AI の分野では、スケーリングの法則は、研究者にガイドラインを提供し、言語モデルのパフォーマンスがスケールに応じてどのように変化するかを理解するための重要なガイドとなります。 しかし残念なことに、ほとんどの研究者はスケーリングの法則をゼロから構築するための計算リソースを持っておらず、オープンモデルのトレーニングスケールが少なすぎて信頼できないため、多くのベンチマークやトレーニング後の研究ではスケーリング分析は一般的ではありません。展開予想。 スタンフォード大学、トロント大学、その他の機関の研究者らは、代替の観察方法である観察スケーリング則を提案しました。これは、言語モデル (LM) の機能と、言語モデル (LM) の機能を、言語モデル内だけでなく、複数のモデル ファミリ全体にわたる下流のパフォーマンスと組み合わせます。標準の計算拡張則の場合と同様に、単一系列です。 このメソッドはモデルのトレーニングをバイパスし、代わりに約 80 の公開されているモデルに基づいてスケーリング則を構築します。しかし、これは別の問題につながります。異なるモデル間のトレーニングの計算効率と能力には大きな違いがあるため、複数のモデル ファミリから単一の拡張則を構築することは大きな課題に直面します。 それにもかかわらず、この研究は、これらの変更が、言語モデルのパフォーマンスが低次元の能力空間の関数であり、モデルファミリー全体が変換効率のみが異なるという、単純で一般化されたスケーリング則と一致していることを示しています。トレーニング計算を能力に変換します。 上記の方法を使用して、この研究は他の多くのタイプの拡張研究の驚くべき予測可能性を実証し、次のことを発見しました。いくつかの創発現象は滑らかなシグモイド挙動に従い、GPT-4 のような小さなモデルから予測可能です。のは、より単純な非エージェント ベンチマークから正確に予測できます。さらに、この研究では、思考連鎖などのトレーニング後の介入がモデルに及ぼす影響を予測する方法も示しています。 小さなサブ GPT-3 モデルのみを使用してフィッティングした場合でも、観察可能な拡張則により、緊急能力、エージェントのパフォーマンス、思考連鎖などのトレーニング後の方法の拡張などの複雑な現象が正確に予測されることが研究で示されています。
