
ホームページ >データベース >mysql チュートリアル >Mysql で SQL を書くための 21 の良い習慣を身につける
Mysql で SQL を書くための 21 の良い習慣を身につける

- coldplay.xixi転載
- 2020-11-02 17:41:242045ブラウズ
mysql ビデオ チュートリアル コラムでは、SQL を書くための良い習慣を紹介します。

まえがき
すべての良い習慣は財産です この記事は、SQL 後悔の薬、SQL パフォーマンスの最適化、および SQL 仕様の優雅さの 3 つの方向に分かれています。 SQL の 21 の良い習慣を共有して作成します。読んでいただきありがとうございます。これからも頑張ってください~
1. SQL を作成した後、実行計画を説明して表示します (SQL パフォーマンスの最適化)
日常生活で SQL を開発および作成するときは、できる限り SQL を作成するようにしてください。これは良い習慣です。SQL を作成した後は、インデックスが使用されているかどうかに特に注意しながら、Explain を使用して SQL を分析します。
explain select * from user where userid =10086 or age =18;复制代码

2. delete または update ステートメントを操作して制限を追加する (SQL 後悔の薬)
delete または update ステートメントを実行するときに、追加してみてください次のような制限 次の SQL を例に挙げます。
delete from euser where age > 30 limit 200;复制代码
制限を追加すると、次のような主な利点があるためです。
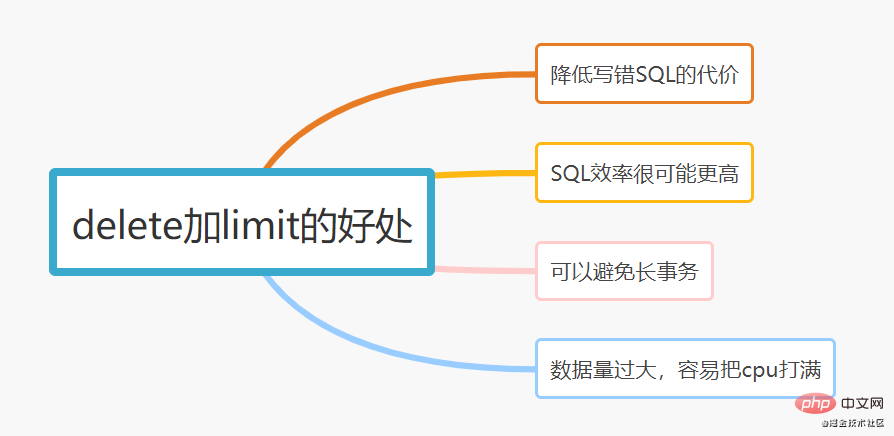
- 間違った SQL を記述するリスクを軽減します。コストは です。この SQL をコマンド ラインで実行すると、制限を追加しなかった場合、実行中に 手が誤って震えた場合、すべてのデータが失われます。削除される可能性があります。削除が間違っている場合? 200 という制限を追加すると違いが生じます。データを誤って削除した場合でも、失われるのは 200 個のデータだけであり、binlog ログを通じてすぐに復元できます。
- SQL 効率はより高くなる可能性があります 。制限 1 を SQL 行に追加します。最初の行がターゲットの戻り値に達した場合、制限がない場合、スキャン テーブルは引き続き実行されます。処刑される。
- 長いトランザクションを避ける.削除が実行されるとき、age がインデックスされている場合、MySQL は関連するすべての行に書き込みロックとギャップ ロックを追加し、実行関連のすべての行がロックされます。削除の数が多いと、関連サービスに直接影響し、利用できなくなります。
- データ量が多い場合、CPU が満杯になりやすいです 大量のデータを削除する場合は、レコード数を制限する制限を追加せず、 CPU がいっぱいになりやすく、削除がさらに多くなります。
肯定的な例:
CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';复制代码
反例:
CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `balance` int(11) DEFAULT NULL, `create_time` datetime NOT NULL , `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8;复制代码4. SQL 記述形式、キーワード サイズの一貫性を保つ、インデントを使用します。 (SQL の仕様は洗練されています) 肯定的な例:
SELECT stu.name, sum(stu.score) FROM Student stu WHERE stu.classNo = '1班' GROUP BY stu.name复制代码反例:
SELECT stu.name, sum(stu.score) from Student stu WHERE stu.classNo = '1班' group by stu.name.复制代码明らかに、キーワードを同じ大文字と小文字で統一し、インデント配置を使用すると、SQL の見栄えが良くなります。よりエレガントに見えます~5. INSERT ステートメントは、対応するフィールド名を示します (SQL 仕様はエレガントです)反例:
insert into Student values ('666','捡田螺的小男孩','100');复制代码正の例:
insert into Student(student_id,name,score) values ('666','捡田螺的小男孩','100');复制代码 6 . SQL 操作を変更して最初にテスト環境で実行し、詳細な操作手順とロールバック計画を書き留めて、本番環境に移行する前にレビューします。 (SQL 後悔の薬)
- SQL 操作を変更し、本番環境に導入する前に文法エラーを回避するために、まずテスト環境でテストします。
- SQL 操作を変更するには、特に依存関係がある場合、最初にテーブル構造を変更してから対応するデータを補足するなど、詳細な手順が必要です。
- SQL 操作の変更にはロールバック プランがあり、本番環境に移行する前に対応する SQL の変更を確認してください。
CREATE TABLE `account` ( `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';复制代码正の例:
CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';复制代码理由:
- 主キーを追加する必要があります。主キーがないテーブルにソウル
- 作成時刻と更新時刻がない場合は、追加することをお勧めします。詳細な監査と追跡記録はすべて役に立ちます。

