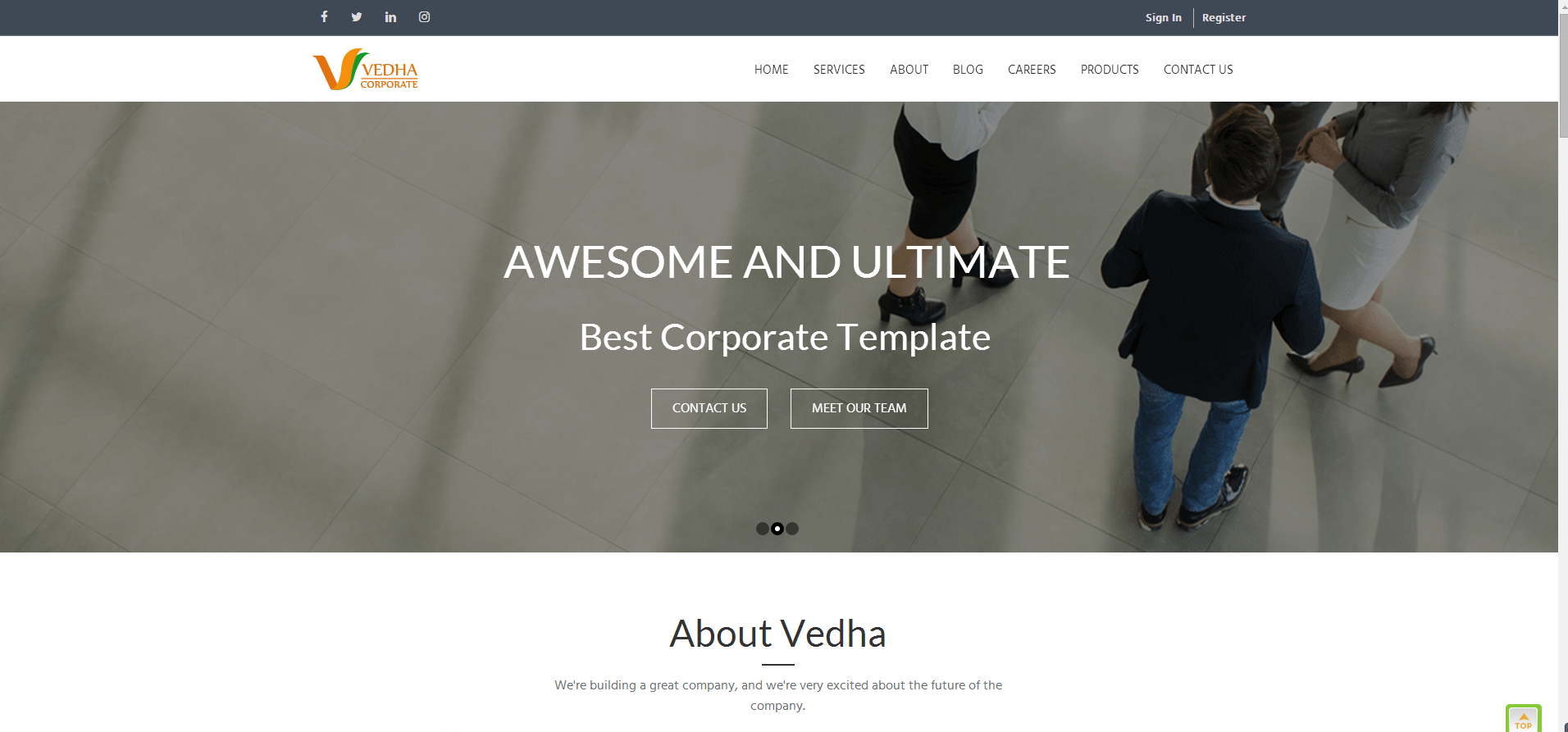
Code source du site WebModèle frontalModèle d'école professionnelle de formation en comptabilité
Code source du site WebModèle frontalModèle d'école professionnelle de formation en comptabilitéModèle d'école professionnelle de formation en comptabilité
Toutes les ressources de ce site proviennent d'internautes ou sont réimprimées par les principaux sites de téléchargement. Veuillez vérifier vous-même l'intégrité du logiciel ! Toutes les ressources de ce site sont uniquement à titre de référence d'apprentissage. Merci de ne pas les utiliser à des fins commerciales. Sinon, vous serez responsable de toutes les conséquences ! En cas d'infraction, veuillez nous contacter pour la supprimer. Coordonnées : admin@php.cn
Article connexe
 Utiliser WPF pour implémenter plusieurs fonctions de service client des comptes publics WeChat
Utiliser WPF pour implémenter plusieurs fonctions de service client des comptes publics WeChat05Mar2017
Il s'agit d'utiliser WPF comme technologie frontale pour implémenter la version de bureau du système de service multi-client WeChat. Le projet utilise Prism comme framework frontal et utilise le modèle MVVM pour séparer efficacement l'interface utilisateur et le code logique.
