



以前に書きました
今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングされたデータに関する広範な実験を通じて、SL-SLAM が測位精度と追跡堅牢性の点で最先端の SLAM アルゴリズムを上回ることを実証しました。
プロジェクトリンク: https://github.com/zzzzxxxx111/SLslam.
(親指を上にスワイプし、一番上のカードをクリックしてフォローしてください。操作全体にかかる時間はわずか 1.328 秒で、その後は未来を離れて、すべて、無料の乾いた情報、コンテンツがあなたに役立つ場合に備えて~)
現在のSLAMアプリケーションの背景の紹介
SLAM (同時測位と地図構築) はロボット工学のテクノロジーです。自動運転と3D再構成 キーとなる技術は、センサーの位置の特定(位置特定)と環境の地図の構築を同時に行うことです。視覚センサーと慣性センサーは最も一般的に使用されるセンシング デバイスであり、関連するソリューションについては徹底的に議論され、検討されてきました。数十年の開発を経て、視覚的 (慣性) SLAM の処理フレームワークは、追跡、マップ構築、ループ検出などの基本的なフレームワークを形成しました。 SLAM アルゴリズムでは、追跡モジュールはロボットの軌道の推定を担当し、マップ構築モジュールは環境マップの生成と更新に使用され、ループ検出は訪問場所の特定に使用されます。これらのモジュールは相互に連携して、ロボットの状態と環境を認識します。 ビジュアル SLAM で一般的に使用されるアルゴリズムには、特徴点法、直接法、および半直接法があります。特徴点法は、特徴点を抽出してマッチングすることでカメラ姿勢と3次元点群を推定するものであり、直接法は画像の階調差を最小限に抑えてカメラ姿勢と3次元点群を推定する手法である。研究は、極端な条件下での堅牢性と適応性の向上に焦点を当ててきました。 SLAM 技術の開発には長い歴史があるため、ORB-SLAM、VINS-Mono、DVO、MSCKF など、伝統的な幾何学的手法に基づいた代表的な SLAM 作品が数多くあります。ただし、いくつかの未解決の疑問が残っています。低照度または動的照明、深刻なジッター、弱いテクスチャ領域などの困難な環境では、従来の特徴抽出アルゴリズムは画像の構造情報や意味情報を考慮せずに画像のローカル情報のみを考慮するため、上記の状況に遭遇した場合、既存のSLAM システムの追跡が不安定になり、効果がなくなる可能性があります。 したがって、これらの条件下では、SLAM システムの追跡が不安定になり、効果がなくなる可能性があります。
ディープラーニングの急速な発展は、コンピュータービジョンの分野に革命的な変化をもたらしました。大量のデータをトレーニングに利用することで、深層学習モデルは複雑なシーン構造と意味論的な情報をシミュレートできるため、SLAM システムのシーンを理解して表現する能力が向上します。この方法は主に 2 つのアプローチに分かれます。 1 つ目は、Droid-slam、NICE-SLAM、DVI-SLAM などの深層学習に基づくエンドツーエンドのアルゴリズムです。ただし、これらの方法では、トレーニング用に大量のデータ、大量のコンピューティング リソース、ストレージ容量が必要となるため、リアルタイムの追跡を実現することが困難になります。 2 番目のアプローチはハイブリッド SLAM と呼ばれ、深層学習を利用して SLAM の特定のモジュールを強化します。ハイブリッド SLAM は、従来の幾何学的手法と深層学習手法を最大限に活用し、ほぼすべての制約と意味的理解の間のバランスを見つけることができます。この分野ではいくつかの研究が行われていますが、深層学習テクノロジーを効果的に統合する方法は、まださらなる研究に値する方向性です。
現在、既存のハイブリッド SLAM にはいくつかの制限があります。 DXNet は、ORB 特徴点を深い特徴点に置き換えるだけですが、これらの特徴を追跡するために従来の方法を引き続き使用します。したがって、これにより、深度特徴情報の一貫性が失われる可能性があります。 SP-Loop は、深層学習の特徴点のみを閉ループ モジュールに導入し、その他の部分では従来の特徴点抽出方法を保持します。したがって、これらのハイブリッド SLAM 手法は深層学習テクノロジを効果的かつ包括的に組み合わせていないため、一部の複雑なシーンでは追跡とマッピングの効果が低下します。
