
Maison >Périphériques technologiques >IA >Xiaohongshu interprète la récupération d'informations à partir du mécanisme de mémoire et propose un nouveau paradigme pour obtenir EACL Oral
Xiaohongshu interprète la récupération d'informations à partir du mécanisme de mémoire et propose un nouveau paradigme pour obtenir EACL Oral

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-29 16:16:071340parcourir

Récemment, l'article "Generative Dense Retrieval: Memory Can Be a Burden" de l'équipe d'algorithmes de recherche de Xiaohongshu a été accepté comme oral par l'EACL 2024, une conférence internationale dans le domaine du traitement du langage naturel, avec un taux d'acceptation de 11,32% (144/1271).
Dans leur article, ils ont proposé un nouveau paradigme de recherche d'informations : la récupération dense générative (GDR). Ce paradigme peut bien résoudre les défis rencontrés par la récupération générative (GR) traditionnelle lors du traitement d'ensembles de données à grande échelle. Il s'inspire du mécanisme de la mémoire.
Dans la pratique passée, GR s'appuyait sur son mécanisme de mémoire unique pour réaliser une interaction approfondie entre les requêtes et les bibliothèques de documents. Cependant, cette méthode qui s'appuie sur le codage autorégressif d'un modèle de langage présente des limites évidentes lors du traitement de données à grande échelle, notamment des fonctionnalités de document floues et à granularité fine, une taille limitée de la bibliothèque de documents et des difficultés de mise à jour de l'index.
Le GDR proposé par Xiaohongshu adopte une idée de récupération en deux étapes, de grossière à fine. Il utilise d'abord la capacité de mémoire limitée du modèle de langage pour réaliser le mappage des requêtes aux documents, puis utilise le mécanisme de correspondance vectorielle pour. compléter le mappage de documents à documents. Le GDR atténue efficacement les inconvénients inhérents au GR en introduisant un mécanisme de correspondance vectorielle pour la récupération d'ensembles denses.
De plus, l'équipe a également conçu une « stratégie de construction d'identifiant de cluster de documents conviviale » et une « stratégie d'échantillonnage négatif adaptatif de cluster de documents » pour améliorer les performances de récupération des deux étapes respectivement. Dans plusieurs paramètres de l'ensemble de données Natural Questions, GDR a non seulement démontré les performances de Recall@k de SOTA, mais a également atteint une bonne évolutivité tout en conservant les avantages d'une interaction profonde, ouvrant ainsi de nouvelles possibilités pour de futures recherches sur la recherche d'informations sur le sexe.
1.Contexte
Les outils de recherche de texte ont une valeur de recherche et d'application importante. Les paradigmes de recherche traditionnels, tels que la récupération clairsemée (SR) basée sur la correspondance de mots et la récupération dense (DR) basée sur la correspondance de vecteurs sémantiques, bien que chacun ait ses propres mérites, avec la montée en puissance de modèles de langage pré-entraînés, basés sur cela. Un paradigme a commencé à émerger. Les débuts du paradigme de récupération générative étaient principalement basés sur des correspondances sémantiques entre requêtes et documents candidats. En mappant les requêtes et les documents dans le même espace sémantique, le problème de récupération des documents candidats se transforme en une récupération dense de degrés de correspondance vectorielle. Ce paradigme de récupération révolutionnaire tire parti de modèles linguistiques pré-entraînés et ouvre de nouvelles opportunités dans le domaine de la recherche de texte. Cependant, le paradigme de la récupération générative reste confronté à des défis. D'une part, la pré-formation existante
Pendant le processus de formation, le modèle génère de manière autorégressive des identifiants de documents pertinents avec une requête donnée comme contexte. Ce processus permet au modèle de mémoriser le corpus candidat. Une fois que la requête entre dans le modèle, elle interagit avec les paramètres du modèle et est décodée de manière autorégressive, ce qui produit implicitement une interaction profonde entre la requête et le corpus candidat, et cette interaction profonde est exactement ce qui manque à SR et DR. Par conséquent, GR peut montrer d’excellentes performances de récupération lorsque le modèle peut mémoriser avec précision les documents candidats.
