AIxivコラムは、本サイト上で学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
上海交通大学の生成人工知能研究室 (GAIR Lab) の研究チームは、主な研究の方向性として、大規模モデルのトレーニング、アライメント、および評価。チームのホームページ: https://plms.ai/
今後 20 年で、AI は人間の知能を超えると予想されています。チューリング賞受賞者のヒントン氏はインタビューの中で、「今後20年でAIは人間の知能のレベルを超えると予想される」と述べ、大手テクノロジー企業が大規模モデル(マルチモーダルを含む)の「効率」を評価するための準備を早期に行うよう示唆した。大型モデル) この準備には「知能レベル」が必要な前提条件となります。
AI を多次元から厳密に評価できる、学際的な問題セットを備えた認知的推論能力評価ベンチマークが非常に急務となっています。
1. 大きなモデルは、小学校のテスト問題から大学入試まで、人間の知能の高い地位を占め続けています
大きなモデルを核とした生成人工知能技術の台頭により、人間はインタラクティブなテキストと画像しかありませんが、ビデオインタラクティブ生成ツールは、人間に「知性」機能を備えたモデルをトレーニングする機会も与えます。人間の拡張された脳とみなすことができ、さまざまな分野の問題を独立して完了し、次のようなことができるモデルになります。今後 10 年間で科学的発見を加速します。 の最も強力なツール (つまり AI4Science)。 過去 2 年間で、私たちは大きなモデルで表されるこの種のシリコンベースのインテリジェンスの急速な進化を目の当たりにしてきました。当初から、これは 2022 年までに小学校の問題を解決するためにしか使用できませんでした。 al. [1] が1位を獲得 初めて「大学入試」の試験場にAIが持ち込まれ、全国論文Ⅱ英語で134点を獲得したが、当時はまだAIであった。数学的論理をよく理解していない部分的な科目の生徒。 2024年度大学入学試験がいよいよ終了。多くの学生が長年の学習の成果を発揮して試験に臨む中、試験会場には今年初めて大型模型も導入されました。すべての分野で、数学と科学で大きな進歩を遂げます。ここで私たちは、AI 知能の進化の天井はどこにあるのか、考えずにはいられません。人間はまだ最も難しい問題を解決できていないが、それがAIの限界となるのだろうか?

2. 知的競争の最高峰:AI大学入学試験からAIオリンピックまで これはスポーツ競技の最高峰のイベントであるだけではありません。人類が極限を追求し続けることの象徴でもあります。主題オリンピックは、知識の深さと知性の限界を完璧に組み合わせたものであり、学業成績を厳格に評価するだけでなく、思考の機敏性と革新能力に対する究極の挑戦でもあります。ここでは、科学の厳密さとオリンピックの情熱が出会い、卓越性の追求と探求する勇気の精神を共同で形成します。