これらの問題を解決するために、ここでは深層学習に基づく多機能 SLAM システムを提案します。 Superpoint 特徴点抽出モジュールをシステムに統合し、それを唯一の表現形式として全体的に使用します。さらに、複雑な環境では、従来の特徴マッチング方法は不安定性を示すことが多く、追跡とマッピングの品質の低下につながります。ただし、深層学習ベースの特徴マッチング手法の最近の進歩により、複雑な環境でもマッチング パフォーマンスの向上を達成できる可能性が示されています。これらの方法では、シーンの事前情報と構造の詳細を利用して、マッチングの有効性を高めます。最新の SOTA (最先端) マッチング手法である Lightglue は、その効率的かつ軽量な特性により、高いリアルタイム性能を必要とする SLAM システムに利点をもたらします。したがって、SLAM システム全体の特徴マッチング手法を Lightglue に置き換え、従来の手法と比較して堅牢性と精度を向上させました。
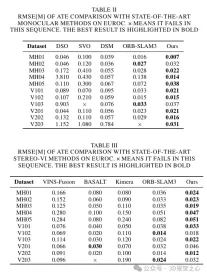
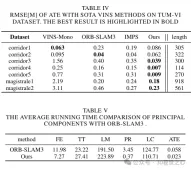
スーパーポイント特徴点記述子を処理するとき、対応するビジュアルワードのバッグのトレーニングと一致するようにそれらを前処理します。 Lightglue と組み合わせると、このアプローチは正確なシーン認識を実現します。同時に、精度と効率のバランスを維持するために、特徴点の選択戦略が設計されます。スケーラビリティ、移植性、リアルタイム パフォーマンスを考慮して、ONNX+Runtime ライブラリを利用してこれらの深層学習モデルを展開します。最後に、図 8 に示すように、この方法がさまざまな困難なシナリオにおいて、SLAM アルゴリズムの軌道予測精度と追跡の堅牢性を向上させることを証明するために、一連の実験が設計されています。

SL-SLAMシステムフレームワーク
SL-SLAMのシステム構造を図2に示します。システムは主に4つのセンサー構成、つまり単眼、単眼慣性、両眼、両眼慣性を備えています。このシステムは ORB-SLAM3 をベースラインとしており、トラッキング、ローカル マッピング、ループ検出という 3 つの主要モジュールが含まれています。深層学習モデルをシステムに統合するには、SuperPoint モデルと LightGlue モデルを組み合わせた ONNX Runtime 深層学習展開フレームワークが使用されます。
各入力画像について、システムはまずそれを SuperPoint ネットワークに入力して、特徴点の確率テンソルと記述子テンソルを取得します。次に、システムは 2 つのフレームで初期化し、後続の各フレームで粗い追跡を実行します。ローカル マップを追跡することで姿勢推定をさらに改良します。追跡が失敗した場合、システムは追跡に参照フレームを使用するか、再位置化を実行して姿勢を再取得します。 LightGlue は、粗い追跡、初期化、参照フレームの追跡、および再配置中の特徴マッチングに使用されることに注意してください。これにより、正確かつ堅牢なマッチング関係が確保され、追跡の効率が向上します。
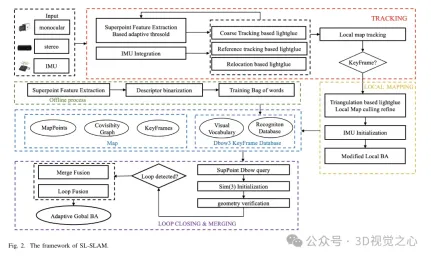
ベースライン アルゴリズムでは、ローカル マッピング スレッドの主な役割は、マップ ポイントやキー フレームを含むローカル マップをリアルタイムで動的に構築することです。ローカル マップを利用してバンドル調整の最適化を実行することで、追跡エラーを削減し、一貫性を高めます。ローカル マッピング スレッドは、追跡スレッドによって出力されたキーフレーム、LightGlue ベースの三角測量、および適応型ローカル バンドル調整 (BA) 最適化を使用して、正確なマップ ポイントを再構築します。その後、冗長なマップ ポイントとキーフレームが区別されて削除されます。