- 論文アドレス: https://arxiv.org/pdf/2405.10938
- 論文タイトル: Observational Scaling Laws and the Predictability of Language Model Performance
のこの論文の中で、Yangjun Ruan 氏は中国人の著者であり、浙江大学を卒業して学士号を取得しました。
この論文は、思考連鎖の提案者であるジェイソン・ウェイからも転送コメントを受け取りました。ジェイソン・ウェイは、この研究がとても気に入ったと述べています。
この調査では、現在、さまざまな規模と機能を持つ何百ものオープン モデルが存在することが観察されました。ただし、研究者はこれらのモデルを直接使用して展開則を計算することはできません (トレーニングの計算効率はモデル ファミリによって大きく異なるため) が、研究者はモデル ファミリに適用できるより一般的な展開則が存在することを期待しています。
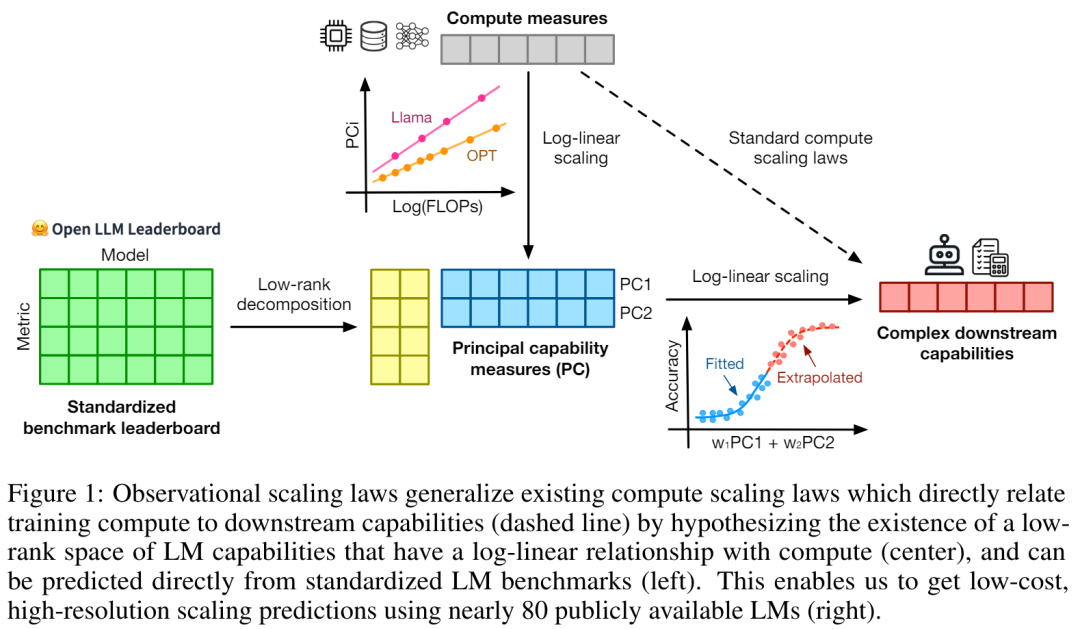
特に、この論文では、LM の下流側のパフォーマンスは低次元の能力空間 (自然言語理解、推論、コード生成など) の関数であり、モデル ファミリはその効率のみが異なると仮定しています。トレーニング計算をこれらの機能に変換する際に。この関係が成り立つ場合、モデル ファミリ全体で低次元の機能から下流の機能まで対数線形の関係が存在することを意味します (これにより、研究者は既存のモデルを使用してスケーリング則を確立できるようになります) (図 1)。この研究では、80 近くの公的に入手可能な LM を使用して、低コストで高解像度の拡張予測を取得しました (右)。
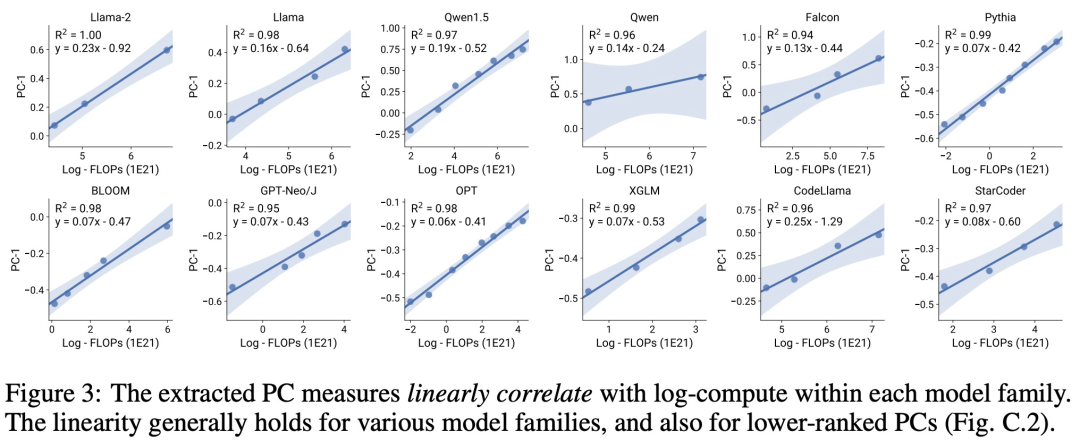
標準的な LM ベンチマーク (Open LLM Leaderboard など) を分析することにより、研究者らは、モデル ファミリ内の計算量 (R^2 > 0.9) と拡張則の関係がある、そのような能力の尺度をいくつか発見しました (参照)下の図 3)、この関係はさまざまなモデルファミリーと下流の指標の間にも存在します。この記事では、この拡大関係を観察可能な拡大則と呼びます。
