
Maison >Périphériques technologiques >IA >Quantification, taille, distillation, que disent exactement ces argots des grands modèles ?
Quantification, taille, distillation, que disent exactement ces argots des grands modèles ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-26 09:28:18988parcourir
Quantification, élagage, distillation, si vous faites souvent attention aux grands modèles de langage, vous verrez certainement ces mots rien qu'en regardant ces mots, il nous est difficile de comprendre ce qu'ils font, mais ces mots sont particulièrement importants. pour le développement de grands modèles de langage à ce stade. Cet article vous aidera à les connaître et à comprendre leurs principes.
Compression de modèle
La quantification, l'élagage et la distillation sont en fait des technologies générales de compression de modèles de réseaux neuronaux, non exclusives aux grands modèles de langage.
L'importance de la compression du modèle
Après la compression, le fichier modèle deviendra plus petit, l'espace disque utilisé deviendra également plus petit, l'espace cache utilisé lors du chargement en mémoire ou affiché deviendra également plus petit, et le le fonctionnement du modèle deviendra également plus petit. Il pourrait également y avoir des améliorations de vitesse.
Grâce à la compression, l'utilisation du modèle consommera moins de ressources informatiques, ce qui peut considérablement élargir les scénarios d'application du modèle, en particulier dans les endroits où la taille du modèle et l'efficacité informatique sont plus préoccupantes, comme les téléphones mobiles, les appareils embarqués, etc.
Qu'est-ce qui est compressé ?
Ce qui est compressé, ce sont les paramètres du modèle. Quels sont les paramètres du modèle ?
Vous avez peut-être entendu dire que l'apprentissage automatique actuel utilise des modèles de réseau neuronal. Le modèle de réseau neuronal simule le réseau neuronal du cerveau humain.
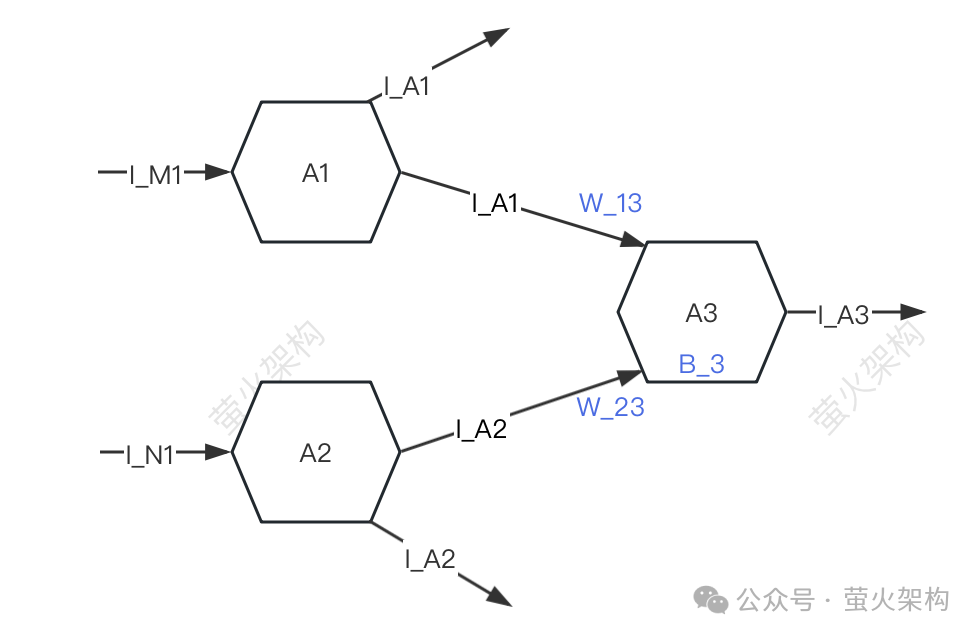
Ici, j'ai dessiné un schéma simple, vous pouvez y jeter un oeil.
 Photos
Photos
Par souci de simplicité, seuls trois neurones sont décrits : A1, A2, A3. Chaque neurone reçoit des signaux d'autres neurones et transmet des signaux à d'autres neurones.
A3 recevra les signaux I_A1 et I_A2 de A1 et A2, mais la force des signaux reçus par A3 de A1 et A2 est différente (cette force est appelée « poids ») Supposons que les forces ici sont W_13 et. W_23 respectivement, A3 traitera les données du signal reçu.