閉ループ修正スレッドは、キーフレーム データベースと、SuperPoint 記述子でトレーニングされたバッグ オブ ワード モデルを利用して、同様のキーフレームを取得します。 SuperPoint 記述子を 2 値化することにより、検索効率が向上します。選択したキーフレームは、共通ビュー ジオメトリ検証のために LightGlue を使用して特徴が一致され、不一致の可能性が軽減されます。最後に、閉ループ融合とグローバル BA (バンドル調整) が実行され、全体的な姿勢が最適化されます。
1) 特徴抽出
SuperPoint ネットワーク構造: SuperPoint ネットワーク アーキテクチャは主に、共有エンコーダー、特徴検出デコーダー、記述子デコーダーの 3 つの部分で構成されます。エンコーダは、画像のサイズを縮小し、特徴を抽出できる VGG スタイルのネットワークです。特徴検出デコーダのタスクは、画像内の各ピクセルの確率を計算して、そのピクセルが特徴点である可能性を判断することです。記述子デコード ネットワークは、サブピクセル畳み込みを利用して、デコード プロセスの計算の複雑さを軽減します。次に、ネットワークは半密記述子を出力し、バイキュービック補間アルゴリズムを適用して完全な記述子を取得します。ネットワークによって出力された特徴点テンソルと記述子テンソルを取得した後、特徴抽出の堅牢性を向上させるために、適応閾値選択戦略を採用して特徴点をフィルタリングし、後処理操作を実行して特徴点とその記述子を取得します。 。特徴抽出モジュールの具体的な構成を図3に示します。

適応特徴選択: まず、I(W × H) とラベル付けされた各画像は、SuperPoint ネットワーク次数画像の入力画像寸法 (W' × H') に一致するようにサイズ変更される前にグレーに変換されます。画像が小さすぎると特徴抽出が妨げられ、追跡パフォーマンスが低下する可能性があります。一方、画像が大きすぎると、過剰な計算要件とメモリ使用量が発生する可能性があります。したがって、特徴抽出の精度と効率のバランスをとるために、この記事では W' = 400 および H' = 300 を選択します。続いて、サイズ W' × H' のテンソルがネットワークに供給され、スコア テンソル S と記述子テンソル D の 2 つの出力テンソルが生成されます。特徴点スコア テンソルと特徴記述子が取得されたら、次のステップは、特徴点をフィルター処理するためのしきい値 th を設定することです。
困難なシナリオでは、各特徴点の信頼度が低下し、固定の信頼度しきい値 th が採用された場合、抽出される特徴の数が減少する可能性があります。この問題を解決するために、適応型 SuperPoint しきい値設定戦略を導入します。この適応手法は、シーンに基づいて特徴抽出のしきい値を動的に調整するため、困難なシーンでもより堅牢な特徴抽出を実現します。適応しきい値メカニズムでは、特徴内の関係とフレーム間の特徴の関係という 2 つの要素が考慮されます。
困難なシナリオでは、各特徴点の信頼度が低下し、固定の信頼度しきい値 th が採用された場合、抽出される特徴の数が減少する可能性があります。この問題を解決するために、適応型 SuperPoint しきい値設定戦略が導入されています。この適応手法は、シーンに基づいて特徴抽出のしきい値を動的に調整するため、困難なシーンでもより堅牢な特徴抽出を実現します。適応しきい値メカニズムでは、特徴内の関係とフレーム間の特徴の関係という 2 つの要素が考慮されます。
2) 特徴マッチングとフロントエンド
LightGlue ネットワーク構造: LightGlue モデルは、2 つの特徴セットを共同で処理する複数の同一のレイヤーで構成されます。各レイヤーには、ポイントの表現を更新するためのセルフ アテンション ユニットとクロス アテンション ユニットが含まれています。各層の分類器は推論をどこで停止するかを決定し、不必要な計算を回避します。最後に、軽量ヘッダーは部分一致スコアを計算します。ネットワークの深さは、入力画像の複雑さに基づいて動的に調整されます。画像ペアが容易に一致する場合、タグの信頼性が高いため、早期終了を達成できます。その結果、LightGlue は実行時間が短くなり、メモリ消費量が少なくなるため、リアルタイム パフォーマンスを必要とするタスクへの統合に適しています。