主題のオリンピックは、人間と機械の知性の間の頂上対決に最適な場を提供します。将来 AGI が実現できるかどうかに関係なく、オリンピックへの AI の参加は、AGI への途中で必要な立ち寄りとなるでしょう。オリンピックへの参加は、モデルの非常に重要な認知推論能力を検査するものであり、これらの能力はさまざまな複雑な現実世界に徐々に反映されつつあるからです。たとえば、シナリオでは、AI エージェントがソフトウェア開発に使用され、複雑な意思決定プロセスを協力して処理し、さらには科学研究分野 (AI4Science) を促進します。
 これに関連して、上海交通大学の生成人工知能研究室 (GAIR Lab) の研究チームは、大学入試試験室から大型モデルを移動させました。より挑戦的な「オリンピックアリーナ」は、新しい大規模モデル(マルチモーダル大規模モデルを含む)の認知推論能力評価ベンチマーク-OlympicArenaを開始しました。このベンチマークは、国際教科オリンピックの難しい問題を使用して、学際的な分野における人工知能の認知推論能力を包括的にテストします。オリンピックアリーナは、数学、物理学、化学、生物学、地理学、天文学、コンピューターサイエンスの 7 つの主要科目をカバーしており、これには 62 の国際科目オリンピック (IMO、IPhO、IChO、IBO、ICPC など) からの中国語と英語のバイリンガル問題 11,163 問が含まれます。 .)、研究者にAIモデルの総合評価に最適なプラットフォームを提供します。 同時に、長期的には、AIが将来科学(AI4サイエンス)や工学(AI4エンジニアリング)の分野でその強力な能力を発揮するために、オリンピックアリーナは無視できない役割を果たすことになるでしょう。人間のレベルを超えた超知性を刺激するためにAIを促進することさえあります。
これに関連して、上海交通大学の生成人工知能研究室 (GAIR Lab) の研究チームは、大学入試試験室から大型モデルを移動させました。より挑戦的な「オリンピックアリーナ」は、新しい大規模モデル(マルチモーダル大規模モデルを含む)の認知推論能力評価ベンチマーク-OlympicArenaを開始しました。このベンチマークは、国際教科オリンピックの難しい問題を使用して、学際的な分野における人工知能の認知推論能力を包括的にテストします。オリンピックアリーナは、数学、物理学、化学、生物学、地理学、天文学、コンピューターサイエンスの 7 つの主要科目をカバーしており、これには 62 の国際科目オリンピック (IMO、IPhO、IChO、IBO、ICPC など) からの中国語と英語のバイリンガル問題 11,163 問が含まれます。 .)、研究者にAIモデルの総合評価に最適なプラットフォームを提供します。 同時に、長期的には、AIが将来科学(AI4サイエンス)や工学(AI4エンジニアリング)の分野でその強力な能力を発揮するために、オリンピックアリーナは無視できない役割を果たすことになるでしょう。人間のレベルを超えた超知性を刺激するためにAIを促進することさえあります。

