
Redis の高頻度インタビューの質問 (回答分析付き)

- 青灯夜游転載
- 2021-04-16 10:36:523842ブラウズ
この記事では、Redis の面接でよくある質問をいくつか紹介します。一定の参考値があるので、困っている友達が参考になれば幸いです。

Redis とは
Redis (Remote Dictionary Server) は、オープンソース (BSD ライセンス) の高パフォーマンスです。非リレーショナル (NoSQL) キーと値のデータベース。
Redis は、キーと 5 つの異なるタイプの値の間のマッピングを保存できます。キーのタイプは文字列のみであり、値は文字列、リスト、セット、ハッシュ テーブル、順序付きセットの 5 つのデータ タイプをサポートします。
従来のデータベースとは異なり、Redis データはメモリに保存されるため、読み取りおよび書き込み速度が非常に高速です。そのため、Redis はキャッシュ方向で広く使用されており、1 秒あたり 100,000 を超える読み取りおよび書き込み操作を処理できます。 . 実行することが知られている最速の Key-Value DB。さらに、Redis は分散ロックによく使用されます。さらに、Redis はトランザクション、永続性、LUA スクリプト、LRU 駆動イベント、およびさまざまなクラスター ソリューションをサポートします。
Redis の長所と短所は何ですか
利点
優れた読み取りおよび書き込みパフォーマンス, Redisは読み込みが110000回/秒、書き込み速度が81000回/秒となります。
データの永続性をサポートし、AOF と RDB の 2 つの永続化メソッドをサポートします。
トランザクションをサポートします。Redis のすべての操作はアトミックです。同時に、Redis は複数の操作をマージした後のアトミック実行もサポートします。
豊富なデータ構造。文字列型の値をサポートするだけでなく、ハッシュ、セット、zset、リスト、その他のデータ構造もサポートします。
マスター/スレーブ レプリケーションをサポートし、ホストはデータをスレーブに自動的に同期し、読み取りと書き込みを分離できます。
欠点
データベース容量は物理メモリによって制限されており、大量のデータの高パフォーマンスな読み取りおよび書き込みには使用できないため、Redis に適したシナリオは次のとおりです。主に少量のデータに限定され、高性能の演算と計算が可能です。
Redis には自動フォールト トレランス機能と回復機能がありません。ホスト マシンとスレーブ マシンのダウンタイムにより、一部のフロントエンドの読み取りおよび書き込みリクエストが失敗します。マシンが再起動するまで待つ必要があります。または、回復するフロントエンド IP を手動で切り替えます。
ホスト マシンがダウンしました。マシンがダウンする前に、一部のデータをスレーブ マシンに同期できませんでした。IP を切り替えた後、データの不整合が生じ、システムの可用性が低下します。
Redis はオンライン拡張に対応しにくく、クラスタ容量が上限に達するとオンライン拡張が非常に複雑になります。この問題を回避するために、運用および保守担当者は、システムがオンラインになったときに十分なスペースを確保する必要がありますが、これによりリソースが大幅に浪費されます。
キャッシュを使う理由、Redisを使う理由
主に「高パフォーマンス」と「高同時実行性」の2点から見ていきましょうこの問題を見てください。
高パフォーマンス:
ユーザーがデータベース内の一部のデータに初めてアクセスする場合。このプロセスはハードディスクから読み取られるため、時間がかかります。ユーザーがアクセスしたデータをキャッシュに保存し、次回アクセスしたときにキャッシュから直接データを取得できるようにします。キャッシュの操作はメモリを直接操作することになるので、かなり高速です。データベース内の対応するデータが変更された場合は、キャッシュ内の対応するデータを同期的に変更するだけです。
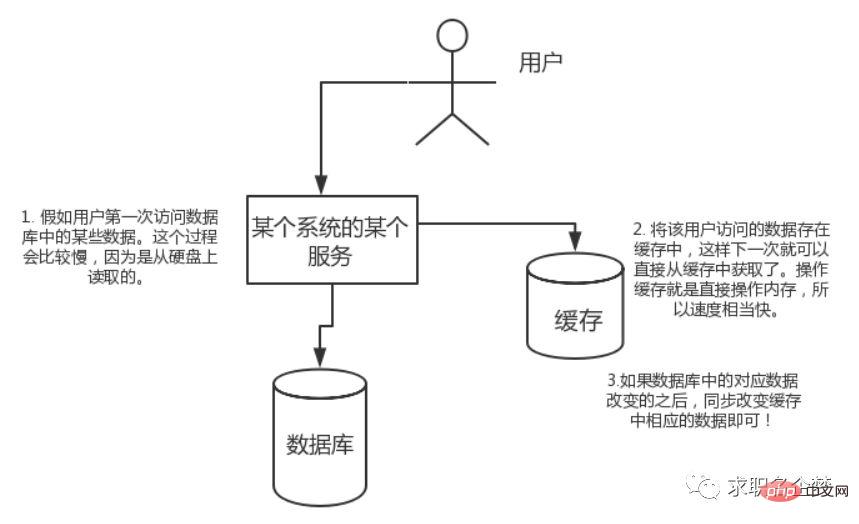
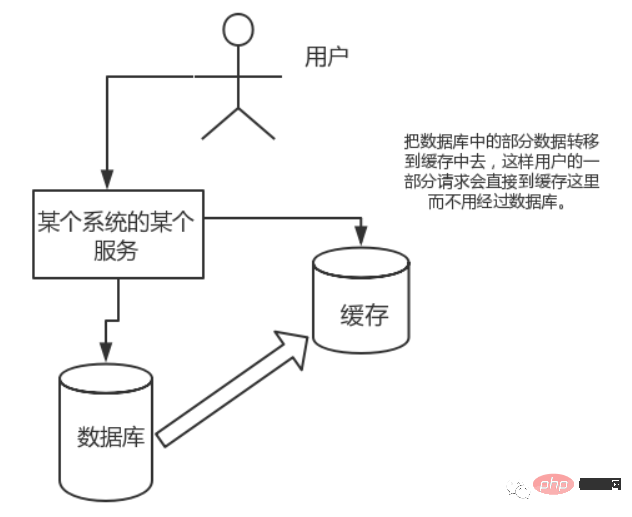
高い同時実行性:
直接操作キャッシュが耐えられるリクエストは、データベースへの直接アクセスよりもはるかに多くなります。したがって、データベース内のデータの一部をキャッシュに転送して、ユーザーのリクエストの一部がデータベースを経由せずに直接キャッシュに送られるようにすることを検討できます。
キャッシュにマップ/グアバではなく Redis を使用する理由
#キャッシュはローカル キャッシュに分割され、分散されます。キャッシュキャッシュ。 Javaを例に挙げると、ローカルキャッシュは組み込みマップやguavaを利用して実装されており、軽量かつ高速であることが最大の特徴であり、ライフサイクルはjvmの破棄で終了し、複数のインスタンスの場合はそれぞれのインスタンス 各キャッシュを保存する必要がありますが、キャッシュは一貫していません。
redis または memcached の使用は分散キャッシュと呼ばれ、複数のインスタンスの場合、各インスタンスはデータのキャッシュを共有し、キャッシュは一貫しています。欠点は、redis または memcached サービスの可用性を高く保つ必要があり、プログラム アーキテクチャ全体が比較的複雑であることです。
Redis はなぜそれほど速いのですか?