- Effectuez d'abord une sommation pondérée des signaux, c'est-à-dire I_A1*W_13+I_A2*W_23,
- Puis ajoutez le propre paramètre B_3 de A3 (appelé "bias"),
- Enfin, ces données est converti sous une forme spécifique et le signal converti est envoyé au neurone suivant.
Dans le processus de traitement de ces données de signal, les poids (W_13, W_23) et les décalages (B_3) utilisés sont les paramètres du modèle. Bien sûr, le modèle a d'autres paramètres, mais les poids et les décalages le sont généralement. tous La majeure partie des paramètres, s'ils sont divisés selon le principe 80/20, doivent être supérieurs à 80 %.
Lors de l'utilisation d'un grand modèle de langage pour générer du texte, ces paramètres sont déjà pré-entraînés et nous ne pouvons pas les modifier. C'est comme les coefficients des polynômes en mathématiques. Nous ne pouvons transmettre que le xyz inconnu et obtenir un résultat de sortie. .
La compression du modèle consiste à compresser ces paramètres du modèle. Les principales considérations sont les poids et les biais. Les méthodes spécifiques utilisées sont la quantification, l'élagage et la distillation, qui font l'objet de cet article.
Quantisation
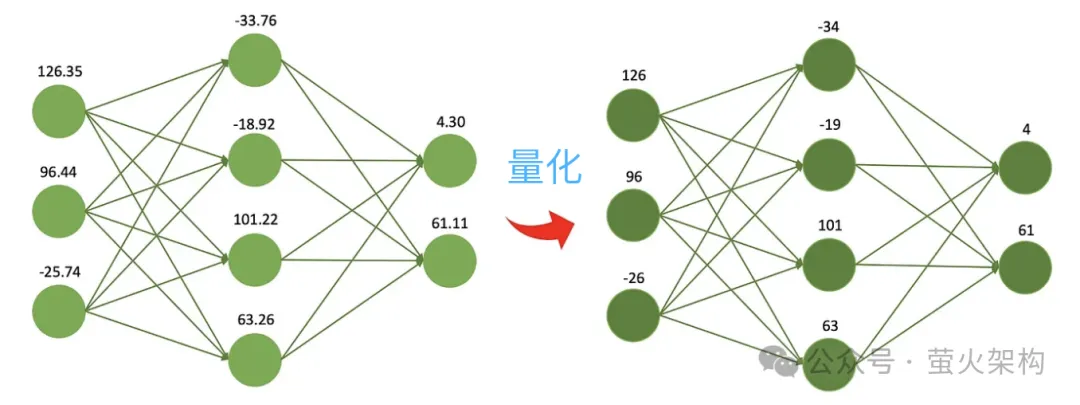
La quantification consiste à réduire la précision numérique des paramètres du modèle. Par exemple, les poids initialement formés sont des nombres à virgule flottante de 32 bits, mais en utilisation réelle, il s'avère qu'il n'y a presque aucune perte si. exprimé en 16 bits, mais la taille du fichier modèle est réduite de moitié, l'utilisation de la mémoire vidéo est réduite de moitié et les besoins en bande passante de communication entre le processeur et la mémoire sont également réduits, ce qui signifie des coûts inférieurs et des avantages plus élevés.
C’est comme suivre une recette, il faut déterminer le poids de chaque ingrédient. Vous pouvez utiliser une balance électronique très précise, précise à 0,01 gramme près, ce qui est génial car vous pouvez connaître très précisément le poids de chaque ingrédient. Cependant, si vous préparez simplement un repas à partager et n'avez pas réellement besoin d'une telle précision, vous pouvez utiliser une balance simple et bon marché avec une balance minimale de 1 gramme, ce qui n'est pas aussi précis mais est suffisant pour préparer un délicieux repas. dîner.
 Images
Images
Un autre avantage de la quantification est qu'elle calcule plus rapidement. Les processeurs modernes contiennent généralement de nombreuses unités de calcul vectoriel de faible précision. Le modèle peut exploiter pleinement ces fonctionnalités matérielles pour effectuer davantage d'opérations parallèles. Dans le même temps, les opérations de faible précision sont généralement plus rapides que les opérations de haute précision. la consommation d'une seule multiplication et addition est plus courte. Ces avantages permettent également au modèle de fonctionner sur des machines de configuration inférieure, telles que des ordinateurs de bureau ou personnels ordinaires, des téléphones mobiles et d'autres terminaux mobiles sans GPU hautes performances.