研究チームは、現在のすべての大型モデルでは、GPT-4o でさえ 39% の精度しかなく、GPT-4V でも 33% しかなく、トップには程遠いことが分かりました。合格ライン(正答率60%)はまだまだ遠い。ほとんどのオープンソースの大規模モデルのパフォーマンスはさらに不十分で、たとえば、LLaVa-NeXT-34B、InternVL-Chat-V1.5 などの現在の強力なマルチモーダル大規模モデルは、精度率 20% に達していません。 。 さらに、ほとんどのマルチモーダル大規模モデルは、複雑な推論タスクを解決するために視覚情報を最大限に活用することが苦手です。これは、大規模モデルと人間の最も重要な違いでもあります (人間は視覚情報の処理を優先する傾向があります)。 )。したがって、OlympicArena でのテスト結果は、このモデルが科学的問題の解決において人間よりもまだ遅れをとっており、人間の科学研究をより良く支援するためにその固有の推論能力を継続的に改善する必要があることを示しています。 
- 論文アドレス: https://arxiv.org/pdf/2406.12753
- プロジェクトアドレス: https://gair-nlp.github.io/OlympicArena/
- コードアドレス: https ://github.com/GAIR-NLP/OlympicArena
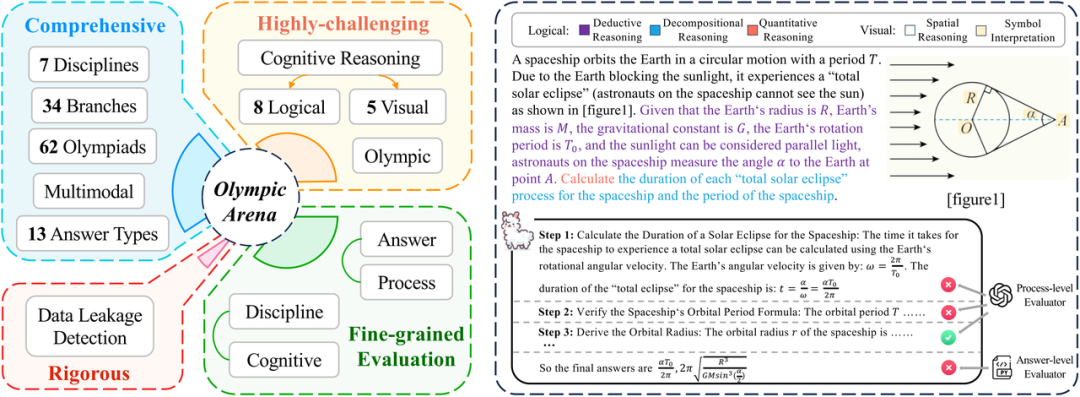
OlympicArena の機能は、マルチモーダルなサポート、複数の認知能力検査、および詳細な評価 (両方を考慮) の概要を示しています。善悪の評価、推論の各段階の評価)。
- 総合:OlympicArena には、62 の異なるオリンピック競技会からの合計 11,163 問が含まれており、数学、物理学、化学、生物学、地理学、天文学、コンピューターの 7 つの主要科目にまたがり、34 の専門分野が関与しています。同時に、多肢選択問題などの客観的な問題に主に焦点を当てていた以前のベンチマークとは異なり、OlympicArena は、式、方程式、区間、化学方程式の記述、さらにはプログラミングの問題など、さまざまな種類の質問をサポートしています。さらに、OlympicArena はマルチモダリティ (質問のほぼ半分に画像が含まれています) をサポートし、現実と最も一致する入力形式 (テキストと画像が交互に挿入された) を採用し、大規模なモデルがタスクを完了するのを支援する視覚情報の使用を完全にテストしています。 . 推論する能力。
- 非常に挑戦的: 高校 (大学入学試験) の問題や大学の問題に焦点を当てた以前のベンチマークとは異なり、OlympicArena は、大規模なモデルの膨大な知識ではなく、複雑な推論能力の純粋な試験に重点を置いています。 、想起能力または単純な応用能力。したがって、OlympicArena のすべての問題はオリンピックの難易度レベルになります。さらに、さまざまな種類の推論能力における大規模モデルのパフォーマンスを詳細に評価するために、研究チームは、8種類の論理推論能力と5種類の視覚推論能力もまとめました。その後、既存の大規模モデルのパフォーマンスを具体的に分析しました。推論能力の異なるタイプのモデル。推論能力のパフォーマンスの違い。
