも、Redis 用のプラグインが提供されています。
2. フル ページ キャッシュ (FPC)
基本的なセッション トークンに加えて、Redis は非常にシンプルな FPC プラットフォームも提供します。一貫性の問題に戻りますが、Redis インスタンスが再起動されても、ディスクの永続性によりユーザーはページの読み込み速度が低下することはありません。これは、PHP ローカル FPC と同様に、大きな改善です。再び Magento を例に挙げると、Magento は Redis をフルページ キャッシュ バックエンドとして使用するためのプラグインを提供します。さらに、WordPress ユーザー向けに、Pantheon には非常に優れたプラグイン wp-redis があり、閲覧したページをできるだけ早く読み込むのに役立ちます。
3. キュー
メモリ ストレージ エンジンの分野における Redis の大きな利点の 1 つは、リストおよびセット操作を提供し、これにより Redis を優れたメッセージ キュー プラットフォームとして使用できることです。 。 Redis によってキューとして使用される操作は、リストに対するローカル プログラミング言語 (Python など) のプッシュ/ポップ操作に似ています。 Google で「Redis キュー」をすぐに検索すると、すぐに多数のオープンソース プロジェクトが見つかります。これらのプロジェクトの目的は、Redis を使用して、さまざまなキューのニーズを満たす非常に優れたバックエンド ツールを作成することです。たとえば、Celery には Redis をブローカーとして使用するバックエンドがあり、ここから確認できます。
4、ランキング/カウンター
Redis は、メモリ内の数値を増減する操作を非常に適切に実装しています。 Sets と Sorted Sets を使用すると、これらの操作を非常に簡単に実行できます。Redis が提供するのは、これら 2 つのデータ構造だけです。したがって、ソートされたセットから上位 10 人のユーザーを取得するには、これらを「user_scores」と呼びます。次のように実行します。 もちろん、これはユーザーのスコアに基づいて実行していることを前提としています。ユーザーとユーザーのスコアを返したい場合は、次のように実行する必要があります: ZRANGE user_scores 0 10 WITHSCORES Agora Games は良い例で、Ruby で実装されており、そのランキングは Redis を使用してデータを保存しています。ここを参照してください。
5. パブリッシュ/サブスクライブ
最後 (そして必ず重要なのは) Redis のパブリッシュ/サブスクライブ機能です。パブリッシュ/サブスクライブには実際に多くの使用例があります。人々がこれをソーシャル ネットワーク接続で使用したり、パブリッシュ/サブスクライブ ベースのスクリプトのトリガーとして使用したり、Redis のパブリッシュ/サブスクライブ機能を使用してチャット システムを構築したりしているのを見てきました。

37. Redis に 1 億個のキーがある場合、そのうちの 100,000 個は固定の既知のプレフィックスで始まります。
回答: 指定されたモードのキー リストをスキャンするには、keys コマンドを使用します。
次に相手は、「この Redis がオンライン ビジネスにサービスを提供している場合、keys コマンドの使用にはどのような問題がありますか?」と尋ねました。
現時点では、redis の重要な機能の 1 つである redis のシングルスレッドについて答える必要があります。キー命令によりスレッドが一定期間ブロックされ、オンライン サービスが一時停止されます。命令が実行されるまでサービスは復元できません。このとき、scan コマンドを使用できます。scan コマンドは、指定したモードのキーリストをブロックせずに抽出できますが、一定の確率で重複が発生します。クライアントで 1 回実行するだけですが、全体の所要時間は長くなります。キーコマンドの長さは、直接使用するよりも長くなります。
38. 同時に期限切れになるように設定する必要があるキーが多数ある場合、通常は何に注意する必要がありますか?
回答: 多数のキーの有効期限が集中して設定されすぎると、redis で有効期限が切れるときに短い遅れが発生する可能性があります。一般に、有効期限を分散するには、ランダムな値を時間に追加する必要があります。
39. Redis を非同期キューとして使用したことがありますか?どのように使用しましたか?
回答: 通常、リスト構造はキューとして使用され、rpush がメッセージを生成し、lpop がメッセージを消費します。 lpop からのメッセージがない場合は、しばらくスリープしてから再試行してください。相手がスリープを使用してもよいか尋ねたらどうしますか? listにはblpopというコマンドもあり、メッセージがない場合はメッセージが到着するまでブロックします。相手が一度生産して複数回消費できるかどうか尋ねたらどうしますか?パブリッシュ/サブスクライブ トピック サブスクライバー モデルを使用すると、1:N メッセージ キューを実装できます。
相手からパブ/サブのデメリットは何ですかと聞かれたら?
コンシューマーがオフラインになると、生成されたメッセージは失われるため、RabbitMQ などの専門的なメッセージ キューを使用する必要があります。
相手が Redis が遅延キューをどのように実装しているかを尋ねたら?