Bien que le mécanisme de mémoire de GR ne soit pas impeccable. Grâce à des expériences comparatives entre le modèle DR classique (AR2) et le modèle GR (NCI), nous avons confirmé que le mécanisme de mémoire apportera au moins trois défis majeurs :
1) Flou des fonctionnalités de document à grain fin :
Nous avons respectivement calculé la probabilité que NCI et AR2 fassent une erreur lors du décodage de chaque bit de l'identifiant du document de grossier à fin. Pour AR2, nous trouvons l'identifiant correspondant au document le plus pertinent pour une requête donnée grâce à la correspondance vectorielle, puis comptons les premiers pas d'erreur de l'identifiant pour obtenir le taux d'erreur de décodage étape par étape correspondant à AR2. Comme le montre le tableau 1, NCI fonctionne bien dans la première moitié du décodage, tandis que le taux d'erreur est plus élevé dans la seconde moitié, et l'inverse est vrai pour AR2. Cela montre que NCI peut mieux compléter la cartographie à gros grain de l'espace sémantique des documents candidats via la base de données mémoire globale. Cependant, étant donné que les caractéristiques sélectionnées au cours du processus de formation sont déterminées par la recherche, sa cartographie à granularité fine est difficile à mémoriser avec précision, elle fonctionne donc mal dans une cartographie à granularité fine.

2) La taille de la bibliothèque de documents est limitée :
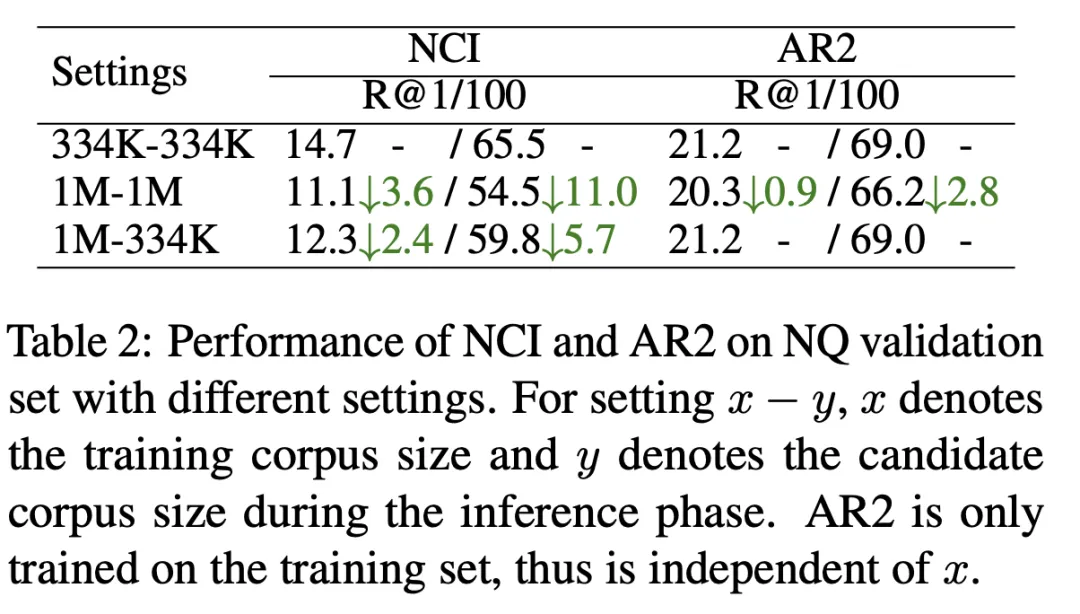
Comme le montre le tableau 2, nous avons formé le modèle NCI avec une taille de bibliothèque de documents candidats de 334 Ko (première ligne) et une taille de document candidat de 1 M (deuxième ligne) et testé avec indicateur R@k. Les résultats montrent que NCI a perdu 11 points sur R@100, par rapport à AR2 qui n'a perdu que 2,8 points. Afin d'explorer la raison pour laquelle les performances NCI diminuent considérablement à mesure que la taille de la bibliothèque de documents candidats augmente, nous avons testé en outre les résultats des tests du modèle NCI formé sur la bibliothèque de documents 1M lors de l'utilisation de 334 Ko comme bibliothèque de documents candidats (troisième ligne). Par rapport à la première ligne, la charge du NCI consistant à mémoriser davantage de documents entraîne une diminution significative de ses performances de rappel, ce qui indique que la capacité de mémoire limitée du modèle limite sa capacité à mémoriser des bibliothèques de documents candidats à grande échelle.
3) Difficulté de mise à jour de l'index :
Lorsqu'un nouveau document doit être ajouté à la bibliothèque candidate, l'identifiant du document doit être mis à jour et le modèle doit être recyclé pour être réenregistré. -mémoriser tous les documents. Sinon, des mappages obsolètes (requête vers l'identifiant du document et identifiant du document vers le document) réduiront considérablement les performances de récupération.