- 厳密さ: 大規模モデルの健全な開発を指導することは、学術界が果たすべき役割です。現在、公開ベンチマークでは、多くの人気のある大規模モデルでデータ漏洩の問題が発生します (つまり、ベンチマークのテスト データが漏洩します)。大規模モデル) トレーニング データ内)。したがって、研究チームは、ベンチマークの有効性をより厳密に検証するために、いくつかの人気のある大規模モデルでOlympicArenaのデータ漏洩を特別にテストしました。
- 粒度の細かい評価: 以前のベンチマークは、大規模なモデルによって与えられた最終的な答えが正しい答えと一致するかどうかのみを評価することが多く、これは非常に複雑な推論問題の評価においては一方的であり、現在のモデルを十分に反映することができません。 . より現実的な推論スキル。そこで研究チームは、回答の評価に加えて、質問のプロセス(ステップ)の正しさの評価も含めました。同時に、研究チームは、異なる分野、異なるモダリティ、異なる推論能力におけるモデルのパフォーマンスの違いを分析するなど、複数の異なる側面から異なる結果を分析しました。
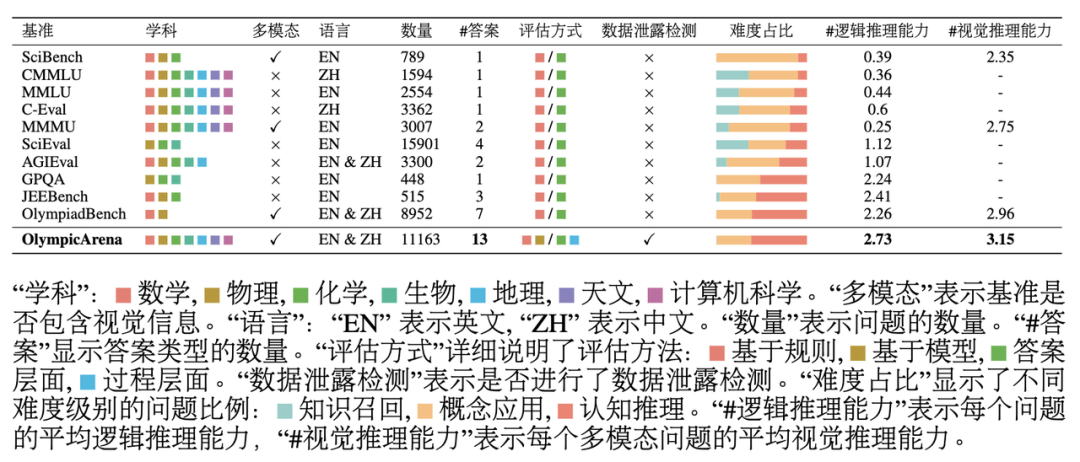
上の表からわかるように、OlympicArena は、主題、言語、モダリティの範囲の点で推論能力に大きな影響を与えます。質問の種類の多様性は、調査の深さと評価方法の包括性が、科学的問題の評価に焦点を当てた他の既存のベンチマークとは大きく異なります。 研究チームは、OlympicArenaで複数のマルチモーダルラージモデル(LMM)とプレーンテキストラージモデル(LLM)をテストしました。マルチモーダル大規模モデルの場合は、インターリーブされたテキスト画像の入力形式が使用され、大規模プレーン テキスト モデルの場合は、画像情報を含まないプレーン テキスト入力 (テキストのみの LLM) とプレーン テキストの 2 つの設定でテストが実行されました。画像説明情報 (画像キャプション + LLM) を含むテキスト入力。プレーン テキストの大規模モデル テストを追加する目的は、このベンチマークの適用範囲を拡大すること (すべての LLM がランキングに参加できるようにするため) だけでなく、既存のマルチモーダル大規模モデルのパフォーマンスをより深く理解し、分析することでもあります。対応する大規模な純粋なテキストモデルと比較して、画像情報を最大限に活用して問題解決能力を向上できるかどうか。すべての実験ではゼロショット CoT プロンプトを使用しました。研究チームはこれを回答タイプごとにカスタマイズし、回答の抽出とルールベースのマッチングを容易にするために出力形式を指定しました。 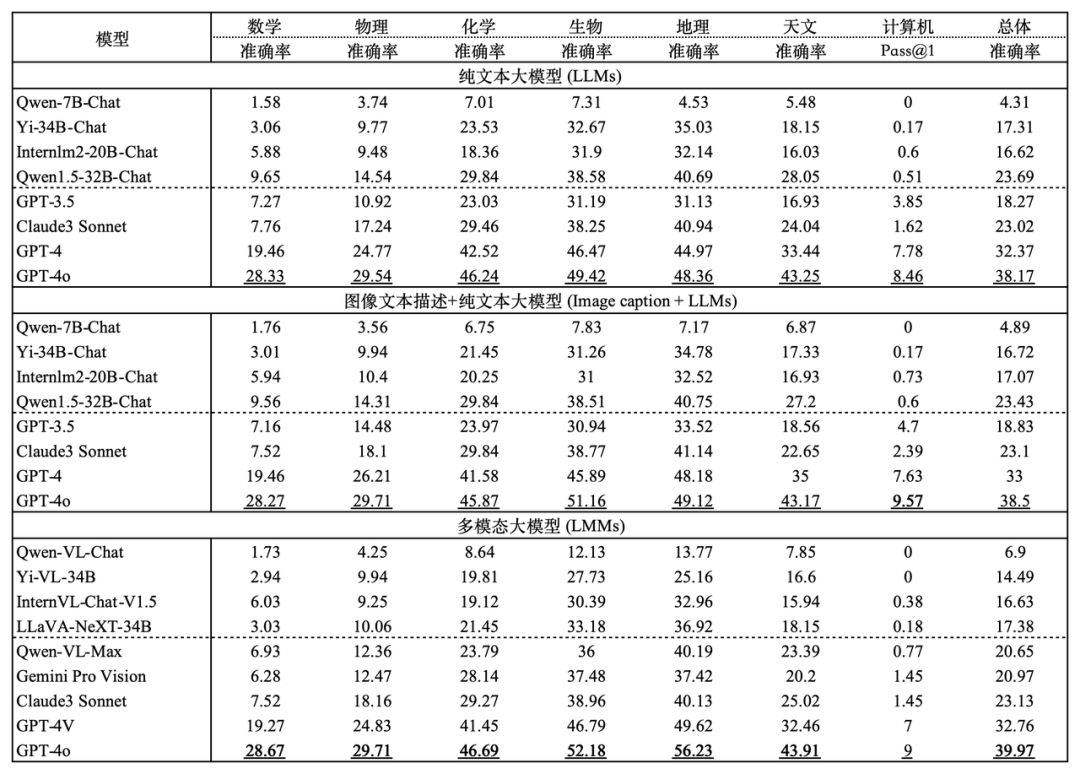
OlympicArena のさまざまな主題におけるさまざまなモデルの精度は、不偏の pass@k インデックスを使用し、残りは精度インデックスを使用します。
表の実験結果から、現在市場にあるすべての主流の大型モデルでは、最も先進的な大型モデルである GPT-4o でさえ、全体の精度が 39.97% にすぎないことがわかります。オープンソース モデルの全体的な精度は 20% に達するのが困難です。この明らかな違いは、このベンチマークの課題を浮き彫りにし、現在の AI 推論能力の上限を押し上げる上で大きな役割を果たしていることを証明しています。