1. Redis は完全にメモリに基づいており、ほとんどのリクエストは純粋なメモリ操作であり、非常に高速です。データは HashMap と同様にメモリに保存されます。HashMap の利点は、検索と操作の時間計算量が O(1);
#2 であることです。データ構造はシンプルであり、データ操作も簡単 Redis の場合 データ構造が特別に設計されている;
3. 不要なコンテキスト切り替えや競合状態を避けるためにシングルスレッドを使用する マルチプロセスやマルチスレッドによる切り替えを考慮する必要がないさまざまなロックの問題について、ロックや解放の操作はなく、デッドロックの可能性によるパフォーマンスの消費もありません;
4. マルチチャネル I/O 多重化モデル、ノンブロッキング IO を使用します。
5. 異なる基礎となるモデルを使用し、基礎となる実装メソッドとクライアントとの通信用のアプリケーション プロトコルが異なります。一般的なシステムがシステム関数を呼び出すと、移動とリクエストに一定の時間が無駄になるため、Redis は独自の VM メカニズムを直接構築しました;
Redis にはどのようなデータ型がありますか
# #Redis には主に String、List、Set、Zset、Hash の 5 つのデータ型があり、ほとんどの使用要件を満たします
| Type |
ストレージ値 |
操作 |
アプリケーション シナリオ |
|||||||||||||||||||||||||||||||||||||||||||||
| 文字列全体または文字列の一部に対して実行します。演算; | 整数および浮動小数点数に対してインクリメントまたはデクリメント演算を実行します | 単純なキーと値のペアのキャッシュを実行します|||||||||||||||||||||||||||||||||||||||||||||||
| #List | 要素を両端からプッシュまたはポップします。単一または複数の要素をトリムし、範囲内の要素のみを保持します。 | いくつかのリスト型データ構造 (ファン リストに似たデータ) を保存します。 、記事のコメント リストなど |
SET | |||||||||||||||||||||||||||||||||||||||||||||
| Unordered set |
追加および取得、単一の要素を削除します。 要素がセット内に存在するかどうかを確認します; | 積集合、和集合、および差集合を計算します; 集合から要素をランダムに取得します 積集合、和集合、差集合などの演算は可能です。 2 人のファン リストを 1 つの交差点に結合します |
#HASH | |||||||||||||||||||||||||||||||||||||||||||||
| すべてのキーと値のペアを取得; キーが存在するかどうかを確認する |
オブジェクトなどの構造化データ |
ZSET | ||||||||||||||||||||||||||||||||||||||||||||||
| 要素の追加、取得、削除; | スコア範囲またはメンバーに基づいて要素を取得; キーのランキングを計算 |
重複排除されていますが、上位ユーザーの取得など、並べ替えは可能です |
Redis アプリケーション シナリオ概要 1 1. カウンタ 要約 2 他のキャッシュと比較すると、Redis には複数のデータ型をサポートしているという非常に大きな利点があります。string——memcached ストレージ構造、SMS 検証コード、構成情報などに似た、最も単純な k-v ストレージに適しており、このタイプを使用して保存します。 hash - 通常、キーは ID または一意の識別子であり、値は詳細に対応します。製品詳細、個人情報詳細、ニュース詳細など。 list——リストは順序付けされているため、順序付けされた比較的固定されたデータを格納するのに適しています。県市表、辞書表など。リストは順序付けされているため、最新のホットニュース、メッセージキューなど、書き込み時間に応じてソートするのに適しています。 set——これは、Weibo 上でその人がどのような友達を持っているかなど、ID リスト モデルとして単純に理解できます。set の最も優れている点は、2 つの間の共通部分を提供できることです。セット、和集合、差分演算。例: 2 人の共通の友人を見つけるなど。 Sorted Set—— は、セットの拡張バージョンであり、スコア値に従って自動的に並べ替えるスコア パラメーターを追加しています。上位 10 位など、挿入時間順にソートされていないデータに適しています。 上で述べたように、Redis はリレーショナル データベースほど複雑なデータ構造ではありませんが、一般的なキャッシュ データ構造以上のものを含む多くのシナリオにも適しています。それぞれのデータ構造に適したビジネスシナリオを理解することで、開発効率の向上だけでなく、Redisのパフォーマンスを有効に活用することもできます。 Redis 永続性とは何ですか?永続化とは、サービスがダウンした場合にメモリ データが失われるのを防ぐために、メモリ データをディスクに書き込むことです。 Redis の永続化メカニズムとは何ですか?それぞれの長所と短所は何ですか?#Redis は、RDB (デフォルト) と AOF メカニズムの 2 つの永続化メカニズムを提供します。
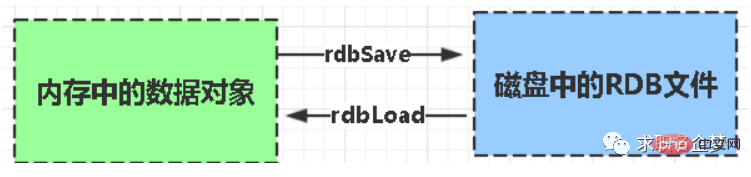
RDB Redis のデフォルトの永続化メソッドです。メモリデータは一定期間ごとにスナップショット形式でハードディスクに保存され、対応するデータファイルがdump.rdbとして生成されます。スナップショットの期間は、構成ファイルの save パラメーターによって定義されます。
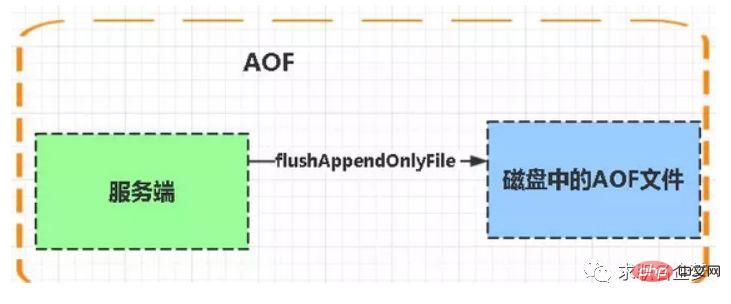
1. ファイル dump.rdb が 1 つだけあるため、永続化に便利です。 2. 耐災害性が高く、ファイルを安全なディスクに保存できます。 3. パフォーマンスを最大化するには、子プロセスをフォークして書き込み操作を完了し、メイン プロセスがコマンドの処理を継続できるようにして、IO を最大化します。永続化のために別のサブプロセスを使用すると、メインプロセスは IO 操作を実行しないため、Redis の高いパフォーマンスが保証されます。 4. データセットが大きい場合、AOF よりも起動効率が高くなります。 欠点: 1. データのセキュリティが低い。 RDB は一定の間隔で永続化されますが、永続化の間に redis に障害が発生するとデータ損失が発生します。したがって、この方法は、データ要件が厳密ではない場合に適しています) 2. AOF (追加専用ファイル) 永続化方法: すべてのコマンド ライン レコードが redis コマンドの形式で完全に永続的に保存されることを指します。 request プロトコル ) は aof ファイルとして保存されます。 AOF: 永続性AOF 永続性 (つまり、ファイル追加のみの永続性) は、Redis が実行した各書き込みコマンドを個別のログ ファイルに記録します。再起動すると、永続ログ ファイル内のデータが復元されます。 両方の方法を同時に有効にすると、データ回復 Redis は AOF 回復を優先します。
利点: 1. データ セキュリティ、永続性は、コマンド操作のたびに、appendfsync 属性を使用して設定できます。 aof ファイルに一度記録するだけです。 2. 追加モードでファイルを書き込む サーバーが途中でダウンした場合でも、redis-check-aof ツールを使用してデータの一貫性の問題を解決できます。 3. AOF メカニズムの書き換えモード。 AOF ファイルが書き換えられる前に (ファイルが大きすぎる場合、コマンドはマージされて書き換えられます)、一部のコマンド (誤ってフラッシュオールなど) を削除する可能性があります。 #欠点: 1. AOF ファイルは RDB ファイルに比べてサイズが大きく、回復速度が遅くなります。 2. データセットが大きい場合、rdbよりも起動効率が悪くなります。メリットとデメリットは何ですか?