Suite à cette idée, les gens continuent de compresser les modèles 8 bits, 4 bits et 2 bits, qui sont plus petits et utilisent moins de ressources informatiques. Cependant, à mesure que l'exactitude des poids diminue, les valeurs des différents poids deviendront plus proches, voire égales, ce qui réduira l'exactitude et la précision de la sortie du modèle, et les performances du modèle diminueront à des degrés divers.
La technologie de quantification a de nombreuses stratégies et détails techniques différents, tels que la quantification dynamique, la quantification statique, la quantification symétrique, la quantification asymétrique, etc. Pour les grands modèles de langage, des stratégies de quantification statique sont généralement utilisées une fois la formation du modèle terminée. Les paramètres sont quantifiés une seule fois et les calculs quantitatifs ne sont plus nécessaires lors de l'exécution du modèle, ce qui facilite sa distribution et son déploiement.
Pruning
L'élagage consiste à supprimer les poids sans importance ou rarement utilisés dans le modèle. Les valeurs de ces poids sont généralement proches de 0. Pour certains modèles, l'élagage peut produire un taux de compression plus élevé, rendant le modèle plus compact et efficace. Ceci est particulièrement utile pour déployer des modèles sur des appareils aux ressources limitées ou lorsque la mémoire et le stockage sont limités.
L'élagage améliore également l'interprétabilité du modèle. En supprimant les composants inutiles, l’élagage rend la structure sous-jacente du modèle plus transparente et plus facile à analyser. Ceci est important pour comprendre le processus décisionnel de modèles complexes tels que les réseaux de neurones.
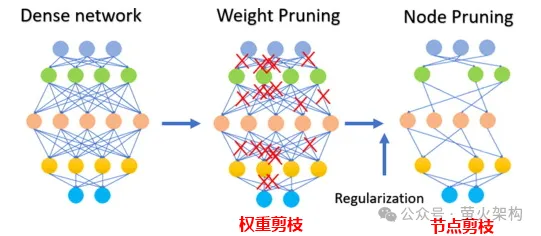
La taille implique non seulement la taille des paramètres de poids, mais également la taille de certains nœuds neuronaux, comme le montre la figure suivante :
 Photo
Photo
A noter que la taille ne convient pas à tous les modèles, pour certains clairsemés. (la plupart des paramètres sont 0 ou proches de 0), l'élagage peut n'avoir aucun effet ; pour certains petits modèles avec relativement peu de paramètres, l'élagage peut également entraîner une baisse significative des performances du modèle ; pour certaines tâches ou applications de haute précision ; Il ne convient pas pour élaguer le modèle, comme le diagnostic médical, qui est une question de vie ou de mort.
Lors de l'application réelle de la technologie d'élagage, il est généralement nécessaire de prendre en compte de manière globale l'amélioration de la vitesse d'exécution du modèle et l'impact négatif de l'élagage sur les performances du modèle, et d'adopter certaines stratégies, telles que la notation de chaque paramètre du modèle, c'est-à-dire évaluer les paramètres. Dans quelle mesure cela contribue-t-il aux performances du modèle. Ceux qui ont des scores élevés sont des paramètres importants qui ne doivent pas être tronqués ; ceux qui ont des scores faibles sont des paramètres qui ne sont peut-être pas si importants et peuvent être pris en compte pour un seuil. Ce score peut être calculé par diverses méthodes, telles que l'examen de la taille du paramètre (la valeur absolue la plus élevée est généralement plus importante), ou déterminé par des méthodes d'analyse statistique plus complexes.