最後に、この研究は、研究の中核となる知見の多くを再現するのに十分な一連のモデルがいくつかあるため、観察可能な展開則の使用が安価で簡単であることを示しています。このアプローチを使用した研究では、ベースラインおよびトレーニング後の介入のスケーリング予測は、わずか 10 ~ 20 個のモデルを評価するだけで簡単に達成できることがわかりました。
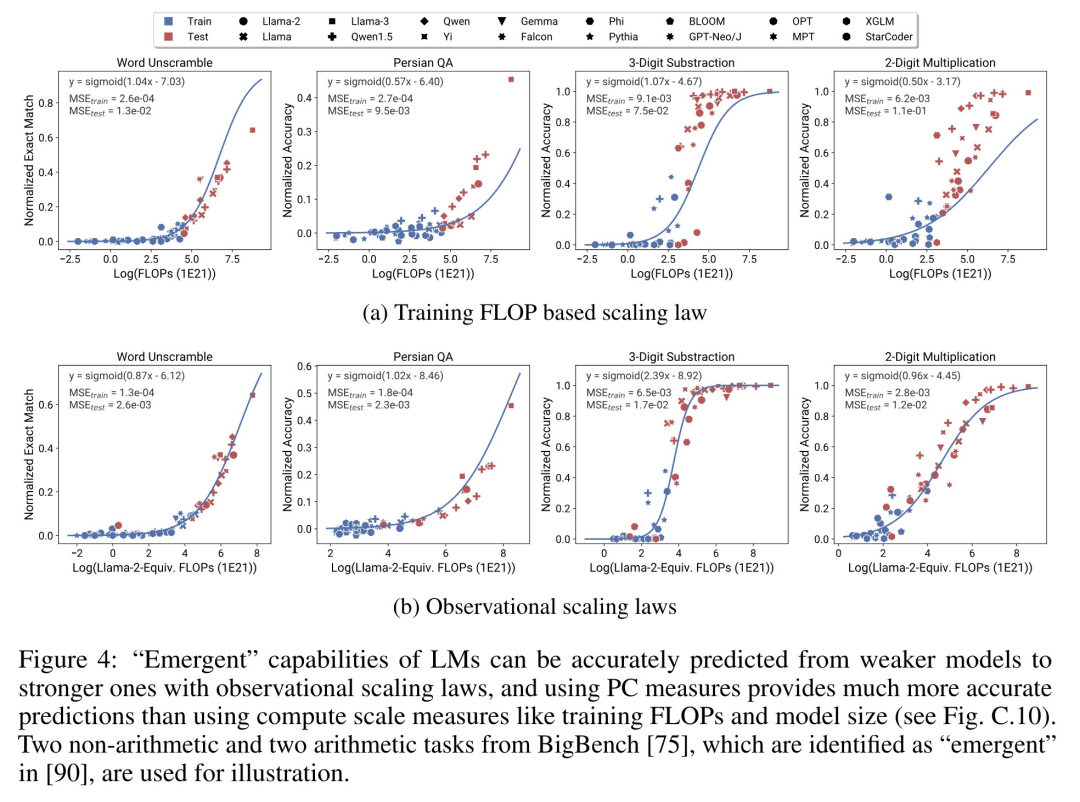
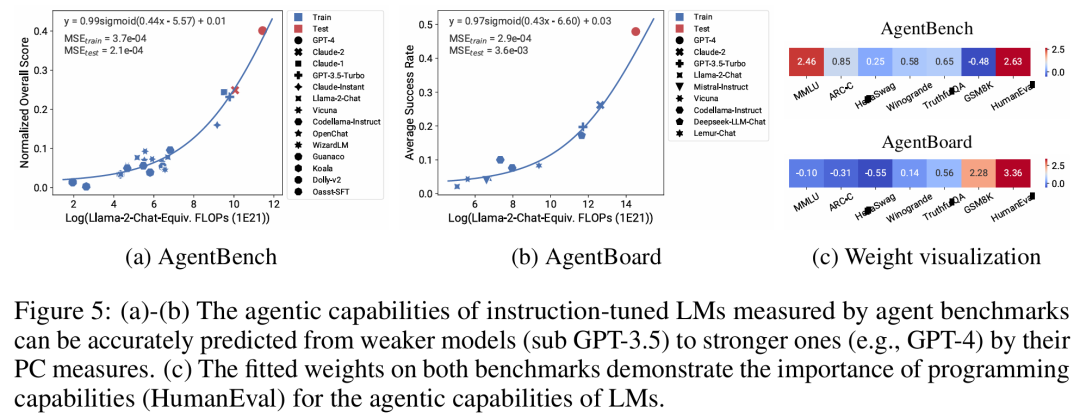
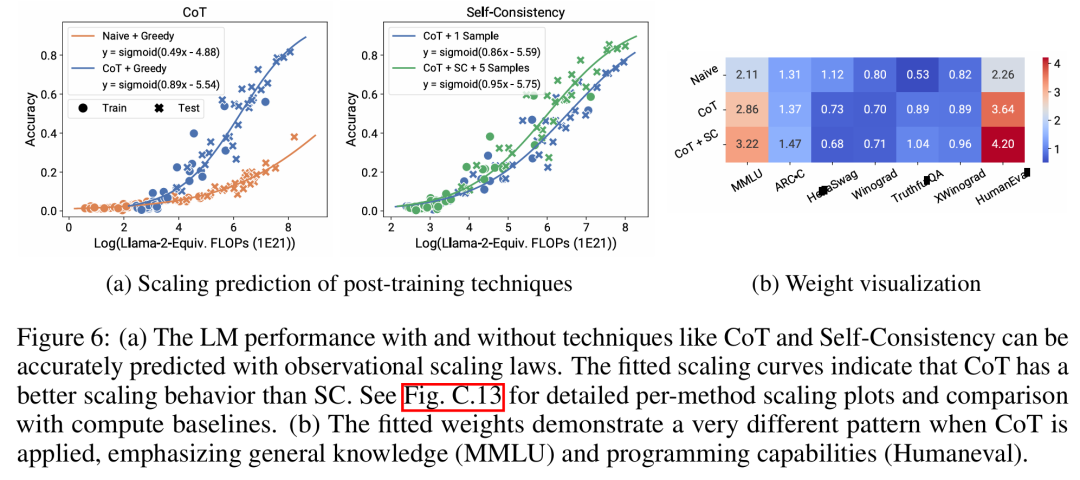
LM に特定の計算しきい値で不連続に発生する「緊急」機能があるかどうか、また、これらの機能が小規模モデルを使用して予測できるかどうかについて、激しい議論が行われてきました。観察可能な膨張法則は、これらの現象の一部が滑らかな S 字曲線に従い、小型のサブ Llama-2 7B モデルを使用して正確に予測できることを示唆しています。 この研究は、AgentBench と AgentBoard によって測定される、エージェントとしての LM のより高度で複雑な能力が、予測される観測可能な拡張則を使用して測定できることを示しています。この研究では、観察可能なスケーリング則を通じて、より弱いモデル (サブ GPT-3.5) のみを使用して GPT-4 のパフォーマンスを正確に予測し、エージェントのパフォーマンスを推進する要因としてプログラミング能力を特定しています。 この研究は、拡張則がより弱いモデル (サブ Llama-2 7B) に適合した場合でもトレーニング後のメソッドを確実に予測できることを示しています。思想、自己一貫性など全体として、この研究の貢献は、計算、単純な能力測定、および複雑な下流指標間の予測可能な対数線形関係を利用する、観察可能なスケーリング則を提案することです。 研究者たちは、実験を通じてこれらの拡大則の有用性を検証しました。さらに、論文の発表後、研究者らは拡張則が現在のモデルに過剰適合するかどうかをテストするために、将来のモデルの予測も事前登録しました。実装プロセスとデータ収集に関する関連コードは GitHub でリリースされました: GitHub アドレス: https://github.com/ryoungj/ObsScaling 以下の図 4 は、PC (プリンシパル ケイパビリティ) 測定を使用した予測結果と、トレーニング FLOP に基づく予測パフォーマンスのベースライン結果を示しています。