
ホームページ >バックエンド開発 >Python チュートリアル >Python は Weibo のホット検索のクロールと Mysql への保存を実現します
Python は Weibo のホット検索のクロールと Mysql への保存を実現します

- coldplay.xixi転載
- 2021-01-27 17:45:132406ブラウズ

無料学習の推奨事項: Python ビデオ チュートリアル
Python クロール マイクロ Boresou Mysql に保存されます
- 最終効果
- 使用ライブラリ
- ターゲット分析
- 1: データの取得
- 2: データベースへのリンク
- 合計コード
最終的な効果
#あまり多くありませんナンセンスです。画像にアクセスしてください。
# ここでは、データベースに日付、コンテンツ、Web サイトのリンクが含まれていることがはっきりとわかります。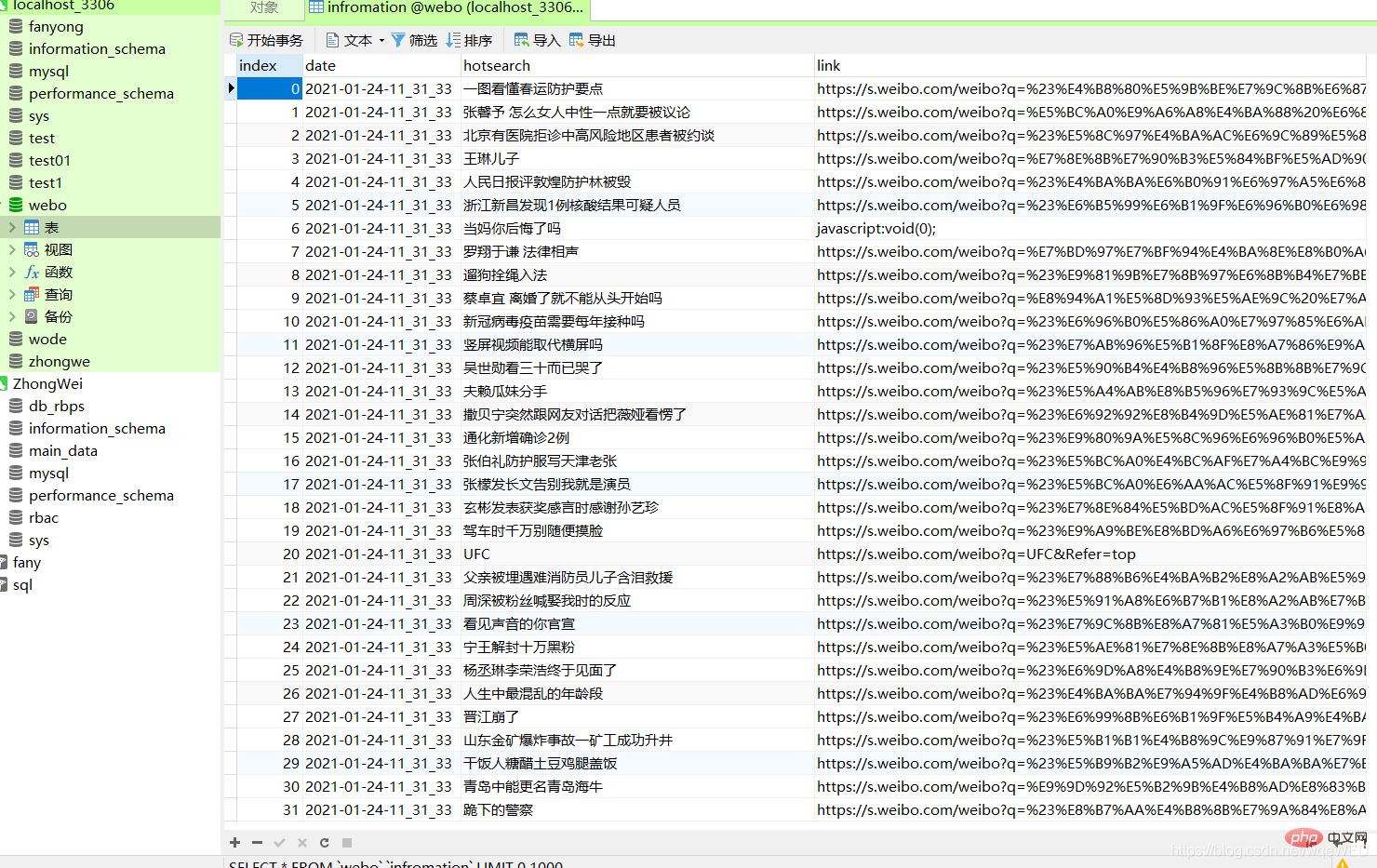 実装方法を分析しましょう
実装方法を分析しましょう
import requests
from selenium.webdriver import Chrome, ChromeOptions
import time
from sqlalchemy import create_engine
import pandas as pd
これは Weibo でよく検索されているリンクです: クリックしてターゲット Web ページに移動します
まず、Selenium を使用してターゲット Web ページをリクエストします。 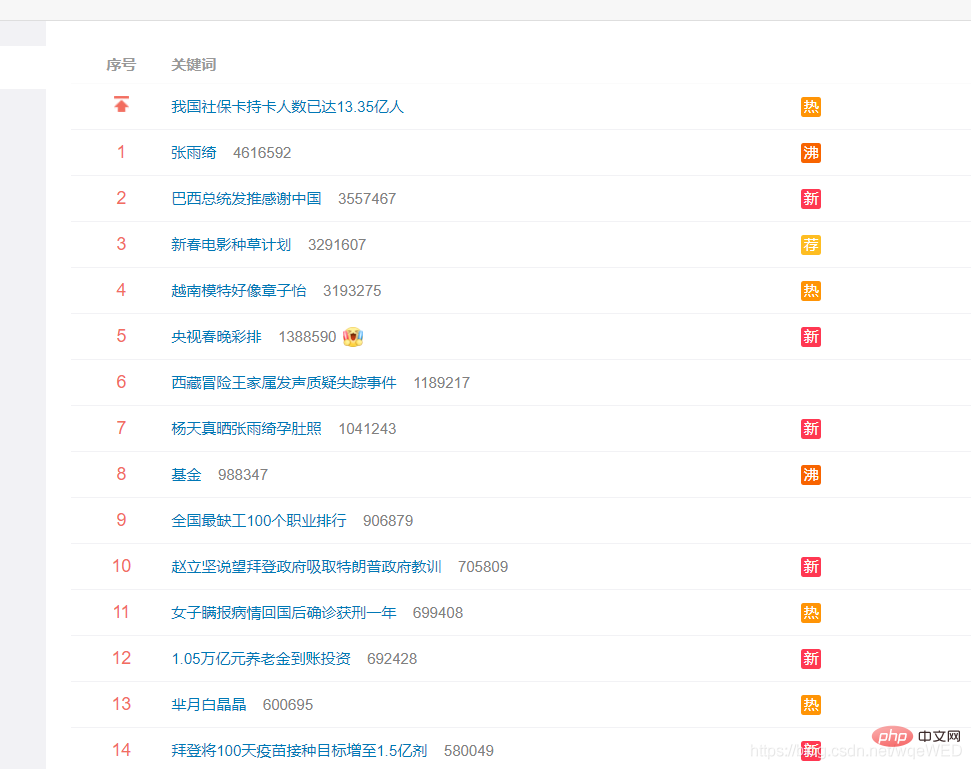 次に、xpath を使用して Web ページ要素を見つけ、トラバースしてすべてのデータを取得します。
次に、xpath を使用して Web ページ要素を見つけ、トラバースしてすべてのデータを取得します。