さらに、研究チームは、数学と物理学が、複雑かつ柔軟な推論能力により依存し、推論のステップが多く、より包括的で応用的な思考スキルを必要とするため、数学と物理学が依然として最も難しい科目であることを観察しました。多様な。生物学や地理学などの科目では、複雑な科目と比較して、豊富な科学的知識を活用して実践的な問題を解決、分析する能力、つまり、アブダクションや因果推論の能力の試験に重点が置かれているため、正解率が比較的高くなります。帰納法、演繹的推論、大規模なモデルは、独自のトレーニング段階で獲得した豊富な知識を活用して、そのような主題を分析することにさらに熟達しています。
コンピューター プログラミング コンテストも、問題をまったく解決できない (精度 0) オープンソース モデルもあり、非常に難しいことが証明されています。これは、現在のモデルが解決するための効果的なアルゴリズムを設計する能力を示しています。プログラム上の複雑な問題には、まだ改善の余地がたくさんあります。
OlympicArena の本来の目的は、問題の難しさを盲目的に追求することではなく、大規模なモデルの能力を最大限に活用して分野を横断し、複数の推論機能を使用して実際の科学的問題を解決することであったことは言及する価値があります。前述した複雑な推論を用いた思考力、豊富な科学知識を活用して現実的な問題を解決・分析する能力、問題を解決するための効率的かつ正確なプログラムを作成する能力は、いずれも科学研究の分野において不可欠であり、常に重要視されてきました。このベンチマークのベンチマーク。
実験結果のより詳細な分析を達成するために、研究チームは、さまざまなモダリティと推論能力に基づいてさらなる評価を実施しました。さらに研究チームは、質問に対するモデルの推論プロセスの評価と分析も実施しました。主な発見は次のとおりです。 論理的推論能力と視覚的推論能力が異なると、モデルのパフォーマンスも異なります。論理的推論能力には、演繹的推論(DED)、帰納的推論(IND)、アブダクティブ推論(ABD)、類推的推論(ANA)、因果的推論(CAE)、批判的思考(CT)、分解推論(DEC)および定量的推論(クア)。視覚的推論能力には、パターン認識 (PR)、空間的推論 (SPA)、図的推論 (DIA)、記号解釈 (SYB)、および視覚的比較 (COM) が含まれます。
ほぼすべてのモデルは、さまざまな論理推論機能において同様のパフォーマンス傾向を持っています。彼らはアブダクティブな推論と因果関係に優れており、提供された情報から因果関係を特定することができます。対照的に、モデルは帰納的推論と分解推論ではあまりパフォーマンスが良くありません。これは、オリンピック レベルの問題の多様性と非日常的な性質によるもので、複雑な問題をより小さなサブ問題に分解する能力が必要であり、各サブ問題を適切に解決し、サブ問題を組み合わせて問題を解決するモデルに依存しています。より大きな問題を解決します。視覚的推論機能の点では、このモデルはパターン認識と視覚的比較においてより優れたパフォーマンスを発揮しました。
