
ホームページ >テクノロジー周辺機器 >AI >LLM | 元 2.0-M32: アテンション ルーティングを備えたエキスパート混合モデル
LLM | 元 2.0-M32: アテンション ルーティングを備えたエキスパート混合モデル

- PHPzオリジナル
- 2024-06-07 09:06:30696ブラウズ
 写真
写真
1. 前に書いた結論
Yuan+2.0-M32 は、Yuan-2.0+2B と同様に、32 人の専門家を含む専門家ハイブリッド アーキテクチャを使用するインフラストラクチャです。これらの専門家のうち 2 名が活動中です。 32 人のエキスパートを含むエキスパート ハイブリッド アーキテクチャが提案され、採用され、従来のルーティング ネットワークを使用したモデルと比較して精度が 3.8% 向上しました。 Yuan+2.0-M32 は、2000B トークンを使用して最初からトレーニングされ、そのトレーニング消費量は、同じパラメーター サイズの高密度アンサンブル モデルのわずか 9.25% です。専門家をより適切に選択するために、迅速に感知する機能を備えたアテンション ルーターが導入され、専門家のより適切な選択が可能になります。
Yuan 2.0-M32 は、コーディング、数学、および複数の専門分野で競争力のある能力を実証しており、合計 400 億のパラメーターのうち 37 億のアクティブなパラメーターのみを使用し、トークンあたり 7.4 GFlops の順計算を行っています。これら 2 つのすべての指標はわずか 1/ です。ラマ3-70Bの19。 Yuan 2.0-M32 は、MATH ベンチマークと ARC-Challenge ベンチマークで Llama3-70B を上回り、精度はそれぞれ 55.89% と 95.8% に達しました。 Yuan 2.0-M32 のモデルとソース コードは GitHub: https://github.com/IEIT-Yuan/Yuan2.0-M32 にあります。
2. 論文の簡単な紹介
2.1 論文の背景
各トークンの計算量が固定の場合、専門家混合 (MoE) 構造を使用したモデルは次のようになります。エキスパートの数を増やすことで構築が容易になり、密集したセットモデルよりも大規模になり、より高い精度のパフォーマンスが得られます。実際、限られたコンピューティング リソースでモデルをトレーニングする場合、MoE はモデル、データセット サイズ、限られたコンピューティング能力に関連するコストを削減する優れたオプションとみなされます。
MoE (Mixture of Experts) の概念は 1991 年に遡ります。損失総額は、独立した判断を下す能力を持つ各専門家からの加重損失を組み合わせたものです。スパースリーゲート MoE の概念は、もともと Shazeer et al (2017) によって翻訳モデルで提案されました。このルーティング戦略を使用すると、質問を提起するときにすべての専門家が同時に呼び出されるのではなく、少数の専門家のみがアクティブになります。このスパース性により、計算効率の損失を最小限に抑えながら、スタックされた LSTM 層間でモデルを最大 1000 倍にスケールアップできます。ノイズ調整可能な Top-K ゲート ルーティングは、ネットワークからソフトマックス関数に調整可能なノイズを導入し、K 値を維持してエキスパートの使用率のバランスをとります。近年、モデル規模の継続的な拡大に伴い、コンピューティングリソースを効率的に割り当てるためのルーティング戦略がより注目されています。
