
Redis に関するよくある面接の質問の概要 (回答分析付き)

- 青灯夜游転載
- 2021-04-08 10:29:182821ブラウズ
大手メーカー 6 社にインタビューした後、よく聞かれなかった Redis の面接でよくある質問を要約して共有しました (回答分析付き)。一定の参考値があるので、困っている友達が参考になれば幸いです。

[関連する推奨事項: Redis ビデオ チュートリアル ]
ナレッジ ポイントのキャッシュ

#キャッシュの種類には何がありますか?
キャッシュは、同時実行性が高いシナリオでホットスポット データ アクセスのパフォーマンスを向上させる効果的な手段であり、プロジェクトの開発時によく使用されます。 キャッシュのタイプは、ローカル キャッシュ、分散キャッシュ、マルチレベル キャッシュに分類されます。
ローカル キャッシュ:
ローカル キャッシュ は、 などのプロセスのメモリにキャッシュされます。 JVM ヒープでは、LRUMap を使用して実装することも、Ehcache などのツールを使用して実装することもできます。
ローカル キャッシュはメモリ アクセスであり、リモート対話のオーバーヘッドがなく、最高のパフォーマンスを発揮します。ただし、単一マシンの容量によって制限されます。一般に、キャッシュは小さいため拡張できません。分散キャッシュ:
分散キャッシュは、この問題をうまく解決できます。
分散キャッシュは一般に、優れた水平方向のスケーラビリティを備えており、大量のデータを含むシナリオを処理できます。欠点は、リモート要求が必要であり、パフォーマンスがローカル キャッシュほど良くないことです。マルチレベル キャッシュ:
この状況のバランスをとるために、通常、マルチレベル キャッシュが使用されます。実際のビジネス、ローカル キャッシュにはアクセス頻度が最も高い一部のホットスポット データのみが保存され、その他のホットスポット データは分散キャッシュに配置されます。
現在の一流メーカーの間では、これが最も一般的に使用されているキャッシュ ソリューションでもあり、単一のキャッシュ ソリューションでは多くの同時実行性の高いシナリオをサポートすることが困難なことがよくあります。排除戦略
ローカル キャッシュでも分散キャッシュでも、より高いパフォーマンスを確保するために、データの保存にメモリが使用されます。コストとメモリの制限により、保存されたデータがキャッシュ容量を超える場合、キャッシュされたデータを削除する必要があります。 一般的な削除戦略には、最も古いデータを削除するFIFO、最も最近使用されていないデータを削除する LRU、および最も使用されていないデータを削除する LFU が含まれます。最近使用したデータの戦略の種類。
noeviction: メモリ制限に達し、クライアントがより多くのメモリを使用するコマンドを実行しようとすると、エラーが返されます (ほとんどの書き込みコマンド、ただし、DEL といくつかの例外)
allkeys-lru: 新しく追加されたデータ用の余地があるように、最も使用されていないキー (LRU) を再利用してみてください。
volatile-lru: 最も使用されていないキー (LRU) のリサイクルを試みますが、期限切れのセット内のキーのみをリサイクルして、新しく追加されたデータを保存できる余地を残します。保管される。
allkeys-random: 新しく追加されたデータ用のスペースを確保するために、ランダム キーをリサイクルします。
volatile-random: ランダム キーをリサイクルして、新しく追加されたデータ用のスペースを確保します。ただし、有効期限が切れたセット内のキーのみを追加します。
-
volatile-ttl: 有効期限が切れたセット内のキーをリサイクルし、生存時間 (TTL) が短いキーを優先して、新たに追加できるスペースを確保します。保存するデータを追加しました。
リサイクルの前提条件を満たすキーがない場合、戦略volatile-lru、volatile-random、および volatile-ttl は noeviction と同様です。 。
LinkedHashMap にも実装されています。実装は次のとおりです:

LRU 戦略の実行を開始します。最も最近使用されていない TimeoutInfoHolder オブジェクト evict を削除します。