しかし、空間的および幾何学的推論を含むタスクや、抽象的なシンボルの理解を必要とするタスクを実行するのは困難です。さまざまな推論能力の詳細な分析から、大規模モデルに欠けている能力(複雑な問題の分解、幾何学的図形の視覚的推論など)は、科学研究において不可欠かつ重要な能力であり、まだ長い時間がかかることを示しています。 AI が人間の科学研究をあらゆる面で真に支援できるようになるには、まだまだ時間がかかります。 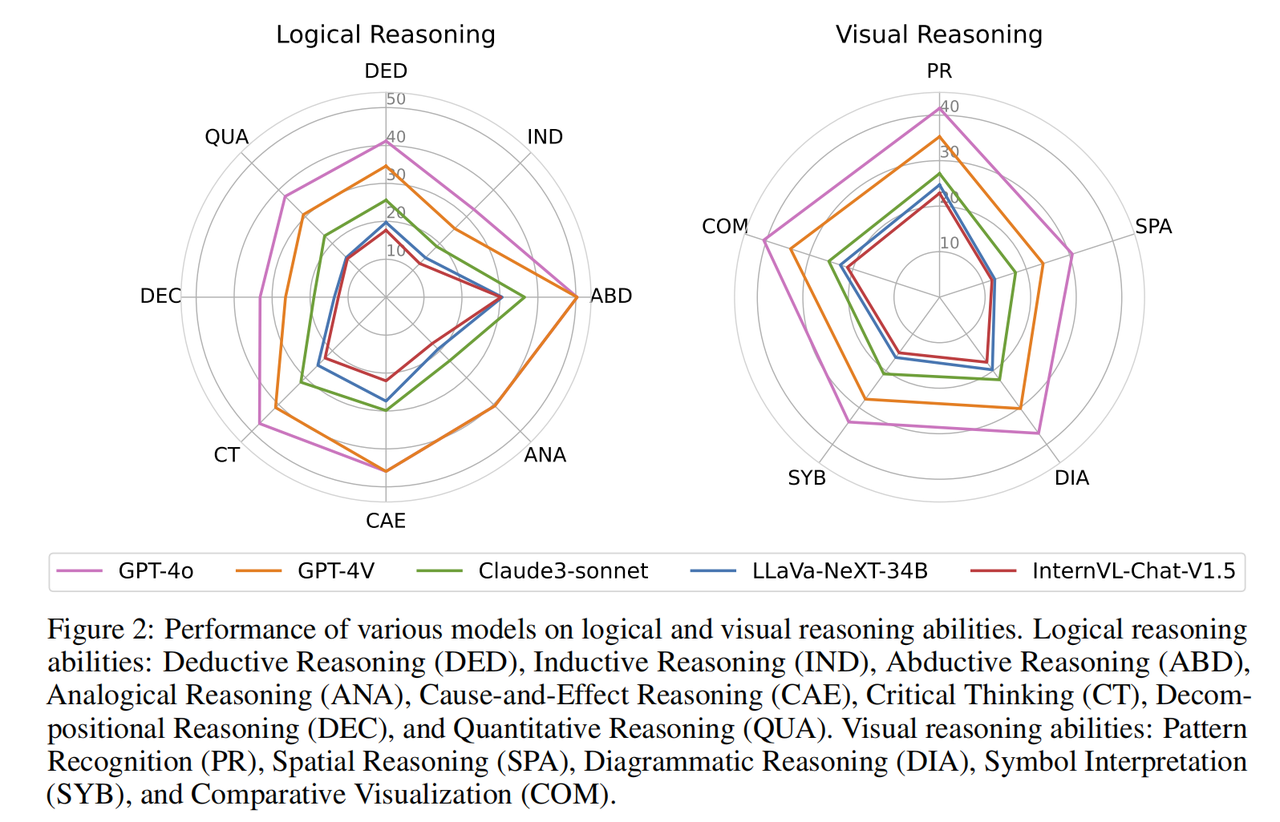
3 つの異なる実験設定における、さまざまなマルチモーダル モデル (LMM) とそれに対応するテキスト専用モデル (LLM) の比較。
ほとんどのマルチモーダル モデル (LMM) は、推論を支援するために視覚情報を利用するのがまだ苦手です上記 (a) に示すように、大規模なマルチモーダル モデル (GPT など) は少数しかありません。 -4o および Qwen-VL -Chat) は、画像入力が与えられた場合に、テキストのみの対応物と比較して大幅なパフォーマンスの向上を示します。大規模なマルチモーダル モデルの多くは、画像入力時にパフォーマンスの向上が見られず、さらには画像処理時にパフォーマンスの低下が見られます。考えられる理由は次のとおりです:
- テキストと画像が一緒に入力される場合、LMM はテキストにより注意を払い、画像内の情報を無視する可能性があります。
- 一部の LMM は、テキスト モデルに基づいて視覚機能をトレーニングするときに、固有の言語機能 (推論機能など) の一部を失う可能性があります。これは、このプロジェクトの複雑なシナリオでは特に顕著です。
- このベンチマーク質問では、複雑なテキスト画像ラッピング入力形式を使用しているため、一部のモデルではこの形式を十分にサポートできず、テキストに埋め込まれた画像の位置情報を処理および理解できません。
科学研究では、多くの場合、チャート、幾何学的図形、視覚データなどの非常に大量の視覚情報が伴います。AI が推論を支援するためにその視覚機能を巧みに使用できる場合にのみ、研究の推進に役立ちます。科学研究の効率と革新は、複雑な科学的問題を解決するための強力なツールとなっています。 
左の図: 推論プロセスが評価されるすべての質問におけるすべてのモデルの回答の正しさとプロセスの正しさの相関関係。右: 誤ったプロセスステップの位置の分布。
モデル推論ステップの正しさの詳細な評価を実施することにより、研究チームは次のことを発見しました:
- 図に示すように( b) 上記、ステップレベルの評価 回答のみに依存する評価の結果と評価の間には、通常、高度な一致が見られます。モデルが正しい答えを生成すると、推論プロセスの品質がほぼ向上します。
- 推論プロセスの精度は、通常、単に答えを見る精度よりも高くなります。これは、非常に複雑な問題であっても、モデルがいくつかの中間ステップを正しく実行できることを示しています。したがって、モデルには認知推論において大きな可能性があり、研究者にとって新たな研究の方向性が開かれる可能性があります。研究チームはまた、一部の分野では、回答のみに基づいて評価された場合に良好なパフォーマンスを示した一部のモデルが、推論プロセスではパフォーマンスが低下したことも発見しました。研究チームは、これは、最終結果にとって重要ではない場合でも、モデルが答えを生成する際に中間ステップの妥当性を無視することがあるためであると推測しています。