次に、pandas を使用して Dataframe オブジェクトを生成し、データベースに直接保存します。
xpath を使用して 51 個のデータを取得できることがわかります。これらはホット検索であり、そこからリンクとタイトルの内容を取得できます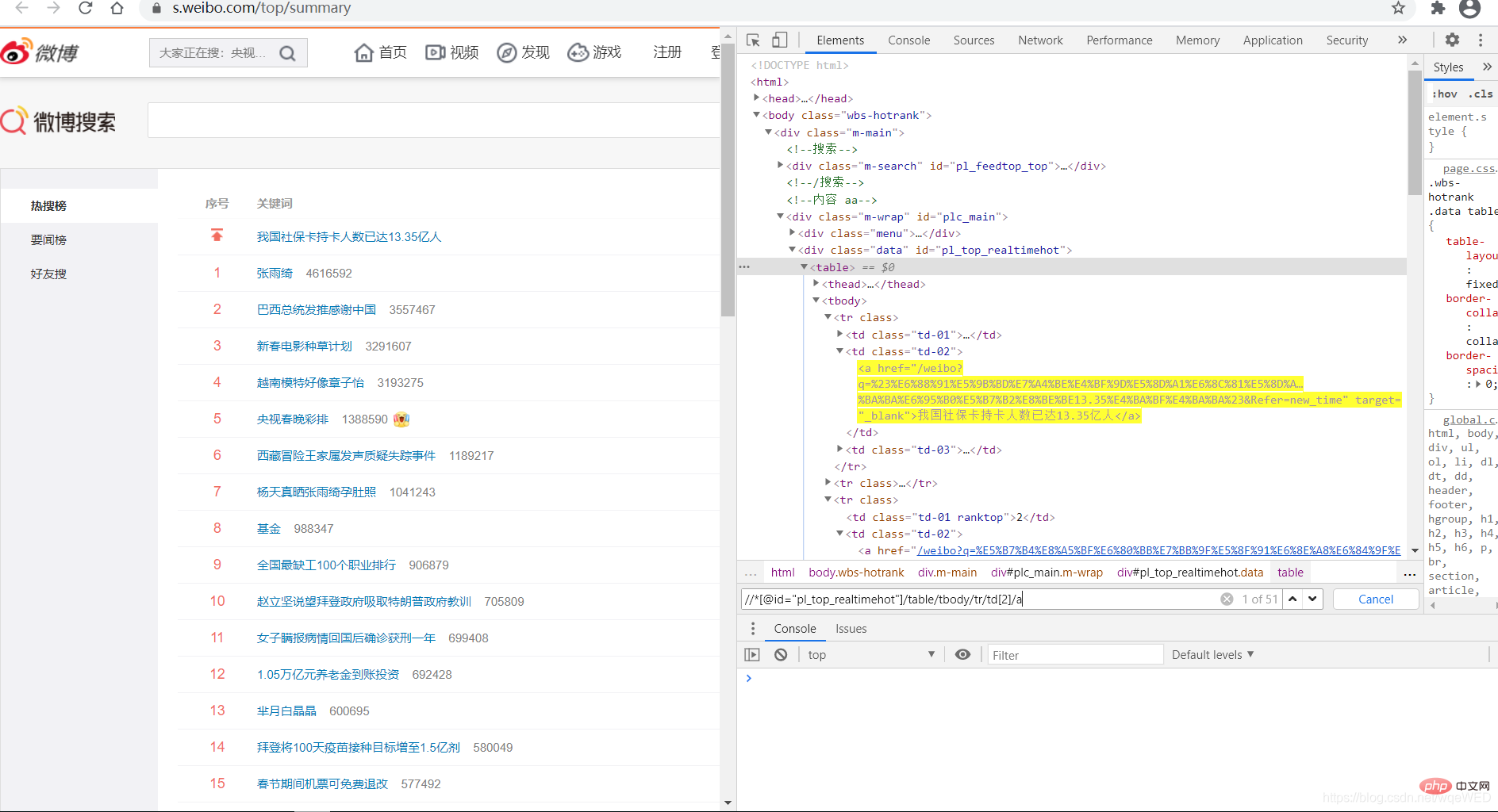
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') #得到所有数据
context = [i.text for i in c] # 得到标题内容
links = [i.get_attribute('href') for i in c] # 得到link
次に、zip 関数を使用して日付、コンテキスト、リンクをマージします zip 関数は、複数のリストを 1 つのリストに結合し、リスト内のデータを 1 つにマージします。インデックスによるタプル。これにより pandas オブジェクトが生成されます。
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
日付は時間モジュールを使用して取得できます2: データベースへのリンク
これは非常に簡単です
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
合計コードfrom selenium.webdriver import Chrome, ChromeOptions
import time
from sqlalchemy import create_engine
import pandas as pd
def get_data():
url = r"https://s.weibo.com/top/summary" # 微博的地址
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
browser = Chrome(options=option)
browser.get(url)
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a')
context = [i.text for i in all]
links = [i.get_attribute('href') for i in all]
date = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime())
dates = []
for i in range(len(context)):
dates.append(date)
# print(len(dates),len(context),dates,context)
dc = zip(dates, context, links)
pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
# pdf.to_sql(name=in, con=enging, if_exists="append")
return pdf
def w_mysql(pdf):
try:
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
except:
print('出错了')
if __name__ == '__main__':
xx = get_data()
w_mysql(xx) 少しでもお役に立てれば幸いです。一緒に進歩し、成長していきましょう!
関連する無料学習の推奨事項:Python チュートリアル(ビデオ)
以上がPython は Weibo のホット検索のクロールと Mysql への保存を実現しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。