Les problèmes ci-dessus entravent l'application du GR dans des scénarios réels. Pour cette raison, après analyse, nous pensons que le mécanisme d'appariement de DR a une relation complémentaire avec le mécanisme de mémoire, nous envisageons donc de l'introduire dans GR pour conserver le mécanisme de mémoire tout en supprimant ses inconvénients. Nous avons proposé un nouveau paradigme de récupération dense générative (GDR) :
- Nous avons conçu un cadre global de récupération en deux étapes, de grossier à fin, en utilisant le mécanisme de mémoire pour réaliser une correspondance inter-clusters (requête vers document cluster Mapping ), et la mise en correspondance intra-cluster (mappage des groupes de documents vers les documents) est réalisée via le mécanisme de mise en correspondance vectorielle.
- Afin d'aider le modèle à mémoriser la bibliothèque de documents candidats, nous avons construit une stratégie de construction d'identifiant de cluster de documents conviviale pour contrôler la granularité de division des clusters de documents en fonction de la capacité de mémoire du modèle et améliorer la correspondance inter-clusters. effet.
- Dans la phase de formation, nous proposons une stratégie d'échantillonnage négatif adaptatif pour les grappes de documents basée sur les caractéristiques de la récupération en deux étapes, qui améliore le poids des échantillons négatifs au sein de la grappe et augmente l'effet d'appariement au sein de la grappe.
2.1 Correspondance inter-clusters basée sur un mécanisme de mémoire
En prenant la requête en entrée, nous utilisons le modèle de langage pour mémoriser la bibliothèque de documents candidate et générons de manière autorégressive k clusters de documents associés (CID) pour compléter le mappage suivant :
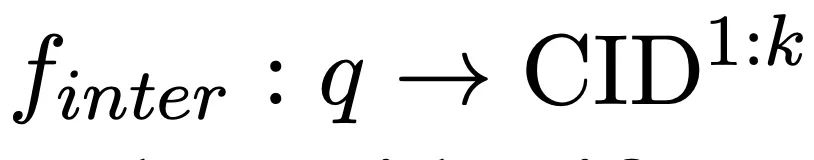
Dans ce processus, la probabilité de génération du CID est :
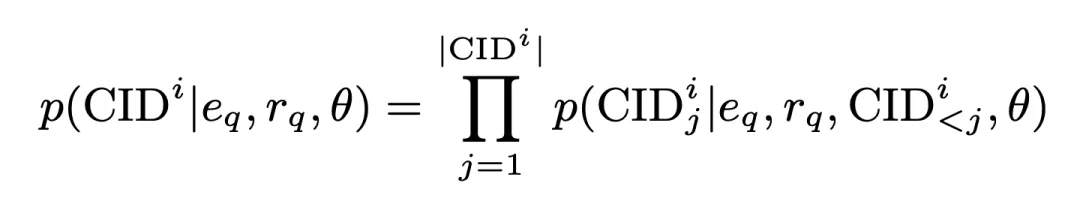
où
sont tous les intégrations de requêtes générées par l'encodeur, en est-il un généré par l'encodeur Représentation de requête dimensionnelle. Cette probabilité est également stockée sous forme de score de correspondance inter-clusters et participe aux opérations ultérieures. Sur cette base, nous utilisons une perte d'entropie croisée standard pour entraîner le modèle :
2.2 Correspondance intra-cluster basée sur un mécanisme de correspondance vectorielle 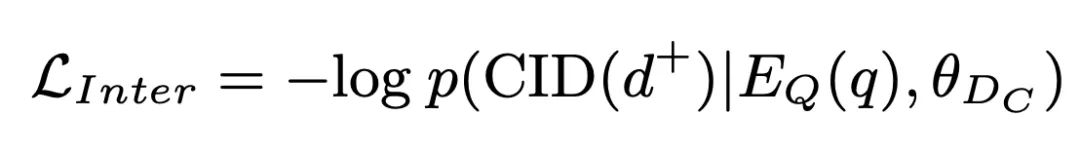
Nous récupérons en outre les documents candidats à partir des clusters de documents candidats et complétons l'intra- correspondance de cluster :
Nous introduisons un encodeur de documents pour extraire la représentation des documents candidats, et ce processus sera complété hors ligne. Sur cette base, calculez la similarité entre les documents du cluster et la requête comme score de correspondance intra-cluster : 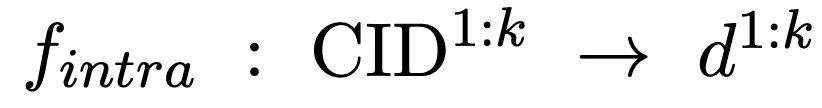