- さらに、研究チームはエラーステップの位置分布の統計分析を実施し(図cを参照)、質問の後半の推論ステップでより高い割合のエラーが発生することを発見しました。これは、推論プロセスが蓄積するにつれて、モデルがエラーを起こしやすくなり、エラーの蓄積を生成することを示しています。これは、長鎖の論理推論を扱う場合、モデルにはまだ改善の余地が多くあることを示しています。
チームはまた、すべての研究者に対し、AI推論タスクにおけるモデル推論プロセスの監督と評価にもっと注意を払うよう呼び掛けています。これにより、AI システムの信頼性と透明性が向上し、モデルの推論パスをより深く理解できるだけでなく、複雑な推論におけるモデルの弱点を特定し、それによってモデルの構造とトレーニング方法の改善を導くことができます。注意深くプロセスを監視することで、AI の可能性をさらに探究し、科学研究や実用化における AI の広範な使用を促進できます。 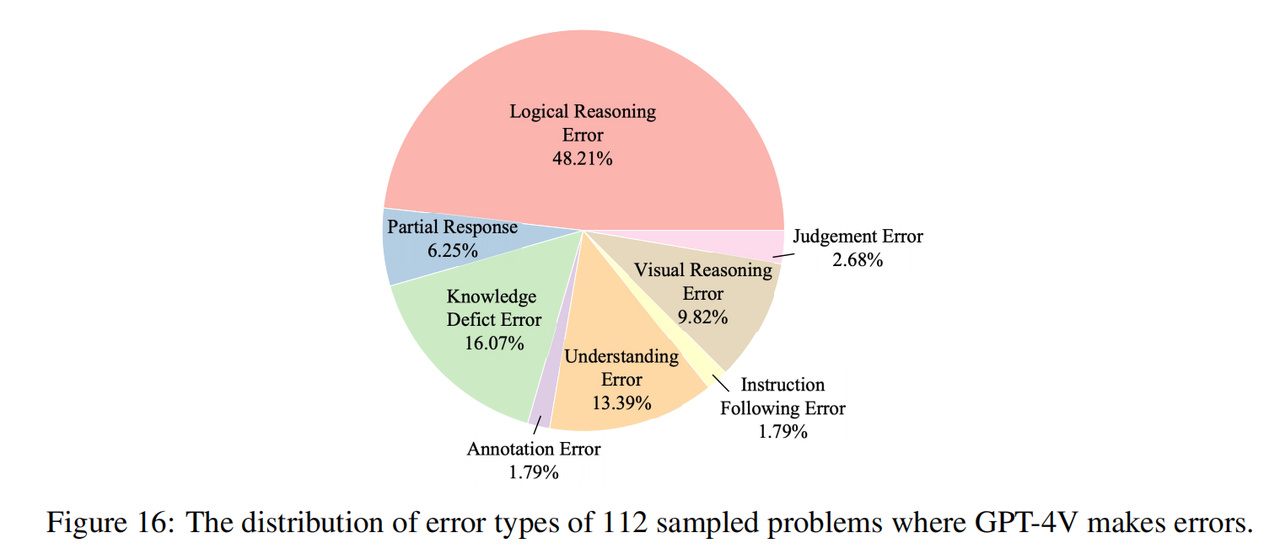
研究チームは、GPT-4V で間違った回答のある 112 の質問 (各科目に 16 の質問、そのうち 8 つは純粋なテキストの質問、8 つはマルチモーダルの質問) をサンプリングし、これらのエラーの理由を手動でマークしました。上の図に示すように、推論エラー (論理的推論エラーと視覚的推論エラーを含む) がエラーの最大の原因を構成しています。これは、ベンチマークが認知的推論機能における現在のモデルの欠点を効果的に強調していることを示しており、これは当初の意図と一致しています。の研究チームの。 さらに、エラーのかなりの部分は知識不足からも生じており (ただし、オリンピックの問題は高校の知識にのみ基づいています)、現在のモデルには専門分野の知識が不足しており、活用できないことがわかります。この知識は推論を支援します。エラーのもう 1 つの一般的な原因は理解バイアスです。これは、モデルによるコンテキストの誤解と、複雑な言語構造とマルチモーダルな情報の統合の難しさに起因すると考えられます。 
数学オリンピックの問題で GPT-4V が間違いを犯した例
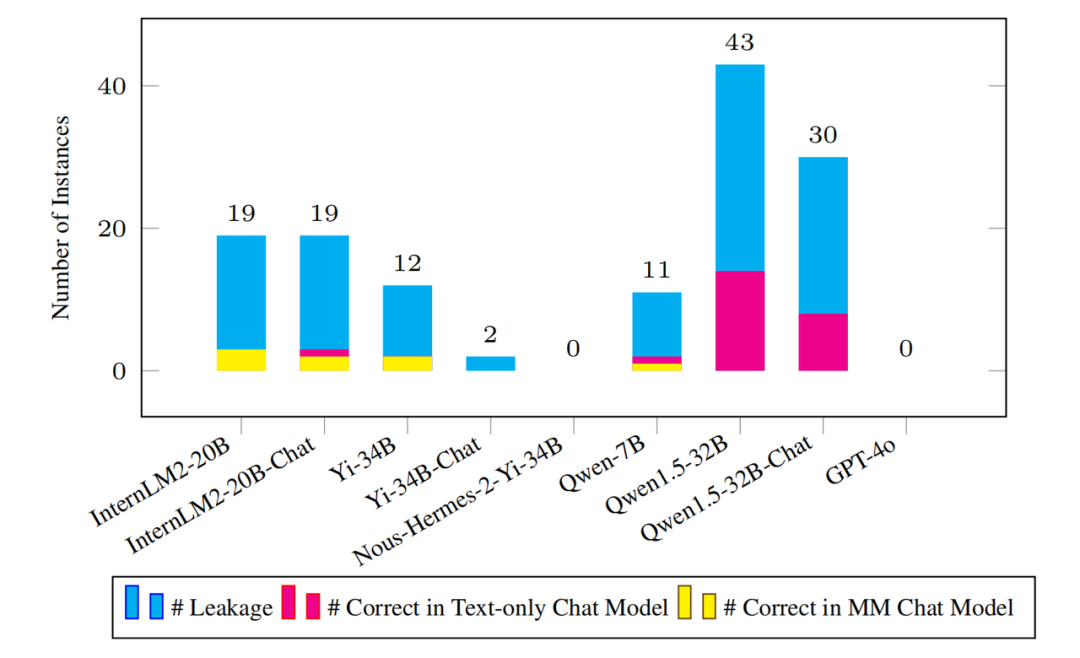
検出された漏洩サンプルの数と、これらのサンプル問題に対応するプレーンテキストおよびマルチモーダルモデル適切な量を作りましょう。
事前トレーニング コーパスの規模が拡大し続けるにつれて、ベンチマークで潜在的なデータ漏洩を検出することが重要になります。事前トレーニング プロセスの不透明性により、このタスクは多くの場合困難になります。この目的を達成するために、研究チームは、新しく提案された「Nグラム予測精度」と呼ばれるインスタンスレベルのリーク検出指標を採用しました。このメトリクスは、各インスタンスからいくつかの開始点を均等にサンプリングし、各開始点の次の N グラムを予測し、予測されたすべての N グラムが正しいかどうかを確認して、モデルがこのインスタンス中にその N グラムに遭遇したかどうかを判断します。