



用的语言是python。目前想要爬的同花顺股票行情(http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860),又一次被javascript卡住。因为一页中只显示52条信息,想要看全部的股票数据必须点击下面的页码,是用javascript写的,无法直接用urllib2之类的库处理。试过用webkit(ghost.py)来模拟点击,代码如下:
page, resources = ghost.open('http://q.10jqka.com.cn/stock/fl/#refCountId=db_5093800d_645,db_509381c1_860')
page, resources = ghost.evaluate("document.getElementById('hd').nextSibling.getElementsByTagName('div')[13].getElementsByTagName('a')[7].click();", expect_loading = True)
提示Unable to load requested page, 或是返回的page是None。不知道无法解决。求教是代码哪里错了,应该如何解决?(在百度和google找了很久解决方法,不过有关ghost.py的资料不是太多,没能解决。)
以及,求问是否有更好的办法解决爬动态网页的问题?用webkit模拟好像会减慢爬的速度,不是上策。
回复内容:
Headless Webkit,开源的有 PhantomJS 等。能够解析并运行页面上的脚本以索引动态内容是现代爬虫的重要功能之一。
Google's Crawler Now Understands JavaScript: What Does This Mean For You?
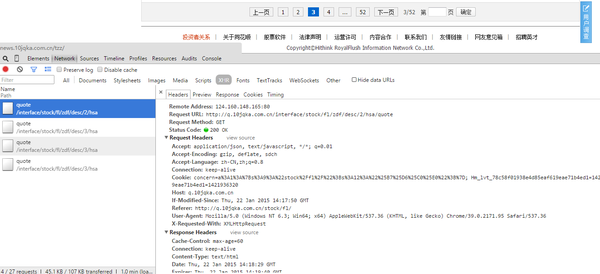

你这个爬虫跟JS关系不大,直接看Network,看发出的网络请求,分析每个URL,找出规律,然后用程序来模拟这样的请求,首先要善于用Chrome的Network功能,我们点几页,看Network如下:
第一页数据URL:
http://q.10jqka.com.cn/interface/stock/fl/zdf/desc/1/hsa/quote
我手上正好有个比较好的例子。需求:爬取爱漫画上的漫画。
问题:图片的名字命名不规则,通过复杂的js代码生成图片的文件名和url,动态加载图片。js代码的模式多样,没有统一的模式。
解决:Py8v库。读取下js代码,加一个全局变量追踪图片的文件名和url,然后Python和这个变量交互,取得某话图片的文件名和url。
全文在此
【原创】最近写的一个比较hack的小爬虫 能说 berserkJS 么……
不过这种玩意可抗不了量啊
╭(╯ε╰)╮ 嫌麻烦的话直接上selenium吧,几乎百分百地模拟用户在浏览器上的操作。也可以用来爬数据,不过速度较慢。 打开Chrome的开发人员控制台或者火狐的FireBug,转到Network那一栏,直接分析ajax访问的url到底是哪些。
对于特定网站的爬虫就不要想着模拟javascript运行了,太费力而且效果还不好。把网站的url结构弄明白了直接构造表单就好。 Selenium with Python 插一句题外话,同花顺好像可以自定义函数,写脚本计算数据,还是挺方便的,一定要自己把数据全部爬下来吗? phantomjs api比较吐血,建议基于之上封装的casperjs吧,写起来比较爽 一个好的爬虫需要解决两个问题:
1、能够解析动态网页,比如瀑布式网站
2、能够规避网站的封锁

 Python vs C: applications et cas d'utilisation comparésApr 12, 2025 am 12:01 AM
Python vs C: applications et cas d'utilisation comparésApr 12, 2025 am 12:01 AMPython convient à la science des données, au développement Web et aux tâches d'automatisation, tandis que C convient à la programmation système, au développement de jeux et aux systèmes intégrés. Python est connu pour sa simplicité et son écosystème puissant, tandis que C est connu pour ses capacités de contrôle élevées et sous-jacentes.
 Le plan Python de 2 heures: une approche réalisteApr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réalisteApr 11, 2025 am 12:04 AMVous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Python: Explorer ses applications principalesApr 10, 2025 am 09:41 AM
Python: Explorer ses applications principalesApr 10, 2025 am 09:41 AMPython est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Combien de python pouvez-vous apprendre en 2 heures?Apr 09, 2025 pm 04:33 PM
Combien de python pouvez-vous apprendre en 2 heures?Apr 09, 2025 pm 04:33 PMVous pouvez apprendre les bases de Python dans les deux heures. 1. Apprenez les variables et les types de données, 2. Structures de contrôle maître telles que si les instructions et les boucles, 3. Comprenez la définition et l'utilisation des fonctions. Ceux-ci vous aideront à commencer à écrire des programmes Python simples.
 Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?Apr 02, 2025 am 07:18 AMComment enseigner les bases de la programmation novice en informatique dans les 10 heures? Si vous n'avez que 10 heures pour enseigner à l'informatique novice des connaissances en programmation, que choisissez-vous d'enseigner ...
 Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?Apr 02, 2025 am 07:15 AMComment éviter d'être détecté lors de l'utilisation de FiddlereVerywhere pour les lectures d'homme dans le milieu lorsque vous utilisez FiddlereVerywhere ...
 Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?Apr 02, 2025 am 07:12 AM
Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?Apr 02, 2025 am 07:12 AMChargement des fichiers de cornichons dans Python 3.6 Rapport de l'environnement Erreur: modulenotFoundError: NomoduLenamed ...
 Comment améliorer la précision de la segmentation des mots jieba dans l'analyse des commentaires pittoresques?Apr 02, 2025 am 07:09 AM
Comment améliorer la précision de la segmentation des mots jieba dans l'analyse des commentaires pittoresques?Apr 02, 2025 am 07:09 AMComment résoudre le problème de la segmentation des mots jieba dans l'analyse des commentaires pittoresques? Lorsque nous effectuons des commentaires et des analyses pittoresques, nous utilisons souvent l'outil de segmentation des mots jieba pour traiter le texte ...


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

mPDF
mPDF est une bibliothèque PHP qui peut générer des fichiers PDF à partir de HTML encodé en UTF-8. L'auteur original, Ian Back, a écrit mPDF pour générer des fichiers PDF « à la volée » depuis son site Web et gérer différentes langues. Il est plus lent et produit des fichiers plus volumineux lors de l'utilisation de polices Unicode que les scripts originaux comme HTML2FPDF, mais prend en charge les styles CSS, etc. et présente de nombreuses améliorations. Prend en charge presque toutes les langues, y compris RTL (arabe et hébreu) et CJK (chinois, japonais et coréen). Prend en charge les éléments imbriqués au niveau du bloc (tels que P, DIV),

Version crackée d'EditPlus en chinois
Petite taille, coloration syntaxique, ne prend pas en charge la fonction d'invite de code