エキスパート ルーティング ネットワークは MoE 構造の中核です。この構造は、各エキスパートへのトークン割り当ての確率を計算することによって、計算に参加する候補エキスパートを選択します。現在、最も一般的な MoE 構造では、トークンと各エキスパートの特徴ベクトルの間の内積を実行し、最大の内積を持つエキスパートを勝者として選択する古典的なルーティング アルゴリズムが一般的に採用されています。この選択では、専門家の特徴ベクトルは独立しており、専門家間の相関は無視されます。ただし、MoE の構造では通常、一度に複数の専門家が選択され、異なる専門家の特性間に相関関係が存在する可能性があります。したがって、この場合、選択された特徴ベクトルには、計算に関与する各専門家間の内積の重複や競合が含まれる可能性があり、結果の精度に影響を与えます。ただし、MoE 構造では通常、一度に複数のエキスパートが選択され、異なるエキスパートの特徴間に相関関係が存在する可能性があるため、この場合、古典的なルーティング アルゴリズムによって選択された特徴ベクトルが重複して競合し、計算に影響を与える可能性があります。正確さ。この問題を解決するために、MoE 構造は独立したエキスパート特徴ベクトルを採用することがよくあります。これは、各エキスパートが完全に独立しているものとして扱われ、エキスパート間の相関関係が無視されることを意味します。ただし、このアプローチではいくつかの問題が発生する可能性があります。したがって、専門家を選択する場合、教育省の組織は通常複数の専門家を選択し、異なる専門家の特性間に相関関係が存在する可能性があります。この場合、選択された特徴ベクトルには、計算に関与する各エキスパート間の内積の重複や競合が含まれる可能性があり、結果の精度に影響を及ぼします。したがって、MoE の構造には、最良の専門家を選択するためのより正確なルーティング アルゴリズムが必要であり、その選択を考慮する必要があります
2.2 論文の手法
2.2.1 モデル アーキテクチャ
元 2.0 に基づく2B モデル構造では、Yuan 2.0 では、入力トークンのローカル依存性を考慮するローカル フィルタリング ベース アテンション (LFA) が導入され、それによってモデルの精度が向上します。 Yuan 2.0-M32 では、各層の高密度フィードフォワード ネットワーク (FFN) が MoE コンポーネントに置き換えられます。
図 1 は、紙モデルに適用された MoE 層のアーキテクチャを示しています。 4 つの FFN を例に挙げると (実際には 32 人のエキスパートがいます)、各 MoE レイヤーはエキスパートとして独立した FFN で構成されます。エキスパート パス ネットワークは入力トークンを関連するエキスパートに割り当てるため、クラシック パス ネットワークは各エキスパートの特徴ベクトルを確立します。そして、入力トークンと各エキスパート特徴ベクトルの間の内積を計算して、トークンと各エキスパート間の類似性を取得します。最も類似性の高いエキスパートが出力の計算に使用されます。最も強い類似性を持つエキスパートがアクティブ化のために選択され、その後の計算に参加します。