研究チームは、この指標を利用可能なすべての基本モデルに適用しました。 上の図に示されているように、主流モデルにはオリンピック アリーナで重大なデータ漏洩の問題はありません。たとえ漏洩があったとしても、その量は完全なベンチマーク データ セットと比較すると微々たるものです。たとえば、最も多くのリークが発生した Qwen1.5-32B モデルでは、リークの疑いのあるインスタンスが 43 件しか検出されませんでした。これは当然のことながら、「モデルはこれらのリークされたインスタンスの質問に正しく答えることができるでしょうか?」という疑問を生じます。 この問題に関して、研究チームは、漏洩した質問であっても、対応するモデルが正しく回答できる質問はほとんどないことに驚きました。これらの結果はすべて、ベンチマークがデータ侵害による影響をほとんど受けておらず、今後長期間にわたってその有効性を維持することが依然として非常に困難であることを示しています。 
OlympicArenaの価値は非常に高いものの、研究チームは、将来的にはやるべきことがまだたくさんあると述べました。まず、OlympicArena ベンチマークにはノイズの多いデータが必然的に導入されますが、著者はコミュニティからのフィードバックを積極的に活用して継続的に改善していきます。さらに、研究チームは、データ侵害に関連する問題をさらに軽減するために、ベンチマークの新しいバージョンを毎年リリースする予定です。さらに、長期的には、現在のベンチマークは複雑な問題を解決するモデルの能力を評価することに限定されています。 将来的には、人工知能が複雑で包括的なタスクの完了を支援し、AI4サイエンスやAI4エンジニアリングなどの実用的なアプリケーションで価値を実証できるようになることを誰もが期待しており、これが将来のベンチマーク設計の目標と目的になります。それにもかかわらず、オリンピック アリーナは、AI の超知能化を促進する触媒として依然として重要な役割を果たしています。 
ビジョン: 人間と AI の共同進歩の輝かしい瞬間
将来、AI テクノロジーが成熟し続け、応用シナリオが拡大し続けるにつれて、OlympicArena は単なる会場以上のものになると信じる理由があります。 AIの能力を評価する「AI」は、さまざまな分野でのAIの応用可能性を実証するステージとなります。科学研究、工学設計、あるいはスポーツ競技などの幅広い分野において、AI は独自の方法で人類社会の発展に貢献します。 最後に、研究チームはまた、主題のオリンピックはオリンピックアリーナの始まりに過ぎず、AIのさらなる機能は継続的に探求される価値がある、例えばオリンピックのスポーツアリーナは身体化された知性のアリーナになるだろうと述べた。将来。 [1] reStructured Pretraining, arXiv 2022, Weizhe Yuan, Pengfei Liu以上が大学入学試験からオリンピック競技場まで: 大型模型と人間の知性の究極の戦いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