パフォーマンスの低いモデルのみを使用した場合でも、PC メトリックを使用してこれらの能力を正確に予測できることがわかります。 対照的に、トレーニング FLOP を使用すると、より高い MSE 値で示されるように、テスト セットでの外挿が大幅に悪化し、トレーニング セットでの適合度が大幅に悪化します。これらの違いは、異なるモデル ファミリに対する FLOP のトレーニングによって引き起こされる可能性があります。 以下の図 5 は、PC メトリックを使用したオブザーバブル拡張則の予測結果を示しています。どちらのエージェント ベンチマークでも、PC メトリックを使用したホールドアウト モデル (GPT-4 または Claude-2) のパフォーマンスは、パフォーマンスの低い (ギャップが 10% 以上) モデルから正確に予測できることがわかります。 これは、LM のより複雑なエージェント機能がその基礎となるモデル機能と密接に関連しており、後者に基づいて予測を行うことができることを示しています。これは、バックボーン LM の規模が拡大し続けるにつれて、LM ベースのエージェント機能が優れたスケーラビリティ特性を備えていることも示しています。 以下の図6aは、観察可能な拡大法則を使用したCoTおよびSC(自己無矛盾性、自己無矛盾性)の拡大予測結果を示しています。 (単純な) ポストトレーニング手法を使用せずに CoT および CoT+SC を使用した、より強力で大規模なモデルのパフォーマンスは、計算規模が小さい (モデル サイズやトレーニング FLOP など) より弱いモデルから正確に予測できることがわかります。 2 つのテクノロジー間でスケーリング傾向が異なることは注目に値します。CoT は、CoT の自己一貫性を使用する場合と比較して、より明らかなスケーリング傾向を示します。技術的な詳細については、元の論文を参照してください。 以上が80 のモデルからスケーリング則を構築: 中国人博士課程学生による新作。思考の連鎖の著者が強く推奨の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。