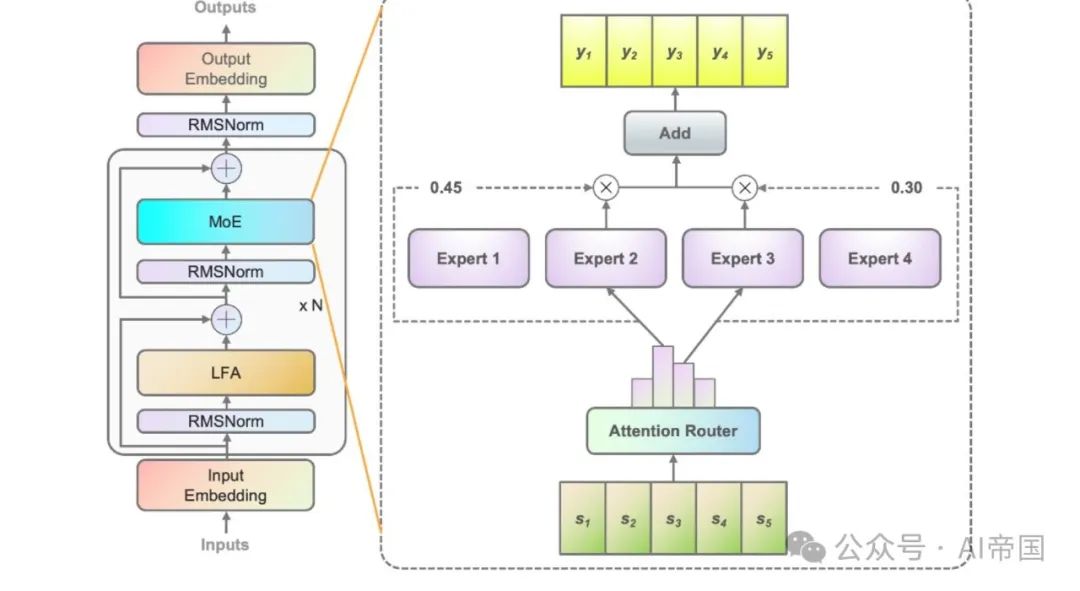 図 2(b) は、この研究で提案されたアテンション ルーターのアーキテクチャを示しています。この新しいルーティング ネットワークは、アテンション メカニズムを採用することで、エキスパート間の相関関係を統合します。専門家間の相関関係を表す係数行列が構築され、最終的な確率値の計算に適用されます。
図 2(b) は、この研究で提案されたアテンション ルーターのアーキテクチャを示しています。この新しいルーティング ネットワークは、アテンション メカニズムを採用することで、エキスパート間の相関関係を統合します。専門家間の相関関係を表す係数行列が構築され、最終的な確率値の計算に適用されます。
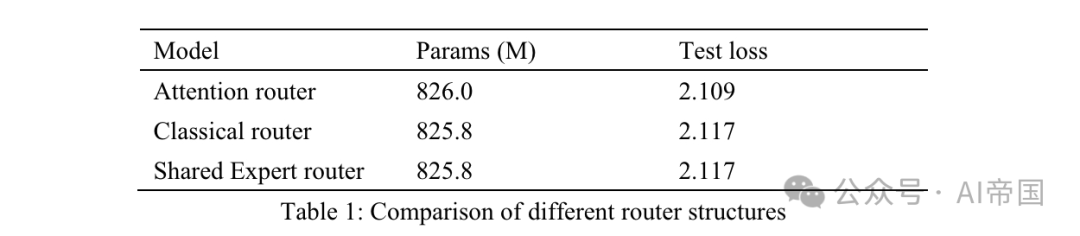
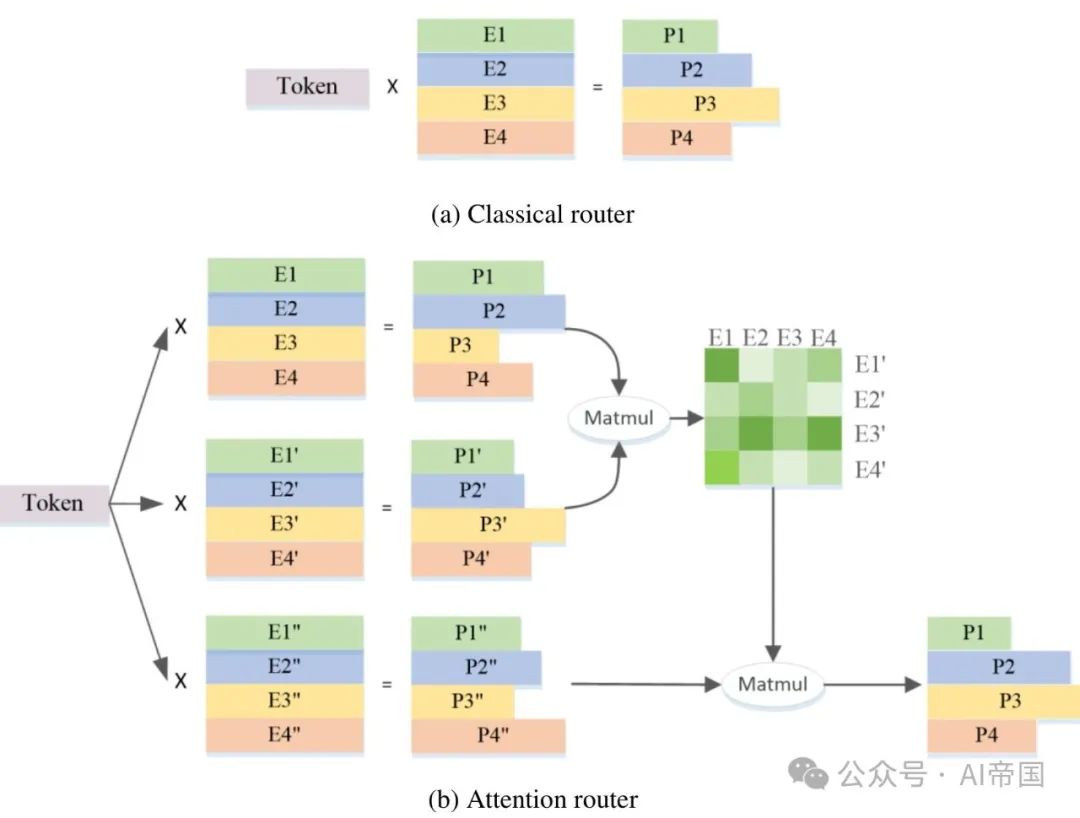 表 1: さまざまなルーティング構造の比較
表 1: さまざまなルーティング構造の比較
表 1 は、さまざまなルーターの精度結果を示しています。この論文のモデルは、訓練可能な 8 人の専門家を対象にアテンション ルーターをテストしました。クラシック ルーター モデルには、同様のパラメーター スケールを確保するために 8 人のトレーニング可能なエキスパートがあり、ルーティング構造は Mixtral 8*7B、つまり 1 つの線形レイヤー上の Softmax に適用されるものと同じです。共有エキスパート ルーターは、共有エキスパート分離戦略とクラシック ルーティング アーキテクチャを採用しています。一般知識を取得する 2 人の固定エキスパートと、14 人のオプションのエキスパートのうちの最初の 2 人が専門エキスパートです。
MoE の出力は、固定エキスパートとルーターによって選択されたエキスパートの組み合わせです。 3 つのモデルはすべて、トレーニングに 30Btoken を使用し、テストに別の 10Btoken を使用します。この論文では、クラシック ルーターと共有エキスパート ルーターの結果を考慮すると、後者はトレーニング時間の 7.35% 増加で全く同じテスト損失を達成したことがわかりました。共有エキスパートの計算効率は比較的低く、従来の MOE 戦略よりも優れたトレーニング精度にはつながりません。したがって、この論文のモデルでは、共有の専門家を持たない古典的なルーティング戦略が採用されています。従来のルーテッド ネットワークと比較して、ルーターの注意力損失テストは 3.8% 増加しました。