Dans ce processus, la perte NLL est utilisée pour entraîner le modèle : 
Enfin, nous calculons la valeur pondérée du score de correspondance inter-cluster et du score de correspondance intra-cluster du document et les trions, et sélectionnons le Top K comme documents pertinents récupérés : 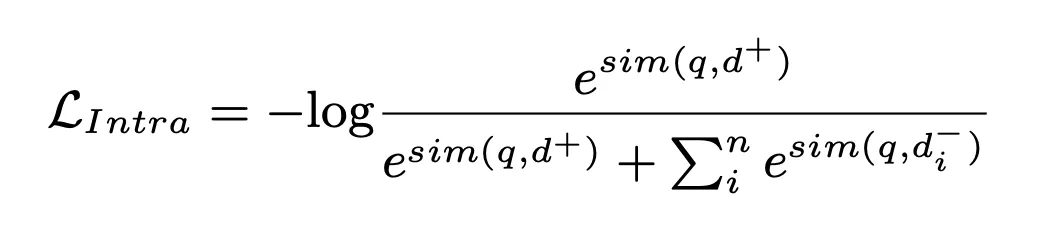
où bêta est défini dans notre expérience Réglé sur 1. 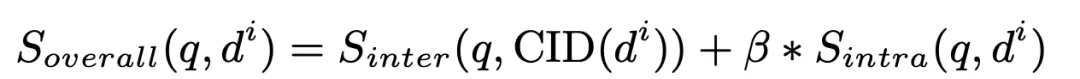
2.3 Stratégie de construction d'identifiants de cluster de documents respectueux de la mémoire
Afin d'utiliser pleinement la capacité de mémoire limitée du modèle pour obtenir une interaction profonde entre la requête et la bibliothèque de documents candidate, nous proposons un cluster de documents respectueux de la mémoire stratégie de construction d’identifiant. Cette stratégie utilise d'abord la capacité de mémoire du modèle comme référence pour calculer la limite supérieure du nombre de documents dans le cluster :
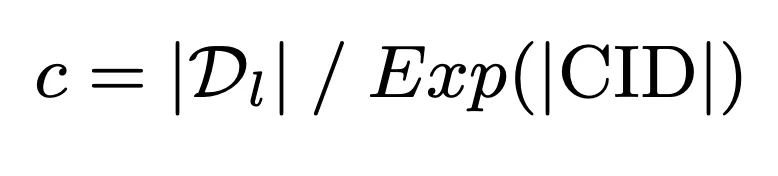
Sur cette base, l'identifiant du cluster de documents est ensuite construit via l'algorithme K-means pour s'assurer que la charge de mémoire du modèle ne dépasse pas sa capacité de mémoire :

2.4 Stratégie d'échantillonnage négatif adaptatif du cluster de documents
GDR Le cadre de récupération en deux étapes détermine que les échantillons négatifs au sein du cluster représentent une plus grande proportion dans le processus d’appariement intra-cluster. À cette fin, nous utilisons la division des clusters de documents comme référence dans la deuxième étape de la formation pour améliorer explicitement le poids des échantillons négatifs au sein du cluster, obtenant ainsi de meilleurs résultats de correspondance intra-cluster :
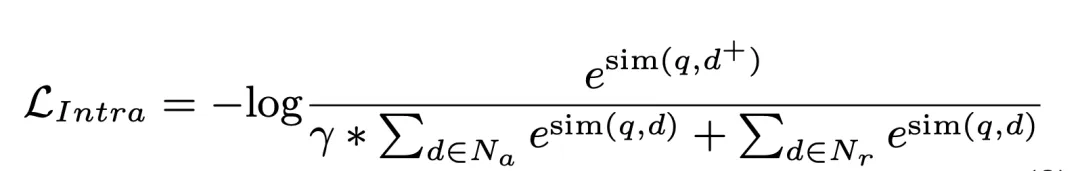
3. Expériences
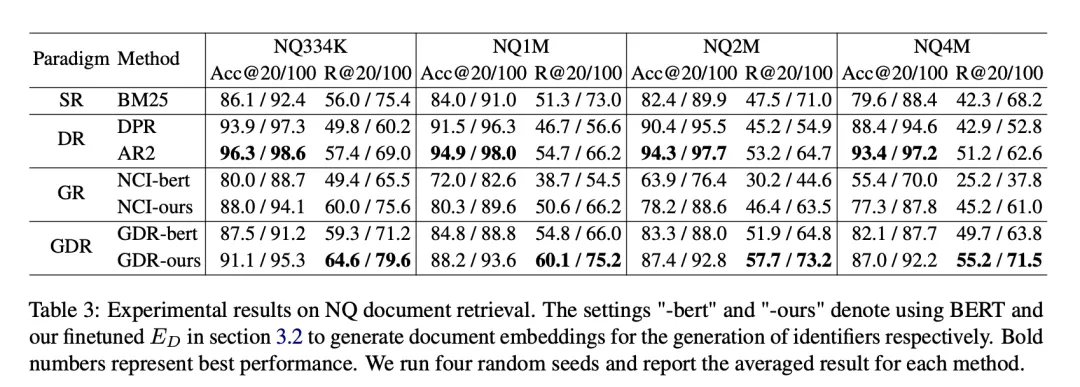
L'ensemble de données utilisé dans les expériences est Natural Questions (NQ), qui contient 58 000 paires de formation (requêtes et documents associés) et 6 000 paires de validation, accompagnées d'une bibliothèque de documents candidats de 21 millions. Chaque requête comporte plusieurs documents associés, ce qui impose des exigences plus élevées en matière de performances de rappel du modèle. Pour évaluer les performances de GDR sur des bases de documents de différentes tailles, nous avons construit différents paramètres tels que NQ334K, NQ1M, NQ2M et NQ4M en ajoutant les passages restants du corpus complet 21M à NQ334K. GDR génère des CID sur chaque ensemble de données séparément pour empêcher les informations sémantiques de la plus grande bibliothèque de documents candidats de s'infiltrer dans le plus petit corpus. Nous adoptons BM25 (implémentation d'Anserini) comme référence SR, DPR et AR2 comme référence DR et NCI comme référence GR. Les mesures d'évaluation incluent R@k et Acc@k.