Distillation
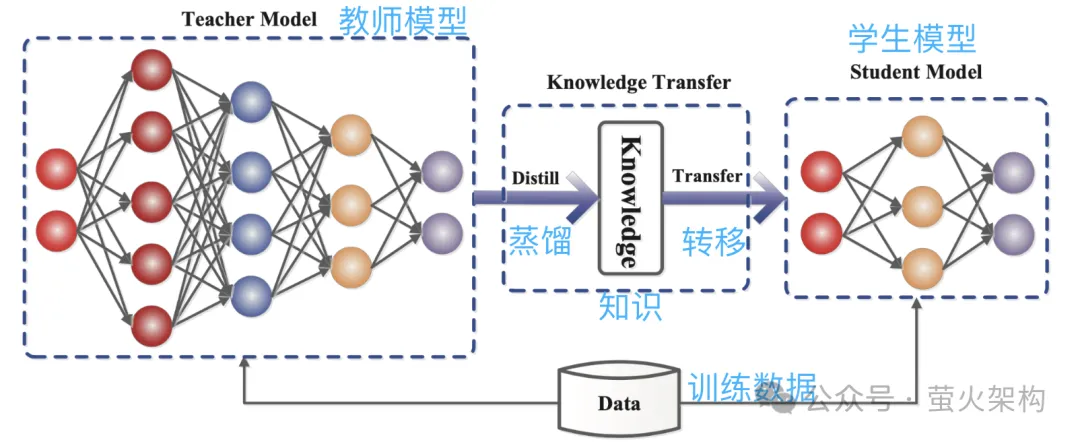
La distillation consiste à copier directement la distribution de probabilité apprise par le grand modèle dans un petit modèle. Le modèle copié est appelé modèle d'enseignant, qui est généralement un excellent modèle avec un grand nombre de paramètres et de fortes performances. Le nouveau modèle est appelé modèle d'étudiant, qui est généralement un petit modèle avec relativement peu de paramètres.
Pendant la distillation, le modèle de l'enseignant générera des distributions de probabilité de plusieurs sorties possibles en fonction de l'entrée, puis le modèle de l'élève apprendra la distribution de probabilité de cette entrée et de cette sortie. Après une formation approfondie, le modèle étudiant peut imiter le comportement du modèle enseignant ou acquérir les connaissances du modèle enseignant.
Par exemple, dans une tâche de classification d'images, étant donné une image, le modèle de l'enseignant peut générer une distribution de probabilité similaire à la suivante :
- Chat : 0,7
- Chien : 0,4
- Voiture : 0.1
Ensuite, soumettez cette image et les informations de distribution de probabilité de sortie au modèle d'élève pour l'apprentissage par imitation.
 Photos
Photos
Parce que la distillation compresse les connaissances du modèle d'enseignant dans un modèle d'étudiant plus petit et plus simple, le nouveau modèle peut perdre certaines informations. De plus, le modèle d'étudiant peut trop s'appuyer sur le modèle d'enseignant, ce qui entraîne une faible capacité de généralisation.
Afin d'améliorer l'effet d'apprentissage du modèle étudiant, nous pouvons adopter certaines méthodes et stratégies.
Présentation du paramètre de température : Supposons qu'il y ait un enseignant qui enseigne très vite et que la densité de l'information soit très élevée, cela peut être un peu difficile à suivre pour les élèves. À ce moment-là, si l’enseignant ralentit et simplifie l’information, celle-ci sera plus facile à comprendre pour les élèves. Dans la distillation du modèle, le paramètre de température joue un rôle similaire à « l'ajustement de la vitesse de cours » pour aider le modèle étudiant (petit modèle) à mieux comprendre et acquérir les connaissances du modèle enseignant (grand modèle). D'un point de vue professionnel, il s'agit de donner à la sortie du modèle une distribution de probabilité plus fluide, ce qui permettra au modèle étudiant de capturer et d'apprendre plus facilement les détails de sortie du modèle enseignant.
Ajustez la structure du modèle d'enseignant et du modèle d'étudiant : Il peut être difficile pour un étudiant d'apprendre quelque chose d'un expert, car l'écart de connaissances entre eux est trop grand et l'apprentissage direct peut ne pas comprendre. ajoutez un enseignant au milieu, qui peut à la fois comprendre les mots des experts et les traduire dans un langage que les élèves peuvent comprendre. L'enseignant ajouté au milieu peut être des couches intermédiaires ou des réseaux de neurones auxiliaires, ou l'enseignant peut apporter quelques ajustements au modèle d'élève afin qu'il puisse mieux correspondre à la sortie du modèle d'enseignant.