隣接するフレーム間の時間間隔は、通常、わずか数十ミリ秒です。ORB-SLAM3 は、この短い時間内にカメラが一定の速度で移動すると想定しています。前のフレームの姿勢と速度を使用して現在のフレームの姿勢を推定し、この推定された姿勢を投影マッチングに使用します。次に、特定の範囲内で一致するポイントを検索し、それに応じてポーズを調整します。ただし、実際にはカメラの動きは必ずしも均一ではありません。急激な加速、減速、回転はこの方法の効果に悪影響を与える可能性があります。 Lightglue は、現在のフレームと前のフレームの間で特徴を直接照合することで、この問題を効果的に解決できます。次に、これらの一致した特徴を使用して初期姿勢推定を改良し、それによって突然の加速や回転による悪影響を軽減します。
突然のカメラの動きやその他の要因により、前のフレームで画像追跡が失敗した状況では、追跡または再配置に参照キーフレームを使用する必要があります。ベースライン アルゴリズムでは、Bag-of-Words (BoW) メソッドを使用して、現在のフレームと参照フレーム間の特徴マッチングを高速化します。しかし、BoW 法は空間情報を視覚語彙に基づいた統計情報に変換するため、特徴点間の正確な空間関係が失われる可能性があります。さらに、BoW モデルで使用される視覚的語彙が不十分であるか、十分に表現されていない場合、シーンの豊かな特徴が捉えられず、マッチング プロセスが不正確になる可能性があります。
Lightglue トラッキングと組み合わせる: 隣接するフレーム間の時間間隔は非常に短く、通常はわずか数十ミリ秒であるため、ORB-SLAM3 は、この期間中にカメラが均一な速度で移動すると想定します。前のフレームの姿勢と速度を使用して現在のフレームの姿勢を推定し、この推定された姿勢を投影マッチングに使用します。次に、特定の範囲内で一致するポイントを検索し、それに応じてポーズを調整します。ただし、実際にはカメラの動きは必ずしも均一ではありません。急激な加速、減速、回転はこの方法の効果に悪影響を与える可能性があります。 Lightglue は、現在のフレームと前のフレームの間で特徴を直接照合することで、この問題を効果的に解決できます。次に、これらの一致した特徴を使用して初期姿勢推定を改良し、それによって突然の加速や回転による悪影響を軽減します。
突然のカメラの動きやその他の要因により、前のフレームで画像追跡が失敗した状況では、追跡または再配置に参照キーフレームを使用する必要があります。ベースライン アルゴリズムでは、Bag-of-Words (BoW) メソッドを使用して、現在のフレームと参照フレーム間の特徴マッチングを高速化します。しかし、BoW 法は空間情報を視覚語彙に基づいた統計情報に変換するため、特徴点間の正確な空間関係が失われる可能性があります。さらに、BoW モデルで使用される視覚的語彙が不十分であるか、十分に表現されていない場合、シーンの豊かな特徴が捉えられず、マッチング プロセスが不正確になる可能性があります。

これらの問題を解決するために、システム全体で BoW メソッドが Lightglue に置き換えられました。この変更により、大規模な変換下で追跡と再位置推定が成功する確率が大幅に向上し、それによって追跡プロセスの精度と堅牢性が向上します。図 4 は、さまざまなマッチング方法の有効性を示しています。 Lightglue に基づくマッチング方法は、ORB-SLAM3 で使用される射影または Bag-of-Words に基づくマッチング方法よりも優れたマッチング パフォーマンスを示していることがわかります。したがって、SLAM 操作中は、図 6 に示すように、マップ ポイントの追跡がより均一で安定します。

Lightglue のローカル マッピングと組み合わせる: ローカル マッピング スレッドでは、現在のキーフレームとその隣接するキーフレームを通じて新しいマップ ポイントの三角形分割が完了します。より正確なマップ ポイントを取得するには、より大きなベースラインを持つキーフレームと照合する必要があります。ただし、ORB-SLAM3 はこれを実現するために Bag-of-Words (BoW) マッチングを使用しますが、ベースラインが大きいと BoW 特徴マッチングのパフォーマンスが低下します。対照的に、Lightglue アルゴリズムは大規模なベースラインとのマッチングに適しており、システムにシームレスに統合されます。 Lightglue を使用してフィーチャ マッチングとマッチング ポイントの三角測量を行うことにより、より包括的で高品質のマップ ポイントを復元できます。