実際の面接では、LUR アルゴリズムを書くように求められます。元のアルゴリズムは作成しないでください。本当に多すぎて、やり終えることができません。上記の質問に答えるか、次の質問に答えてください。原則を知っていれば、Java バージョンの LRU をダウンロードするのは比較的簡単です。
Memcache
Memcache## が追加されることに注意してください以降 # MC と略される。まずMCの特徴を見てみましょう:
- MC は、リクエストの処理時にマルチスレッドの非同期 IO を使用します。これにより、マルチコア CPU を合理的に活用でき、優れたパフォーマンスが得られます。
- MC は、機能がシンプルで、データの保存にメモリを使用します。
- MC のメモリ構造と石灰化の問題については詳しく説明しません。詳細については公式 Web サイトを確認してください。
- MC はキャッシュされたデータの有効期限を設定でき、期限切れのデータはクリアされます;
- 無効化戦略は遅延無効化を採用しており、データが再度使用されるときに無効かどうかを確認します;
- 容量がいっぱいになると、キャッシュ内のデータはクリアされます。削除中は、期限切れのキーのクリーンアップに加えて、LRU ポリシーに従ってデータもカリングされます。
さらに、MC の使用にはいくつかの制限があります。これらの制限は、現在のインターネット シナリオでは非常に致命的であり、誰もが Redis と を選択する重要な理由となっています。 MongoDB:
- キーは 250 バイトを超えることはできません;
- 値は 1M バイトを超えることはできません;
- キーの最大有効期限は 30 日です;
- K-V 構造のみをサポートし、永続化およびマスター/スレーブ同期機能は提供しません。
Redis
MC との比較を容易にするために、Redis の特徴について簡単に説明します。
- MC とは異なり、Redis はシングルスレッド モードを使用してリクエストを処理します。これには 2 つの理由があります: 1 つはノンブロッキングの非同期イベント処理メカニズムを使用しているため、もう 1 つはキャッシュされたデータはすべてメモリ操作であり、IO 時間がそれほど長くなく、単一スレッドでコストを回避できるためです。スレッドコンテキストの切り替え。
- Redis は永続性をサポートしているため、Redis はキャッシュとしてだけでなく、NoSQL データベースとしても使用できます。
- MC と比較すると、Redis には非常に大きな利点があります。つまり、K-V に加えて、リスト、セット、ソートされたセット、ハッシュなどの複数のデータ形式もサポートします。等
- Redis マスター/スレーブ同期メカニズムと Cluster クラスター展開機能を提供し、高可用性サービスを提供します。
#Redis の詳細説明
Redis のナレッジ ポイント構造を次の図に示します。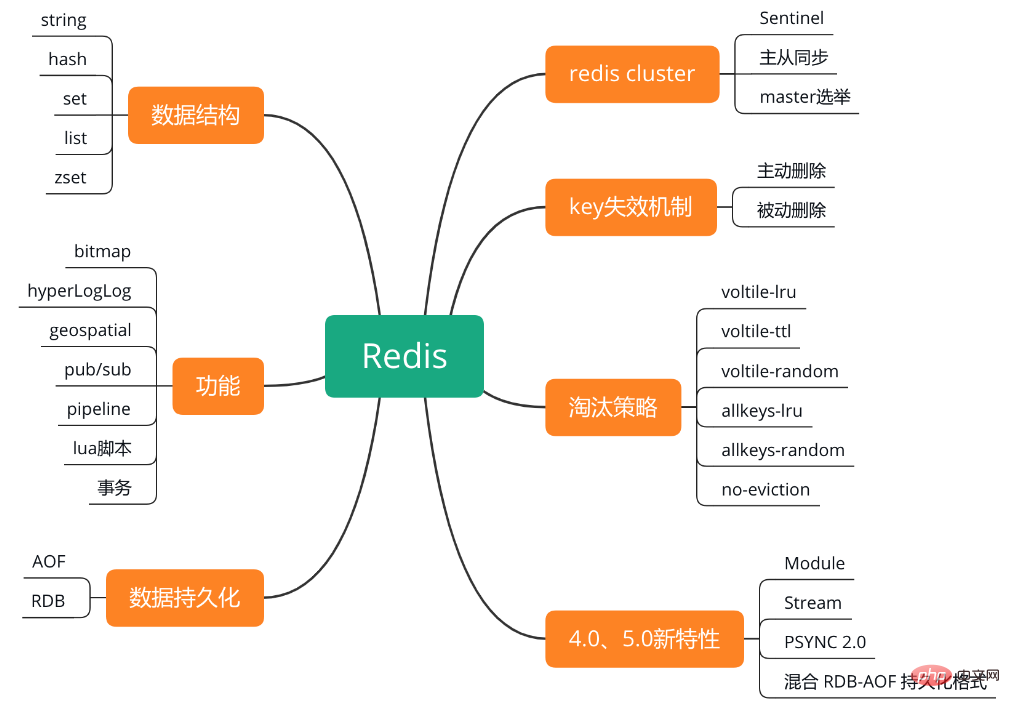
FunctionSee
Redis提供されるものの機能 まず基本的な型を見てみましょう:
String: ##String
型は # です。 ## Redisで最も一般的に使用される型で、内部実装は SDS (Simple Dynamic String) を通じて保存されます。 SDS は Java の ArrayList に似ており、冗長スペースを事前に割り当てることでメモリの頻繁な割り当てを削減できます。 これは最も単純なタイプで、通常の set と get であり、単純な KV キャッシュを実行します。 しかし、実際の開発環境では、多くの人が多くの複雑な構造を保存して使用するために
Stringに変換する可能性があります。たとえば、オブジェクトや
Listを変換することを好む人もいます。は、ストレージ用に JSONString に変換され、取り出して逆シリアル化されます。 これを行うことの是非についてはここでは議論しませんが、誰もが最も適切なシナリオで最も適切なデータ構造を使用できることを願っています。オブジェクトが最適であることが見つかりません。さて、他の人があなたのコードを引き継いで、それが非常に standard であることを見たとき、ああ、この人は何か