一般的に、PostgreSQL と同等のデータ セキュリティを実現したい場合は、両方の永続化機能を同時に使用する必要があります。この場合、Redis が再起動されると、AOF ファイルが最初にロードされて元のデータが復元されます。これは、通常の状況では、AOF ファイルによって保存されたデータ セットの方が、RDB ファイルによって保存されたデータ セットよりも完全であるためです。データを非常に重視していても、数分以内のデータ損失は許容できる場合は、RDB 永続性を使用するだけで済みます。
サーバーの実行中にのみデータを存在させたい場合は、永続化メソッドを使用することもできません。 Redis の永続データとキャッシュを拡張するにはどうすればよいですか?Redis をキャッシュとして使用する場合は、コンシステント ハッシュを使用して動的な拡張と縮小を実現します。Redis を永続ストレージとして使用する場合は、固定のキーとノードのマッピング関係を使用する必要があり、ノードの数は一度決定すると変更できません。それ以外の場合 (つまり、Redis ノードを動的に変更する必要がある場合)、実行時にデータのバランスを再調整できるシステムを使用する必要があります。現在、これを実行できるのは Redis クラスターのみです。 Redis がキーと値のデータベースであり、キャッシュされたキーの有効期限を設定できることは誰もが知っています。 Redisで。 Redis の有効期限ポリシーは、Redis にキャッシュされたキーの有効期限が切れたときに Redis がそれを処理する方法を指します。有効期限戦略には通常、次の 3 つのタイプがあります: : 有効期限を設定する各キーはタイマーを作成する必要があります。有効期限が切れると、すぐにクリアされます。この戦略は期限切れのデータを即座にクリアでき、メモリに非常に優しいですが、期限切れのデータを処理するために大量の CPU リソースを占有するため、キャッシュの応答時間とスループットに影響します。 遅延有効期限: キーにアクセスしたときのみ、キーの有効期限が切れているかどうかを判定し、有効期限が切れたらキーをクリアします。この戦略は CPU リソースを最大限に節約できますが、メモリには非常に優しくありません。極端な場合には、期限切れの多数のキーに再度アクセスできなくなり、クリアされずに大量のメモリを占有してしまうことがあります。 定期有効期限: 一定期間ごとに、特定の数のデータベースの有効期限ディクショナリ内の特定の数のキーがスキャンされ、期限切れのキーがクリアされます。この戦略は、最初の 2 つの戦略の折衷案です。スケジュールされたスキャンの時間間隔と各スキャンの制限された消費時間を調整することにより、さまざまな状況下で CPU とメモリのリソース間の最適なバランスを実現できます。 (expires ディクショナリは、有効期限が設定されたすべてのキーの有効期限データを保存します。ここで、key はキー空間内のキーへのポインタ、value はミリ秒精度でのキーの UNIX タイムスタンプ表現です。有効期限。キー スペースは、Redis クラスターに保存されているすべてのキーを指します。)Redis は、遅延有効期限と定期的な有効期限の両方の戦略を使用します。 Redis キーの有効期限と永続的な有効性を設定するにはどうすればよいですか?EXPIRE および PERSIST コマンド。 キーの有効期限が期限切れまでに設定されていることはわかっていますが、期限切れのデータはどのように処理すればよいですか?キャッシュ無効化ポリシーに加えてこれはキャッシュ サーバーに付属しています さらに (Redis にはデフォルトで 6 つの戦略から選択できます)、特定のビジネス ニーズに応じてキャッシュの削除をカスタマイズすることもできます。一般的な戦略は 2 つあります: 1. スケジュール済みキャッシュの削除 期限切れのキャッシュをクリーンアップします。 2. ユーザーがリクエストを行うとき、リクエストで使用されているキャッシュの期限が切れているかどうかを確認します。期限が切れた場合は、基盤となるシステムにアクセスして新しいデータを取得し、キャッシュを更新します。キャッシュ。 どちらにも独自の長所と短所があります。前者の短所は、キャッシュされた多数のキーを維持するのがより面倒なことです。後者の短所は、ユーザーが毎回リクエストすると、キャッシュが無効であると判断する必要があり、ロジックは比較的複雑です。具体的にどのソリューションを使用するかは、独自のアプリケーション シナリオに基づいて検討できます。 MySQL には 2,000 万のデータがありますが、redis には 200,000 のデータしか保存されません。redis 内のデータがホット データであることを確認するにはどうすればよいですか?Redis メモリ データ セットのサイズが特定のサイズに増加すると、データ削除戦略が実装されます。 Redis のメモリ削除戦略とは何ですか?Redis のメモリ削除戦略とは、Redis のメモリが不足した場合に問題を解決する方法を指します。キャッシュが不十分です。新たな書き込みが必要であり、追加のスペースを要求する必要があるプロセス データ。 1. グローバル キー スペースの選択的削除 noeviction: メモリが新しく書き込まれたデータを収容するのに十分でない場合、新しい書き込み操作ではエラーが報告されます。 allkeys-lru: 新しく書き込まれたデータを格納するにはメモリが不足している場合、キー スペースで、最も最近使用されていないキーを削除します。 (これが最も一般的に使用されます) allkeys-random: メモリが新しく書き込まれたデータを収容するのに十分でない場合、キーはキー空間からランダムに削除されます。 2. 有効期限を設定したキースペースの選択的削除 volatile-lru: メモリが新しく書き込まれたデータを収容するのに十分でない場合、有効期限が設定されたキースペースで、最も最近使用されていないキーを削除します。 volatile-random: メモリが新しく書き込まれたデータを収容するのに不十分な場合、キーは有効期限が設定されてキー空間からランダムに削除されます。 volatile-ttl: メモリが新しく書き込まれたデータを収容するのに不十分な場合、有効期限が設定されたキー空間では、有効期限が古いキーが最初に削除されます。 概要 Redis のメモリ削除戦略の選択は、期限切れのキーの処理には影響しません。メモリ削除ポリシーは、メモリが不十分な場合に追加の領域を必要とするデータを処理するために使用され、有効期限ポリシーは、期限切れのキャッシュ データを処理するために使用されます。 Redis は主にどのような物理リソースを消費しますか? ############メモリ。Redis のメモリが不足するとどうなりますか? 設定された上限に達すると、Redis 書き込みコマンドはエラー メッセージを返します (ただし、読み取りコマンドは正常に戻ることができます)。または、Redis の書き込み時にメモリ削除メカニズムを構成することもできます。メモリの上限に達しました。古いコンテンツはフラッシュされます。Redis はメモリの最適化をどのように実行しますか? 通常、多数の小さな Key-Value を 1 つのグループにまとめて保存できるため、ハッシュ、リスト、ソート セット、セットなどのコレクション型データを有効に活用できます。よりコンパクトな方法。