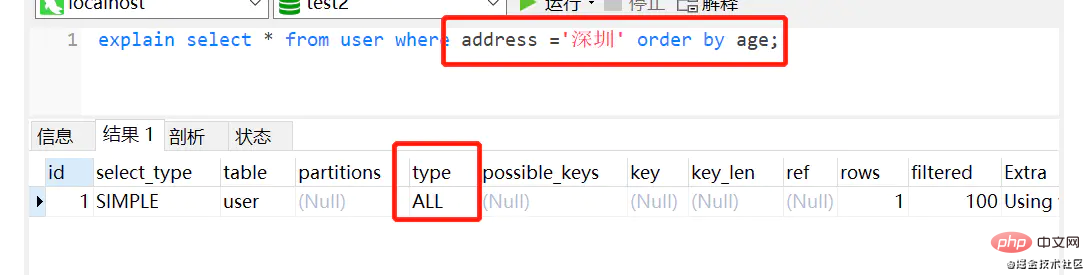
select * from user where address ='深圳' order by age ;复制代码
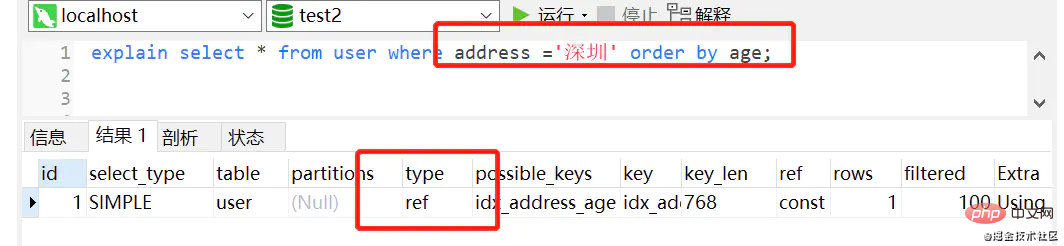
添加索引 alter table user add index idx_address_age (address,age)复制代码
後悔の薬を一口飲むこともできます~
10. where后面的字段,留意其数据类型的隐式转换(SQL性能优化)
反例:
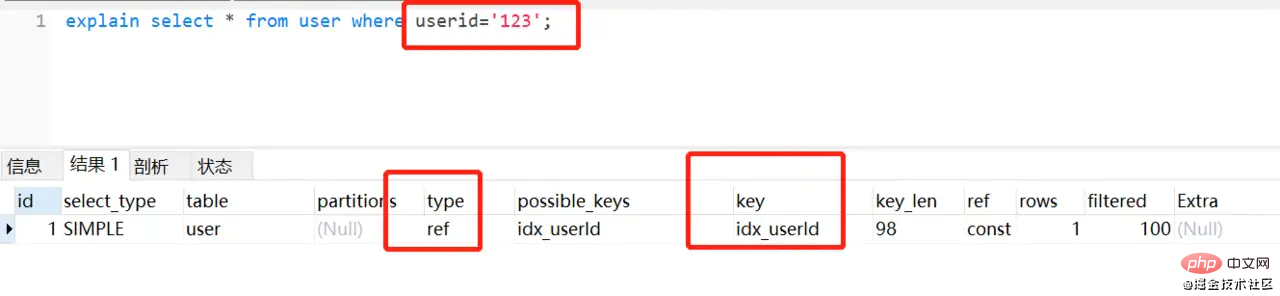
//userid 是varchar字符串类型 select * from user where userid =123;复制代码