を持っていて、# を使用しているのがわかります。 ##文字列,ゴミ!
さて、これらはすべて余談です。皆さんも覚えておいていただけると幸いです。習慣は自然になり、小さな習慣が成功につながります。キャッシュ関数: String
文字列は最も一般的に使用されます。データ型は- Redis
- だけではなく、各言語が最も基本的な型であるため、
Redis をキャッシュとして使用したり、ストレージ層として他のデータベースと連携したり、Redis を使用したりすることができます。 高い同時実行性をサポートすると、システムの読み取りおよび書き込み速度が大幅に向上し、バックエンド データベースへの負荷が軽減されます。 カウンター:
多くのシステムは、システムのリアルタイム カウンターとして Redis - を使用します。これにより、カウント機能とクエリ機能を迅速に実装できます。また、最終的なデータ結果は、永続的に保存するために特定の時間にデータベースまたは他の記憶媒体に保存できます。
共有ユーザー セッション:
ユーザーはインターフェイスを再度更新し、再度ログインするためにデータにアクセスするか、ページ キャッシュにアクセスする必要がある場合があります Cookie - ですが、
Redis を使用してユーザーの セッション を集中管理できます。このモードでは、Redis の高可用性を確保するだけで済みます。ユーザーの時間 セッション 更新と取得はすぐに完了できます。効率が大幅に向上します。
ハッシュ:
これは Map に似た構造です。これは一般に、構造が次のことができることを意味します。オブジェクト ( このオブジェクトが他のオブジェクトをネストしていないことを条件とします) などのデータは Redis にキャッシュされ、キャッシュが読み書きされるたびに、 ##ハッシュの特定のフィールドを操作しました。 しかし、多くのオブジェクトが比較的複雑になっているため、このシナリオは実際にはある程度単純です。たとえば、製品オブジェクトにはオブジェクトを含む多くの属性が含まれている可能性があります。私自身のユースケースではあまり使用しません。
List:List
は順序付きリストであり、これを使用してさまざまなトリックを行うことができます。たとえば、List
を使用して、ファン リストや記事コメント リストなどのリスト タイプのデータ構造を保存できます。たとえば、lrange
コマンドを使用して、特定の閉じた間隔で要素を読み取ることができ、List に基づいてページング クエリを実装できます。 Redis をベースにした機能 シンプルで高パフォーマンスなページングを実装します。Weibo のプルダウンや連続ページングのようなことができます。高いパフォーマンスで、ページごとに移動できます。 たとえば、単純なメッセージ キューを作成し、それを List
の先頭から挿入し、List の末尾から取り出すことができます。 List
自体は、ホット データは言うまでもなく、開発プロセスで一般的に使用されるデータ構造です。
- メッセージ キュー: Redis
- のリンク リスト構造はブロッキング キューを簡単に実装でき、left-in および right-out コマンドを使用してキューの設計を完了できます。たとえば、データ プロデューサーは
Lpush コマンドを使用して左からデータを挿入でき、複数のデータ コンシューマーは BRpop コマンドを使用してリストの末尾のデータをブロックできます。
記事リストやデータページング表示用のアプリケーションです。 - 例えば、よく利用するブログサイトの記事リストの利用者が増え、各ユーザーが独自の記事リストを持っている場合、記事数が多い場合にはページ単位で表示する必要があります。現時点では、
Redis
リストを使用することを検討できます。リストは順序付けされるだけでなく、範囲内の要素のフェッチもサポートされ、ページング クエリ機能を完全に解決できます。クエリ効率が大幅に向上します。
Set
は、重複を自動的に削除する順序なしのセットです。 。Set
に直接基づいて、システム内で重複排除する必要があるデータを投入すると、自動的に重複排除されます。一部のデータを迅速にグローバルに重複排除する必要がある場合は、もちろん、重複排除はJVM のメモリ内の HashSet に基づいて実行することもできますが、システムの 1 つが複数のマシンにデプロイされている場合はどうなるでしょうか?グローバル Set 重複排除は、Redis に基づいて実行する必要があります。 Set