可能な限りハッシュを使用する ハッシュ テーブル (ハッシュ テーブルに格納される数値が小さいことを意味します) は非常に少量のメモリを使用するため、データ モデルを可能な限りハッシュ テーブルに抽象化する必要があります。たとえば、Web システムにユーザー オブジェクトがある場合、ユーザーの名前、姓、電子メール、パスワードに個別のキーを設定せず、すべてのユーザー情報をハッシュ テーブルに保存します。Redis スレッド モデル Redis は、Reactor モデルに基づいてネットワーク イベント プロセッサを開発しました。このプロセッサは、ファイル イベント ハンドラ (ファイル イベント ハンドラ) と呼ばれます。その構造は、複数のソケット、IO マルチプレクサ、ファイル イベント ディスパッチャ、およびイベント プロセッサの 4 つの部分で構成されます。ファイル イベント ディスパッチャー キューの消費はシングル スレッドであるため、Redis はシングル スレッド モデルと呼ばれます。1. ファイル イベント ハンドラーは、I/O 多重化 (多重化) プログラムを使用して複数のソケットを同時に監視し、ソケットによって現在実行されているタスクに従ってソケットを構成します。ハンドラー。
ファイル イベント プロセッサはシングル スレッド方式で実行されますが、I/O マルチプレクサを使用して複数のソケットをリッスンすることにより、ファイル イベント プロセッサは高性能のネットワーク通信モデルを実装するだけでなく、同じくシングルスレッド方式で実行される Redis サーバー内の他のモジュールと適切に接続されているため、Redis 内のシングルスレッド設計のシンプルさが維持されます。 トランザクションとは何ですか?#トランザクションは、単一の分離された操作です。トランザクション内のすべてのコマンドはシリアル化され、順番に実行されます。トランザクションの実行中、他のクライアントから送信されたコマンド要求によって中断されることはありません。 Redis トランザクションの概念 Redis トランザクションの本質は、MULTI、EXEC、WATCH などのコマンドの集合です。トランザクションは一度に複数のコマンドの実行をサポートしており、トランザクション内のすべてのコマンドはシリアル化されます。トランザクション実行処理中、キュー内のコマンドは順番に実行され、他のクライアントから送信されたコマンド要求はトランザクション実行コマンドシーケンスに挿入されません。 要約すると、redis トランザクションは、キュー内の一連のコマンドを 1 回限り、順次、排他的に実行します。#Redis トランザクションの 3 つのステージ1. トランザクションの開始 MULTI 2. コマンド エンキュー 3. トランザクション実行 EXEC トランザクション実行処理中、サーバは EXEC、DISCARD、WATCH、MULTI 以外のリクエストを受信した場合、リクエストをキューに入れます ##Redis トランザクション関連コマンドRedis トランザクション機能は 4 つのプリミティブ MULTI、EXEC、DISCARD、WATCH Redis はトランザクション内のすべてのコマンドを実行します。シリアル化されてから順番に実行されます。 1、 redis はロールバックをサポートしていません、「トランザクションが失敗したときに Redis はロールバックしませんが、残りのコマンドは実行し続けます」ため、Redis の内部はシンプルかつ高速なままになります。 2, トランザクション内のコマンドでエラーが発生した場合、すべてのコマンドは実行されません;3, トランザクションでエラーが発生した場合トランザクション エラーが発生した場合、正しいコマンドが実行されます。WATCH コマンドは、Redis トランザクションにチェック アンド セット (CAS) 動作を提供するオプティミスティック ロックです。 1 つ以上のキーを監視できます。キーの 1 つが変更 (または削除) されると、それ以降のトランザクションは実行されず、EXEC コマンドが実行されるまで監視が継続されます。 MULTI コマンドはトランザクションの開始に使用され、常に OK を返します。 MULTI の実行後、クライアントはサーバーに任意の数のコマンドを送信し続けることができます。これらのコマンドはすぐには実行されず、キューに入れられます。EXEC コマンドが呼び出されると、キュー内のすべてのコマンドが実行されます。 EXEC: すべてのトランザクション ブロック内でコマンドを実行します。トランザクションブロック内のすべてのコマンドの戻り値をコマンド実行順に並べて返します。操作が中断されると、空の値 nil が返されます。 DISCARD を呼び出すと、クライアントはトランザクション キューをクリアしてトランザクションの実行を放棄でき、クライアントはトランザクション状態から抜けます。 UNWATCH コマンドは、すべてのキーの監視をキャンセルできます。 トランザクション管理 (ACID) の概要
Redis トランザクションは分離をサポートしていますか Redis は単一プロセス プログラムであり、トランザクションの実行時にトランザクションが中断されず、トランザクションが完了するまで実行できることが保証されます。キュー内のコマンドに対してトランザクションが実行されます。したがって、Redis トランザクションは常に分離されます。Redis では、単一のコマンドはアトミックに実行されますが、トランザクションはアトミックではありません。アトミックでロールバックなし。トランザクション内のいずれかのコマンドが実行に失敗した場合でも、残りのコマンドは引き続き実行されます。
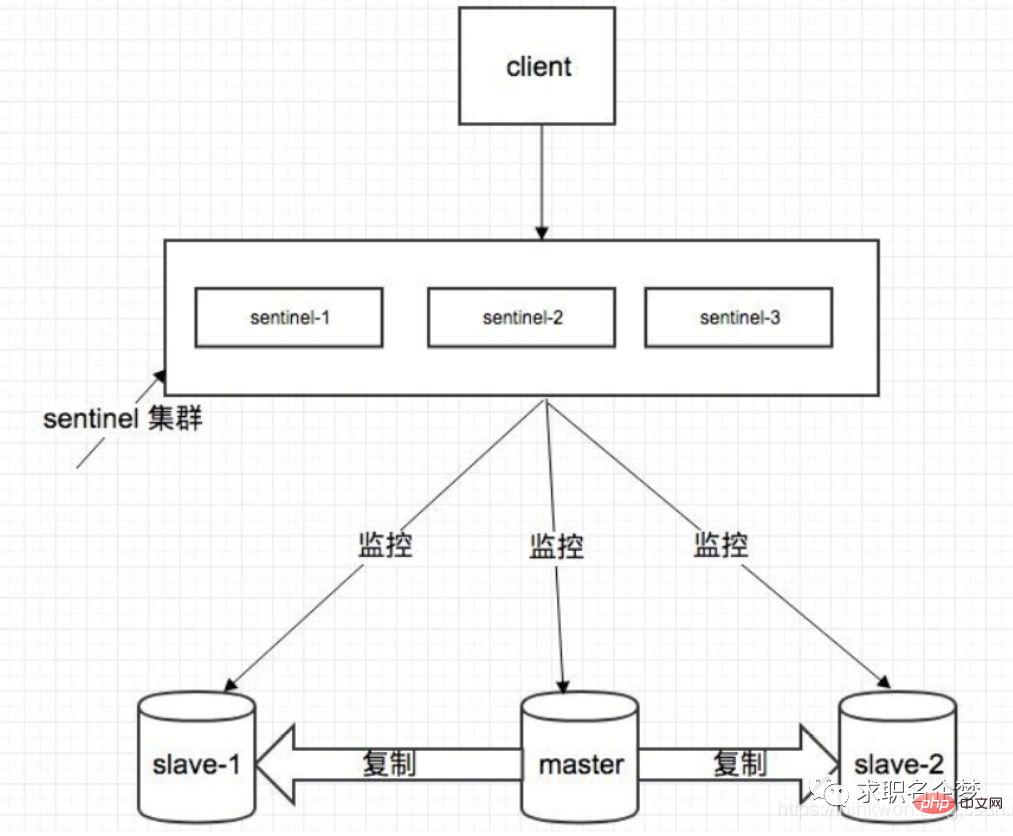
Sentinel モード
##Sentinel の概要 センチネル、中国名はセンチネルです。 Sentinel は Redis クラスター組織において非常に重要なコンポーネントであり、主に次の機能があります:クラスター監視: Redis のマスター プロセスとスレーブ プロセスが正常に動作しているかどうかを監視します。 メッセージ通知: Redis インスタンスに障害が発生した場合、Sentinel はアラーム通知としてメッセージを管理者に送信する責任があります。 フェイルオーバー: マスター ノードがハングすると、自動的にスレーブ ノードに転送されます。 Configuration Center: フェイルオーバーが発生した場合は、クライアントに新しいマスター アドレスを通知します。 Sentinel は、Redis クラスターの高可用性を実現するために使用されます . また、センチネルは分散され、連携して動作するセンチネル クラスターとして実行されます。 1. フェイルオーバー中に、マスター ノードがダウンしているかどうかを判断するには、ほとんどのセンチネルの同意が必要であり、これには分散選出の問題が伴います。 2. 一部のセンチネル ノードがハングアップした場合でも、高可用性メカニズムの重要な部分であるフェイルオーバー システムが単一ポイントである場合、センチネル クラスターは正常に動作することができます。混乱する。sentry の核となる知識 1. Sentinel の堅牢性を確保するには、少なくとも 3 つのインスタンスが必要です。 2. Sentinel redis マスター/スレーブ デプロイ アーキテクチャは、データ損失ゼロを保証するものではなく、redis クラスターの高可用性のみを保証します。 3. Sentinel redis マスター/スレーブの複雑なデプロイメント アーキテクチャについては、テスト環境と本番環境の両方で十分なテストと訓練を実施するようにしてください。 公式 Redis クラスター ソリューション (サーバー側ルーティング クエリ)
