


大規模言語モデル (llm) は、自然言語処理の分野に革命をもたらしました。これらのモデルのサイズと複雑さが増大するにつれて、推論に必要な計算量も大幅に増加します。この課題に対処するには、複数の GPU を活用することが重要になります。

したがって、この記事では、複数の GPU で同時に推論を実行します。内容は主に、Accelerate ライブラリの紹介、簡単なメソッドと実際のコード例、複数の GPU を使用したパフォーマンス ベンチマーク
この記事では、複数の 3090
##基本的な例
最初に、Accelerate を使用したマルチ GPU の「メッセージ パッシング」を示す簡単な例を紹介します。
from accelerate import Accelerator from accelerate.utils import gather_object accelerator = Accelerator() # each GPU creates a string message=[ f"Hello this is GPU {accelerator.process_index}" ] # collect the messages from all GPUs messages=gather_object(message) # output the messages only on the main process with accelerator.print() accelerator.print(messages)
出力は次のとおりです:
['Hello this is GPU 0', 'Hello this is GPU 1', 'Hello this is GPU 2', 'Hello this is GPU 3', 'Hello this is GPU 4']
マルチ GPU 推論
次のとおりです。は、単純な非バッチ推論方法です。コードは非常に単純です。Accelerate ライブラリがすでに多くの作業を行っているため、それを直接使用できます。
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:# store output of generations in dictresults=dict(outputs=[], num_tokens=0) # have each GPU do inference, prompt by promptfor prompt in prompts:prompt_tokenized=tokenizer(prompt, return_tensors="pt").to("cuda")output_tokenized = model.generate(**prompt_tokenized, max_new_tokens=100)[0] # remove prompt from output output_tokenized=output_tokenized[len(prompt_tokenized["input_ids"][0]):] # store outputs and number of tokens in result{}results["outputs"].append( tokenizer.decode(output_tokenized) )results["num_tokens"] += len(output_tokenized) results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time {timediff}, total tokens {num_tokens}, total prompts {len(prompts_all)}")
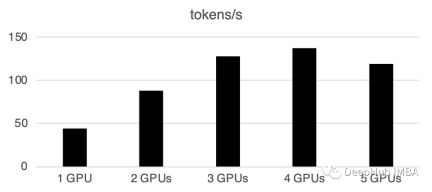
複数の GPU を使用すると、ある程度の通信オーバーヘッドが発生します: パフォーマンス4 GPU では直線的に増加し、この特定の設定では横ばいになります。もちろん、ここでのパフォーマンスは、モデルのサイズと量子化、ヒントの長さ、生成されたトークンの数、サンプリング戦略などの多くのパラメーターに依存するため、一般的なケースについてのみ説明します。
1 GPU: 44 トークン/秒、時間: 225.5秒
2 GPU: 1秒あたり88トークン処理、合計時間112.9秒
3 GPU: 128トークン処理1 秒あたり、合計時間 77.6 秒
4 GPU: 137 トークン/秒、時間: 72.7 秒
5 GPU: 119 トークン/秒処理2 番目、合計 83.8 秒かかります
複数の GPU でのバッチ処理
現実の世界では、バッチ推論を使用して処理を高速化できます。これにより、GPU 間の通信が削減され、推論が高速化されます。 prepare_prompts 関数を追加するだけで、単一のデータではなくデータのバッチをモデルに入力できます。
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() def write_pretty_json(file_path, data):import jsonwith open(file_path, "w") as write_file:json.dump(data, write_file, indent=4) # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) tokenizer.pad_token = tokenizer.eos_token # batch, left pad (for inference), and tokenize def prepare_prompts(prompts, tokenizer, batch_size=16):batches=[prompts[i:i + batch_size] for i in range(0, len(prompts), batch_size)]batches_tok=[]tokenizer.padding_side="left" for prompt_batch in batches:batches_tok.append(tokenizer(prompt_batch, return_tensors="pt", padding='longest', truncatinotallow=False, pad_to_multiple_of=8,add_special_tokens=False).to("cuda") )tokenizer.padding_side="right"return batches_tok # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:results=dict(outputs=[], num_tokens=0) # have each GPU do inference in batchesprompt_batches=prepare_prompts(prompts, tokenizer, batch_size=16) for prompts_tokenized in