に基づいて交差、和集合、および差分演算を実行できます。たとえば、交差する場合、2 人の友人リストを結合して、共通の友人を表示できます。それ?右。とにかく、比較が速く、操作が簡単なため、このようなシナリオが多く、1つの Set
で 2 つのクエリを実行できます。ソート セット:
ソート セット
はソートされたSet、重複排除されていますが、ソートは問題ありません、書き込み時にスコアを付与し、スコアに応じて自動的に並べ替えます。 順序付きセットの使用シナリオはセットと似ていますが、セット コレクションは自動的に順序付けされませんが、ソートされたセット
はスコアを使用してメンバーを並べ替えることができ、挿入時に並べ替えられます。したがって、順序付けされた重複のないセット リストが必要な場合は、Sorted set データ構造を選択できます。
ランキング リスト: 順序付けされたコレクションの古典的な使用シナリオ。たとえば、ビデオ Web サイトでは、ユーザーがアップロードしたビデオをランク付けする必要があります。そのランク付けは、時間、再生回数、いいねの数など、さまざまな観点から維持されます。- Use Sorted Sets
- to make a Weighted Queue. たとえば、通常のメッセージのスコアは 1、重要なメッセージのスコアは 2 です。スレッドは、スコアを押して逆の順序で作業タスクを取得することを選択できます。重要なタスクに優先順位を付けます。
Weibo ホット検索リストの後ろに人気の値があり、その前に名前があります
Bitmap
:Bitmap はビットごとの情報の保存をサポートしており、BloomFilter )
;# の実装に使用できます。##HyperLogLog:
は、大規模なデータの重複排除に適した、不正確な重複排除およびカウント機能を提供します。統計 UV;
地理空間:
地理的位置を保存し、位置の距離を計算したり、半径に基づいて位置を計算したりするために使用できます。 Redis を使用して近くの人々を実装することを考えたことはありますか?それとも最適なマップ パスを計算しますか? これら 3 つは、実際には一種のデータ構造と見なすことができます。夢の始まりである Redis の基本で言及したことを今でも覚えている友人がどれだけいるかわかりません。基本的な 5 つのタイプだけを知っている場合, そうすると60点しか取れませんが、高度な使い方がわかれば、何かあると思います。 pub/sub: パイプライン: Lua: Redis は、一連の機能を実行するための Lua スクリプトの送信をサポートしています。 like とコメントをしていただければ簡単に販売できます。 トランザクション: Redis は厳密なトランザクションを提供しません。 Redis はコマンドのシリアル実行のみを保証し、すべての実行を保証できますが、コマンドの実行が失敗した場合、ロールバックせずに実行を継続します。 永続性 Redis は、RDB と AOF という 2 つの永続化メソッドを提供します。RDB はデータをメモリに保存します。データセットははスナップショットの形式でディスクに書き込まれ、実際の操作はバイナリ圧縮ストレージを使用して fork サブプロセスを通じて実行されます。AOF は、Redis によって処理されたすべての書き込み操作または削除操作を次の形式で記録します。テキストログ。 RDB Redis データ全体を 1 つのファイルに保存します。これは災害復旧に適していますが、欠点は、スナップショットの保存前にダウンタイムが発生すると、スナップショットの保存中にデータが失われることです。この期間は失われ、スナップショットを保存するとサービスが短期間利用できなくなる可能性があります。 AOF ログ ファイルへの操作の書き込みに使用される追加モードには、1 秒ごとの同期、変更ごとの同期、および非同期をサポートする柔軟な同期戦略があります。データセットのサイズが大きいため、AOF は RDB よりも大きく、動作効率の点で AOF は RDB よりも遅くなることがよくあります。 