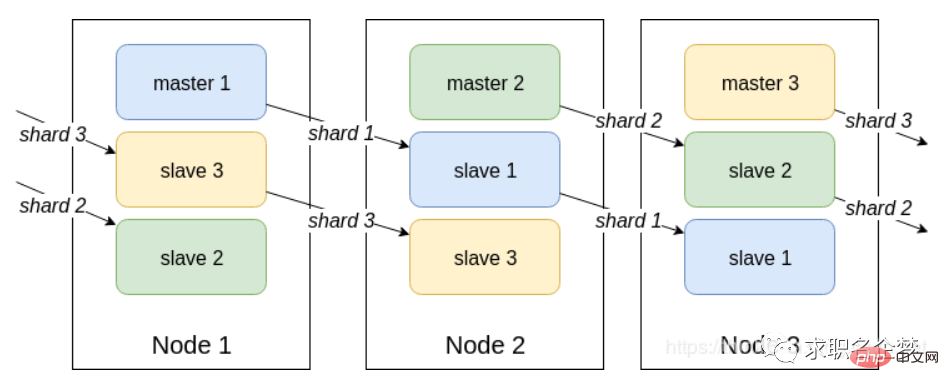
はじめに Redis Cluster はサーバー側のシャーディング テクノロジであり、バージョン 3.0 で正式に利用可能になります。 Redis Cluster は一貫したハッシュを使用せず、合計 16384 個のスロットに分割されるスロットの概念を使用します。リクエストを任意のノードに送信すると、リクエストを受信したノードは実行のために正しいノードにクエリ リクエストを送信しますプログラムの説明 1. ハッシュ化により、データは断片化されており、各ノードは特定のハッシュ スロット (ハッシュ値) 範囲にデータを均等に格納します。デフォルトでは、16384 スロットが割り当てられます 2。各データ フラグメントは、複数のノードに格納されます。相互にマスターとスレーブ#3. データは最初にマスター ノードに書き込まれ、次にスレーブ ノードに同期されます (ブロック同期の構成をサポート) #4. 同じシャード内の複数のノードデータは 5 間の一貫性を維持しません。データを読み取るときに、クライアントによって操作されたキーがノードに割り当てられていない場合、redis は正しいノードを指すようにステアリング命令を返します。 6. 容量を拡張する場合、古いノードのデータの一部を新しいノードに移行する必要があります。Redis クラスター アーキテクチャでは、各 Redis は 2 つのポート番号 (たとえば、1 つは 6379) を開く必要があります。もう 1 つは 16379 などの 1w ポート番号を追加します。 16379 ポート番号はノード間の通信、つまりクラスタバス通信に使用され、障害検出、構成更新、フェイルオーバー認可に使用されます。クラスター バスは、別のバイナリ プロトコルであるgossip プロトコルを使用します。このプロトコルは、ノード間の効率的なデータ交換に使用され、ネットワーク帯域幅と処理時間を削減します。ノード間の内部通信メカニズム 基本的な通信原理クラスターのメタデータを維持するには、集中プロトコルとゴシップ プロトコルの 2 つの方法があります。ゴシップ プロトコルは、Redis クラスター ノード間の通信に使用されます。 分散アドレス指定アルゴリズム ハッシュ アルゴリズム (一括キャッシュ再構築)
2. Sentinel モニタリングと自動フェイルオーバー機能を備えています 3. クライアントクラスター内のすべてのノードに接続します。クラスター内の使用可能なノードに接続するだけです4。高パフォーマンス、クライアントは Redis サービスに直接接続され、プロキシの損失が排除されますデメリット 1. 運用保守も非常に煩雑であり、データ移行も手動で行う必要があります2. データベースNo.0のみ使用可能 3. バッチ操作はサポートされていません (パイプライン パイプライン操作)4、分散ロジックとストレージ モジュールの結合など。クライアント割り当てに基づく## ######### ####導入###### Redis シャーディングは、Redis Cluster が登場する前に業界で一般的に使用されていたマルチ Redis インスタンスのクラスター手法です。主なアイデアは、ハッシュ アルゴリズムを使用して Redis データのキーをハッシュすることであり、ハッシュ関数を通じて、特定のキーが特定の Redis ノードにマッピングされます。 Java Redis クライアントは jedis を駆動し、Redis シャーディング機能、つまり ShardedJedis とキャッシュ プールと組み合わせた ShardedJedisPool をサポートします 利点 利点は、非常にシンプルであることです。サーバーサイド Redis インスタンスは互いに独立しており、相関関係はありません。各 Redis インスタンスは単一のサーバーのように動作し、直線的に拡張するのが非常に簡単です。システムの柔軟性は非常に高いです。 デメリット 1. シャーディング処理をクライアント側に置くため、さらに規模が拡大すると運用保守に課題が生じます。 2. クライアント側のシャーディングは、ノードの動的な追加と削除をサポートしていません。サーバーの Redis インスタンス グループのトポロジが変更されると、各クライアントを更新して調整する必要があります。接続を共有することはできません。アプリケーションの規模が増大した場合、リソースの無駄を制御する最適化 #プロキシ サーバーのシャーディングに基づく
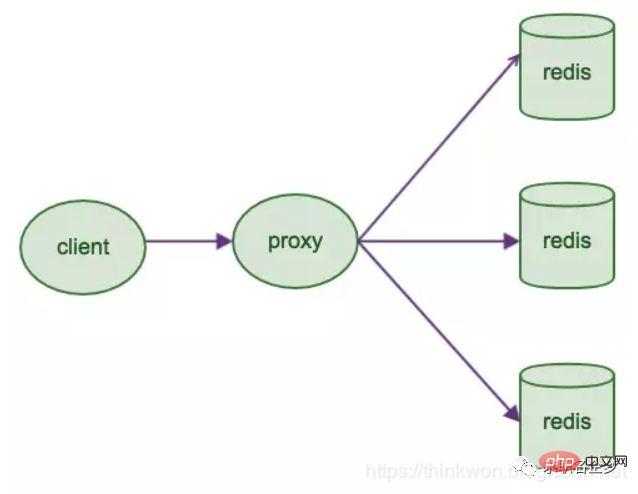
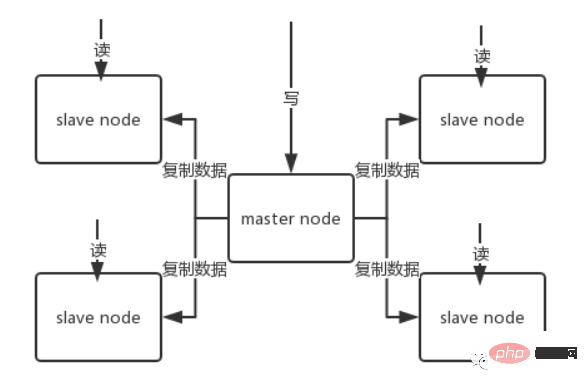
# はじめに#クライアントはプロキシ コンポーネントにリクエストを送信し、プロキシはクライアントのデータを解析し、リクエストを正しいノードに転送し、最後に結果をクライアントに返信します # # 特徴 #1. 透過的なアクセス、ビジネス プログラムはバックエンド Redis インスタンスを気にする必要がなく、スイッチング コストが低い 2. プロキシ ロジックとストレージ ロジックは分離されています3. プロキシ層にはもう 1 つの転送があり、パフォーマンスが低下します業界のオープンソース ソリューション 1. Twtter のオープンソース Twemproxy 2. Wandojia のオープン ソース CodisRedis マスター/スレーブ アーキテクチャ 単一マシンの Redis は、数十から数十の範囲の QPS を伝送できます。数千から数万。キャッシュの場合、通常、高い読み取り同時実行性をサポートするために使用されます。そのため、アーキテクチャは 1 つのマスターと複数のスレーブからなるマスター スレーブ アーキテクチャとなっており、マスターは他のスレーブ ノードへのデータの書き込みとコピーを担当し、スレーブ ノードは読み取りを担当します。すべての読み取りリクエストはスレーブ ノードに送信されます。これにより、水平方向の拡張も簡単に実現でき、高い読み取り同時実行性がサポートされます。
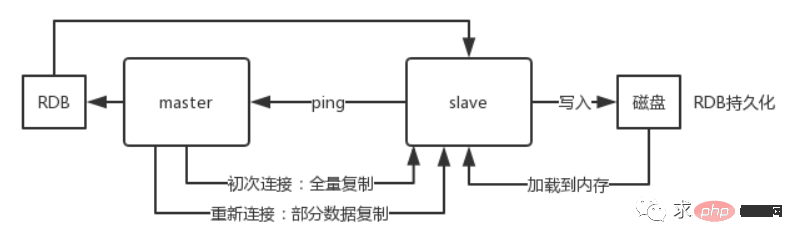