prompt_batches:outputs_tokenized=model.generate(**prompts_tokenized, max_new_tokens=100) # remove prompt from gen. tokensoutputs_tokenized=[ tok_out[len(tok_in):] for tok_in, tok_out in zip(prompts_tokenized["input_ids"], outputs_tokenized) ] # count and decode gen. tokens num_tokens=sum([ len(t) for t in outputs_tokenized ])outputs=tokenizer.batch_decode(outputs_tokenized) # store in results{} to be gathered by accelerateresults["outputs"].extend(outputs)results["num_tokens"] += num_tokens results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time elapsed: {timediff}, num_tokens {num_tokens}")
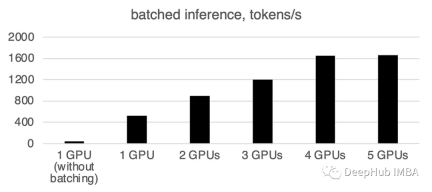
バッチ処理が大幅に高速化されることがわかります。
書き直す必要があるのは次のとおりです: 1 GPU: 520 トークン/秒、時間: 19.2 秒
2 つの GPU の場合、計算能力は次のとおりです。 1 秒あたり 900 トークン、計算時間は 11.1 秒です。
3 GPU: 1205 トークン/秒、時間: 8.2 秒
##4 GPU : 1655 トークン/秒、所要時間: 6.0 秒5 GPU: 1658 トークン/秒、所要時間: 6.0 秒
この記事の時点では、llama.cpp、ctransformer は、llama のようなマルチ GPU 推論をサポートしていません。cpp は 6 月にマルチ GPU マージを予定しています。が、公式アップデートは見ていないので、現時点ではマルチGPUはここではサポートされていないと判断されます。誰かが複数の GPU をサポートできることを確認した場合は、メッセージを残してください。
huggingface の Accelerate パッケージは、複数の GPU を使用するための非常に便利なオプションを提供します。推論に複数の GPU を使用すると、パフォーマンスが大幅に向上しますが、GPU 間の通信コストが増加するにつれて大幅に増加します。 GPUの数が増えます。
以上がAccelerate ライブラリを使用した複数の GPU での LLM 推論の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AM
生成エンジン最適化に関するビジネスリーダーのガイド(GEO)May 03, 2025 am 11:14 AMGoogleはこのシフトをリードしています。その「AIの概要」機能はすでに10億人以上のユーザーにサービスを提供しており、誰もがリンクをクリックする前に完全な回答を提供しています。[^2] 他のプレイヤーも速く地位を獲得しています。 ChatGpt、Microsoft Copilot、およびPE
 このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM
このスタートアップは、AIエージェントを使用して悪意のある広告となりすましアカウントと戦っていますMay 03, 2025 am 11:13 AM2022年、彼はソーシャルエンジニアリング防衛のスタートアップDoppelを設立してまさにそれを行いました。そして、サイバー犯罪者が攻撃をターボチャージするためのより高度なAIモデルをハーネスするにつれて、DoppelのAIシステムは、企業が大規模に戦うのに役立ちました。
 世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM
世界モデルがどのように生成AIとLLMの未来を根本的に再形成しているかMay 03, 2025 am 11:12 AM出来上がりは、適切な世界モデルとの対話を介して、生成AIとLLMを実質的に後押しすることができます。 それについて話しましょう。 革新的なAIブレークスルーのこの分析は、最新のAIで進行中のForbes列のカバレッジの一部であり、
 2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM
2050年5月:私たちは祝うために何を残しましたか?May 03, 2025 am 11:11 AM労働者2050年。全国の公園は、ノスタルジックなパレードが街の通りを通り抜ける一方で、伝統的なバーベキューを楽しんでいる家族でいっぱいです。しかし、お祝いは現在、博物館のような品質を持っています。
 あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AM
あなたが聞いたことがないディープフェイク検出器はそれが98%正確ですMay 03, 2025 am 11:10 AMこの緊急かつ不安な傾向に対処するために、TEM Journalの2025年2月版の査読済みの記事は、その技術のディープフェイクが現在存在する場所に関する最も明確でデータ駆動型の評価の1つを提供します。 研究者
 Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM
Quantum Talent Wars:The Hidden Crisis Treatenting Tech'の次のフロンティアMay 03, 2025 am 11:09 AM新薬を策定するのにかかる時間を大幅に短縮することから、より環境に優しいエネルギーを生み出すまで、企業が新境地を破る大きな機会があります。 しかし、大きな問題があります:スキルを持っている人々が深刻な不足があります
 プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM
プロトタイプ:これらの細菌は電気を生成できますMay 03, 2025 am 11:08 AM数年前、科学者は、特定の種類のバクテリアが酸素を摂取するのではなく、電気を生成することで呼吸するように見えることを発見しましたが、どのようにしたのかは謎でした。 Journal Cellに掲載された新しい研究は、これがどのように起こるかを特定しています:微生物
 AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM
AIとサイバーセキュリティ:新政権の100日間の計算May 03, 2025 am 11:07 AM今週のRSAC 2025会議で、SNYKは「The First 100 Days:How AI、Policy&Cybersecurity Collide」というタイトルのタイムリーなパネルを開催しました。ニコール・ペルロス、元ジャーナリストとパートネ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