3.1 Principaux résultats de l'expérience
Sur l'ensemble de données NQ, GDR s'améliore en moyenne de 3,0 sur la métrique R@k et se classe deuxième sur la métrique Acc@k. Cela montre que le GDR maximise les avantages du mécanisme de mémoire dans l'interaction profonde et du mécanisme de correspondance dans la discrimination des caractéristiques à granularité fine grâce à un processus de récupération grossier à fin.
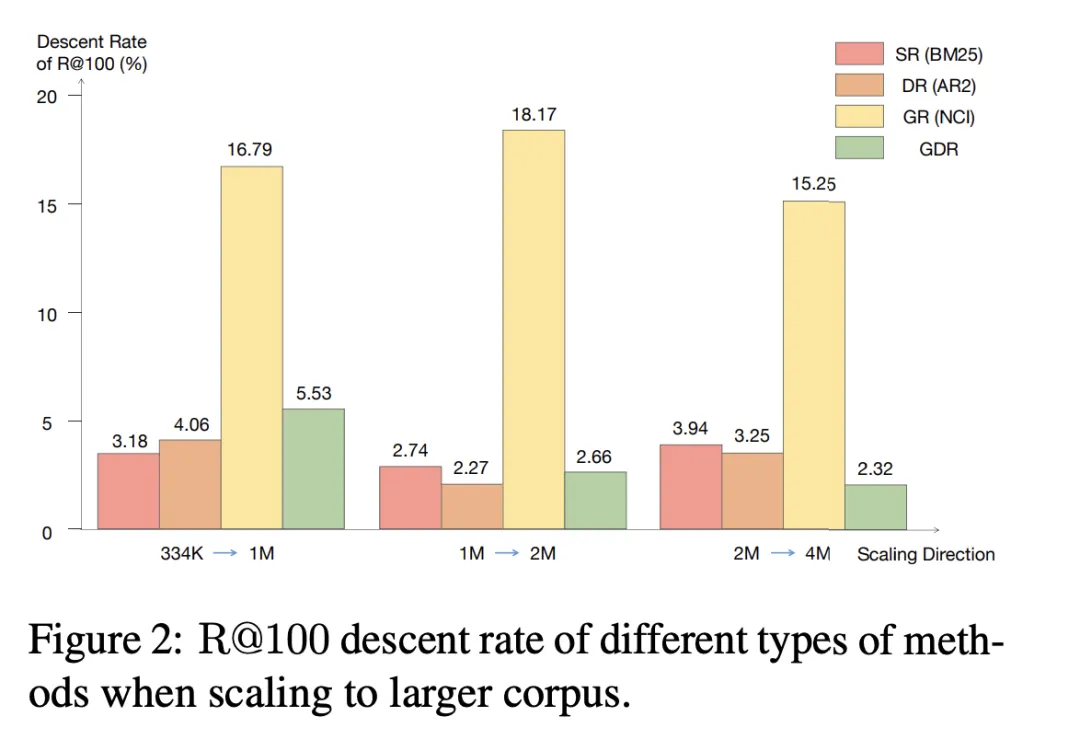
3.2 Mise à l'échelle vers un corpus plus grand
Nous remarquons que lorsque le corpus candidat est mis à l'échelle vers une taille plus grande, le taux de réduction R@100 de SR et DR reste inférieur à 4,06%, tandis que GR est le le taux de déclin dans les trois directions d’expansion dépasse 15,25 %. En revanche, GDR atteint un taux de réduction R@100 moyen de 3,50 %, ce qui est similaire à SR et DR en concentrant le contenu de la mémoire sur un volume fixe de fonctionnalités à gros grains du corpus.