 この論文では、エキスパートの数を増やし、各エキスパートのパラメーター サイズを固定することによって、モデルのスケーラビリティをテストしています。トレーニング専門家の数を増やすと、モデルの能力が変わるだけで、実際にアクティブ化されたモデルのパラメーターは変わりません。すべてのモデルは 500 億トークンでトレーニングされ、さらに 100 億トークンでテストされています。この論文では、アクティブ化されたエキスパートを 2 に設定し、3 つのモデルのトレーニング ハイパーパラメーターは同じです。エキスパートのスケーリング効果は、500 億個のトークンをトレーニングした後のテスト損失によって測定されます (表 2)。 8 人の訓練可能な専門家を含むモデルと比較して、16 人の専門家を含むモデルは 2% の損失削減を示し、32 人の専門家を含むモデルは 3.6% の損失削減を示しました。同紙はその正確性を考慮して、人民元2.0-M32について32人の専門家を選出した。
この論文では、エキスパートの数を増やし、各エキスパートのパラメーター サイズを固定することによって、モデルのスケーラビリティをテストしています。トレーニング専門家の数を増やすと、モデルの能力が変わるだけで、実際にアクティブ化されたモデルのパラメーターは変わりません。すべてのモデルは 500 億トークンでトレーニングされ、さらに 100 億トークンでテストされています。この論文では、アクティブ化されたエキスパートを 2 に設定し、3 つのモデルのトレーニング ハイパーパラメーターは同じです。エキスパートのスケーリング効果は、500 億個のトークンをトレーニングした後のテスト損失によって測定されます (表 2)。 8 人の訓練可能な専門家を含むモデルと比較して、16 人の専門家を含むモデルは 2% の損失削減を示し、32 人の専門家を含むモデルは 3.6% の損失削減を示しました。同紙はその正確性を考慮して、人民元2.0-M32について32人の専門家を選出した。
表 2: 拡張実験結果
2.2.2 モデルトレーニング
Yuan 2.0-M32 はデータ並列処理とパイプライン並列処理の組み合わせを通じてトレーニングされますが、テンソル並列処理やオプティマイザ並列処理は使用しません。図 3 は損失曲線を示しており、最終的なトレーニング損失は 1.22 です。 微調整プロセスを介して、このペーパーはシーケンスの長さを16384に延長しました。 CodeLLama の研究 (Roziere et al., 2023) に従って、この論文では、シーケンス長の増加に伴う注意スコアの減衰を避けるために、回転位置埋め込み (RoPE) の基本周波数値をリセットしています。基本値を単純に 1000 から非常に大きな値 (1000000 など) に増やすのではなく、この論文では NTK 認識 (bloc97、2023) を使用して新しい基本値を計算します。
この論文では、事前トレーニング済み Yuan 2.0-M32 モデルのパフォーマンスを、NTK 知覚スタイルの新しい塩基と、および最大 16K の配列長の針検索タスクにおける他の塩基と比較しています。この論文では、NTK 知覚スタイルの新しい基本値 40890 の方がパフォーマンスが良いことがわかりました。したがって、微調整時には 40890 が適用されます。
2.2.4 事前トレーニングデータセット
Yuan 2.0-M32 は、2000B トークンを含むバイリンガル データ セットを使用して最初から事前トレーニングされます。事前トレーニングされた生データには 3,400B を超えるトークンが含まれており、各カテゴリの重みはデータの品質と量に基づいて調整されます。