1. Redis はデータをスレーブ ノードに非同期的にレプリケートしますが、redis2.8 以降、スレーブ ノードは毎回レプリケートするデータの量を定期的に確認します。 2. マスター ノードは複数のスレーブ ノードで構成できます; 3. スレーブ ノードは他のスレーブ ノードに接続することもできます; 4. スレーブ ノードが複製する場合, マスター ノードの通常の作業はブロックされません; 5. スレーブ ノードがレプリケートしているとき、それ自体のクエリ操作はブロックされません。古いデータ セットを使用してサービスを提供しますが、レプリケーションが完了しました。場合によっては、古いデータ セットを削除して新しいデータ セットをロードする必要があります。このとき、外部サービスは一時停止されます。 6. スレーブ ノードは主に水平方向の拡張と分離に使用されます拡張されたスレーブ ノードにより、読み取りスループットが向上します。 マスター/スレーブ アーキテクチャを採用する場合、マスター ノードの永続性を有効にする必要があることに注意してください。スレーブ ノードをマスター ノードのデータ ホット バックアップとして使用することは推奨されません。その場合、マスターの永続性をオフにすると、マスターがクラッシュして再起動したときにデータが空になる可能性があり、その後、スレーブ ノードのデータがレプリケートされるとすぐに失われる可能性があるためです。 さらに、マスターのさまざまなバックアップ計画も実行する必要があります。ローカルファイルがすべて失われた場合には、バックアップからRDBを選択してマスターを復元することで、起動時にデータが存在することを保証します 後述する高可用性の仕組みを採用しても、スレーブノードが自動的にマスターを引き継ぐことができますただし、センチネルがマスター障害を検出する前にマスター ノードが自動的に再起動した可能性もあり、それによって上記のスレーブ ノード データがすべてクリアされる可能性もあります。 Redis マスター/スレーブ レプリケーションの中心原則スレーブ ノードが起動すると、PSYNC コマンドがマスター ノードに送信されます。 スレーブ ノードがマスター ノードに初めて接続する場合、完全な再同期フル コピーがトリガーされます。このとき、マスターはバックグラウンド スレッドを開始し、RDB スナップショット ファイルの生成を開始します。 同時に、クライアントから新たに受信したすべての書き込みコマンドがメモリにキャッシュされます。 RDB ファイルが生成された後、マスターは RDB をスレーブに送信します。スレーブはまずそれをローカル ディスクに書き込み、次にローカル ディスクからメモリにロードします。 その後、マスターが RDB を送信します。メモリにキャッシュされた書き込みコマンドをスレーブに送信し、スレーブはこれらのデータも同期します。 スレーブノードとマスターノードの間でネットワーク障害が発生し、接続が切断された場合、自動的に再接続され、接続後、マスターノードは欠落しているデータのみをスレーブにコピーします。 プロセス原則 1. スレーブ データベースとマスター データベースが MS 関係を確立すると、SYNC コマンドがマスター データベースに送信されます 2. マスター データベースは SYNC コマンドを受信した後、スナップショットの保存を開始しますバックグラウンド (RDB 永続化プロセス) で、期間中に受信した書き込みコマンドをキャッシュします。 3. スナップショットが完了すると、マスター Redis はスナップショット ファイルとキャッシュされたすべての書き込みコマンドをスレーブ Redis# に送信します。 ##4. スレーブ Redis 受信後、スナップショット ファイルがロードされ、受信したキャッシュされたコマンドが実行されます5. その後、マスター Redis はコマンドをスレーブ Redis に送信します。データの一貫性を確保するために書き込みコマンドを受け取ります欠点 スレーブ ノード データのレプリケーションと同期はすべてマスター ノードによって処理されるため、マスター ノードに過度の負荷がかかります。Redis クラスターのマスター スレーブ レプリケーション モデルとは何ですか? 一部のノードに障害が発生した場合、またはほとんどのノードが通信できなくなった場合でもクラスターを引き続き使用できるようにするために、クラスターはマスター/スレーブ レプリケーション モデルを使用し、各ノードには N-1 個のレプリカが存在します。製品Redis は運用環境にどのようにデプロイされますか?redis クラスター、10 台のマシン、5 台のマシンは redis マスター インスタンスでデプロイされ、他の 5 台のマシンは redis スレーブ インスタンスでデプロイされます。各マスター インスタンスにはスレーブ インスタンスがあり、5 つのノードが公開されます読み取りおよび書き込みサービスを提供すると、各ノードのピーク読み取りおよび書き込み QPS は 1 秒あたり 50,000 に達し、5 台のマシンの最大読み取りおよび書き込みリクエスト/秒は 250,000 になります。 Redis ハッシュ スロットの概念について話しますか?Redis クラスターは一貫したハッシュを使用しませんが、ハッシュ スロットの概念を導入しています。Redis クラスターには 16384 のハッシュ スロットがあります。各キーは CRC16 検証に合格し、16384 が取得されます。モジュールは決定します。どのスロットを配置するか、クラスター内の各ノードがハッシュ スロットの一部を担当します。 Redis はデータの強力な一貫性を保証しません。つまり、実際には、特定の条件下でクラスターが書き込み操作を失う可能性があります。非同期レプリケーション16384Redis クラスターは現在データベースを選択できず、デフォルトはデータベース 0 です。Redis はシングルスレッドですが、マルチコア CPU の使用率を改善するにはどうすればよいですか? 同じサーバー上に複数の Redis インスタンスをデプロイし、それらを異なるサーバーとして使用できます。いずれにしても 1 つのサーバーでは十分ではないため、複数の CPU を使用したい場合は、シャーディングを検討できます。パーティショニングにより、Redis はより大きなメモリを管理できるようになり、Redis はすべてのマシンのメモリを使用できるようになります。パーティションがないと、最大 1 台のマシンのメモリしか使用できません。パーティショニングを使用すると、コンピュータを追加するだけで Redis のコンピューティング能力を 2 倍にすることができ、コンピュータとネットワーク カードを追加すると Redis のネットワーク帯域幅も飛躍的に増加します。1. クライアントのパーティショニングとは、データをどの Redis ノードに保存するか、またはどの Redis ノードから読み取るかをクライアントが決定することを意味します。ほとんどのクライアントはすでにクライアント側パーティショニングを実装しています。
3. クエリ ルーティング (クエリ ルーティング) とは、クライアントが任意の Redis インスタンスをランダムにリクエストし、Redis がそのリクエストを正しい Redis ノードに転送することを意味します。 Redis Cluster はハイブリッド形式のクエリ ルーティングを実装していますが、ある Redis ノードから別の Redis ノードにリクエストを直接転送するのではなく、クライアントの助けを借りて正しい Redis ノードに直接リダイレクトします。 Redis パーティショニングの欠点は何ですか?1. 複数のキーを含む操作は、通常はサポートされていません。たとえば、2 つのコレクションは異なる Redis インスタンスに保存されている可能性があるため、それらを交差させることはできません (実際には、この状況を解決する方法はありますが、交差コマンドを直接使用することはできません)。 2. 複数のキーを同時に操作した場合、Redis トランザクションは使用できません。 3. パーティション分割の粒度が重要であるため、非常に大きなソート セットのような単一の巨大なキーでデータセットをシャーディングすることはできません) 4. パーティションを使用する場合、データ処理たとえば、バックアップの場合、異なる Redis インスタンスおよびホストから同時に RDB/AOF ファイルを収集する必要があります。 5. パーティショニング中の動的な拡張または縮小は非常に複雑になる場合があります。 