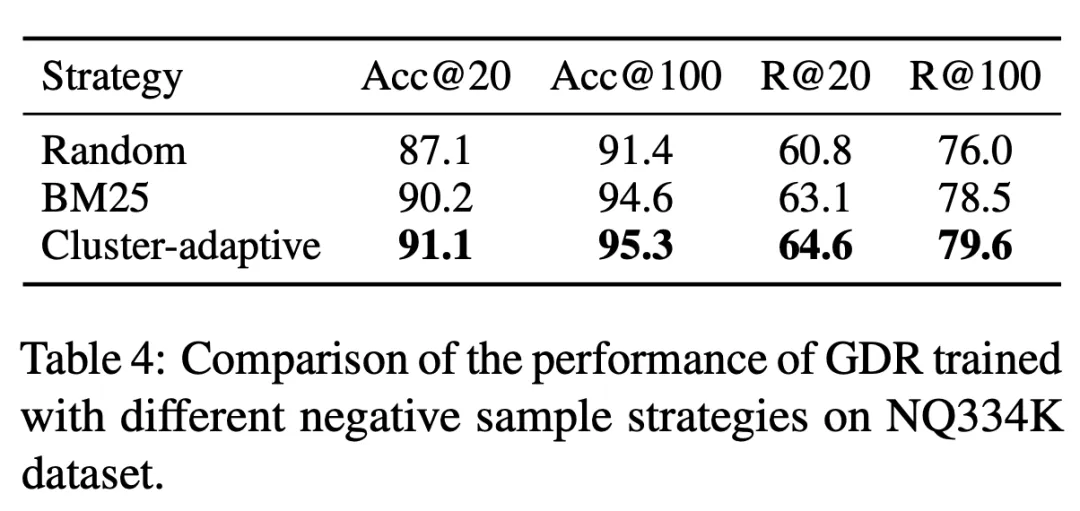
3.3 Expérience d'ablation
Tableau 3 GDR-bert et GDR-notre représentent respectivement les performances du modèle correspondant dans le cadre des stratégies de construction traditionnelles et CID. L'expérience prouve que l'utilisation de la mémoire-. documents conviviaux La stratégie de construction d'identifiant de cluster peut réduire considérablement la charge de mémoire, conduisant ainsi à de meilleures performances de récupération. De plus, le tableau 4 montre que la stratégie d'échantillonnage négatif adaptatif des groupes de documents utilisée dans la formation GDR améliore les capacités de correspondance fine en fournissant des signaux plus discriminants au sein des groupes de documents.
3.4 Nouveau document ajouté
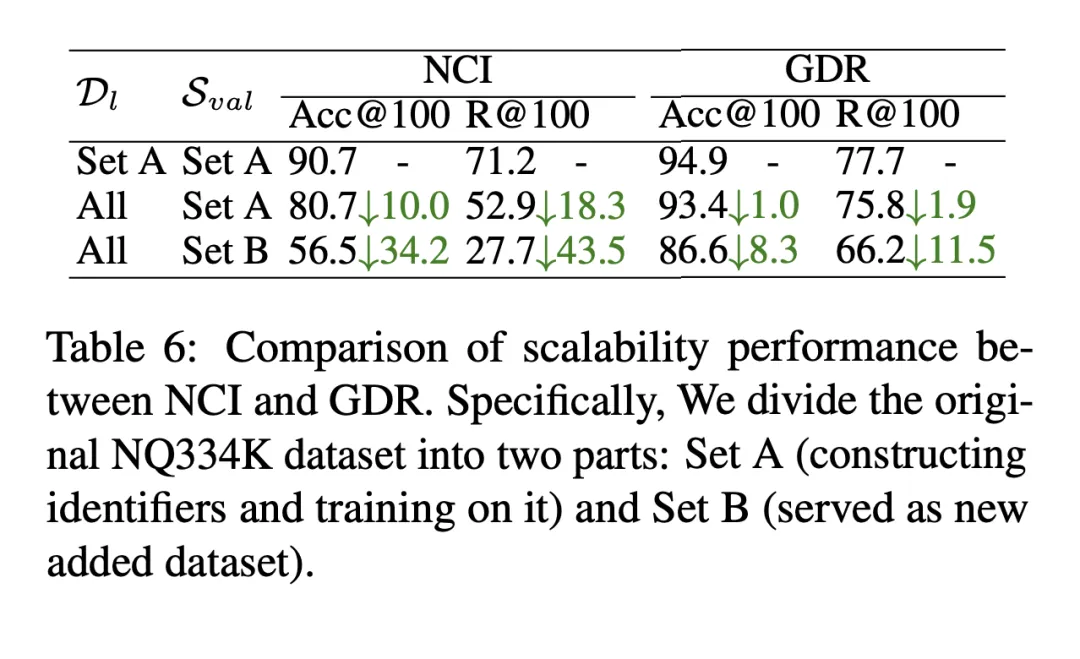
Lorsqu'un nouveau document est ajouté à la bibliothèque de documents candidats, GDR ajoutera le nouveau document au centre de cluster de documents le plus proche et lui attribuera l'identifiant correspondant, et en même temps, grâce à l'encodeur de documents, il extrait les représentations vectorielles et met à jour les index vectoriels, complétant ainsi l'expansion rapide de nouveaux documents. Comme le montre le tableau 6, dans le cadre de l'ajout de nouveaux documents au corpus candidat, le R@100 du NCI chute de 18,3 points de pourcentage, tandis que la performance du GDR ne baisse que de 1,9 point de pourcentage. Cela montre que GDR atténue la difficile évolutivité du mécanisme de mémoire en introduisant un mécanisme de correspondance et maintient de bons effets de rappel sans recycler le modèle.