 Quel est l'objectif et la fonctionnalité d'un contrôleur frontal dans les applications PHP ?
Quel est l'objectif et la fonctionnalité d'un contrôleur frontal dans les applications PHP ?23Oct2024
Ce guide explique le modèle de conception Front Controller, couramment utilisé dans les applications PHP pour gérer les requêtes. Il agit comme un point d'entrée centralisé pour toutes les demandes, facilitant le routage, la création de modèles et la sécurité. Le contrôleur frontal assure une
 Laravel et la pile complète: avant et dos ensemble
Laravel et la pile complète: avant et dos ensemble18Apr2025
Laravel réalise le développement complet à travers le moteur du modèle de lame, l'éloquente, les outils artisanaux et Laravelmix: 1. La lame simplifie le développement frontal; 2. Eloquent simplifie les opérations de base de données; 3. Artisan améliore l'efficacité du développement; 4. Laravelmix gère les ressources frontales.
 Angularjs
Angularjs23Feb2025
Points de base AngularJS, un framework JavaScript développé par Google, permet aux développeurs de créer du code frontal sans avoir à manipuler directement le modèle d'objet de document (DOM). Cela peut être réalisé en définissant des vues et des contrôleurs dynamiques à l'aide d'instructions et de liaison des données. AngularJS utilise la structure MVC (modèle-View-Controller). Le modèle est défini par des modules et des contrôleurs angulaires connectés au HTML via des instructions. Cela permet la liaison des données bidirectionnelle, où les modifications du modèle mettent automatiquement à jour la vue et vice versa. Dans AngularJS, les directives étendent le vocabulaire HTML, fournissant des mods plus dynamiques et puissants
 Frontend avec Laravel: Explorer les possibilités
Frontend avec Laravel: Explorer les possibilités20Apr2025
Laravel peut être utilisé pour le développement frontal. 1) Utilisez le moteur du modèle de lame pour générer du HTML. 2) Intégrez Vite pour gérer les ressources frontales. 3) Construisez SPA, PWA ou site Web statique. 4) Combinez le routage, le middleware et l'éloquente pour créer une application Web complète.
 Comment puis-je accéder aux ressources statiques avec un servlet Global Front Controller mappé sur /* ?
Comment puis-je accéder aux ressources statiques avec un servlet Global Front Controller mappé sur /* ?08Dec2024
Servlet de contrôleur frontal global sur /* : résolution de l'accès aux ressources statiquesLors du mappage d'un servlet de contrôleur frontal global sur /*, il devient un...
 Comment servir des ressources statiques lors de l'utilisation d'un servlet de contrôleur frontal global mappé sur /* ?
Comment servir des ressources statiques lors de l'utilisation d'un servlet de contrôleur frontal global mappé sur /* ?18Dec2024
Accès aux ressources statiques avec un servlet de contrôleur frontal global mappé sur /*Mappage d'un servlet de contrôleur frontal global, tel que Spring MVC...
 Comment accéder aux ressources statiques avec un servlet Global Front Controller mappé sur /* ?
Comment accéder aux ressources statiques avec un servlet Global Front Controller mappé sur /* ?04Dec2024
Accès aux ressources statiques lors du mappage du servlet du contrôleur frontal global sur /*Le mappage d'un servlet du contrôleur frontal global sur /* peut empêcher...



Outils chauds