Redis クラスターは、実行時に Redis ノードを追加または削除するため、ユーザーに対して最大限透過的なデータのリバランスを実現できますが、他の一部のクライアント パーティショニングまたはプロキシ パーティショニング方法では、この機能がサポートされていません。ただし、この問題をより適切に解決できるプレシャーディング テクノロジもあります。 Redis は分散ロックを実装しますRedis は、単一プロセス、単一スレッド モードであり、キュー モードを使用して同時アクセスをシリアル アクセスに変換し、マルチクライアント Redis への接続に競合はありません。Redis で SETNX コマンドを使用して分散ロックを実装できます。 キーが存在しない場合に限り、キーの値を value に設定します。指定されたキーがすでに存在する場合、SETNX は何も実行しません。 SETNX は、「SET if Not eXists」の略です (存在しない場合は SET)。 戻り値: 設定が成功すると1が返ります。セットアップは失敗し、0 を返します。 SETNX を使用して同期ロックを完了するプロセスと事項は次のとおりです: SETNX コマンドを使用してロックを取得します。0 が返された場合 (キーがすでに存在している場合、ロックはすでに確立されています)存在する場合は取得が失敗し、それ以外の場合は取得が成功します ロック取得後のプログラムで例外が発生し、SETNX コマンドの呼び出し時に他のスレッド/プロセスが常に 0 を返してデッドロック状態になるのを防ぐため、キーには「適切な」有効期限を設定する必要があります ロックを解除し、DEL コマンドを使用してロック データを削除します キーの同時競合の問題を解決する方法Redis の#Redis におけるキーの同時競合の問題は複数あります。システムは同時にキーを操作しますが、最終的な実行順序は実行順序と異なります。期待すると、異なる結果が得られます。 分散 Redis は初期段階で行うべきですか、それとも規模が大きくなった後の段階で行うべきですか?なぜ?Redis は非常に軽量であるため (単一インスタンスで使用するメモリは 1M のみ)、将来の拡張を防ぐ最善の方法は、最初により多くのインスタンスを起動することです。サーバーが 1 台しかない場合でも、パーティションを使用して同じサーバー上で複数のインスタンスを起動することで、最初から Redis を分散方式で実行できます。 RedLock とはRedis 公式 Web サイトでは、Redlock と呼ばれる、Redis に基づいて分散ロックを実装するための権威ある方法が提案されています。単一ノードのアプローチの方が安全です。次の機能を保証できます: キャッシュ例外##キャッシュなだれ #キャッシュ雪崩とは、同じキャッシュのことを指します。 広範囲に障害が発生すると、後続のリクエストがデータベースに落ち、データベースが短期間に大量のリクエストに耐えられなくなり、崩壊します。 解決策 1. キャッシュされたデータの有効期限をランダムに設定して、多数のデータが同時に期限切れになるのを防ぎます。 2. 一般に、同時実行の量が特に大きくない場合、最も一般的に使用される解決策はロック キューイングです。 3. キャッシュされた各データに対応するキャッシュ タグを追加し、キャッシュが無効かどうかを記録します。キャッシュ タグが無効な場合は、データ キャッシュを更新します。 キャッシュ ペネトレーション キャッシュ ペネトレーションとは、キャッシュにもデータベースにも存在しないデータを指し、すべてのリクエストがデータベースに落ちます。 、短期間に大量のリクエストが発生したため、データベースが崩壊します。 解決策 1. ユーザー認証検証、ID の基本検証、ID の直接傍受などの検証をインターフェイス層に追加します 2. キャッシュから取得できないデータはデータベースには取得されませんが、このときキーと値のペアを key-null として記述することもでき、キャッシュの有効期間を短く設定することもできます。 30秒(長すぎると通常は使用できなくなります)。これにより、攻撃ユーザーが同じ ID を繰り返し使用してブルート フォース攻撃を行うことを防ぐことができます。 3. ブルーム フィルターを使用して、すべての可能なデータを十分な大きさのビットマップにハッシュします。存在してはいけないデータはインターセプトされます。このビットマップを使用することで、基盤となるストレージ システムに対するクエリのプレッシャーを回避できます。 追加 スペースの究極の使い方は、ビットマップとブルーム フィルターです。 ビットマップ: 典型的なものはハッシュ テーブルです。 欠点は、ビットマップは各要素に対して 1 ビットの情報しか記録できないことです。追加の関数を完成させたい場合は、 、より多くの空間と時間を犠牲にすることによってのみ達成できるのではないかと思います。 ブルーム フィルター (推奨) k(k>1)k(k>1) の独立したハッシュ関数を導入して、指定された空間と誤判定率の下で、要素の重みを決定するプロセスが完了します。 利点は、スペース効率とクエリ時間が一般的なアルゴリズムよりもはるかに高いことですが、欠点は、一定の誤認識率と削除が難しいことです。 ブルーム フィルター アルゴリズムの中心となるアイデアは、複数の異なるハッシュ関数を使用して「競合」を解決することです。 ハッシュには競合 (衝突) の問題があり、同じハッシュを使用して取得された 2 つの URL の値が同じになる可能性があります。競合を減らすために、さらにいくつかのハッシュを導入することができます。ハッシュ値の 1 つによって要素がセットに含まれていないことが判明した場合、その要素は間違いなくセットに含まれていません。すべてのハッシュ関数が要素がセット内にあることを示す場合にのみ、要素がセット内に存在することを確認できます。これがブルームフィルターの基本的な考え方です。 ブルーム フィルターは通常、大規模なデータ コレクションに要素が存在するかどうかを判断するために使用されます。 キャッシュ ブレークダウン キャッシュ ブレークダウンとは、キャッシュ内にはないがデータベース内にあるデータを指します (通常、キャッシュ時間の期限が切れています)。 , この時、同時接続ユーザーが非常に多いため、リードキャッシュにデータが同時に読み込まれず、同時にデータベースからデータがフェッチされるため、データベースへの負荷が一気に高まり、過度の圧力を引き起こします。キャッシュ雪崩とは異なり、キャッシュ ブレークダウンは同じデータに対する同時クエリを指します。キャッシュ雪崩とは、異なるデータの有効期限が切れ、大量のデータが見つからないため、データベースが検索されることを意味します。 解決策 1. ホットスポット データを無期限に設定します 2. ミューテックス ロック、ミューテックス ロックを追加します キャッシュの予熱 #キャッシュの予熱とは、システムがオンラインになった後に、関連するキャッシュ データをキャッシュ システムに直接ロードすることを意味します。このようにして、最初にデータベースにクエリを実行し、ユーザーが要求したときにデータをキャッシュするという問題を回避できます。ユーザーは、予熱されたキャッシュ データを直接クエリします。解決策 1. キャッシュ更新ページを直接作成し、オンラインになるときに手動で実行します; 2. データ量は問題ありません。大きい場合は、プロジェクトの開始時に自動的にロードすることができます。 3. キャッシュを定期的に更新します。