これにより、キーフレーム間の接続をより多く作成し、同時に表示されるキーフレームとマップ ポイントのポーズを共同で最適化することでトラッキングを安定させることにより、ローカル マッピング機能が強化されます。マップ ポイントの三角測量の効果を図 6 に示します。 ORB-SLAM3 と比較して、私たちの方法で構築されたマップ ポイントはシーンの構造情報をよりよく反映していることがわかります。さらに、それらは空間内により均一かつ広範囲に分布します。
3) ループクロージャ
バッグオブワード深度記述子: ループクロージャ検出で使用されるバッグオブワード手法は、視覚語彙に基づいた手法であり、バッグオブワードの概念を利用しています。自然言語処理において。まず、辞書のオフライン トレーニングを実行します。最初に、K 平均法アルゴリズムを使用して、トレーニング画像セット内で検出された特徴記述子を k セットにクラスター化し、辞書ツリーの第 1 レベルを形成します。その後、各セット内で再帰的な操作が実行され、最終的に深さ L と分岐数を持つ最終的な辞書ツリーが取得され、視覚的な語彙が確立されます。各葉ノードは語彙とみなされます。
辞書トレーニングが完了すると、アルゴリズムの実行中に現在の画像のすべての特徴点からバッグオブワードベクトルと特徴ベクトルがオンラインで生成されます。主流の SLAM フレームワークは、メモリ使用量が小さく、比較方法が単純であるため、手動で設定されたバイナリ記述子を使用する傾向があります。方法の効率をさらに向上させるために、SP ループでは、期待値 0、標準偏差 0.07 のガウス分布を使用してスーパーポイント記述子の値を表します。したがって、スーパーポイントの 256 次元浮動小数点記述子をバイナリ エンコードして、視覚的位置認識のクエリ速度を向上させることができます。バイナリエンコーディングを式 4 に示します。
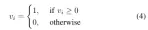
基本プロセス: SLAM のループ クロージャ検出には、通常、最初のループ クロージャ候補キーフレームの検索、ループ クロージャ候補キーフレームの検証、ループ クロージャ修正とグローバル バンドル調整 (バンドル調整、BA) の実行という 3 つの主要な段階が含まれます。
起動プロセスの最初のステップは、最初のループ クロージャ候補キーフレームを特定することです。これは、以前にトレーニングされた DBoW3 バッグオブワード モデルを活用することで実現されます。現在のフレーム Ka と語彙を共有するキーフレームが識別されますが、Ka と同時表示されるキーフレームは除外されます。これらの候補キーフレームに関連する、同時に表示されるキーフレームの合計スコアを計算します。閉ループ候補キーフレームの中で最も高いスコアを持つ上位 N グループから、最も高いスコアを持つキーフレームを選択します。この選択されたキーフレームをKmとする。
次に、Km から現在のキーフレーム Ka への相対的な姿勢変換 Tam を決定する必要があります。 ORB-SLAM3 では、バッグオブワード ベースの特徴マッチング方法を使用して、現在のキー フレームを候補キー フレーム Km およびその共通可視キー フレーム Kco と照合します。 lightglue アルゴリズムはマッチング効率を大幅に向上させるため、現在のフレームと候補フレーム Km をマッチングすると高品質のマップ ポイント対応が生成されることは注目に値します。次に、RANSAC アルゴリズムを適用して外れ値を除去し、Sim(3) 変換を解いて初期相対姿勢 Tam を決定します。誤った位置識別を回避するために、候補キーフレームが幾何学的に検証され、その後のステップは ORB-SLAM3 と同様です。
実験比較分析
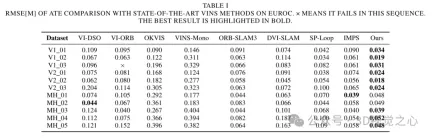