包括的な事前トレーニング コーパスは、Web クロールされたデータ、Wikipedia、学術論文、書籍、コード、数学と数式、およびドメイン固有の専門知識をカバーする
44 のサブデータセットで構成されています。それらの一部はオープンソース データセットであり、残りは Yuan 2.0 によって作成されました。
一部の一般的な Web クローラー データ、中国語の書籍、会話、中国のニュース データは、Yuan 1.0 から継承されています (Wu et al., 2021)。 Yuan 2.0 の事前トレーニング データのほとんども再利用されています。
各データセットの構造とソースに関する詳細は次のとおりです:
ウェブ (25.2%): ウェブサイト クローラー データはオープン ソース データセットから取得され、パブリック クローラーは論文の以前の作業 (元 1.0) データから処理されました。集めました。 Web コンテキストから高品質のコンテンツを抽出するための Massive Data Filtering System (MDFS) の詳細については、Yuan 1.0 を参照してください。
百科事典 (1.2%)、論文 (0.84%)、書籍 (6.49%)、翻訳 (1.1%): データは Yuan 1.0 および Yuan 2.0 データセットから継承されます。
コード (47.5%): コード データセットは、Yuan 2.0 と比較して大幅に拡張されました。この論文では、Stack v2 のコードを使用しています (Lozhkov et al.、2024)。 Stack v2 のコメントは中国語に翻訳されます。コード合成データは、Yuan 2.0 と同様のアプローチで生成されました。
数学 (6.36%): 元 2.0 のすべての数学データが再利用されました。これらのデータは主に、proof-pile v1 (Azerbayev、2022) および v2 (Paster et al.、2023)、AMPS (Hendrycks et al.、2021)、MathPile (Wang、Xia、および Liu、2023) などのオープンソース データセットから取得しています。 ) および StackMathQA (Zhang、2024)。四則演算を容易にするためにPythonを使用して数値計算用の合成データセットを作成しました。
特定のドメイン (1.93%): これは、さまざまな背景知識を含むデータセットです。
2.2.5 微調整データセット
微調整データセットは、Yuan 2.0 で適用されたデータセットに基づいて拡張されています。
コード命令データセット。中国語の命令を含むすべてのプログラミング データと、英語のコメントを含む一部のプログラミング データは、大規模言語モデル (LLM) によって生成されます。コード命令データの約 30% は英語で、残りは中国語です。合成データは、プロンプト生成およびデータ クリーニング戦略において中国語の注釈を備えた Python コードを模倣しています。
Magicoder-Evol-Instruct-110K および CodeFeedback-Filtered-struct から収集された英語のコメントを含む Python コード。データセットから言語タグ (「Python」など) を含む命令データを抽出します。