3.5 Limitations
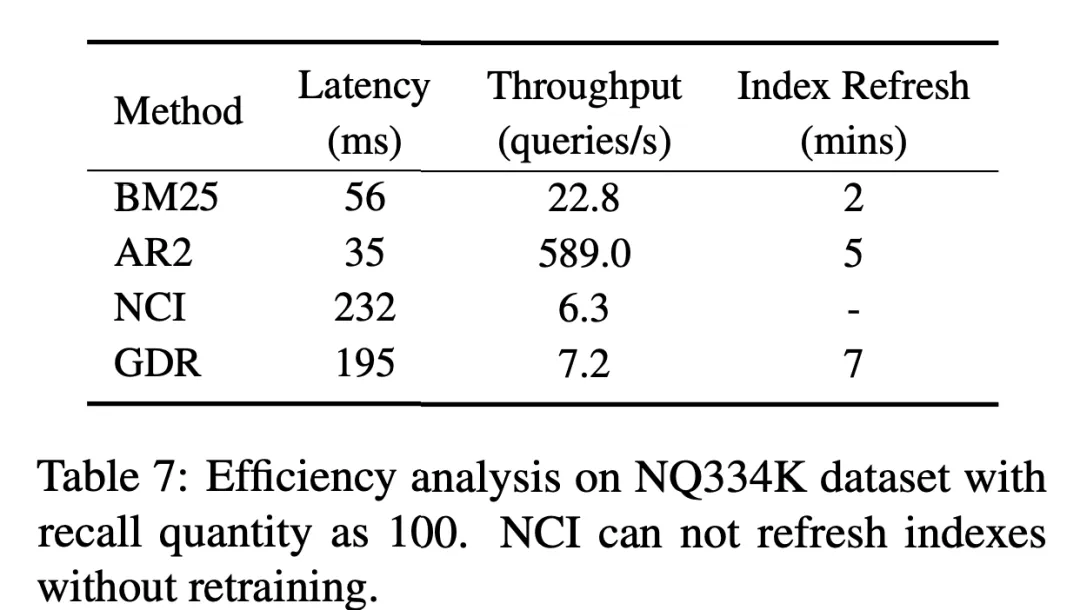
Limité par les caractéristiques de la génération autorégressive du modèle de langage, bien que GDR introduise un mécanisme de correspondance vectorielle dans la deuxième étape, qui permet d'obtenir une amélioration significative de l'efficacité de la récupération par rapport au GR, mais par rapport au DR Il y a encore beaucoup de possibilité d'amélioration avec SR. Nous attendons avec impatience d'autres recherches à l'avenir pour aider à atténuer le problème de retard causé par l'introduction de mécanismes de mémoire dans le cadre de récupération.
4. Conclusion
Dans cette étude, nous avons exploré en profondeur l'effet d'épée à double tranchant du mécanisme de mémoire dans la recherche d'informations : d'une part, ce mécanisme permet une interaction profonde entre la requête et le candidat. bibliothèque de documents ; elle compense les inconvénients de la recherche intensive ; d'autre part, la capacité de mémoire limitée du modèle et la complexité de la mise à jour de l'index rendent difficile le traitement de bibliothèques de documents candidats à grande échelle et évoluant de manière dynamique. Afin de résoudre ce problème, nous combinons de manière innovante le mécanisme de mémoire et le mécanisme de correspondance vectorielle de manière hiérarchique, afin que les deux puissent maximiser leurs forces, éviter leurs faiblesses et se compléter.