Nous avons présenté trois technologies principales de compression de modèles ci-dessus. En fait, il y a encore beaucoup de détails ici, mais c'est presque suffisant pour comprendre les principes. Il existe également d'autres technologies de compression de modèles, telles que la décomposition de bas rang. et partage de paramètres, connexion clairsemée, etc. Les étudiants intéressés peuvent consulter davantage de contenu connexe.
De plus, une fois le modèle compressé, ses performances peuvent diminuer considérablement. À ce stade, nous pouvons affiner le modèle, en particulier pour les tâches qui nécessitent une grande précision du modèle, telles que le diagnostic médical, le risque financier. contrôle et conduite automatique, etc., le réglage fin peut restaurer les performances du modèle dans une certaine mesure et stabiliser son exactitude et sa précision dans certains aspects.
En parlant de réglage fin du modèle, j'ai récemment partagé une image de Text Generation WebUI sur AutoDL Text Generation WebUI est un programme Web écrit à l'aide de Gradio, qui peut facilement effectuer l'inférence et le réglage fin de grands modèles de langage, et prend en charge. une variété de types de grands modèles de langage, notamment Transformers, llama.cpp (GGUF), GPTQ, AWQ, EXL2 et d'autres modèles dans divers formats. Dans la dernière image, j'ai intégré le grand modèle Llama3 récemment open source par Meta. . Étudiants intéressés Vous pouvez l'essayer, voir comment l'utiliser : Apprenez à peaufiner un grand modèle de langage en dix minutes
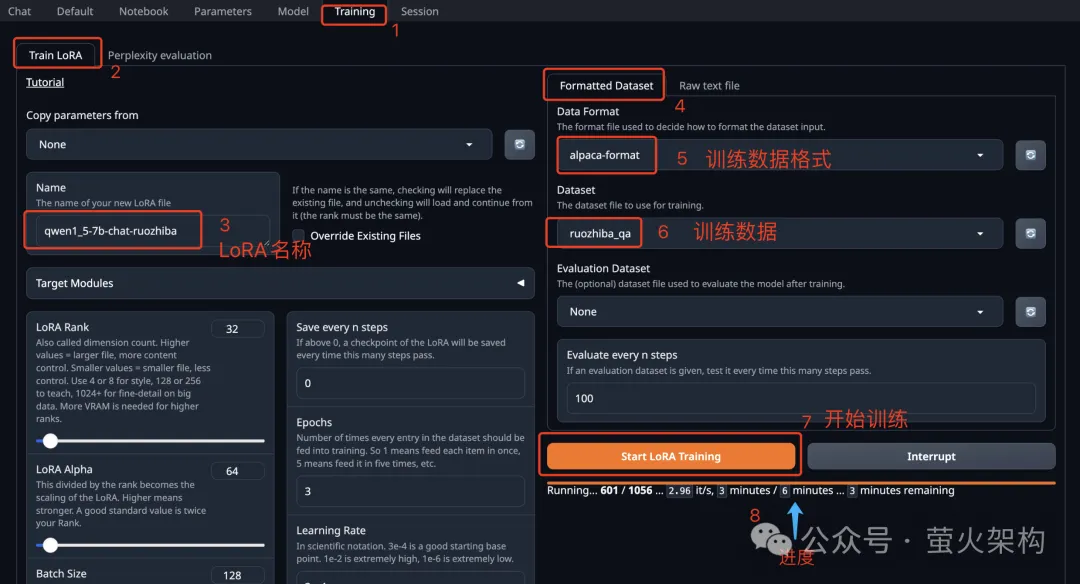 Photos
Photos
Article de référence :
https:/ /www.php.cn/link/d7852cd2408d9d3205dc75b59 a6ce22e
https://www.php.cn/link/f204aab71691a8e18c3f6f00872db63b
https://www.php.cn/link/b31f0c758bb498b5d56b5fea80 f313a7
https://www.php .cn/link/129ccfc1c1a82b0b23d4473a72373a0a
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- En quoi la norme ieee802 divise-t-elle le modèle hiérarchique du réseau local en
- Définition des méthodes d'interaction : interaction entre quantification de modèles et intelligence artificielle de pointe
- Logiciel de trading quantitatif de monnaie numérique classé parmi les dix meilleures applications de plateforme de trading quantitatif dans le cercle des devises
- ICLR 2024 Spotlight | Le poids du modèle de langage large, l'activation et la micronisation complète à faible débit ont été intégrés dans l'application commerciale