C/C++/Go/Java/SQL/Shell などの他の言語のコード (英語のコメント付き) は、オープンソース データセットから取得され、Python コードと同様の方法で処理されます。クリーニング戦略は、Yuan 2.0 の方法と似ています。サンドボックスは、生成されたコードからコンパイル可能および実行可能な行を抽出し、少なくとも 1 つの単体テストに合格した行を保持するように設計されています。
算数指導データセット。数学指導データ セットはすべて、Yuan 2.0 の微調整データ セットから継承されています。プログラミング手法を通じて数学的問題を解決するモデルの能力を向上させるために、この論文では、Thoughts (PoT) によって促された数学的データを構築しました。 PoT は、数学的問題を Python で計算を実行するコード生成タスクに変換します。
安全指示データセット。 Yuan 2.0 チャット データ セットに加えて、この論文では、オープンソースの安全調整データ セットに基づいたバイリンガルの安全調整データ セットも構築しています。この論文では、公開データセットから質問のみを抽出し、質問の多様性を高め、大規模な言語モデルを使用して中国語と英語の回答を再生成しています。
2.2.6 トークナイザー
Yuan 2.0-M32 の場合、英語と中国語のトークナイザーは Yuan 2.0 で適用されたトークナイザーから継承されます。
2.3 論文の効果
この論文は、HumanEval での Yuan 2.0-M32 のコード生成能力、GSM8K と MATH での数学的問題解決能力、ARC での科学的知識と推論能力を評価しています。総合的なベンチマークとして MMLU で評価されます。
2.3.1 コード生成
コード生成機能は、HumanEval ベンチマークを使用して評価されます。評価方法とヒントは、メタ 2.0 で説明されているものと同様です。
 表 3: Yuan 2.0-M32 と HumanEval pass @1 の他のモデルの比較
表 3: Yuan 2.0-M32 と HumanEval pass @1 の他のモデルの比較
モデルはその後に機能を完了する予定です。生成された関数は単体テストを通じて評価されます。表 3 は、Yuan 2.0-M32 のゼロショット学習の結果と他のモデルとの比較を示しています。 Yuan 2.0-M32 の結果は、DeepseekV2 と Llama3-70B に次いで 2 番目であり、アクティブなパラメーターと計算消費量が他のモデルよりもはるかに低いにもかかわらず、他のモデルをはるかに上回っています。
DeepseekV2 と比較すると、この論文のモデルはアクティブなパラメーターの 4 分の 1 未満を使用し、トークンごとに必要な計算は 5 分の 1 未満でありながら、90% 以上の精度レベルを達成しています。 Llama3-70B と比較すると、モデルパラメータと計算量の差はさらに大きくなりますが、それでも 91% のレベルに達することができます。 Yuan 2.0-M32 は確かなプログラミング能力を示し、4 問中 3 問に合格しました。 Yuan 2.0-M32 は小規模サンプルの学習に優れており、HumanEval の精度は 14 回の試行で 78.0 に向上しました。