Nous proposons un nouveau paradigme de récupération de texte, Generative Dense Retrieval (GDR). GDR Ce paradigme effectue une récupération en deux étapes, de grossière à fine pour une requête donnée. Tout d'abord, le mécanisme de mémoire génère de manière autorégressive des identifiants de cluster de documents pour mapper la requête aux clusters de documents, puis le mécanisme de correspondance vectorielle calcule la relation entre les la requête et le document. La similarité complète le mappage des clusters de documents aux documents.
La stratégie de construction d'identifiants de cluster de documents respectueuse de la mémoire garantit que la charge de mémoire du modèle ne dépasse pas sa capacité de mémoire et augmente l'effet de correspondance inter-clusters. La stratégie d'échantillonnage négatif adaptatif du cluster de documents améliore le signal d'entraînement pour distinguer les échantillons négatifs au sein du cluster et augmente l'effet de correspondance au sein du cluster. Des expériences approfondies ont prouvé que GDR peut atteindre d'excellentes performances de récupération sur des bibliothèques de documents candidates à grande échelle et peut répondre efficacement aux mises à jour des bibliothèques de documents.
En tant que tentative réussie d'intégrer les avantages des méthodes de récupération traditionnelles, le paradigme de récupération intensive générative présente les avantages d'une bonne performance de rappel, d'une forte évolutivité et de performances robustes dans des scénarios avec d'énormes bibliothèques de documents candidats. À mesure que les grands modèles linguistiques continuent d’améliorer leurs capacités de compréhension et de génération, les performances de la récupération générative intensive seront encore améliorées, ouvrant ainsi un monde plus vaste pour la récupération d’informations.
Adresse papier : https://www.php.cn/link/9e69fd6d1c5d1cef75ffbe159c1f322e
5.
Yuan Peiwen
-
maintenant Ph.D. A étudié à l'Institut de technologie de Pékin, a travaillé comme stagiaire dans l'équipe de recherche communautaire de Xiaohongshu et a publié de nombreux articles de premier auteur dans NeurIPS, ICLR, AAAI, EACL, etc. Les principales directions de recherche sont le raisonnement et l'évaluation de grands modèles de langage, ainsi que la recherche d'informations. 王星霖 -
Actuellement étudiant à l'Institut de technologie de Pékin, stagiaire au sein du Xiaohongshu Community Search Group, a publié plusieurs articles dans EACL, NeurIPS, ICLR, etc., et a participé à l'International Dialogue Technology Défi DSTC11 A remporté la deuxième place sur la piste d'évaluation. Les principales directions de recherche sont le raisonnement et l'évaluation de grands modèles de langage, ainsi que la recherche d'informations. Feng Shaoxiong -
est responsable du rappel des vecteurs de recherche de la communauté Xiaohongshu. Diplômé de l'Institut de technologie de Pékin avec un doctorat, il a publié plusieurs articles dans des conférences/revues de premier plan dans le domaine de l'apprentissage automatique et du traitement du langage naturel telles que ICLR, AAAI, ACL, EMNLP, NAACL, EACL, KBS, etc. . Les principales directions de recherche comprennent l'évaluation de grands modèles de langage, la distillation d'inférence, la récupération générative, la génération de dialogues en domaine ouvert, etc.
Daoxuan -
Chef de l'équipe de recherche de transactions Xiaohongshu. Diplômé d'un doctorat de l'Université du Zhejiang, il a publié plusieurs articles de premier auteur lors de conférences de premier plan dans le domaine de l'apprentissage automatique telles que NeurIPS et ICML, et a longtemps été critique pour de nombreuses conférences/revues de premier plan. L'activité principale couvre la recherche de contenu, la recherche de commerce électronique, la recherche de diffusion en direct, etc.
Zeng Shu -
est diplômé du Département d'électronique de l'Université Tsinghua avec une maîtrise. Il est engagé dans des travaux d'algorithme dans le traitement du langage naturel, la recommandation, la recherche et d'autres domaines connexes dans le domaine d'Internet. actuellement responsable du rappel et de la recherche verticale dans la recherche communautaire de Xiaohongshu et d'autres directions techniques.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une revue récemment publiée des modèles linguistiques à grande échelle : la revue la plus complète de T5 à GPT-4, rédigée conjointement par plus de 20 chercheurs nationaux
- L'auteur d'un article est populaire. Quand les grands modèles de langage tels que ChatGPT peuvent-ils devenir co-auteur de l'article ?
- Ne paniquez pas si vous révisez votre article 100 fois ! Meta publie un nouveau modèle de langage d'écriture PEER : des références seront ajoutées
- Alibaba Cloud ouvre les tests du modèle linguistique à grande échelle « Tongyi Qianwen »
- Wang Haifeng, CTO de Baidu : Les grands modèles linguistiques annoncent l'aube de l'intelligence artificielle générale