キャッシュのダウングレード 訪問数が増加した場合 サービスの問題 (応答時間が遅い、応答がないなど) が発生した場合、または非コア サービスがコア プロセスのパフォーマンスに影響を与えた場合、サービスが停止している場合でも、サービスが引き続き利用可能であることを確認する必要があります。妥協した。システムは、いくつかの重要なデータに基づいて自動的にダウングレードすることも、手動でダウングレードできるようにスイッチを構成することもできます。 キャッシュ ダウングレードの最終的な目標は、たとえ損失があったとしても、コア サービスが確実に利用できるようにすることです。また、一部のサービスはダウングレードできません (ショッピング カートへの追加、チェックアウトなど)。 ダウングレードする前に、システムが兵士を失い、指揮官を維持できるかどうかを確認する必要があります。これにより、何を死ぬまで守る必要があり、何をダウングレードできるかを分類する必要があります。たとえば、以下を参照できます。ログ レベル設定計画:1. 一般: たとえば、一部のサービスは、ネットワーク ジッターが原因でタイムアウトする場合や、サービスがオンラインであるため、自動的にダウングレードされる可能性があります; 2. 警告:一部のサービスは一定期間内で成功率が変動するため (95 ~ 100% など)、自動的にダウングレードまたは手動でダウングレードし、アラームを送信できます; 3. エラー: たとえば、可用性率は次のとおりです。 90% 未満、データベース接続プールが使い果たされた、またはアクセス数が突然増加した場合、システムが耐えられる最大しきい値に達します。このとき、状況に応じて自動的にダウングレードするか、手動でダウングレードすることができます。 4. 重大なエラー: たとえば、特別な理由によりデータが正しくない場合は、緊急の手動ダウングレードが必要です。 サービスのダウングレードの目的は、Redis サービスの障害によってデータベースに雪崩の問題が発生するのを防ぐことです。したがって、重要でないキャッシュされたデータについては、サービスのダウングレード戦略を採用できます。たとえば、Redis に問題がある場合、データベースにクエリを実行する代わりに、デフォルト値をユーザーに直接返すという一般的なアプローチがあります。 ホット データとコールド データ ホット データ、キャッシュは貴重です コールド データの場合、ほとんどのデータには、再度アクセスされる前にメモリから搾り取られてしまうため、メモリを占有するだけでなく、ほとんど価値がありません。頻繁に変更されるデータの場合は、状況に応じてキャッシュの使用を検討してください。 当社の IM 製品、誕生日の挨拶モジュール、その日の誕生日リストなどのホット データの場合、キャッシュは数十万回読み取られる可能性があります。回。別の例として、ナビゲーション製品では、ナビゲーション情報をキャッシュし、将来的にそれを何百万回も読み取る可能性があります。 キャッシュは、更新前にデータが少なくとも 2 回読み取られる場合にのみ意味を持ちます。これは最も基本的な戦略ですが、キャッシュが有効になる前に失敗すると、あまり意味がありません。 キャッシュが存在せず、変更の頻度が非常に高いが、キャッシュを考慮する必要があるシナリオはどうでしょうか?持っている!たとえば、この読み取りインターフェイスはデータベースに多大な負荷をかけますが、ホット データでもあります。このとき、いいね数、コレクション数、アシスタント製品の 1 つの共有。これは非常に一般的なホット データですが、変化し続けます。現時点では、データベースへの負荷を軽減するために、データを Redis キャッシュに同期的に保存する必要があります。 キャッシュ ホットスポット キー キャッシュ内のキー (プロモーション製品など) が特定の時点で期限切れになると、次のようなことが起こります。この時点では、このキーに対する同時リクエストが多数あります。これらのリクエストは、キャッシュの有効期限が切れていることを検出すると、通常、バックエンド DB からデータをロードし、キャッシュにリセットします。この時点では、大同時リクエストによりバックエンド DB が瞬時に圧倒される可能性があります。 解決策 キャッシュ クエリをロックします。KEY が存在しない場合はロックし、DB をキャッシュにチェックインしてロックを解除します。他のプロセスが存在する場合は、ロックを解除します。ロックがあることを確認します。待って、ロックを解除した後、データを返すか、DB クエリを入力します。 共通ツール##Java とはRedis でサポートされているクライアント?公式で推奨されているのはどれですか? Redis と Redisson の関係は何ですか? Redisson は、ユーザーが分散環境、ConcurrentMap、List で一部の Java オブジェクト (ブルーム フィルター、BitSet、Set、SetMultimap、ScoredSortedSet、SortedSet、Map) を簡単に実装できるようにする高度な分散調整 Redis クライアントです。 、ListMultimap、Queue、BlockingQueue、Deque、BlockingDeque、セマフォ、Lock、ReadWriteLock、AtomicLong、CountDownLatch、パブリッシュ/サブスクライブ、HyperLogLog)。ジェディスとレディソンの長所と短所は何ですか? Jedis は、Java の Redis によって実装されたクライアントです。その API は、Redis コマンドに対する比較的包括的なサポートを提供します。Redisson は、分散型でスケーラブルな Java データ構造を実装します。Jedis と比較して、その機能は比較的シンプルです。文字列操作はサポートされておらず、並べ替え、トランザクション、パイプライン、パーティションなどの Redis 機能もサポートされていません。 Redisson の目的は、ユーザーの懸念事項を Redis から分離して、ユーザーがビジネス ロジックの処理に集中できるようにすることです。その他の質問##Redis と Memcached の違い
(2) redis は memcached よりもはるかに高速です (3) redis はデータを永続化できます キャッシュ データの一貫性を確保する方法データベースの二重書き込み?キャッシュを使用する限り、ストレージの二重化、キャッシュとデータベースの二重書き込みが発生する可能性があります。二重書き込みを使用している限り、データの一貫性の問題が確実に発生します。一貫性の問題?? 一般的に、システムがキャッシュ データベースの一貫性を厳密に要求していない場合、キャッシュはデータベースとわずかに不一致になることがあります。この解決策は実行しないことをお勧めします。読み取りリクエスト文字列と書き込みリクエスト文字列のシリアル化 シリアル化後は、システムのスループットが大幅に低下し、使用量が通常の状態よりも大幅に低下します。 . オンライン リクエストをサポートするには、数倍のマシンをダウンロードします。 もう 1 つの方法は、一時的な不整合が発生する可能性がありますが、発生の可能性は非常に低いということです。つまり、 最初にデータベースを更新してから、キャッシュを削除します。
|
以上がRedis の高頻度インタビューの質問 (回答分析付き)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。