2.3.2 数学
Yuan 2.0-M32 の数学的機能は、GSM8K および MATH ベンチマークを通じて評価されます。 GSM8K のプロンプトとテスト戦略は、Yuan 2.0 に適用されたものと似ていますが、唯一の違いは、この論文では 8 回の試行が行われることです (表 4)。
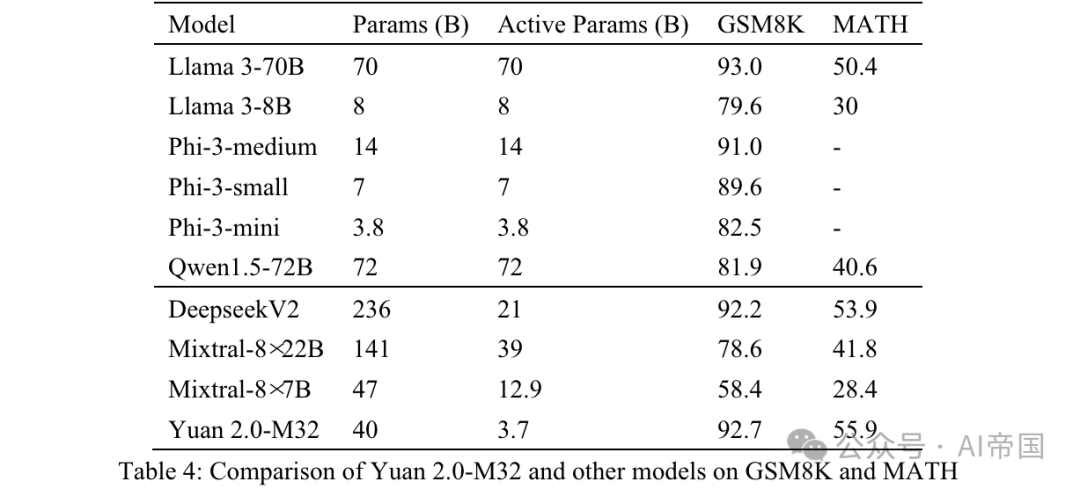 表 4: Yuan 2.0-M32 と GSM8K および MATH の他のモデルとの比較
表 4: Yuan 2.0-M32 と GSM8K および MATH の他のモデルとの比較
MATH は、12,500 の難しい数学コンテストの質問と回答を含むデータセットです。このデータセットの各質問には完全な段階的な解決策があり、モデルが回答の導出と説明を生成するようにガイドされます。質問に対する答えは、数値または数式 (y=2x+5、x-+2x-1、2a+b など) にすることができます。 Yuan 2.0-M32 は、Chain of Thinking (CoT) メソッドを使用して、4 回の試行を通じて最終的な答えを生成します。分析から回答が抽出され、統一されたフォーマットに変換されます。
数値結果の場合、すべての形式で数学的に同等の出力が受け入れられます。たとえば、分数 1/2、12、0.5、0.50 はすべて 0.5 に変換され、同じ結果として扱われます。数式については、この論文ではタブ記号とスペース記号が削除され、リズムや音符の正規表現が統一されています。 55 「5」はすべて同じ答えとして受け入れられます。処理後の最終結果は標準回答と比較され、EM (Exact Match) スコアを使用して評価されます。
表 4 に示す結果からわかるように、Yuan 2.0-M32 は MATH ベンチマークで最高のスコアを持っています。 Mixtral-8x7B と比較すると、後者のアクティブパラメータは Yuan 2.0-M32 の 3.48 倍ですが、Yuan のスコアはそのほぼ 2 倍です。 GSM8K では、Yuan 2.0-M32 のスコアも Llama 3-70B に非常に近く、他のモデルよりも優れています。
2.3.3MMLU
大規模マルチタスク言語理解 (MMLU) は、基本的な言語タスクから高度な論理推論タスクまで、STEM、人文科学、社会科学などの 57 分野をカバーします。 MMLU のすべての質問は英語の多肢選択式 QA 質問です。モデルは、正しいオプションまたは対応する分析を生成することが期待されます。
元 2.0-M32 の入力データ構成を付録 B に示します。前のテキストがモデルに送信され、正解またはオプション ラベルに関連付けられたすべての回答が正しいとみなされます。
最終精度は MC1 によって測定されます (表 5)。 MMLU の結果は、さまざまな分野におけるペーパー モデルの機能を示しています。 Yuan 2.0-M32 は、Mixtral-8x7B、Phi-3-mini、Llama 3-8B をパフォーマンスで上回っています。
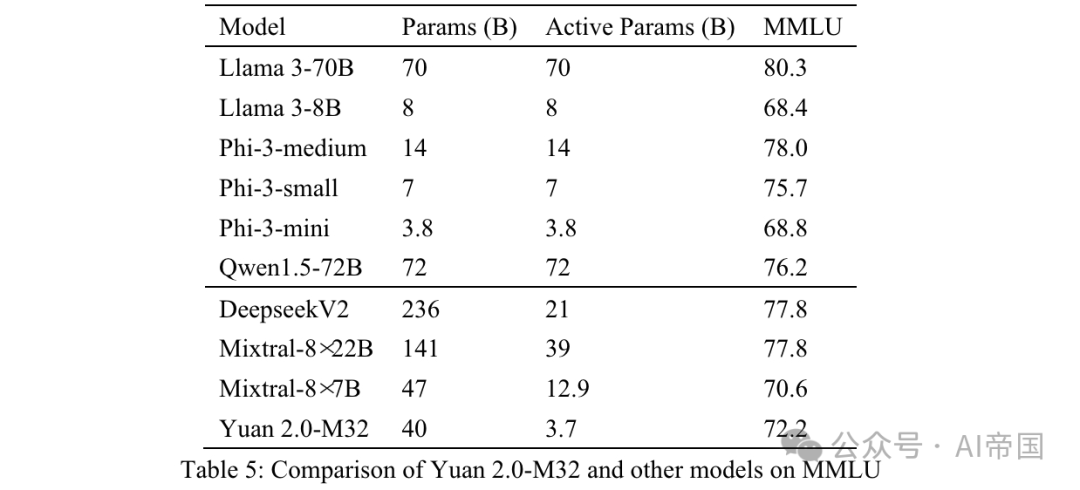 表 5: Yuan 2.0-M32 と MMLU 上の他のモデルの比較