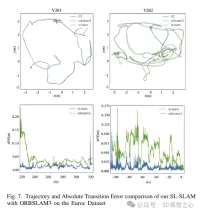


以上がORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM
革新を調理する:人工知能がフードサービスを変革する方法Apr 12, 2025 pm 12:09 PM食品の準備を強化するAI まだ初期の使用中ですが、AIシステムは食品の準備にますます使用されています。 AI駆動型のロボットは、ハンバーガーの製造、SAの組み立てなど、食品の準備タスクを自動化するためにキッチンで使用されています
 Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM
Pythonネームスペースと可変スコープに関する包括的なガイドApr 12, 2025 pm 12:00 PM導入 Python関数における変数の名前空間、スコープ、および動作を理解することは、効率的に記述し、ランタイムエラーや例外を回避するために重要です。この記事では、さまざまなASPを掘り下げます
 ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイドApr 12, 2025 am 11:58 AM導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM
MediaTekは、Kompanio UltraとDimenity 9400でプレミアムラインナップをブーストしますApr 12, 2025 am 11:52 AM製品のケイデンスを継続して、今月MediaTekは、新しいKompanio UltraやDimenity 9400を含む一連の発表を行いました。これらの製品は、スマートフォン用のチップを含むMediaTekのビジネスのより伝統的な部分を埋めます
 今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM
今週のAIで:Walmartがファッションのトレンドを設定する前に設定しますApr 12, 2025 am 11:51 AM#1 GoogleはAgent2Agentを起動しました 物語:月曜日の朝です。 AI駆動のリクルーターとして、あなたはより賢く、難しくありません。携帯電話の会社のダッシュボードにログインします。それはあなたに3つの重要な役割が調達され、吟味され、予定されていることを伝えます
 生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM
生成AIは精神障害に会いますApr 12, 2025 am 11:50 AM私はあなたがそうであるに違いないと思います。 私たちは皆、精神障害がさまざまな心理学の用語を混ぜ合わせ、しばしば理解できないか完全に無意味であることが多い、さまざまなおしゃべりで構成されていることを知っているようです。 FOを吐き出すために必要なことはすべてです
 プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM
プロトタイプ:科学者は紙をプラスチックに変えますApr 12, 2025 am 11:49 AM今週公開された新しい研究によると、2022年に製造されたプラスチックの9.5%のみがリサイクル材料から作られていました。一方、プラスチックは埋め立て地や生態系に積み上げられ続けています。 しかし、助けが近づいています。エンジンのチーム
 AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM
AIアナリストの台頭:これがAI革命で最も重要な仕事になる理由Apr 12, 2025 am 11:41 AM主要なエンタープライズ分析プラットフォームAlteryxのCEOであるAndy Macmillanとの私の最近の会話は、AI革命におけるこの重要でありながら過小評価されている役割を強調しました。 MacMillanが説明するように、生のビジネスデータとAI-Ready情報のギャップ


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