正例:
select * from user where userid ='123';复制代码
理由:
- 因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较,最后导致索引失效
11. 尽量把所有列定义为NOT NULL(SQL规范优雅)
- NOT NULL列更节省空间,NULL列需要一个额外字节作为判断是否为 NULL 的标志位。
- NULL列需要注意空指针问题,NULL列在计算和比较的时候,需要注意空指针问题。
12.修改或者删除SQL,先写WHERE查一下,确认后再补充 delete 或 update(SQL后悔药)
尤其在操作生产的数据时,遇到修改或者删除的SQL,先加个where查询一下,确认OK之后,再执行update或者delete操作
13.减少不必要的字段返回,如使用select <具体字段> 代替 select * (SQL性能优化)
反例:
select * from employee;复制代码
正例:
select id,name from employee;复制代码
理由:
- 节省资源、减少网络开销。
- 可能用到覆盖索引,减少回表,提高查询效率。
14.所有表必须使用Innodb存储引擎(SQL规范优雅)
Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好,所以呢,没有特殊要求(即Innodb无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用Innodb存储引擎
15.数据库和表的字符集统一使用UTF8(SQL规范优雅)
统一使用UTF8编码
- 可以避免乱码问题
- 可以避免,不同字符集比较转换,导致的索引失效问题
如果是存储表情的,可以考虑 utf8mb4
16. 尽量使用varchar代替 char。(SQL性能优化)
反例:
`deptName` char(100) DEFAULT NULL COMMENT '部门名称'复制代码
正例:
`deptName` varchar(100) DEFAULT NULL COMMENT '部门名称'复制代码
理由:
- 因为首先变长字段存储空间小,可以节省存储空间。
- 其次对于查询来说,在一个相对较小的字段内搜索,效率更高。
17. 如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。 (SQL规范优雅)
这个点,是阿里开发手册中,Mysql的规约。你的字段,尤其是表示枚举状态时,如果含义被修改了,或者状态追加时,为了后面更好维护,需要即时更新字段的注释。
18. SQL修改数据,养成begin + commit 事务的习惯;(SQL后悔药)
正例:
begin; update account set balance =1000000 where name ='捡田螺的小男孩'; commit;复制代码
反例:
update account set balance =1000000 where name ='捡田螺的小男孩';复制代码
19. 索引命名要规范,主键索引名为 pk_ 字段名;唯一索引名为 uk _字段名 ; 普通索引名则为 idx _字段名。(SQL规范优雅)
说明: pk_ 即 primary key;uk _ 即 unique key;idx _ 即 index 的简称。
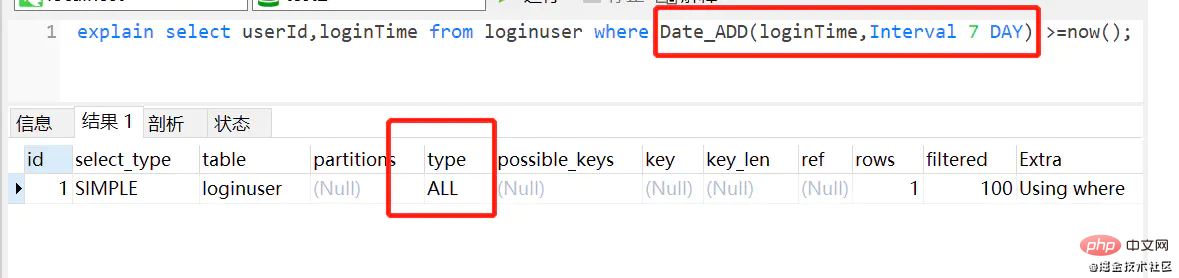
20. WHERE从句中不对列进行函数转换和表达式计算
假设loginTime加了索引
反例:
select userId,loginTime from loginuser where Date_ADD(loginTime,Interval 7 DAY) >=now();复制代码
正例:
explain select userId,loginTime from loginuser where loginTime >= Date_ADD(NOW(),INTERVAL - 7 DAY);复制代码
理由:
- 索引列上使用mysql的内置函数,索引失效
21.如果修改\更新数据过多,考虑批量进行。
反例:
delete from account limit 100000;复制代码
正例:
for each(200次)
{
delete from account limit 500;
}复制代码
理由:
- 大批量操作会会造成主从延迟。
- 大批量操作会产生大事务,阻塞。
- 大批量操作,数据量过大,会把cpu打满。
参考与感谢
- delete后加 limit是个好习惯么
- 《阿里开发手册》
相关免费学习推荐:mysql视频教程
以上がMysql で SQL を書くための 21 の良い習慣を身につけるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。