あなたは今、面接官を殴り殺したいと思っているのでしょうが、野球のバットを手に持っているのに、なぜそんなに細かい質問をするのでしょうか?しかし、あなたは非常に自制しており、冷静に答えました。sortedset を使用し、タイムスタンプをスコアとして使用し、メッセージの内容をキーとして使用し、zadd を呼び出してメッセージを生成し、コンシューマは zrangebyscore 命令を使用して N 秒前のポーリング データを取得します。加工用に。この時点で、面接官はあなたに密かに親指を立てています。しかし、彼は知らなかったのですが、あなたがこの瞬間、椅子の後ろで中指を立てていたということです。
40. Redis 分散ロックを使用したことがありますか?それは何ですか?
最初に setnx を使用してロックを取得し、取得後、expired を使用してロックの解放忘れを防ぐために有効期限をロックに追加します。
このとき、相手はあなたの答えは良いと伝え、setnx後にexpiredを実行する前にプロセスが予期せずクラッシュするか、メンテナンスのために再起動する必要がある場合はどうなりますか?と尋ねます。この時点で、あなたは驚くべきフィードバックを与える必要があります: ああ、そうです、このロックは決して解放されません。次に、頭をかきむしり、あたかも次の結果が自分自身の主導権であるかのように、しばらく考えているふりをしてから、次のように答える必要があります: set コマンドには非常に複雑なパラメーターがあることを覚えています。これは setnx を設定し、次の時点で期限切れになるはずです。 1つの説明書にまとめて使用します。このとき、相手は微笑み、心の中で静かに言い始めます:プレス、この男は悪くありません。
マインド マップにまとめられた知識ポイントについて
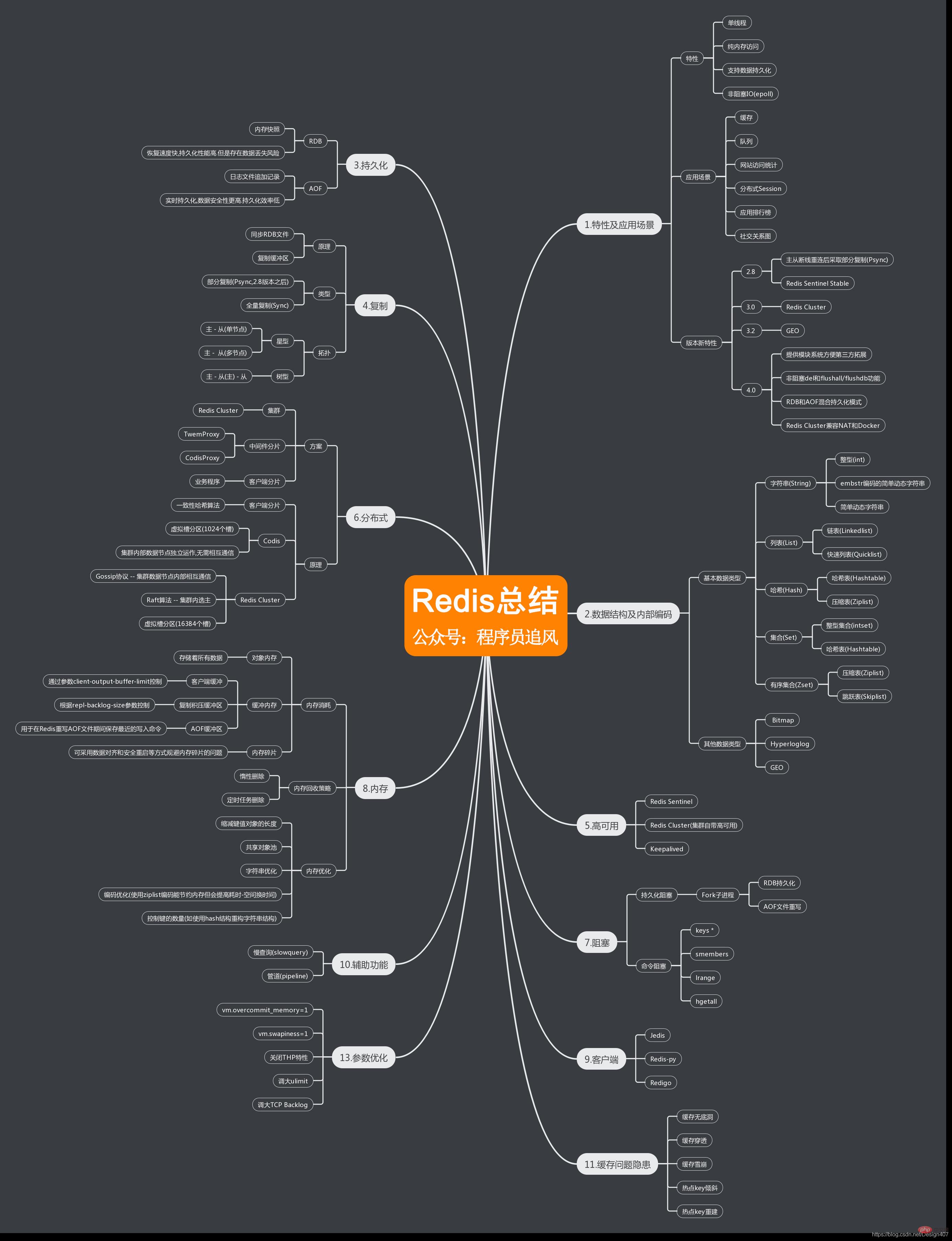
プログラミング関連の知識については、プログラミング入門#をご覧ください。 ##! !
以上がRedis の面接で見逃せない 40 の質問 (回答とマインド マップを含む)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。