「Beat the Interviewer」シリーズ - Redis セントリー、永続性、マスター/スレーブ、ハンドシュレッディング LRU 高可用性 Sentinel ですが、クラスターの高可用性は保証できます。 なぜ 3 つのインスタンスが必要なのでしょうか?まず 2 人の歩哨に何が起こるかを見てみましょう。 それでは、これの何が問題なのでしょうか? M1 がダウンしている場合、S1 がダウンしていなければ問題ありませんが、マシン全体がダウンしている場合はどうなるでしょうか。センチネルは S2 だけが残っており、フェイルオーバーを許可するセンチネルは存在せず、もう一方のマシンには R1 がありますが、フェイルオーバーは実行されません。 古典的なセンチネル クラスターは次のとおりです: Nuan Man 私、センチネル コンポーネントの主な機能を簡単にまとめておきます。 マスター/スレーブ これに関しては、先ほど述べたデータの永続化と同じですRDB と AOF には密接な関係があります。 まず、なぜマスター/スレーブ アーキテクチャ モデルを使用する必要があるのかについてお話しますが、前述したように、単一マシン QPS には上限があり、 の特性は次のとおりです。 Redis はサポートされている必要があります。高い同時実行性で読み取る場合は、1 台のマシンで読み取りと書き込みができます。 これに耐えられる人は 、あなたは人間ではありません。しかし、このマスター マシンにデータを書き込ませ、他のスレーブ マシンにデータを同期させ、すべてのスレーブ マシンがそれを使用して読み取りを行う場合、大量のリクエストを分散した方がはるかに優れていると考えられます。また、容量を拡張する場合、水平方向の拡張が可能になります。簡単に達成できます。 スレーブを起動すると、psync コマンドがマスターに送信されます。このスレーブが最初の場合は、マスターに接続すると、完全なレプリケーションがトリガーされます。マスターはスレッドを開始し、RDB スナップショットを生成し、新しい書き込みリクエストをメモリにキャッシュします。RDB ファイルが生成された後、マスターはこの RDB を保存しますスレーブに送信されます。取得後、スレーブが最初に行うことは、それをローカル ディスクに書き込み、メモリにロードすることです。その後、マスターはメモリにキャッシュされているすべての新しい名前をスレーブに送信します。 私が投稿した後、CSDN のネチズン: Jian_Shen_Zer が質問をしました: マスターとスレーブが同期しているとき、新しいスレーブが入ってきたときは # を使用してください##RDB 、その後のデータはどうなるでしょうか?新しいデータをマスターからスレーブに同期するにはどうすればよいですか? ##同様に、ログの増分をスレーブ サービスに同期するだけです キー障害メカニズム Redis 定期的な遅延メモリの削除
キャッシュの更新方法 これは、キャッシュの使用を決定するときに考慮する必要がある問題です。 データ ソースが DB ではなく、他のリモート サービスである場合、データの変更をタイムリーに事前に検知できない可能性があります。この場合、通常はキャッシュされたデータの有効期限を設定することを選択します。これは、データの不整合に対する最大許容時間です。 このシナリオでは、無効化更新を選択できます。キーが存在しない場合、または無効な場合は、まずデータ ソースに最新データの取得を要求し、それから再度キャッシュして、有効期限を更新します。 Redis 解決策は、サービスが時間のかかることに特に敏感でない場合は、再試行を増やすことができます。サービスが時間のかかることに敏感な場合は、非同期補正タスクを通じて失敗した更新を処理するか、または短い次回の更新が成功し、最終的な一貫性が保証される限り、データの不一致はビジネスに影響しません。