表 5: Yuan 2.0-M32 と MMLU 上の他のモデルの比較
2.3.4 ARC
AI2 Inference Challenge (ARC) ベンチマークは、3 つのデータを含む複数選択の QA データセットです。 9年生から9年生までの理科のテストの問題。 Easy と Challenge の 2 つの部分に分かれており、後者にはさらなる推論が必要なより複雑な部分が含まれています。この論文では、課題セクションで論文のモデルをテストします。
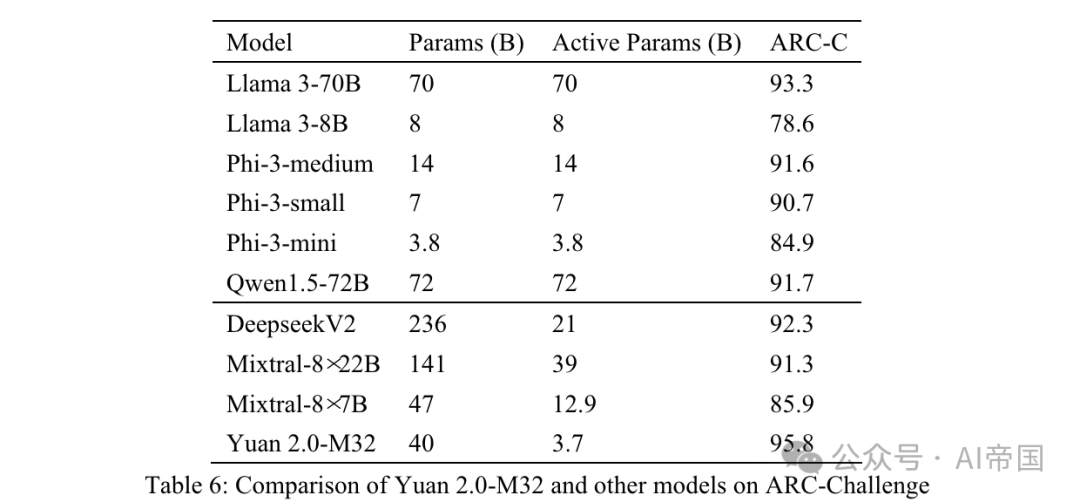 表 6: Yuan 2.0-M32 と ARC-Challenge の他のモデルの比較
表 6: Yuan 2.0-M32 と ARC-Challenge の他のモデルの比較
質問と選択肢は直接接続されており、 で区切られています。 前のテキストがモデルに送信され、ラベルまたは対応する回答が生成されることが期待されます。生成された回答は実際の回答と比較され、結果は MC1 ターゲットを使用して計算されます。
表 6 は、Yuan 2.0-M32 が複雑な科学的問題の解決に優れていることを示す ARC-C の結果を示しており、このベンチマークでは Llama3-70B よりも優れています。
 写真
写真
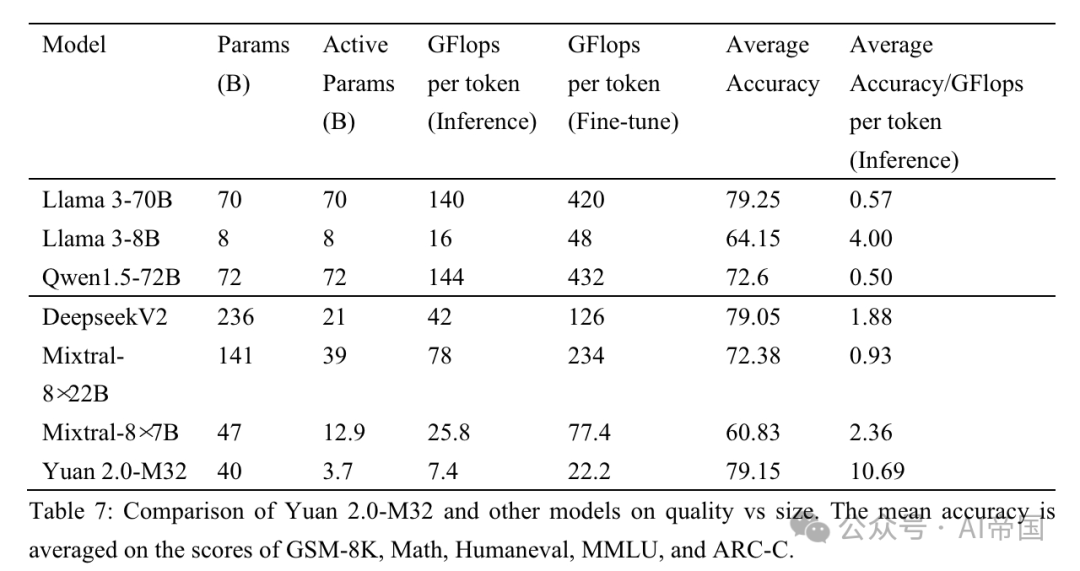
表 7: 元 2.0-M32 と他のモデルの品質とサイズの比較。平均精度は、GSM-8K、Math、Humaneval、MMLU、ARC-C のスコアに基づいて平均化されています
この論文では、論文のパフォーマンスを 3 つの MoE モデル (Mixtral ファミリー、Deepseek) と 6 つの高密度モデル (Qwen (Bai et al., 2023)、Llama ファミリー、および Phi-3 ファミリー (Abdin et al., 2024) と比較しています) )) さまざまな分野で元 2.0-M32 のパフォーマンスを評価します。表 7 は、Yuan 2.0-M32 と他のモデルの精度と計算量の比較を示しています。 Yuan 2.0-M32 は、370 億のアクティブ パラメーターとトークンあたり 22.2 GFlops のみを使用して微調整されており、表にリストされている他のモデルと同等またはそれを上回る結果を得るのに最も経済的です。表 7 は、推論プロセスにおけるペーパー モデルの優れた計算効率とパフォーマンスを示しています。 Yuan 2.0-M32 の平均精度は 79.15 で、Llama3-70B に匹敵します。トークンごとの平均精度/GFlops 値は 10.69 で、Llama3-70B の 18.9 倍です。
論文のタイトル: 元 2.0-M32: 注目ルーターと専門家の混合
論文のリンク: https://www.php.cn/link/cc7d159d6ff3ea6f39b9419877dfc81f
以上がLLM | 元 2.0-M32: アテンション ルーティングを備えたエキスパート混合モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。