キャッシュペネトレーション 解決策は次のとおりです。 存在しないユーザーの場合は、空のオブジェクトをキャッシュに保存してマークを付け、同じ ID が再び DB にアクセスするのを防ぎます。ただし、この方法では問題が十分に解決されない場合があり、大量の無駄なデータがキャッシュに格納される可能性があります。 BloomFilter フィルターを使用します。BloomFilter の特徴は存在検出です。BloomFilter にデータが存在しない場合は、そのデータは存在しないはずです。BloomFilter に存在する場合は、データが存在する必要があります。 、実際のデータは存在しない可能性があります。この種の問題を解決するのに非常に適しています。 キャッシュの故障 #キャッシュの故障とは、特定のホットスポット データに障害が発生したとき、つまり大規模なこのデータに対するリクエストの数がデータ ソースに侵入します。 キャッシュ雪崩 キャッシュ雪崩、理由はキャッシュがハングすることです。すべてのリクエストは DB に送信されます。 ここでいくつかの点だけ触れておきます。前回の記事は本当に詳細すぎたので、仕方がありません。 と同様に、ここでは重複しません。 テスト ポイントとボーナス ポイント# #Takeノート! キャッシュについては面接時にお聞きします、主に検査用 キャッシュ機能を理解し、MC Redis の特徴と使い方をマスターします。 キャッシュの使用シナリオと、さまざまな種類のキャッシュの使用方法を知る必要があります。例: Redis; の zset 構造体を使用して保存できます。 MC と #MC と Redis #RDB や Cluster デプロイメント原則を理解するため##と違い。 キャッシュの侵入、ブレークダウン、アバランシェの類似点、相違点、および解決策を知る必要があります。 #........ では、実際のアプリケーション シナリオに基づいてキャッシュの使用法を紹介します。たとえば、バックエンド サービス インターフェイスを呼び出して情報を取得する場合、ローカルおよびリモートのマルチレベル キャッシュを使用できます。動的ランキング シナリオの場合は、Redis## の Sorted set プロジェクトでどのようなシナリオで Redis が使用されたか、どのようなデータ構造が使用されたか、どのタイプが使用されたかなど、分散キャッシュの設計と使用の経験があることが最適です。 MC を使用する場合は、見積もりサイズに応じて McSlab 割り当てパラメータなどを調整してください。 キャッシュの使用時に発生する可能性がある問題を理解しておくことが最善です。たとえば、Redis はシングルスレッド処理リクエストです。相互影響を防ぐために、時間のかかる単一リクエストのタスクはできる限り回避する必要があります。Redis サービスは、他の CPU 負荷の高いプロセスと同じ場所.マシン; または、Redis キャッシュ データがハード ディスクにスワップされてパフォーマンスに影響を与えるのを防ぐために、スワップ メモリ交換を無効にします。別の例は、前述した MC 石灰化の問題です。 Redis の一般的なアプリケーション シナリオを理解するには、たとえば、Redis を使用して分散ロックを実装し、Bitmap## を使用します。 #BloomFilter を実装するには、HyperLogLog を使用して UV 統計などを実行します。 プログラミング ビデオ をご覧ください。 ! スレーブの優先順位が低く設定されているほど、優先順位が高くなります。
Redis クラスターでは、センチネルも複数のインスタンスにデプロイされ、センチネルは Raft プロトコルを使用して高可用性を確保します。 Redis クラスターはシャーディング メカニズムを使用しており、内部で 16384 個のスロットに分割され、すべてのマスター ノードに分散され、各マスター ノードがスロットの一部を担当します。データ操作中に、キーに従って CRC16 が実行され、キーがどのスロットにあるか、どのマスターがそれを処理するかを計算します。データの冗長性はスレーブ ノードを通じて保証されます。



実際のシナリオでは、これら 2 つの方法が組み合わせて使用されます。 私が大々的に紹介しなかった理由は古い友人ならみんな知っています 「インタビュアーを攻撃する」シリーズ - Redis の基本

-キャッシュ DB ホット データDB の負荷を軽減する; 同時実行パフォーマンスを向上させるためのキャッシュ依存サービス;
Redis の一般的なコマンド (アトミックの増加と減少、さまざまなデータ構造を操作するコマンドなど) を理解するため。
以上がRedis に関するよくある面接の質問の概要 (回答分析付き)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。